MapReduce实现倒排索引(类似协同过滤)
一、问题背景
倒排索引其实就是出现次数越多,那么权重越大,不过我国有凤巢....zf为啥不管,总局回应推广是不是广告有争议...
eclipse里ctrl+t找接口或者抽象类的实现类,看看都有啥方法,有时候hadoop的抽象类返回的接口没有需要的方法,那么我们返回他的实现类。
吧需要的文件放入hdfs下的目录下,只要不是以下划线开头的均算。
二、理论准备
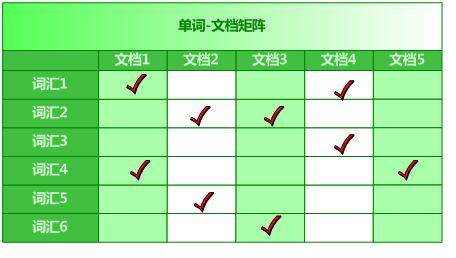
搜索引擎查询的时候就是查询这个单词文档矩阵,旺旺采用倒排索引存储,后缀树也可以。
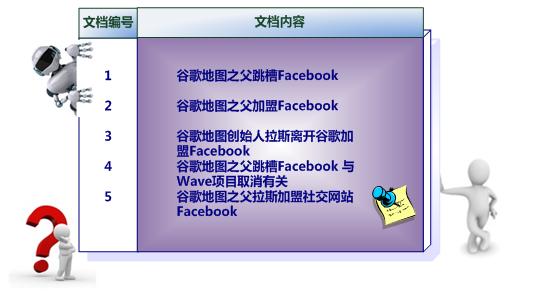
不管理论直接看例子,这是原始的文档
下面是简单的索引,只是表征是否在文档中出现过。
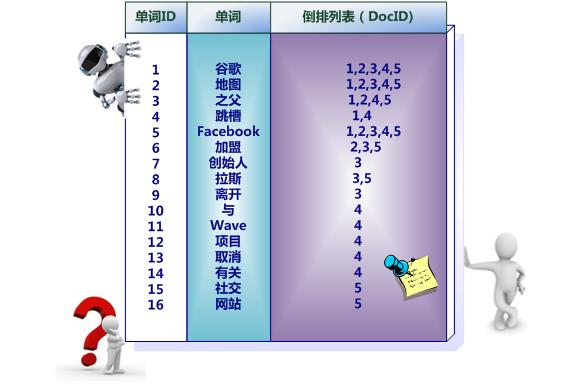
下面就是文档及出现次数。

擦,咋有点想协同过滤。
三、思路分析
其实是一个全文检索的数据结构。理论上关键字出现次数越多,那么文章就越靠前。
就是wc的加强版本。wc是统计单词在文章里出现的次数,倒排是统计关键字在各个文章出现的次数。
有时候不能一下子写出来,可能需要多次mr,那么我们首先确定最终的结果形式,然后向上反推。
如果多个mr,考虑使用combiner,不过要考虑combiner是不是可插拔的,也就是combiner和业务逻辑是否和reducer一样。
怎么知道单词出现在那个文章里?从context对象里获取。既然能忘context写东西,那么也能从其中获取信息。
最终结果是
hello "a.txt->5 b.txt->3"
tom "a.txt->2 b.txt->1"
kitty "a.txt->1"
那么reduce的输出
context.write("hello","a.txt->5 b.txt->3");
那么combiner阶段是
<"hello",{"a.txt->5","b.txt->3"}>
那么map的输出
context.write("hello","a.txt->5");
context.write("hello","b.txt->3");
不过考虑到wc,map的输出应该是,路径放在value不好处理,还要廉价呢。
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
那么combiner阶段根据就输出
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1><"hello->b.txt",1>
<"hello->b.txt",1>
<"hello->b.txt",1>context.write("hello","a.txt->5");
context.write("hello","b.txt->3");
次是不同文件的相同key并没有合并,reducer合并输出皆可。
四、代码实现
4.1 Mapper
public class IIMapper1 extends Mapper<LongWritable, Text, Text, Text> {private Text k = new Text();//下面其实是int,不过也可以在接收端Integer.parseInt转了就好private Text v = new Text();public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");//从context对象里找到单词属于那个文章//context.getInputSplit();找到切片 按ctrl找 发现返回时InputSplit//不过是个抽象类 ctrl + t找他的实现类//能把数据写入context,繁殖也能从context拿到很多信息//从下面inputSplit调用get的时候发现没有合适的方法,那么我们找他的实现类,调用实现类的方法//InputSplit inputSplit = context.getInputSplit();//inputSplit.get//他的子类很多 我们处理文件就用File开头的 然后有个getPathFileSplit inputSplit = (FileSplit)context.getInputSplit();//文件名是hdfs://hostname:port/a/1.txt//我们戒掉hdfs://hostname:port 不能戒掉a 应为这是文件夹否则不知道1.txt来自哪 其他文件家下可能也有同名文件//也可以不接去String path = inputSplit.getPath().toString();for(String w:words) {k.set(w+"->"+path);v.set("1");context.write(k, v);}}}
4.2 Combiner
String[] wordAndPath = key.toString().split("->");String word = wordAndPath[0];String path = wordAndPath[1];// process valuesint sum = 0;for (Text val : value) {sum += Integer.parseInt(val.toString());}k.set(word);v.set(path+"->"+sum);context.write(k, v);
4.3 Reducer
//不涉及多线程 用StringBuilde即可StringBuilder sb = new StringBuilder();// process valuesfor (Text val : value) {sb.append(val.toString()).append("\t");}context.write(key, new Text(sb.toString()));
四、实验分析

MapReduce实现倒排索引(类似协同过滤)相关推荐
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
- 协同过滤算法 R/mapreduce/spark mllib多语言实现
用户电影评分数据集下载 http://grouplens.org/datasets/movielens/ 1) Item-Based,非个性化的,每个人看到的都一样 2) User-Based,个性化 ...
- 从原理到实现,详解基于朴素ML思想的协同过滤推荐算法
作者丨gongyouliu 编辑丨Zandy 来源 | 大数据与人工智能(ID: ai-big-data) 作者在<协同过滤推荐算法>.<矩阵分解推荐算法>这两篇文章中介绍了几 ...
- 推荐系统组队学习——协同过滤
文章目录 一.协同过滤介绍 二.相似度度量方法 1. 杰卡德(Jaccard)相似系数 2. 余弦相似度 3. 皮尔逊相关系数 三.基于用户的协同过滤 原理 编程实现 UserCF优缺点 四.基于物品 ...
- Java游戏碟中谍_MapRedcue的demo(协同过滤)
MapRedcue的演示(协同过滤) 做一个关于电影推荐.你于你好友之间的浏览电影以及电影评分的推荐的协同过滤. 百度百科: 协同过滤简单来说是利用某兴趣相投.拥有共同经验之群体的喜好来推荐用户感兴趣 ...
- 推荐引擎算法学习导论:协同过滤、聚类、分类(2011年旧文)
推荐引擎算法学习导论:协同过滤.聚类.分类 作者:July 出处:结构之法算法之道 引言 昨日看到几个关键词:语义分析,协同过滤,智能推荐,想着想着便兴奋了.于是昨天下午开始到今天凌晨3点,便研究了一 ...
- 推荐系统2——协同过滤CF
在之前我也看了很多人写的推荐系统的博客,理论的.算法的都有,多是个人的理解和感悟,虽然很深刻,但是对于自己而言还是不成系统,于是我参考大牛项亮编著的<推荐系统实践>将该领域知识系统整理一遍 ...
- 从原理到落地,七大维度读懂协同过滤推荐算法
作者丨gongyouliu 来源 | 大数据与人工智能 导语:本文会从协同过滤思想简介.协同过滤算法原理介绍.离线协同过滤算法的工程实现.近实时协同过滤算法的工程实现.协同过滤算法应用场景.协同过滤算 ...
- 推荐算法——基于协同过滤CF
https://www.toutiao.com/a6643326861214482957/ 2019-01-06 18:21:09 前边我们已经介绍了推荐算法里的基于内容的推荐算法CB,今天我们来介绍 ...
最新文章
- Camera360与全球1.8亿用户共同创造更美的照片
- JavaFX 2 GameTutorial第5部分
- 七、CSS 三大特性(完整详细解析)
- 挑战记忆力-Web前端实现记忆纸牌游戏(JS+CSS)
- 保护我方小学生!腾讯游戏全面启用防沉迷规则,每月充值金额有上限
- 单点登录原理与简单实现【转载】
- 一组飒气十足的商务海报PSD分层海报
- C语言实现可变参数列表的system接口:宏__VA_ARGS__
- Maven学习总结(28)——Maven+Nexus+Myeclipse集成
- GitHub 的简单使用
- 训练中Loss为Nan的原因,梯度消失或者爆炸的优化
- (转)一张图学会Dockerfile
- 开发APP软件需要哪些编程语言和开发环境
- 基于matlab的64QAM通信系统的仿真
- linux安装五笔输入法centos,CentOS 7系统怎么安装极点五笔输入法?
- 飞信2008协议抓包(2)
- arcgis server发布自定义打印模板及利用ArcGIS API javascript使用自定义打印服务打印地图
- st58服务器装系统,微pe硬盘安装系统教程
- ServiceNow获得FedRAMP高基准授权
- web服务器是什么?web服务器有哪些
热门文章
- mysql存储过程表_mysql 存储过程,表
- mysql date week_mysql weekday(date)/subdate(date,间隔天数)查询年龄/本月/周过生日
- 数学建模题目及论文_三道适合作为试题的数学建模题目及其评分标准
- showdoc windows 搭建_Windows 搭建在线文档工具showdoc工具
- autocad不能画图_设计院老司机谈CAD:学习AutoCAD掌握方法技巧更重要
- matlab 二重积分
- Markdown 编辑器的使用记录 (Typora)
- 【 FPGA 】跨时钟域处理以及边沿检测
- Spartan-6的MCB模块、GTP模块、PCIe端点模块
- Spartan-6的SelectIO资源