从 pheatmap 无缝迁移至 ComplexHeatmap
pheatmap 是一个非常受欢迎的绘制热图的 R 包。ComplexHeatmap 包即是受之启发而来。你可以发现Heatmap()函数中很多参数都与pheatmap()相同。在 pheatmap 的时代(请允许我这么说),pheatmap 意思是 pretty heatmap,但是随着时间推进,技术发展,各种新的数据出现,pretty is no more pretty,我们需要更加复杂和更有效率的热图可视化方法对庞大的数据进行快速并且有效的解读,因此我开发并且一直维护和改进着 ComplexHeatmap 包。
为了使庞大并且“陈旧”的(对不起,我不应该这么说。)pheatmap 用户群能够迅速并且无痛的迁移至 ComplexHeatmap,从 2.5.2 版本开始,我在 ComplexHeatmap 包中加入了一个pheatmap()函数,它涵盖了pheatmap::pheatmap()所有的功能,也就是说,它提供了和pheatmap::pheatmap()一模一样的参数,并且生成的热图的样式也几乎相同。同时,ComplexHeatmap::pheatmap()函数也能使用 ComplexHeatmap 独有的功能,比如对行和列进行切分,加入自定义的 annotation,多个热图和 annotation 的连接,或者创建一个互动的热图(interactive heatmap, 通过ht_shiny()函数)。
ComplexHeatmap::pheatmap()包含了pheatmap::pheatmap()中所有的参数,这意味着,当你从 pheatmap 迁移至 ComplexHeatmap 时,你无需添加任何额外的步骤,你只需要载入 ComplexHeatmap 而不是 pheatmap 包,然后重新运行你原始的 pheatmap 代码。剩下的你只是去见证奇迹的发生。
注意如下五个pheatmap::pheatmap()的参数在ComplexHeatmap::pheatmap()中被忽视:
kmeans_k:在pheatmap::pheatmap()中,如果这个参数被设定,输入矩阵会进行 k 均值聚类,然后每个 cluster 使用其均值向量表示。最终的热图是 k 个均值向量的热图。此操作改变了原始矩阵的大小,而且每个 cluster 的大小信息丢失了,直接解读均值向量可能会造成对数据的误解。我不赞成此操作,因此我没有支持这个参数。在 ComplexHeatmap 中,row_km和column_km参数可能是一个更好的选择。filename:如果这个参数被设定,热图直接保存至指定的文件中。我认为这只是画蛇添足(没有贬低 pheatmap 的意思,只是最近在给小孩讲成语故事,然后想在这里使用一下)的一步,ComplexHeatmap::pheatmap()不支持此参数。width:filename的宽度。height:filename的长度。silent:是否打印信息。
在pheatmap::pheatmap()中,color参数需要设置为一个长长的颜色向量(如果你想用 100 种颜色的话),比如:
pheatmap::pheatmap(mat, color = colorRampPalette(rev(brewer.pal(n = 7, name = "RdYlBu")))(100))在ComplexHeatmap::pheatmap()中,你可以简化无需使用colorRampPalette()去扩展更多的颜色,你可以直接简化为如下,颜色会被自动插值和扩展。
ComplexHeatmap::pheatmap(mat, color = rev(brewer.pal(n = 7, name = "RdYlBu")))例子
我们首先创建一个随机数据,这个来自于 pheatmap 包中提供的例子:
https://rdrr.io/cran/pheatmap/man/pheatmap.html
test = matrix(rnorm(200), 20, 10)test[1:10, seq(1, 10, 2)] = test[1:10, seq(1, 10, 2)] + 3test[11:20, seq(2, 10, 2)] = test[11:20, seq(2, 10, 2)] + 2test[15:20, seq(2, 10, 2)] = test[15:20, seq(2, 10, 2)] + 4colnames(test) = paste("Test", 1:10, sep = "")rownames(test) = paste("Gene", 1:20, sep = "")我们载入 ComplexHeatmap 包,然后执行pheatmap()函数,生成一副和pheatmap::pheatmap()非常类似的热图。
library(ComplexHeatmap)# 注意这是ComplexHeatmap::pheatmappheatmap(test)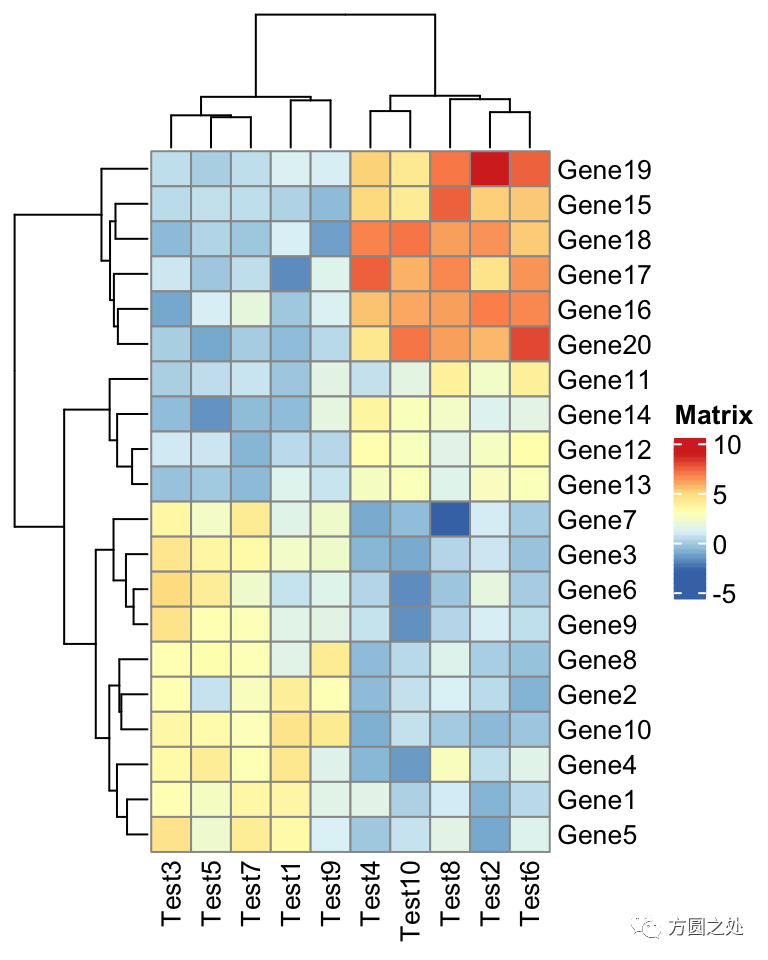
在ComplexHeatmap::pheatmap()中,按照pheatmap::pheatmap()的样式进行了相应的配置,因此,大部分元素的样式一模一样。只有少部分不一致,比如说热图的 legend。
下一个例子是在热图中加入 annotation。以下代码是在pheatmap()中添加 annotation。如果你是pheatmap()用户,你应该对 annotation 的数据格式不太陌生。
annotation_col = data.frame( CellType = factor(rep(c("CT1", "CT2"), 5)), Time = 1:5)rownames(annotation_col) = paste("Test", 1:10, sep = "")
annotation_row = data.frame( GeneClass = factor(rep(c("Path1", "Path2", "Path3"), c(10, 4, 6))))rownames(annotation_row) = paste("Gene", 1:20, sep = "")
ann_colors = list( Time = c("white", "firebrick"), CellType = c(CT1 = "#1B9E77", CT2 = "#D95F02"), GeneClass = c(Path1 = "#7570B3", Path2 = "#E7298A", Path3 = "#66A61E"))
pheatmap(test, annotation_col = annotation_col, annotation_row = annotation_row, annotation_colors = ann_colors)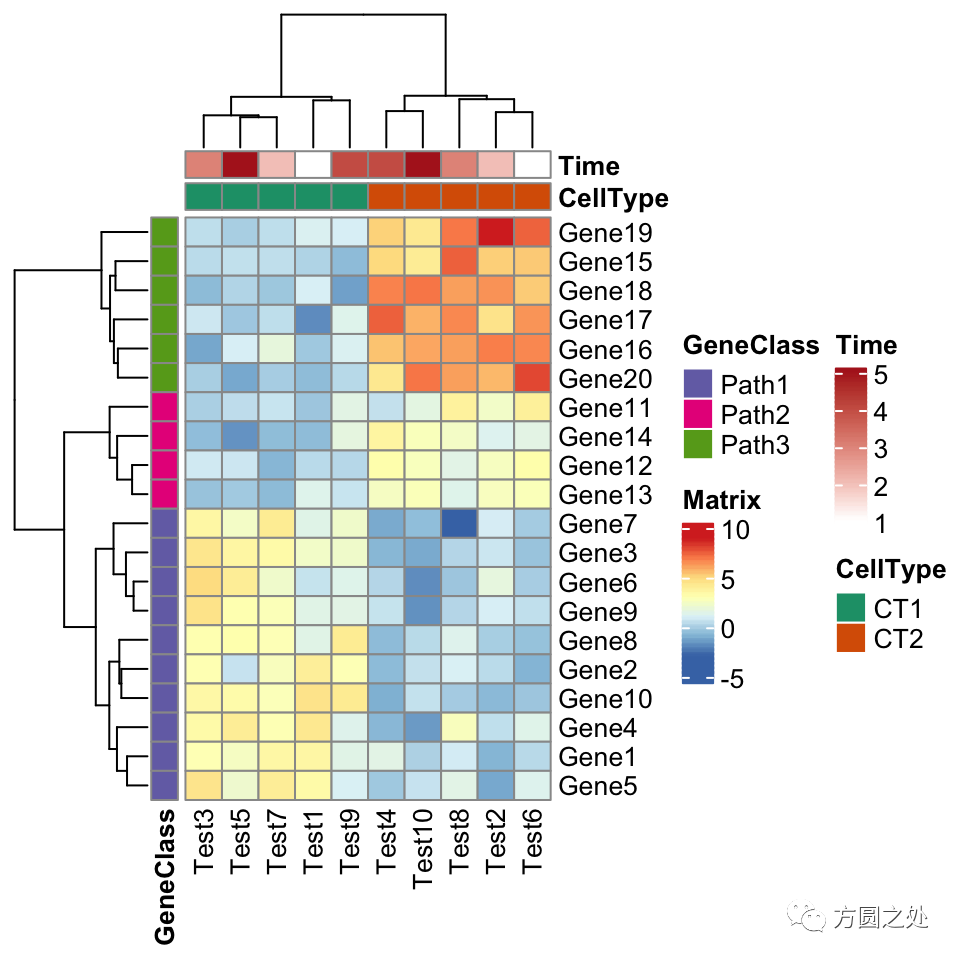
看起来和pheatmap::pheatmap()还是很一致。
ComplexHeatmap::pheatmap()内部其实使用了Heatmap()函数,因此更多的参数都最终传递给了Heatmap()。我们可以在pheatmap()中使用一些Heatmap()特有的参数,比如row_split和column_split来对行和列进行切分。
pheatmap(test, annotation_col = annotation_col, annotation_row = annotation_row, annotation_colors = ann_colors, row_split = annotation_row$GeneClass, column_split = annotation_col$CellType)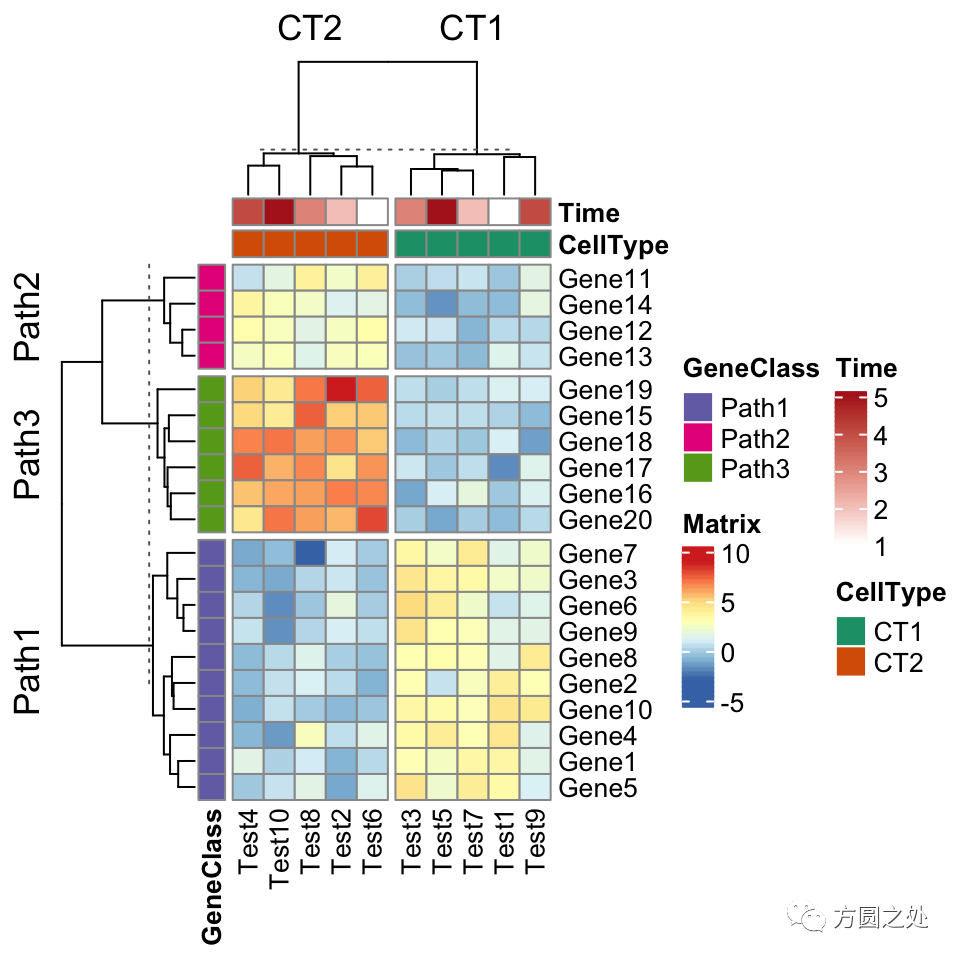
ComplexHeatmap::pheatmap()返回一个Heatmap对象,因此它可以与其他Heatmap/HeatmapAnnotation对象连接。换句话说,你可以使用炫酷的+或者%v%对多个 pheatmap 水平连接或者垂直连接。
p1 = pheatmap(test, name = "mat1")p2 = rowAnnotation(foo = anno_barplot(1:nrow(test)))p3 = pheatmap(test, name = "mat2", col = c("navy", "white", "firebrick3"))p1 + p2 + p3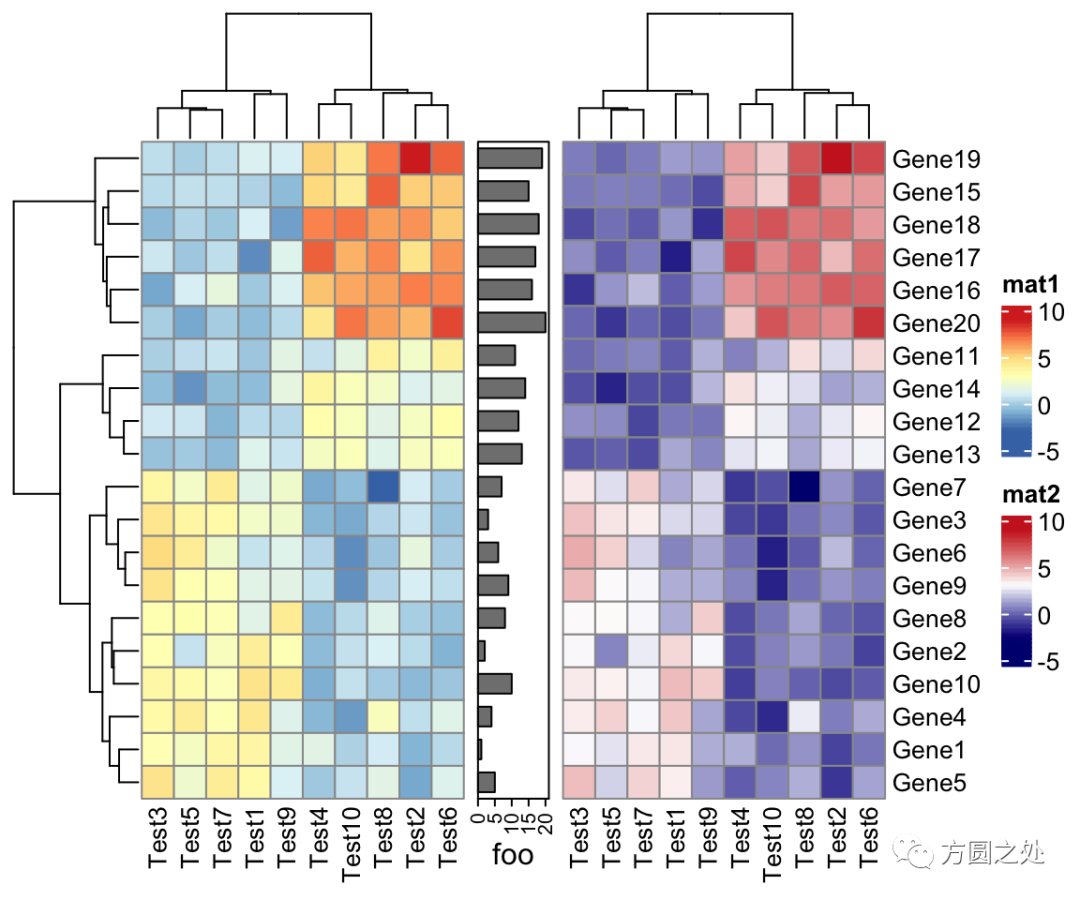
ComplexHeatmap 支持将一个热图导出为一个 shiny app,这也同样适用于pheatmap(),因此你可以这样做:
ht = pheatmap(...)ht_shiny(ht) # 强烈建议试一试还有一件重要的小事是,因为ComplexHeatmap::pheatmap()返回一个Heatmap对象,如果pheatmap()并没有在一个 interactive 的环境执行,比如说在一个 R 脚本中,或者在一个函数/for loop 中,你应该显式的调用draw()函数进行画图。
for(...) { p = pheatmap(...) draw(p)}最后我想说的事,这篇文章的主旨并不是鼓励用户直接使用ComplexHeatmap::pheatmap(),我只是在此展示了 pheatmap 完全可以用 ComplexHeatmap 来代替,而且 ComplexHeatmap 提供了工具让用户无需任何额外的操作(zero effort)就可以迁移以前旧的代码。但是我还是强烈建议用户直接使用 ComplexHeatmap 中的“正经函数”。
从 pheatmap 到 ComplexHeatmap 的翻译
在“阅读原文”中,你可以找到一个表格,其中详细的列出了如何将pheatmap::pheatmap()中的参数对应到Heatmap()中。
比较
这一小节我比较了相同参数下pheatmap::pheatmap()生成的热图和ComplexHeatmap::pheatmap()的相似度。我使用了 pheatmap 包中所有的例子(https://rdrr.io/cran/pheatmap/man/pheatmap.html)。同时我也使用了 ComplexHeatmap 中提供的一个简单的帮助函数ComplexHeatmap::compare_pheatmap()。它的功能就是把参数同时传递给pheatmap::pheatmap()和ComplexHeatmap::pheatmap(),然后生成两幅热图,这样可以直接进行比较。因此如下代码:
compare_pheatmap(test)其实等同于:
pheatmap::pheatmap(test)ComplexHeatmap::pheatmap(test)在往下阅读之前,我先告诉你结论:pheatmap::pheatmap()和ComplexHeatmap::pheatmap()产生的热图几乎完全相同。
只提供一个矩阵:
compare_pheatmap(test)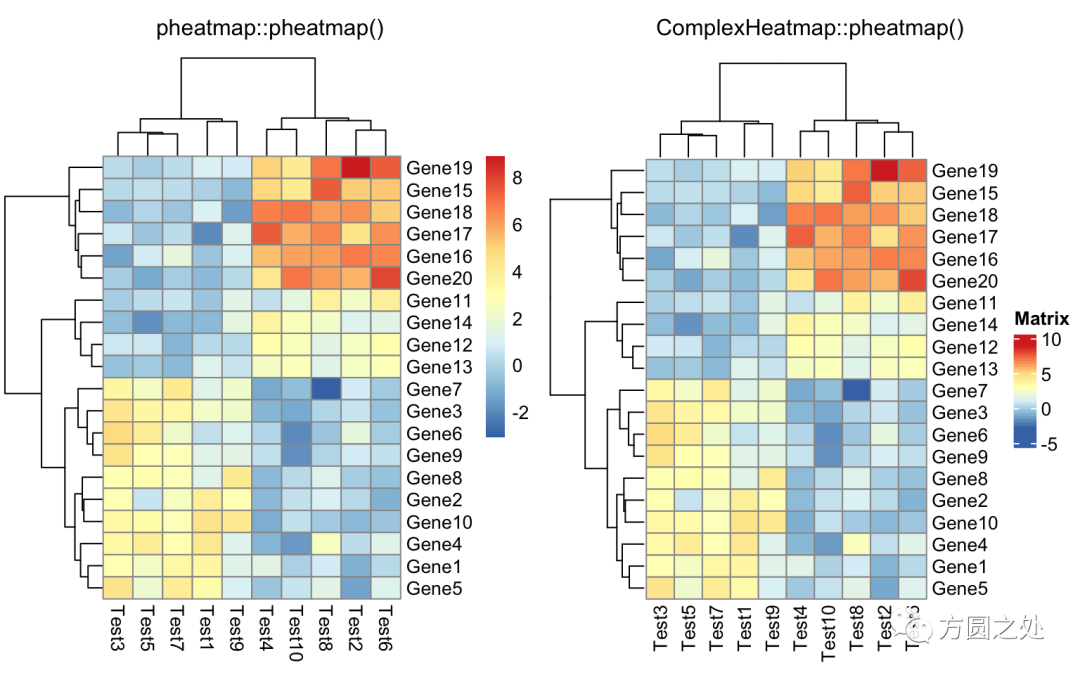
对列进行 z-score 归一化,行聚类距离使用相关性距离:
compare_pheatmap(test, scale = "row", clustering_distance_rows = "correlation")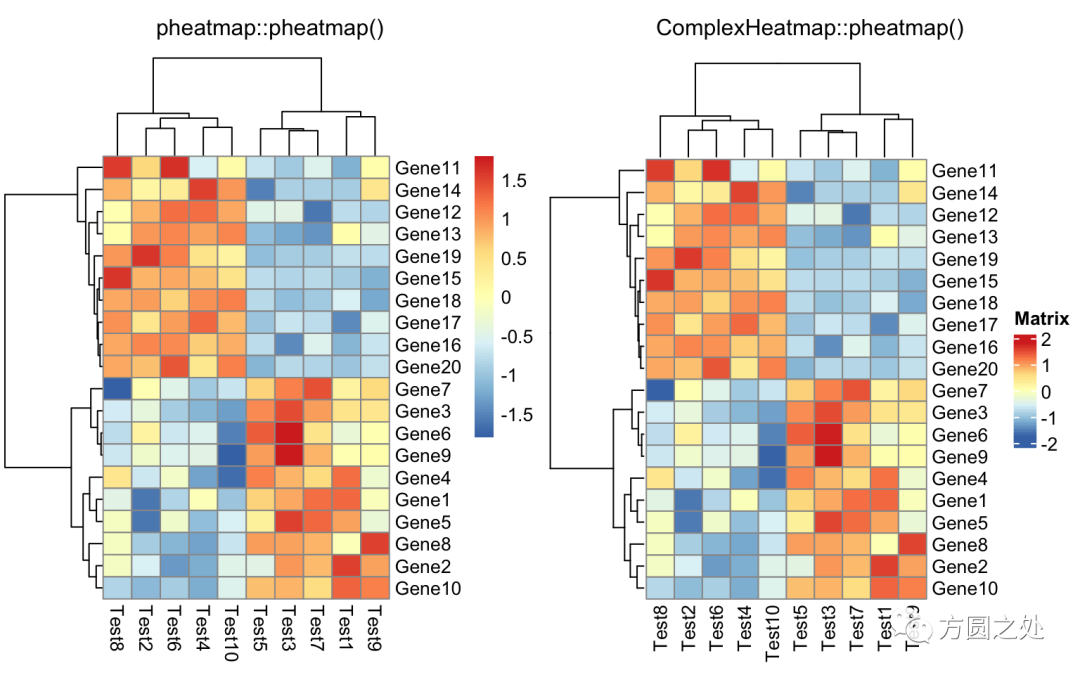
设定颜色:
compare_pheatmap(test, color = colorRampPalette(c("navy", "white", "firebrick3"))(50))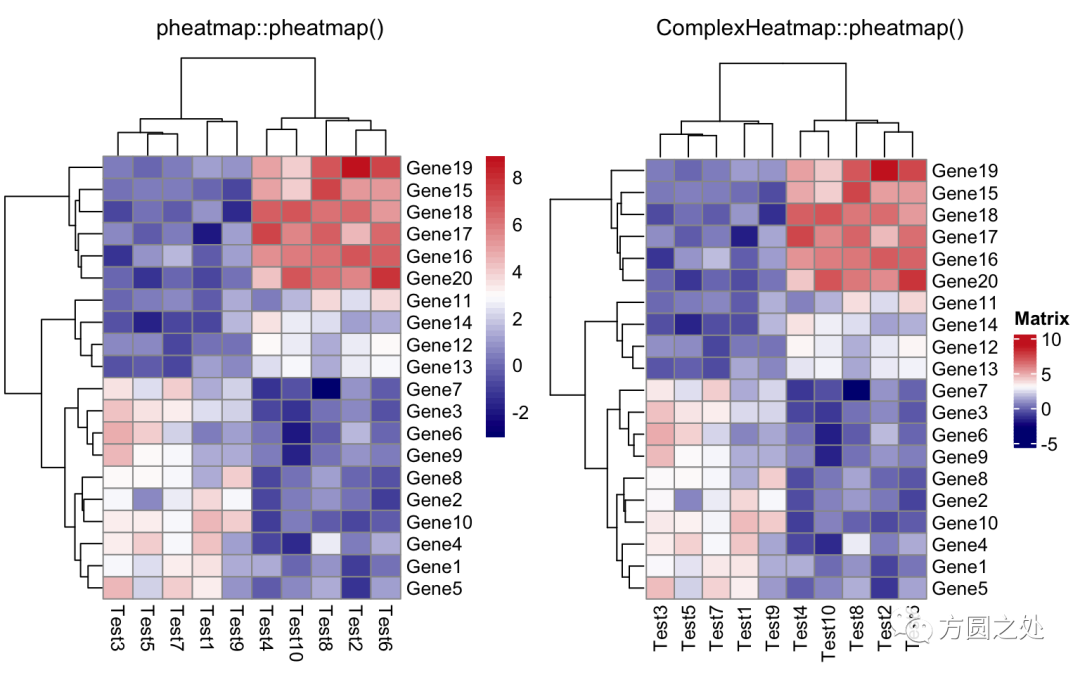
不对行聚类:
compare_pheatmap(test, cluster_row = FALSE)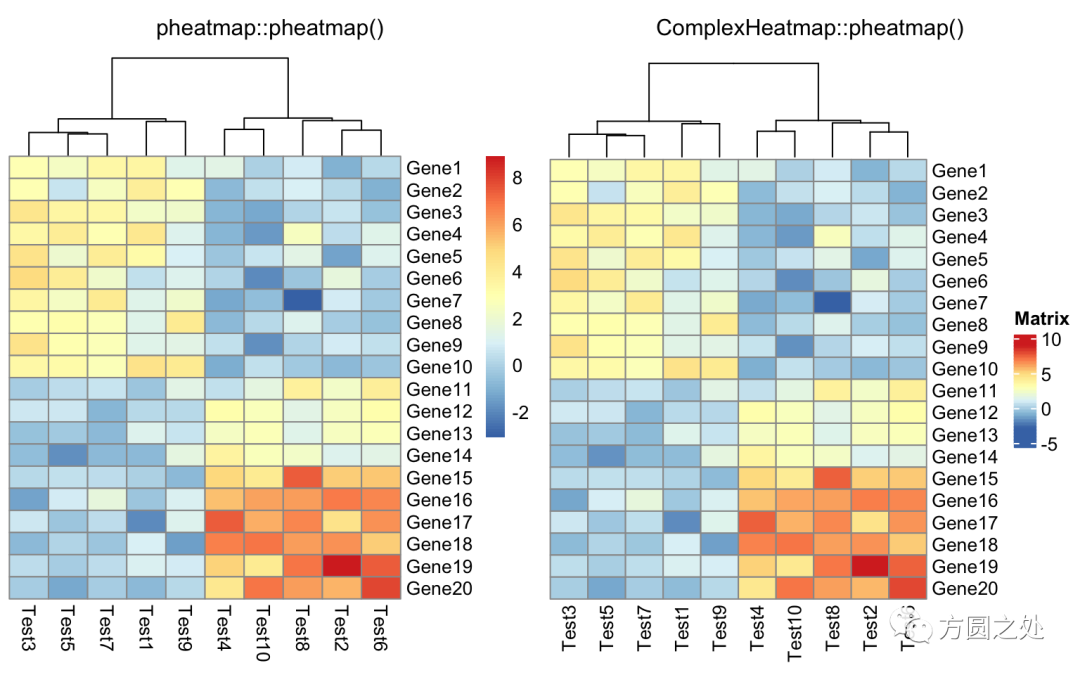
不显示 legend:
compare_pheatmap(test, legend = FALSE)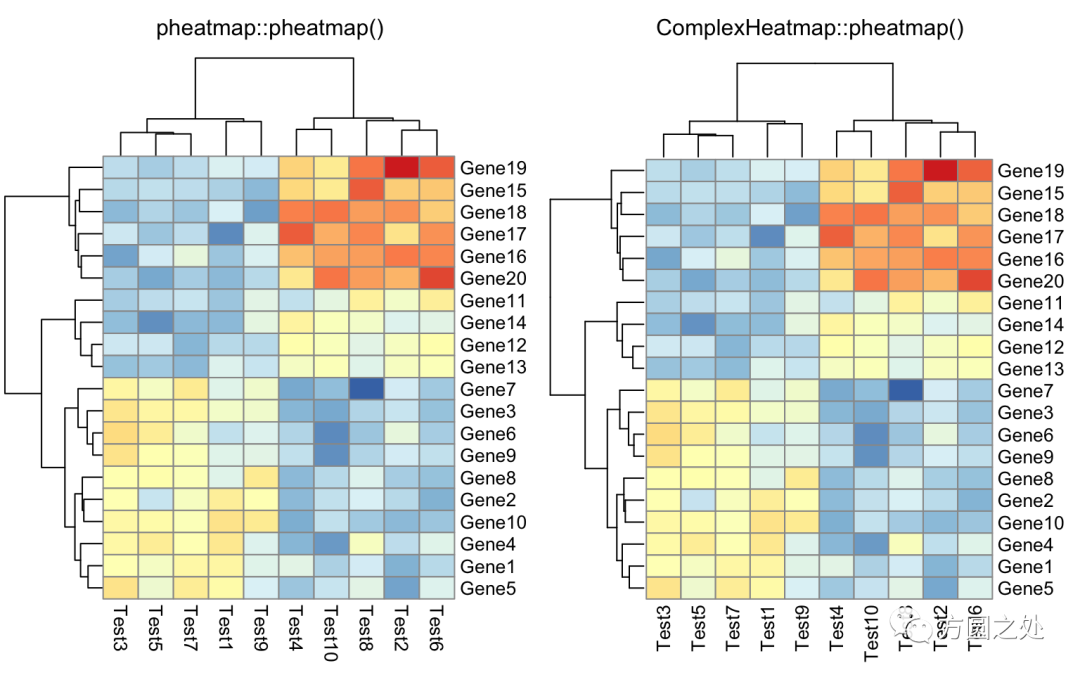
在矩阵格子上显示数值:
compare_pheatmap(test, display_numbers = TRUE)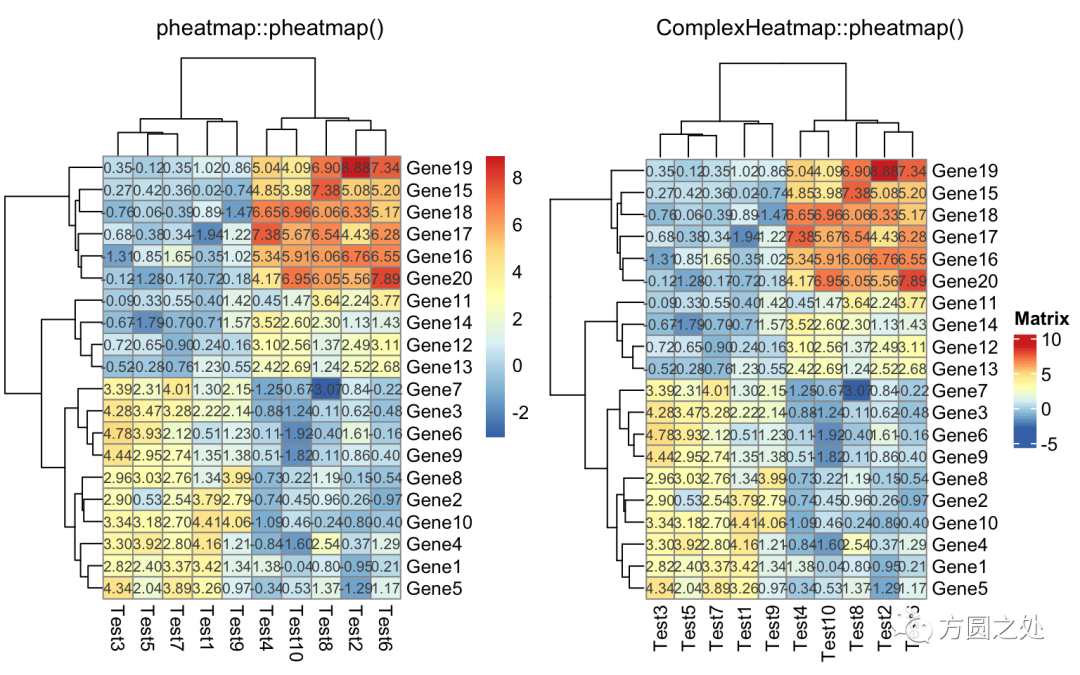
对矩阵格子上的数值进行格式化:
compare_pheatmap(test, display_numbers = TRUE, number_format = "%.1e")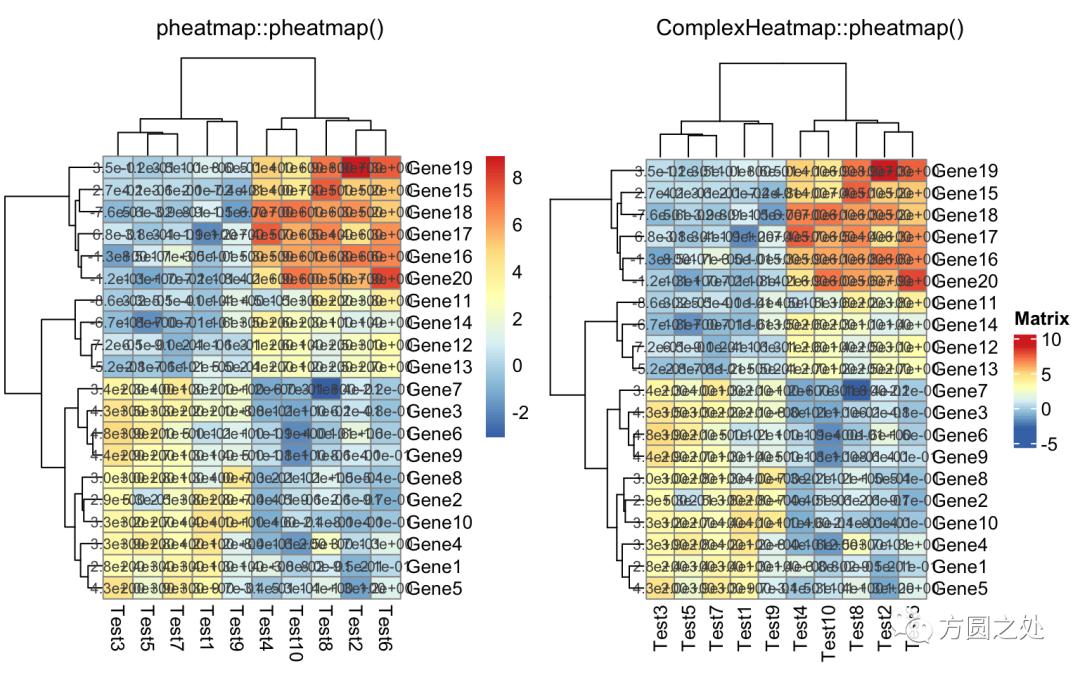
自定义矩阵格子上的文字:
compare_pheatmap(test, display_numbers = matrix(ifelse(test > 5, "*", ""), nrow(test)))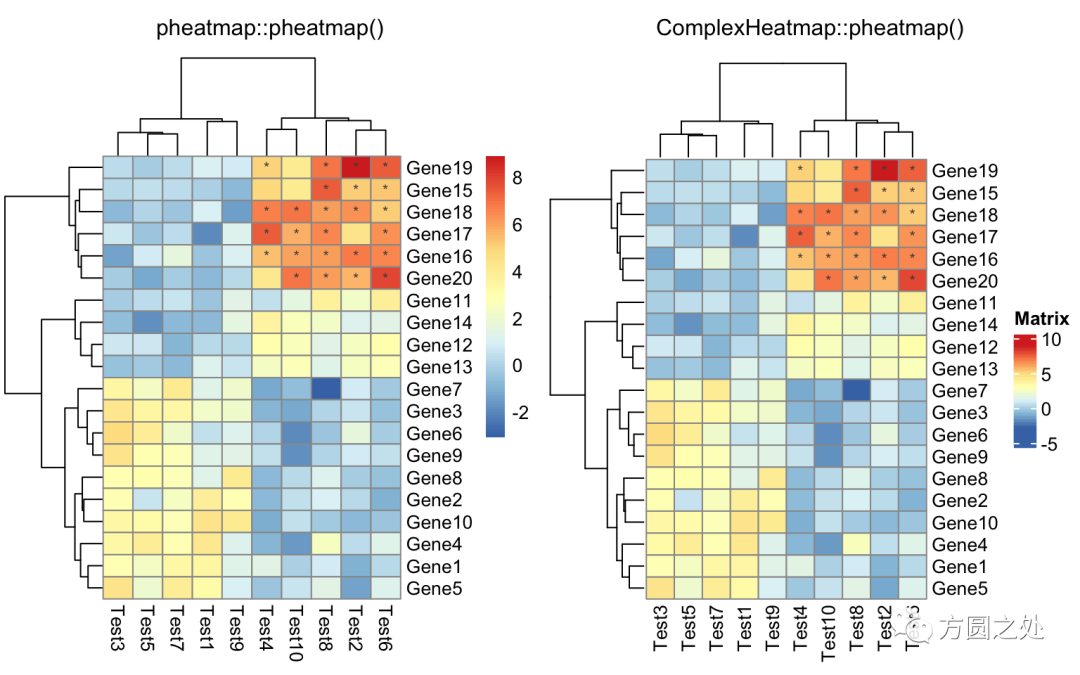
定义 legend 上的 label:
compare_pheatmap(test, cluster_row = FALSE, legend_breaks = -1:4, legend_labels = c("0", "1e-4", "1e-3", "1e-2", "1e-1", "1"))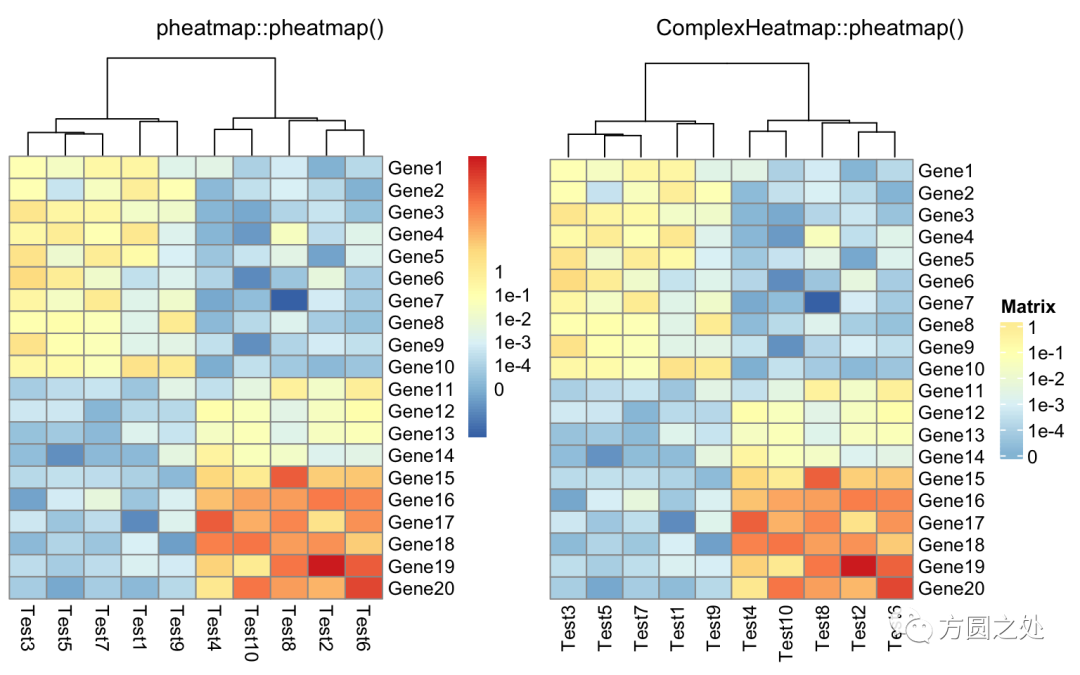
热图的标题:
compare_pheatmap(test, cellwidth = 15, cellheight = 12, main = "Example heatmap")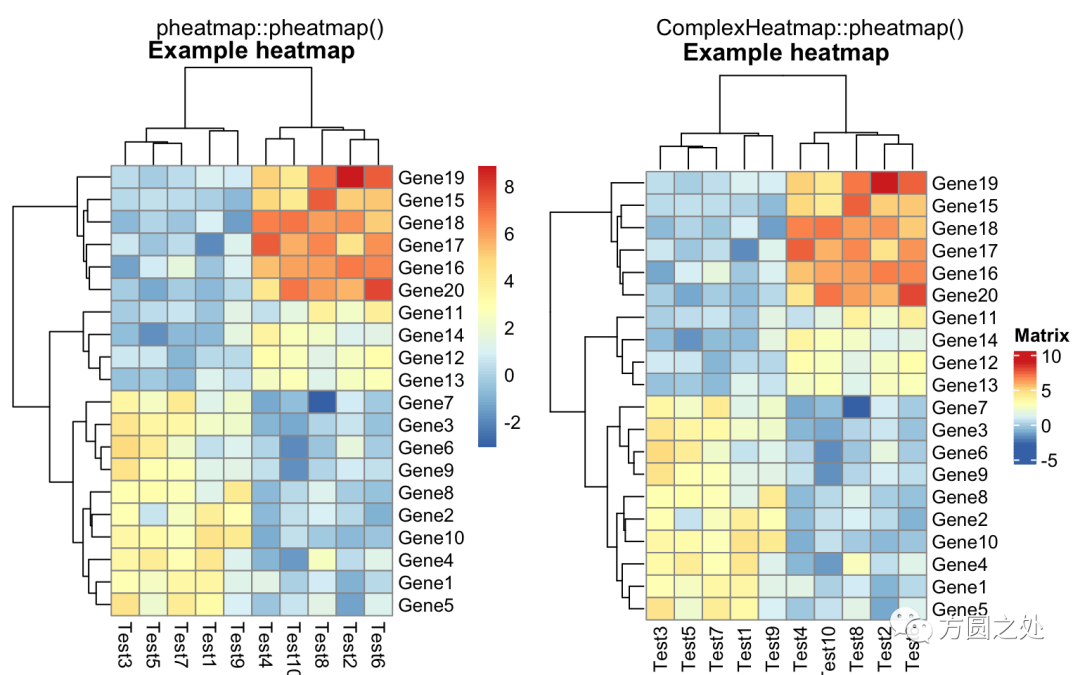
添加列的 annotation:
annotation_col = data.frame( CellType = factor(rep(c("CT1", "CT2"), 5)), Time = 1:5)rownames(annotation_col) = paste("Test", 1:10, sep = "")
annotation_row = data.frame( GeneClass = factor(rep(c("Path1", "Path2", "Path3"), c(10, 4, 6))))rownames(annotation_row) = paste("Gene", 1:20, sep = "")
compare_pheatmap(test, annotation_col = annotation_col)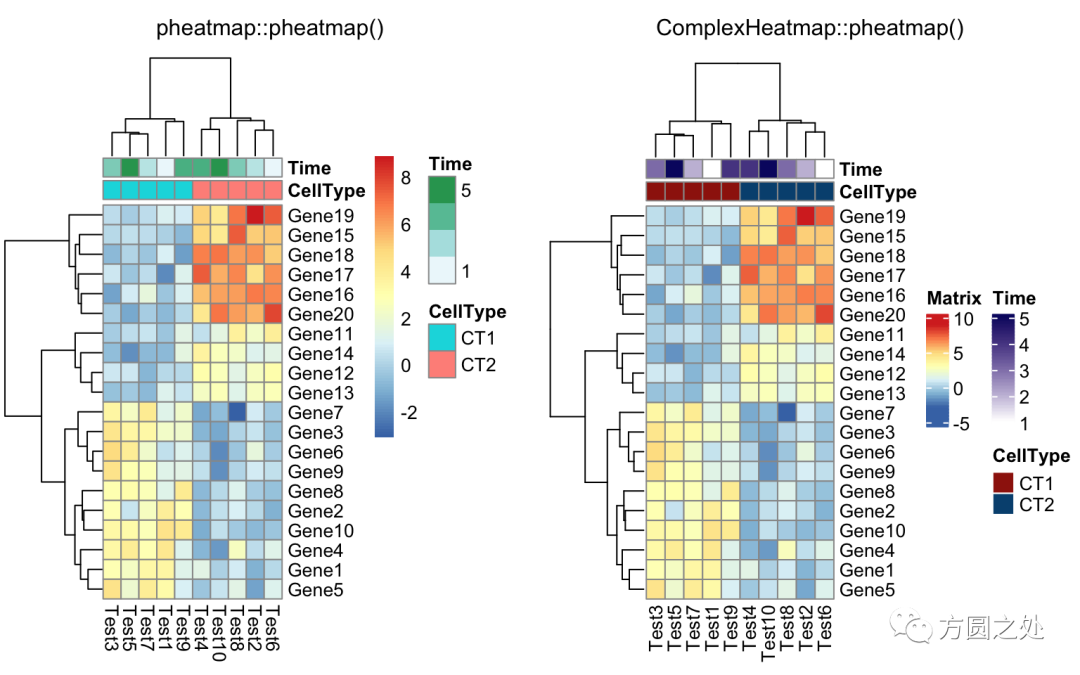
不绘制 annotation 的 legend:
compare_pheatmap(test, annotation_col = annotation_col, annotation_legend = FALSE)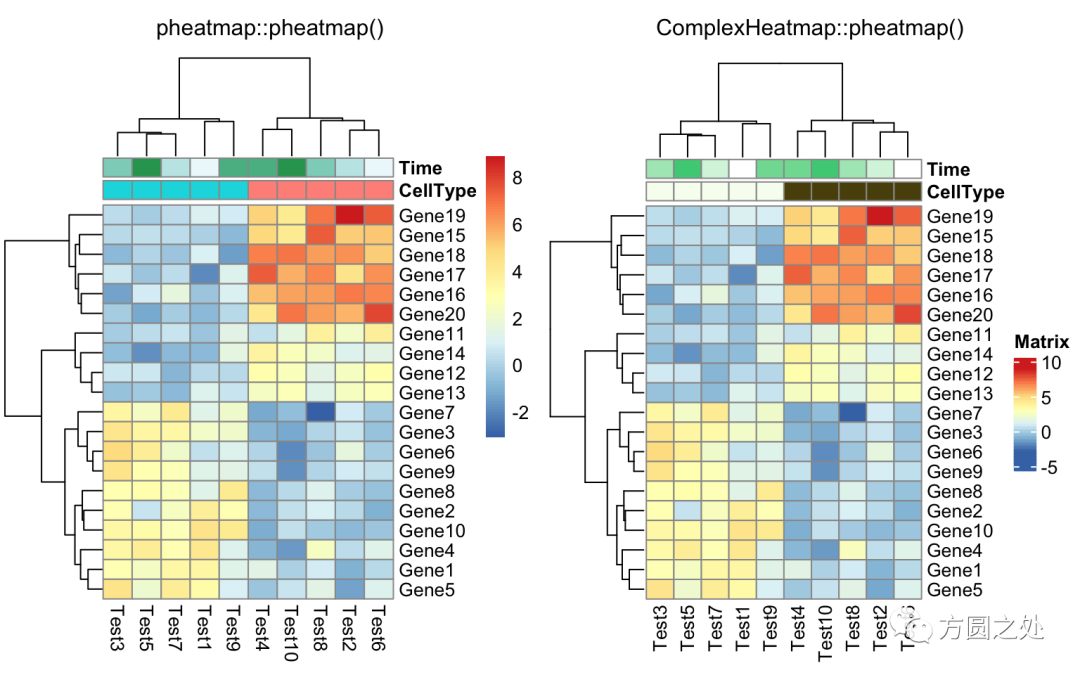
同时添加行和列的 annotation:
compare_pheatmap(test, annotation_col = annotation_col, annotation_row = annotation_row)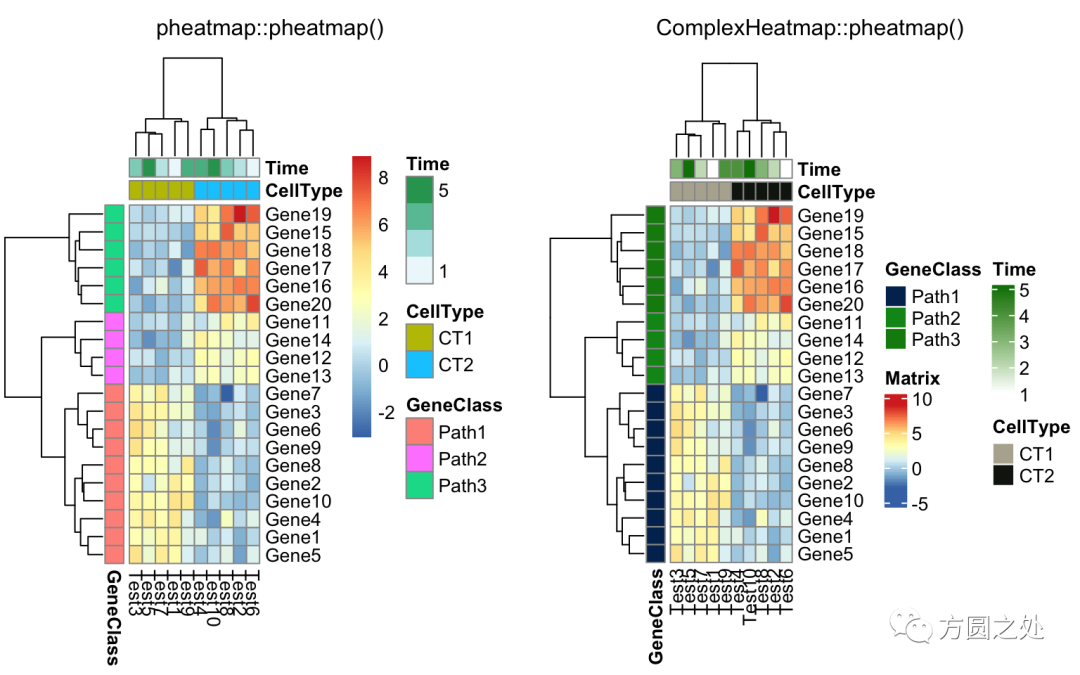
调整列名的旋转:
compare_pheatmap(test, annotation_col = annotation_col, annotation_row = annotation_row, angle_col = "45")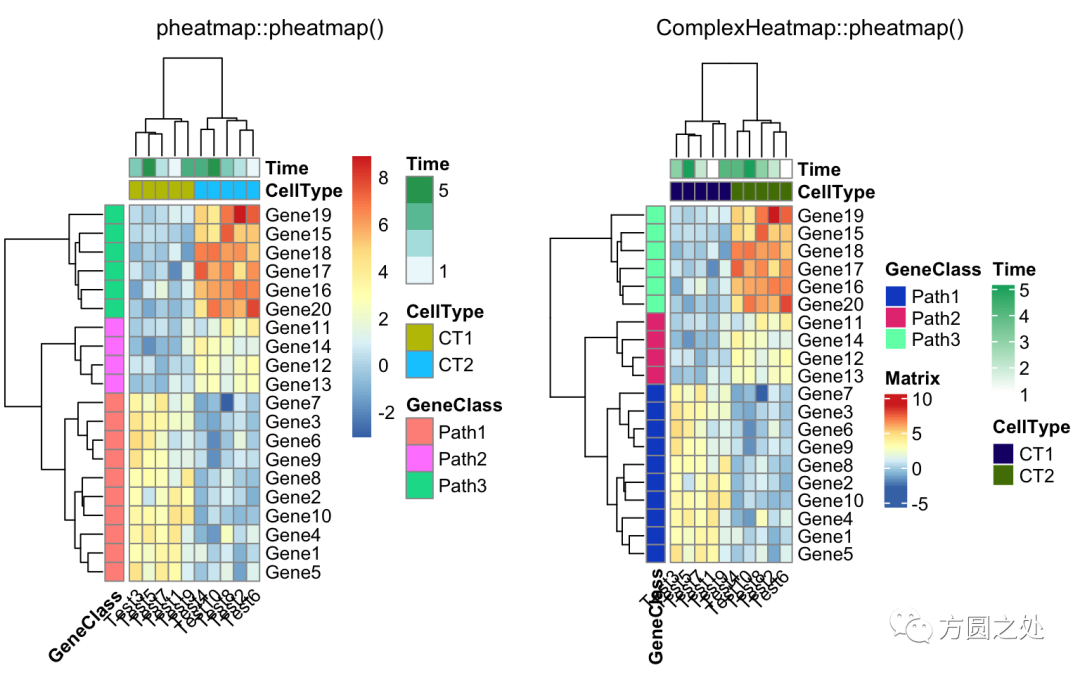
调整列名的旋转至水平方向:
compare_pheatmap(test, annotation_col = annotation_col, angle_col = "0")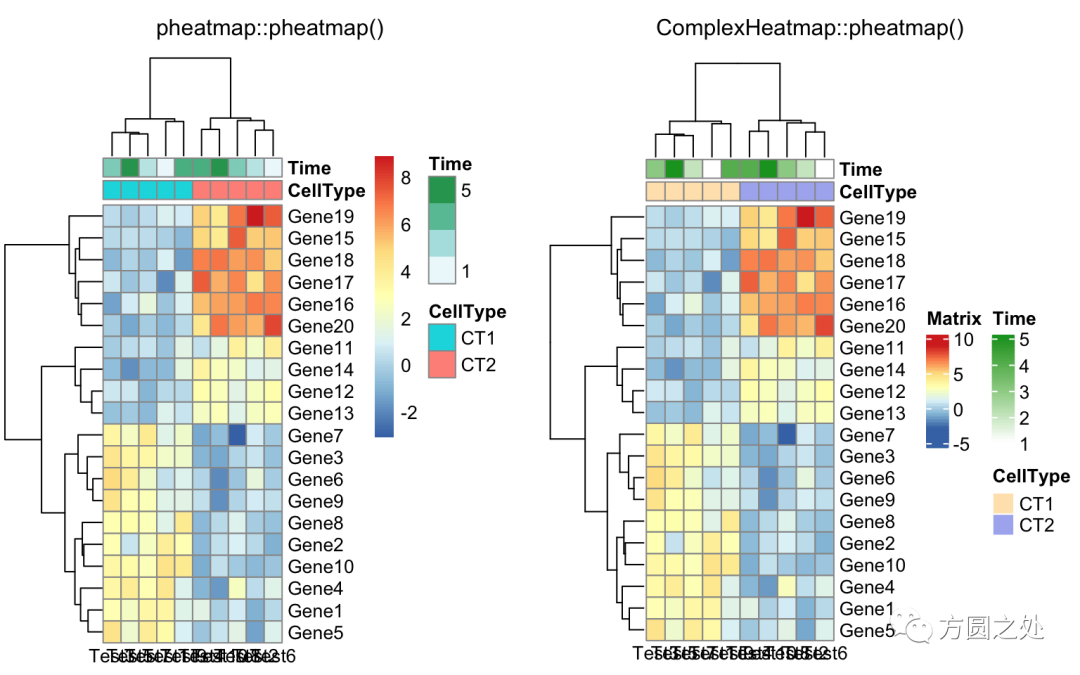
控制 annotation 的颜色:
ann_colors = list( Time = c("white", "firebrick"), CellType = c(CT1 = "#1B9E77", CT2 = "#D95F02"), GeneClass = c(Path1 = "#7570B3", Path2 = "#E7298A", Path3 = "#66A61E"))
compare_pheatmap(test, annotation_col = annotation_col, annotation_colors = ann_colors, main = "Title")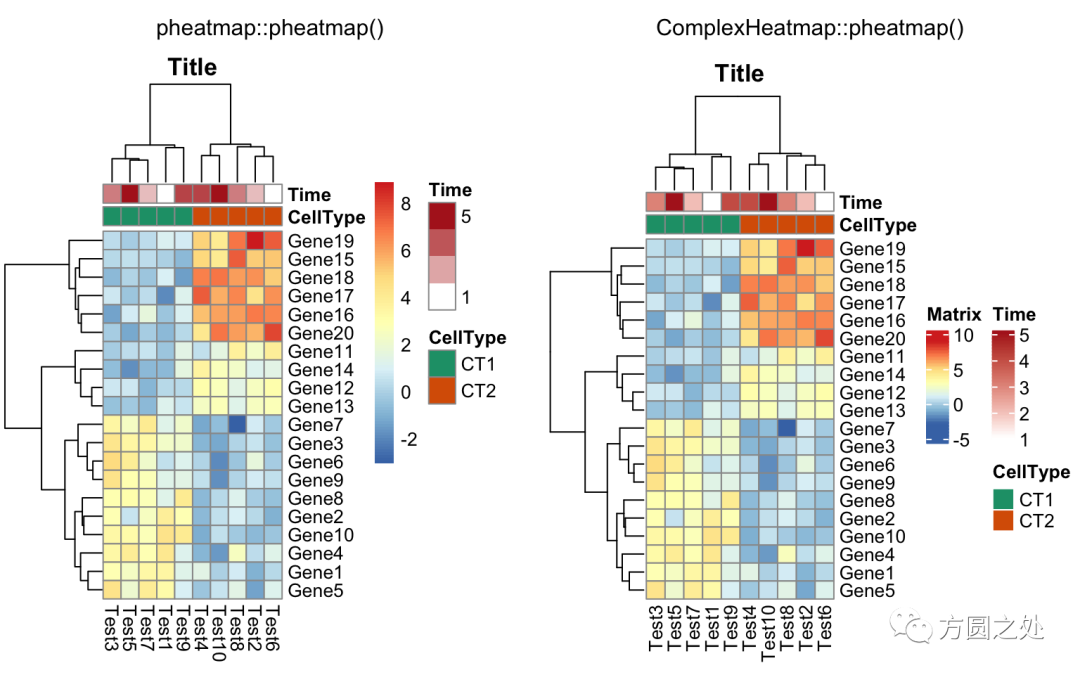
同时控制行和列 annotation 的颜色:
compare_pheatmap(test, annotation_col = annotation_col, annotation_row = annotation_row, annotation_colors = ann_colors)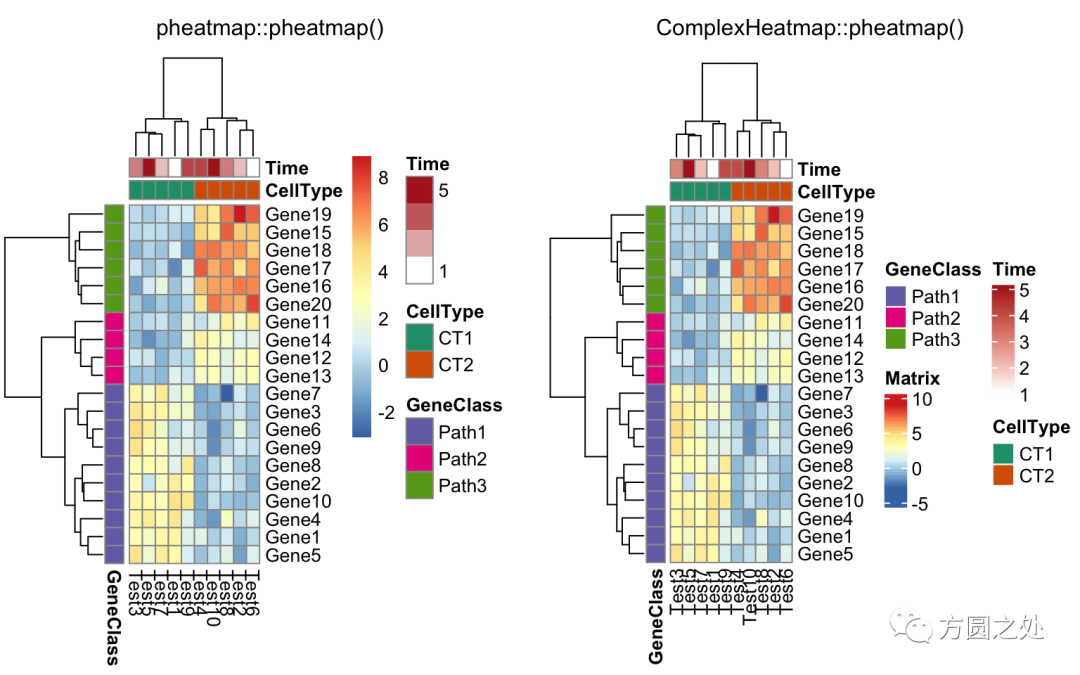
只提供部分 annotation 的颜色,未提供颜色的 annotation 使用随机颜色:
compare_pheatmap(test, annotation_col = annotation_col, annotation_colors = ann_colors[2]) 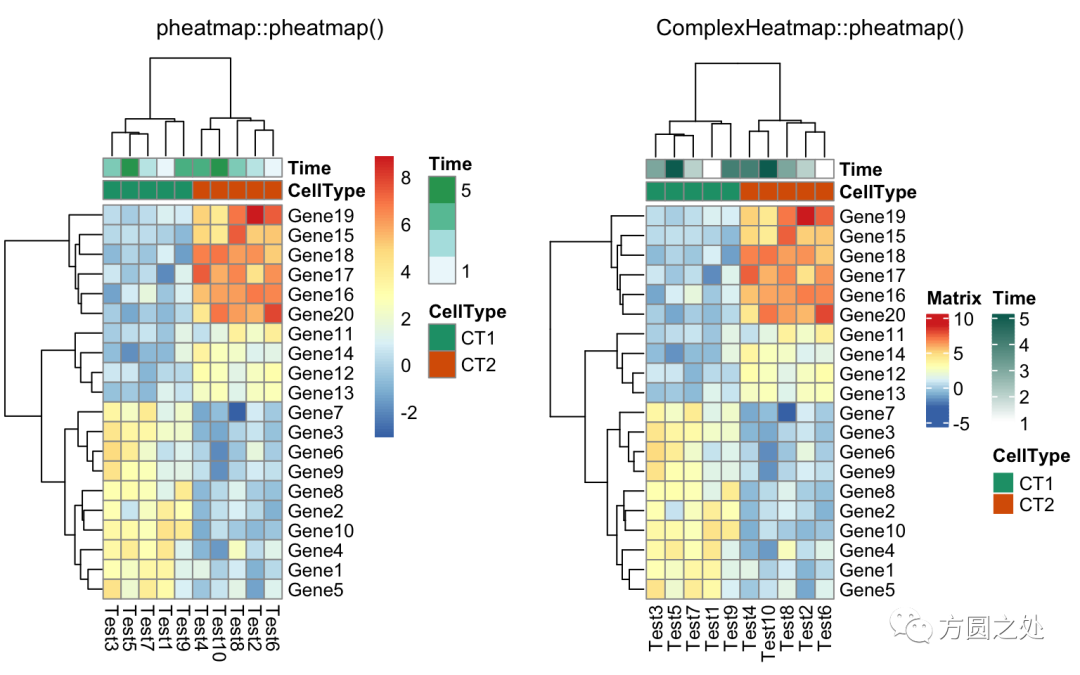
将热图分为两部分,我建议直接使用Heatmap()中的row_split或者row_km参数。
compare_pheatmap(test, annotation_col = annotation_col, cluster_rows = FALSE, gaps_row = c(10, 14))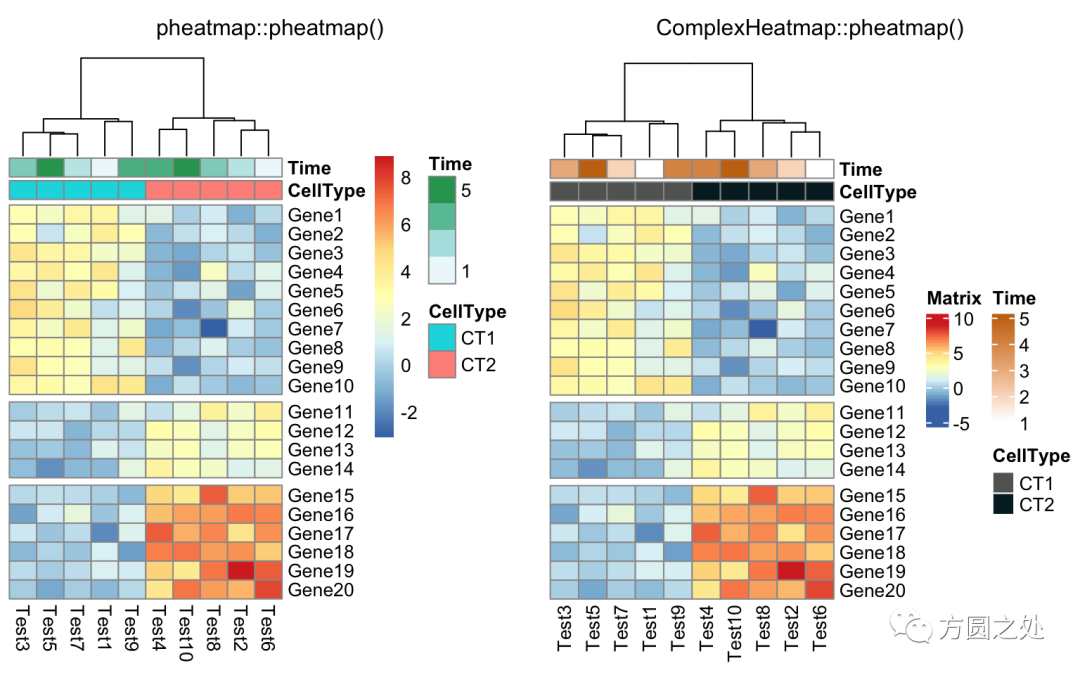
使用cutree()对列的 dendrogram 切分:
compare_pheatmap(test, annotation_col = annotation_col, cluster_rows = FALSE, gaps_row = c(10, 14), cutree_col = 2)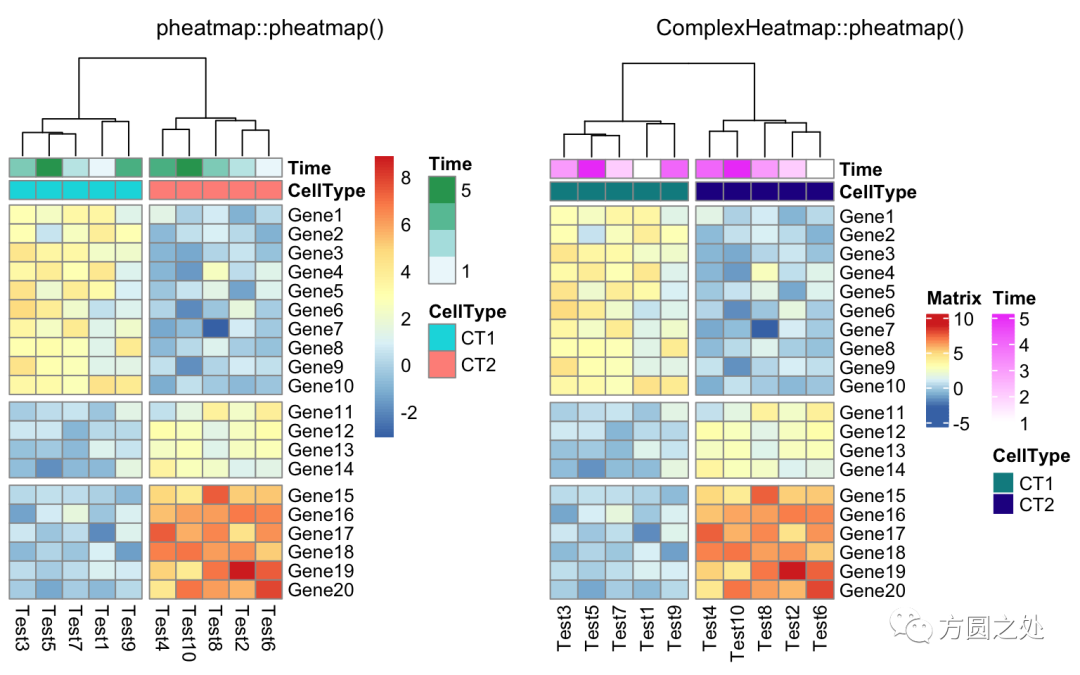
自定义行名:
labels_row = c("", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "Il10", "Il15", "Il1b")compare_pheatmap(test, annotation_col = annotation_col, labels_row = labels_row)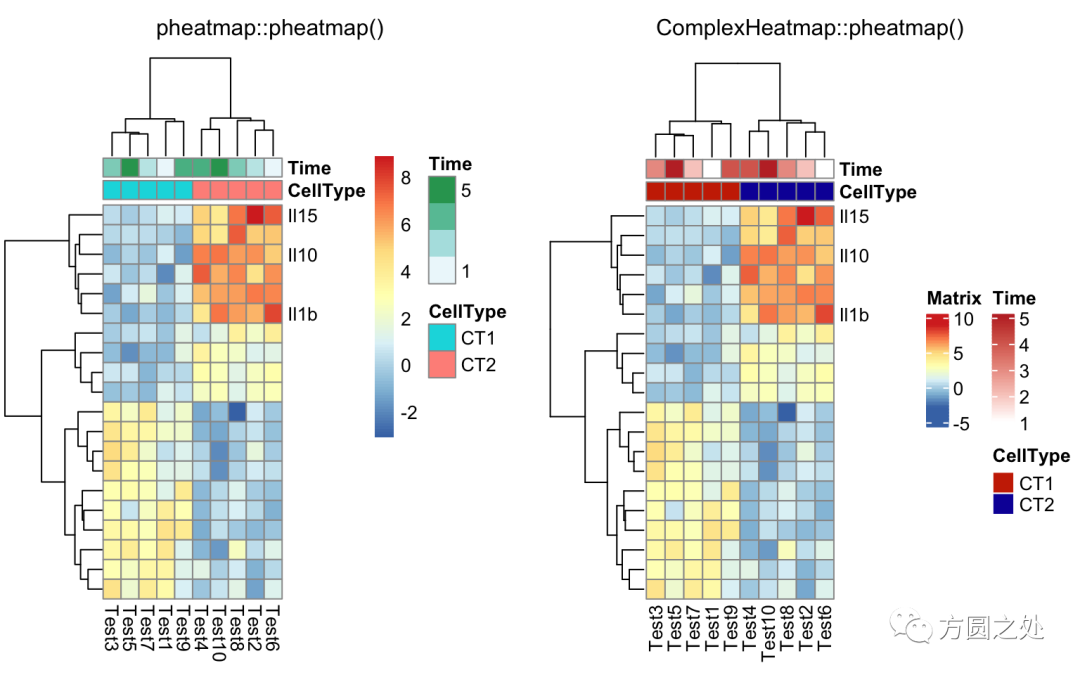
自定义聚类的距离:
drows = dist(test, method = "minkowski")dcols = dist(t(test), method = "minkowski")compare_pheatmap(test, clustering_distance_rows = drows, clustering_distance_cols = dcols)对聚类的回调处理:
library(dendsort)callback = function(hc, ...){dendsort(hc)}compare_pheatmap(test, clustering_callback = callback)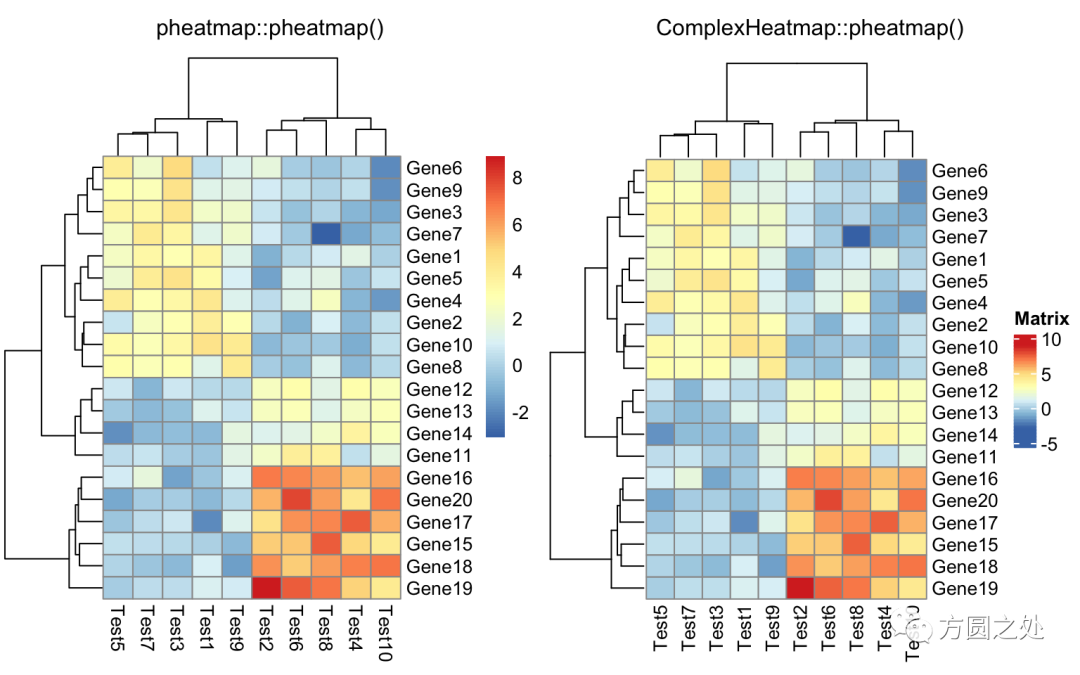
本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
从 pheatmap 无缝迁移至 ComplexHeatmap相关推荐
- 从pheatmap无缝迁移至ComplexHeatmap
pheatmap是一个非常受欢迎的绘制热图的R包.ComplexHeatmap包即是受之启发而来.你可以发现Heatmap()函数中很多参数都与pheatmap()相同.在pheatmap的时代(请允 ...
- 阿里云消息队列Kafka商业化:支持消息无缝迁移到云上
摘要: 7月25日,阿里云宣布正式推出消息队列Kafka,全面融合开源生态.在兼容Apache生态的基础上,阿里云消息队列Kafka彻底解决了开源产品稳定性不足的痛点,可用性达99.9%,数据可靠性9 ...
- Spring Cloud/Dubbo 应用无缝迁移到 Serverless 架构
背景 通过前面几节课程的学习,相信大家对于 SAE 平台已经有了一定的了解,SAE 基于 IaaS 层资源构建的一款 Serverles 应用托管产品,免除了客户很多复杂的运维工作,开箱即用.按用量付 ...
- 如何无缝迁移 SpringCloud/Dubbo 应用到 Serverless 架构
作者 | 行松 阿里巴巴云原生团队 本文整理自<Serverless 技术公开课>,"Serverless"公众号后台回复"入门",即可获取系列文章 ...
- springcloud阿里巴巴五大组件_如何无缝迁移 SpringCloud/Dubbo 应用到 Serverless 架构
简介: 本文分为三部分来介绍,分别介绍微服务应用迁移到 SAE 的优势,如何迁移 SpringCloud/Dubbo 应用到 SAE 上,以及针对 SpringCloud 应用迁移的实践演示. 背景 ...
- 成功案例 | 助力贵州省国家税务局从VMware无缝迁移至国产化安超云平台
贵州省国家税务局成立于1994年8月,是主管贵州省国家税收工作的行政机构,实行垂直领导的管理体制.贵州省国家税务局负责中央税和中央地方共享税征收管理的同时,还负责进出口税收和国际税收管理工作.2018 ...
- ThinkPad R480 C盘 固态128G 升级到 512G + 系统无缝迁移,不用重装软件
文章目录 概述 升级步骤: 1. 确定型号 2. 备份操作系统 3. 拆机更换硬盘 4. 还原操作系统 概述 我本机电脑型号ThinkPad R480 买电脑时C 盘 买的全固态盘,纯当操作系统启动盘 ...
- Kubernetes实战指南:零宕机无缝迁移Spring Cloud至k8s
1. 项目迁移背景 1.1 为什么要在"太岁"上动土? 目前公司的测试环境.UAT环境.生产环境均已经使用k8s进行维护管理,大部分项目均已完成容器化,并且已经在线上平稳运行许久. ...
- 思迅软件收银系统E店通10数据库无缝迁移导入到Eshop
思迅的E店通10,销售流水迁移至Eshop10的语句. declare m_cursor cursor scroll for select a.com_no from eStore10_xyj..t_ ...
最新文章
- 配置flutter For IOS
- [LeetCode]题解(python):087-Scramble String
- Altium Designer chapter6总结
- javaweb基础(35)_jdbc处理oracl大数据
- Linux之shell脚本(2)
- Linux系统编程30:进程信号之产生信号的四种方式(Core Dump,kill,raise)
- 网页服务器攻击,WEB服务器攻击分析全过程_91Ri.org
- 洛谷——P1909 [NOIP2016 普及组] 买铅笔
- Identity Mappings in Deep Residual Networks2016【论文理解】
- TextBar for Mac(菜单栏增强工具)支持m1
- Django 学习笔记(五) --- Ajax 传输数据
- android 语音读短信,读短信来电报姓名2021下载-读短信来电报姓名app下载10.50 安卓版-西西软件下载...
- 我的时时在线电脑(千脑)
- android抢qq红包源码,QQ抢红包插件实现,安卓源码,以及详细分析,androidqq抢红包源码,捡代码论坛整理...
- 联想微型计算机7360,我的电脑是联想启天M7360台式品牌机,想升级CPU,请问可以换什么CPU?...
- 操作系统理论:信号量机制与共享资源的并发访问问题
- 《博德之门3》的许多设计,还不如上世纪的前作
- LinkedList源码浅析
- rocketmq初学者入门
- 提升工作效率五步走之后三步 2016-09-19 刘思佳 思佳真探