Python 多进程开发与多线程开发
我们先来了解什么是进程?
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
有了进程为什么还要线程?
进程提供了多道编程,充分发挥了计算机部件的并行性,提高了计算机的利用率,既然进程这么优秀,为什么还要线程呢? 其实,还是有很多缺陷的,主要体现在两点上:
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
而解决办法就是让单个进程,接受请求、等待I/O、处理计算并行起来,这样很明显可以避免同步等待,提高执行效率,在实际操作系统中这样的机制就是——线程。
线程的优点
因 为要并发,我们发明了进程,又进一步发明了线程。只不过进程和线程的并发层次不同:进程属于在处理器这一层上提供的抽象;线程则属于在进程这个层次上再提 供了一层并发的抽象。如果我们进入计算机体系结构里,就会发现,流水线提供的也是一种并发,不过是指令级的并发。这样,流水线、线程、进程就从低到高在三 个层次上提供我们所迫切需要的并发!
除 了提高进程的并发度,线程还有个好处,就是可以有效地利用多处理器和多核计算机。现在的处理器有个趋势就是朝着多核方向发展,在没有线程之前,多核并不能 让一个进程的执行速度提高,原因还是上面所有的两点限制。但如果讲一个进程分解为若干个线程,则可以让不同的线程运行在不同的核上,从而提高了进程的执行 速度。
例如:我们经常使用微软的Word进 行文字排版,实际上就打开了多个线程。这些线程一个负责显示,一个接受键盘的输入,一个进行存盘等等。这些线程一起运行,让我们感觉到我们输入和屏幕显示 同时发生,而不是输入一些字符,过一段时间才能看到显示出来。在我们不经意间,还进行了自动存盘操作。这就是线程给我们带来的方便之处。
进程与线程的区别
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程是进程的一个实体, 是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行。
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进 程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之 间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序 健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
Python 多进程(multiprocessing)
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
|
1
2
3
4
5
6
7
8
9
|
# multiprocessing.py
import os
print 'Process (%s) start...' % os.getpid()
pid = os.fork()
if pid==0:
print 'I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid())
else:
print 'I (%s) just created a child process (%s).' % (os.getpid(), pid)
|
由于Windows没有fork调用,上面的代码在Windows上无法运行。
multiprocessing
multiprocessing是跨平台版本的多进程模块,它提供了一个Process类来代表一个进程对象,下面是示例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
from multiprocessing import Process
import time
def f(n):
time.sleep(1)
print n*n
for i in range(10):
p = Process(target=f,args=[i,])
p.start()
|
这个程序如果用单进程写则需要执行10秒以上的时间,而用多进程则启动10个进程并行执行,只需要用1秒多的时间。
在一般情况下多个进程的内存资源是相互独立的,而多线程可以共享同一个进程中的内存资源,示例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
# 通过多进程和多线程对比,进程间内存无法共享,线程间的内存共享
from multiprocessing import Process
import threading
import time
lock = threading.Lock()
def run(info_list,n):
lock.acquire()
info_list.append(n)
lock.release()
print('%s\n' % info_list)
info = []
for i in range(10):
'''target为子进程执行的函数,args为需要给函数传递的参数'''
p = Process(target=run,args=[info,i])
p.start()
'''这里是为了输出整齐让主进程的执行等一下子进程'''
time.sleep(1)
print('------------threading--------------')
for i in range(10):
p = threading.Thread(target=run,args=[info,i])
p.start()
|
执行结果:
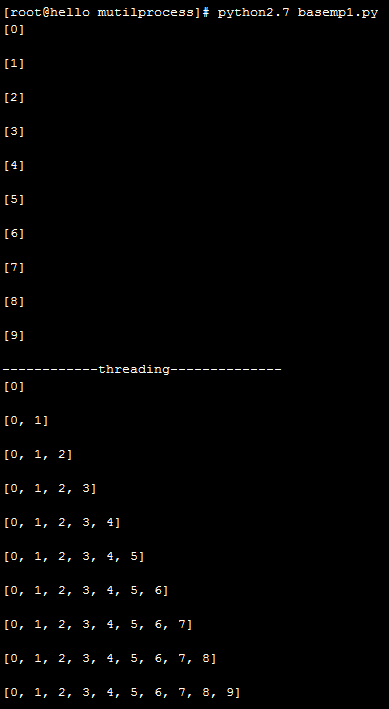
进程间通信
Queue
Queue 是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和 timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。 如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
get 方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且 timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果 Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常。Queue的一段示例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
# 通过multiprocessing.Queue实现进程间内存共享
from multiprocessing import Process,Queue
import time
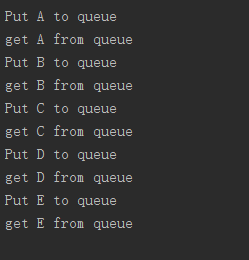
def write(q):
for i in ['A','B','C','D','E']:
print('Put %s to queue' % i)
q.put(i)
time.sleep(0.5)
def read(q):
while True:
v = q.get(True)
print('get %s from queue' %v)
if __name__ == '__main__':
q = Queue()
pw = Process(target=write,args=(q,))
pr = Process(target=read,args=(q,))
pw.start()
pr.start()
pr.join()
pr.terminate()
|
执行结果:
Value,Array
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
# 通过Value Array 实现进程间的内存共享
from multiprocessing import Value,Array,Process
def f(n,a,raw):
n.value = 3.14
for i in range(5):
a[i] = -a[i]
raw.append(9999)
print(raw)
if __name__ == '__main__':
num = Value('d',0.0)
arr = Array('i',range(10))
raw_list = range(10)
print(num.value)
print(arr[:])
print(raw_list)
#调用子进程之后,重新打印array和value,值将会发生改变。 而raw_list 普通列表在外层打印则没有发生改变。
p = Process(target=f,args=(num,arr,raw_list))
p.start()
p.join()
print(num.value)
print(arr[:])
print(raw_list)
|
执行结果:

Manager
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
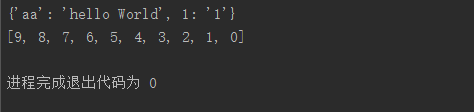
from multiprocessing import Process,Manager
def f(d,l):
d[1] = '1'
d['aa'] = 'hello World'
l.reverse()
if __name__ == '__main__':
manager = Manager()
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f,args=(d,l))
p.start()
p.join()
print(d)
print(l)
|
执行结果:
Pool (进程池)
用于批量创建子进程,可以灵活控制子进程的数量
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
from multiprocessing import Pool
import time
def f(x):
print x*x
time.sleep(2)
return x*x
'''定义启动的进程数量'''
pool = Pool(processes=5)
res_list = []
for i in range(10):
'''以异步并行的方式启动进程,如果要同步等待的方式,可以在每次启动进程之后调用res.get()方法,也可以使用Pool.apply'''
res = pool.apply_async(f,[i,])
print('-------:',i)
res_list.append(res)
pool.close()
pool.join()
for r in res_list:
print(r.get(timeout=5))
|
Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
Python 多线程(threading)
上面介绍了线程的作用,在python的标准库中提供了两个模块:thread和threading,threading是对thread进行了封装的高级模块。启动一个线程就是把一个函数传给Thread实例,然后调用start()方法。
先来看一个示例程序:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
from threading import Thread
import time
def f(n):
time.sleep(1)
num = n*n
print('%s\n' % num)
l1 = range(10)
for i in l1:
p = Thread(target=f,args=(i,))
p.start()
|
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
示例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
import time, threading
balance = 0
def change_it(n):
# 先加后减,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print balance
|
定义的这个balance最后执行结果理论上是0,但是多个线程交替执行时就不一定是0了,因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致数据不对,如果要确保balance计算正确,就需要给change_i()上一把锁,确保一个线程在修改balance的时候,别的线程一定不能改。
下面看示例代码,创建锁通过threading.Lock()来实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
import time, threading
balance = 0
lock = threading.Lock()
def change_it(n):
# 先加后减,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
lock.acquire()
try:
change_it(n)
finally:
lock.release()
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print balance
|
生产者消费者模型
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
from threading import Thread
from Queue import Queue
import time
class procuder(Thread):
'''
@:param name:生产者名称
@:param queue:容器
'''
def __init__(self,name,queue):
self.__Name = name
self.__Queue = queue
super(procuder,self).__init__()
def run(self):
while True:
if self.__Queue.full():
time.sleep(1)
else:
self.__Queue.put('baozi')
time.sleep(1)
print('%s 生产了一个包子' %(self.__Name))
class consumer(Thread):
def __init__(self,name,queue):
self.__Name = name
self.__Queue = queue
'''执行父类的构造方法'''
super(consumer,self).__init__()
def run(self):
while True:
if self.__Queue.empty():
time.sleep(1)
else:
self.__Queue.get()
time.sleep(1)
print('%s 吃了一个包子' %(self.__Name))
que = Queue(maxsize=100)
tuchao1 = procuder('小涂1',que)
tuchao1.start()
tuchao2 = procuder('小涂2',que)
tuchao2.start()
tuchao3 = procuder('小涂3',que)
tuchao3.start()
for i in range(20):
name = '小喻%d' %(i,)
temp = consumer(name,que)
temp.start()
|
python 多线程开发之事件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
#!/usr/local/python27/bin/python2.7
# coding=utf8
# noinspection PyUnresolvedReferences
import threading
import time
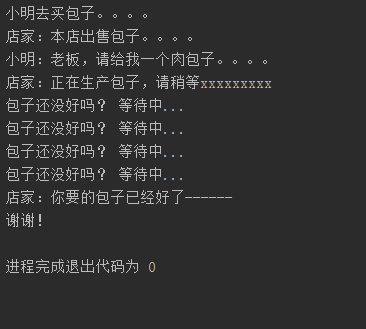
def producer():
print ('店家:本店出售包子。。。。')
'''触发事务等待'''
event.wait()
'''清楚事务状态'''
event.clear()
print ('小明:老板,请给我一个肉包子。。。。')
print ('店家:正在生产包子,请稍等xxxxxxxxx')
time.sleep(6)
print ('店家:你要的包子已经好了------')
event.set()
def consumer():
print('小明去买包子。。。。')
'''解除事务等待'''
event.set()
time.sleep(2)
while True:
if event.isSet():
print ('谢谢!')
break
else:
print ('包子还没好吗? 等待中...')
time.sleep(1)
event = threading.Event()
p = threading.Thread(target=producer)
c = threading.Thread(target=consumer)
c.start()
p.start()
|
执行结果:
GIL锁(Global Interpreter Lock)
Python 的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL 全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
参考文献:
http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143192823818768cd506abbc94eb5916192364506fa5d000
http://www.cnblogs.com/hazir/archive/2011/05/09/2447287.html
转载于:https://blog.51cto.com/lancger/1721856
Python 多进程开发与多线程开发相关推荐
- python 多进程并发与多线程并发总结
本文对python支持的几种并发方式进行简单的总结. Python支持的并发分为多线程并发与多进程并发(异步IO本文不涉及).概念上来说,多进程并发即运行多个独立的程序,优势在于并发处理的任务都由操作 ...
- iOS开发-多线程开发之线程安全篇
前言:一块资源可能会被多个线程共享,也就是多个线程可能会访问同一块资源,比如多个线程访问同一个对象.同一个变量.同一个文件和同一个方法等.因此当多个线程访问同一块资源时,很容易会发生数据错误及数据不安 ...
- Python多进程(process)和多线程(thread)的区别
目录 一.线程与进程 1.基本概念 2.区别 二.多进程与多线程 1.多进程 (1)Python的多进程编程与multiprocess模块 (2)利用multiprocess模块的Pool类创建多进程 ...
- python multithreading_操作系统OS,Python - 多进程(multiprocessing)、多线程(multithreading)...
多进程(multiprocessing) 参考: 1. 多进程概念 multiprocessing is a package that supports spawning processes usin ...
- iOS开发-多线程编程技术(Thread、Cocoa operations、GCD)
简介 在软件开发中,多线程编程技术被广泛应用,相信多线程任务对我们来说已经不再陌生了.有了多线程技术,我们可以同做多个事情,而不是一个一个任务地进行.比如:前端和后台作交互.大任务(需要耗费一定的时间 ...
- Java/Android 进程与线程之 多线程开发(二)
多线程开发 Java多线程开发 1.线程状态 线程阻塞 线程协作 作用 **wait() / notify** **join()** **Thread.sleep()** wait 与 sleep 的 ...
- python守护多线程_Python守护进程(多线程开发)入门实例
这篇文章主要为大家详细介绍了Python守护进程(多线程开发)入门实例,具有一定的参考价值,可以用来参考一下. 对python这个高级语言感兴趣的小伙伴,下面一起跟随512笔记的小编两巴掌来看看吧! ...
- 熟练掌握skynet,后端开发丨游戏开发轻松搞定丨多线程丨多进程
掌握skynet,后端开发原来如此简单 1. 多线程 2. 多进程 3. actor模型-skynet 4. csp模型 [技术分享篇]熟练掌握skynet,后端开发丨游戏开发轻松搞定丨多线程丨多进程 ...
- Python学习笔记:多线程和多进程(转1)
前言 最近在学习深度学习,已经跑出了几个模型,但Pyhton的基础不够扎实,因此,开始补习Python了,大家都推荐廖雪峰的课程,因此,开始了学习,但光学有没有用,还要和大家讨论一下,因此,写下这些帖 ...
最新文章
- [Android]使用RecyclerView替代ListView(四:SeizeRecyclerView)
- 获取socket对应的接收缓冲区中的可读数据量
- java表达式语句_Java基础知识笔记第三章:运算符表达式语句
- html静态网页模板cs4,Adobe Dreamweaver CS4 精简版
- java netty modbus协议接收iot数据
- 自建服务器打印机,关于Windows 2016 Server创建打印机服务器后对打印机设置权限的问题...
- AI在中国,还没到抢切蛋糕的时候
- 南加大计算机科学博士,美国南加州大学计算机科学博士专业介绍
- 摩拜单车的节能黑科技
- 2010年总结机器人领域sci期刊杂志
- Desktoppr与 Dropbox国内成功使用
- 激活函数 ReLU、sigmoid、tanh(双曲正切)
- 力扣OJ 剑指 Offer(1-30)
- JAVA入门-024(int的正负数)
- 同时设置min-height和max-height后el-scrollbar滚动监听失效?
- 用通道法抠出外国MM的头发 - PS通道抠图教程
- 函数的可重入和不可重入
- 日乒赛-马龙爆冷止步次轮 朱雨玲陈梦率先进8强
- linux电脑自启动,caddyserver在linux系统下设置开机启动
- 揭秘 · 阿里云第一女神 — 清宵