基于Spark ML 聚类分析实战的KMeans
2019独角兽企业重金招聘Python工程师标准>>> 
聚类分析是一个无监督学习 (Unsupervised Learning) 过程, 一般是用来对数据对象按照其特征属性进行分组,经常被应用在客户分群,欺诈检测,图像分析等领域。K-means 应该是最有名并且最经常使用的聚类算法了,其原理比较容易理解,并且聚类效果良好,有着广泛的使用。目前Spark ML支持四种聚类算法,Kmeans, Bisecting k-means(二分k均值算法),GMMs(高斯混合模型),LDA(主题模型算法)。
1、K均值(K-means)算法
K-means是一个常用的聚类算法,将数据点按预定的簇数进行聚集。
K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为c个类别,算法描述如下:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
使用FEA-spk技术Kmeans的可调参数如下
k 表示期望的聚类的个数。默认为2
maxIter表示方法单次运行最大的迭代次数。默认为20
initMode 表示初始聚类中心点的选择方式, 目前支持随机选择或者 K-means||方式默认是 K-means||。
initSteps表示 K-means||方法中的部数。默认是5
tol表示 K-means 算法迭代收敛的阀值。默认是1e-4
seed 表示集群初始化时的随机种子。默认为None
2、使用FEA-spk技术来实现聚类算法
FEA-spk技术,它的底层基于最流行的大数据开发框架spark,对各种算子的操作都是基于DataFrame的,使用FEA-spk来做交互分析,不但非常简单易懂,而且几乎和spark的功能一样强大,更重要的一点,它可以实现可视化,处理的数据规模更大,可以进行分布式的机器学习等。
3、聚类测试数据集简介
在本文中,我们所用到目标数据集是来自 UCI Machine Learning Repository 的
Wholesale customer Data Set。UCI 是一个关于机器学习测试数据的下载中心站点,里面包含了适用于做聚类,分群,回归等各种机器学习问题的数据集。Wholesale customer Data Set 是引用某批发经销商的客户在各种类别产品上的年消费数。
4、案例分析和原语实现
本例中,我们将根据目标客户的消费数据,将每一列视为一个特征指标,对数据集进行聚类分析。具体的步骤如下所示
(1) 创建spk的连接,加载存放在hdfs的CSV数据集
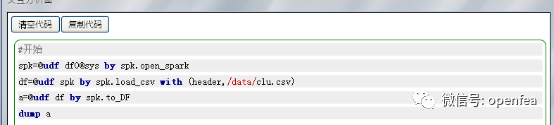
可以看到数据的格式如图所示
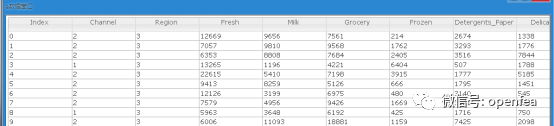
(2) 将df表的所有列都转化为double类型


(3) 进行聚类分析


(4) 对模型进行打分,评估这个模型好坏

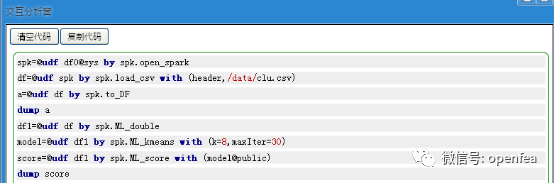

对参数进行调试的时候,这个值是越小越好
(5) 将训练好的模型保存在hdfs上面,方便用户进行使用


(6) 将hdfs上面保存的模型加载下来,进行预测
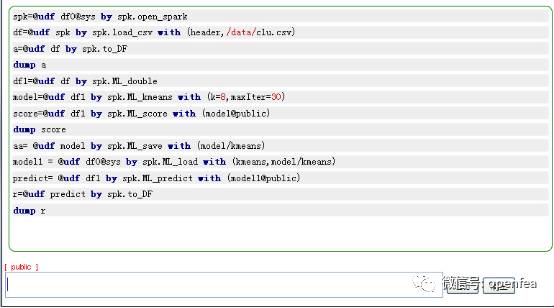
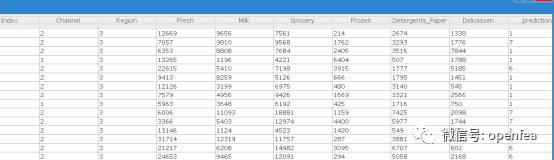
其中prediction列就是预测后的结果。
5、总结
通过本文的学习,读者已经初步了解了 FEA-spk的使用,并且掌握了 K-means 算法的基本原理,以及如何基于 FEA-spk构建自己的机器学习应用。机器学习应用的构建是一个复杂的过程,我们通常还需要对数据进行预处理,然后特征提取以及数据清洗等,然后才能利用算法来分析数据。Spark MLlib 区别于传统的机器学习工具,不仅是因为它提供了简单易用的 API,更重要的是 Spark 在处理大数据上的高效以及在迭代计算时的独特优势。
转载于:https://my.oschina.net/u/3115904/blog/1537749
基于Spark ML 聚类分析实战的KMeans相关推荐
- spark 逻辑回归算法案例_黄美灵的Spark ML机器学习实战
原标题:黄美灵的Spark ML机器学习实战 本课程主要讲解基于Spark 2.x的ML,ML是相比MLlib更高级的机器学习库,相比MLlib更加高效.快捷:ML实现了常用的机器学习,如:聚类.分类 ...
- 基于 spark ml NaiveBayes实现中文文本分类
思路: 1 准备数据 2,代码编写 准备数据 这里数据我将它分为两类, 1 军事,2 nba , 我将文件数据放在下面 代码编写: 这里面我用的是spark ml 进行代码的 ...
- python 聚类分析实战案例:K-means算法(原理源码)
K-means算法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xvV44zrK-1573127992123)(https://img-blog.csdn.net/ ...
- python聚类分析案例_python 聚类分析实战案例:K-means算法(原理源码)
K-means算法: 关于步骤:参考之前的博客 关于代码与数据:暂时整理代码如下:后期会附上github地址,上传原始数据与代码完整版, 各种聚类算法的对比:参考连接 Kmeans算法的缺陷 1.聚类 ...
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- Spark ML - 聚类算法
http://ihoge.cn/2018/ML2.html Spark ML - 聚类算法 1.KMeans快速聚类 首先到UR需要的包: import org.apache.spark.ml.clu ...
- Spark大数据分析与实战:基于Spark MLlib 实现音乐推荐
Spark大数据分析与实战:基于Spark MLlib 实现音乐推荐 基于Spark MLlib 实现音乐推荐 一.实验背景: 熟悉 Audioscrobbler 数据集 基于该数据集选择合适的 ML ...
- 基于Spark的机器学习实践 (三) - 实战环境搭建
0 相关源码 1 Spark环境安装 ◆ Spark 由scala语言编写,提供多种语言接口,需要JVM ◆ 官方为我们提供了Spark 编译好的版本,可以不必进行手动编译 ◆ Spark安装不难,配 ...
- [收藏]基于Spark Graphframes的社交关系图谱项目实战
大家好,我是老兵. 本文是基于Spark Graphframes的社交关系图谱实战演练. 我将结合自身开发和项目经验,分别讲述社交关系图谱原理.图计算原理.Spark Graphframes图计算编程 ...
最新文章
- html5头像裁剪实例,使用cropper.js裁剪头像的实例代码
- 每日一皮:这也许是稍微二字最好的诠释...
- Python进阶03 模块
- GMGridView cell button
- 电脑如何进入bios模式_电脑如何进入bios关闭软驱
- SAP UI5 初学者教程之二:SAP UI5 的引导过程(Bootstrap) 试读版
- 参数调优为什么要采样_程序员精进之路:性能调优利器--火焰图
- mysql 导出csv 多列_从包含300多列的csv,txt或xls文件创建MySQL表
- 聚类方法:DBSCAN算法研究
- rplidar 启动马达 c++_【玩码】刘作虎:一加7 Pro的横向线性马达,为安卓手机最大...
- 表达式求值(NOIP2013 普及组第二题)
- WMI 查询分析工具更新
- java byte数组打印
- wps2019怎么调整字间距_wps2019表格和文字间距太大怎么调整?
- 【独行秀才】macOS Monterey 12.0 Beta4(21A5294g)原版镜像
- 两台电脑共享宽带的方法
- mybatis一个怪异的问题: Invalid bound statement not found 作者及来源: babyblue - 博客园 收藏到→_→: 摘要: mybatis一个怪异
- 金蝶云苍穹查找目标单
- css 选父元素,CSS中模拟父元素选择器
- 川大计算机系导师,川大计算机学院硕士生导师简介