python大数据分析实例-Python大数据处理案例
编辑推荐:
来源于cnblogs,介绍了利用决策树分类,利用随机森林预测,
利用对数进行fit,和exp函数还原等。
分享

知识要点:
lubridate包拆解时间 | POSIXlt
利用决策树分类,利用随机森林预测
利用对数进行fit,和exp函数还原
训练集来自Kaggle华盛顿自行车共享计划中的自行车租赁数据,分析共享自行车与天气、时间等关系。数据集共11个变量,10000多行数据。
https://www.kaggle.com/c/bike-sharing-demand
首先看一下官方给出的数据,一共两个表格,都是2011-2012年的数据,区别是Test文件是每个月的日期都是全的,但是没有注册用户和随意用户。而Train文件是每个月只有1-20天,但有两类用户的数量。
求解:补全Train文件里21-30号的用户数量。评价标准是预测与真实数量的比较。

1.png
首先加载文件和包
library (lubridate)
library (randomForest)
library (readr)
setwd ("E:")
data <-read_csv ("train.csv")
head (data)
这里我就遇到坑了,用r语言缺省的read.csv死活读不出来正确的文件格式,换成xlsx更惨,所有时间都变成43045这样的怪数字。本来之前试过as.Date可以正确转换,但这次因为有时分秒,就只能用时间戳,但结果也不行。
最后是下载了"readr"包,用read_csv语句,顺利解读。
因为test比train日期完整,但缺少用户数,所以要把train和test合并。
test$registered=0
test$casual=0
test$count=0
data<-rbind(train,test)
摘取时间:可以用时间戳,这里的时间比较简单,就是小时数,所以也可以直接截字符串。
data$hour1<-substr
(data$datetime,12,13)
table(data$hour1)
统计一下每个小时的使用总数,是这样(为什么介么整齐):

6-hour1.png
接下来是运用箱线图,看一下使用者和时间,周几这些的关系。为什么用箱线图而不用hist直方图,因为箱线图有离散点表达,下面也因此运用对数求fit
从图中可以看出,在时间方面,注册用户和非注册用户的使用时间有很大不同。
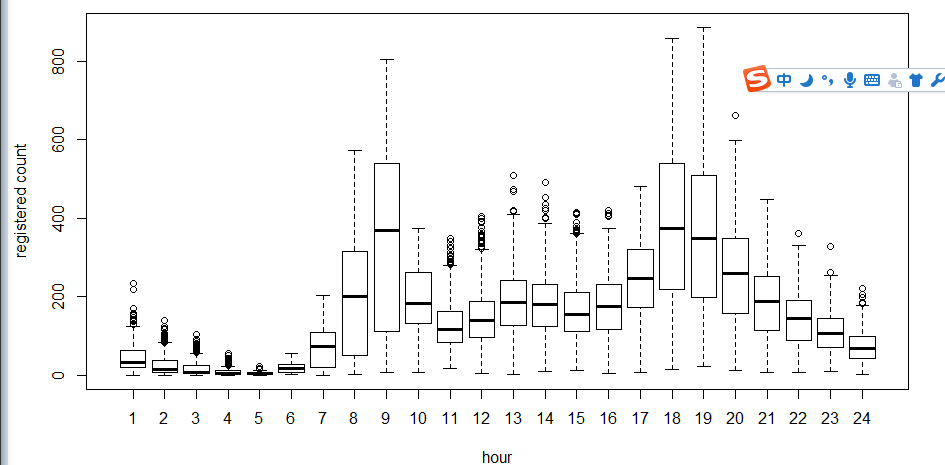
5-hour-regestered.png
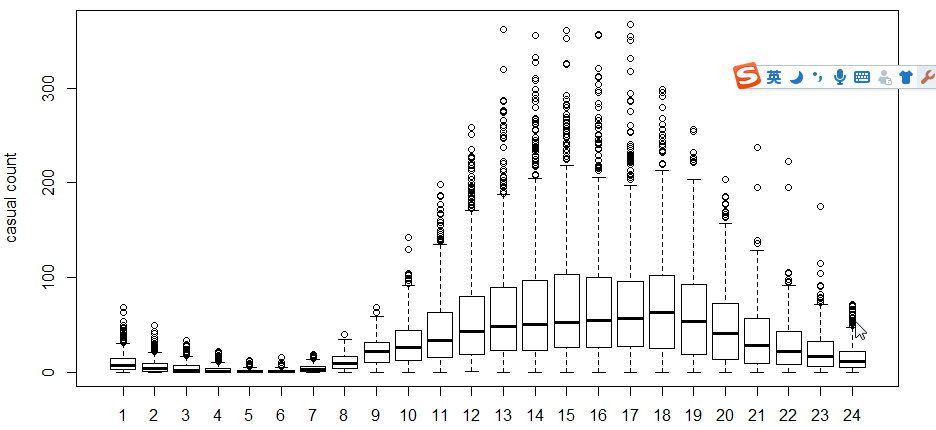
5-hour-casual.png
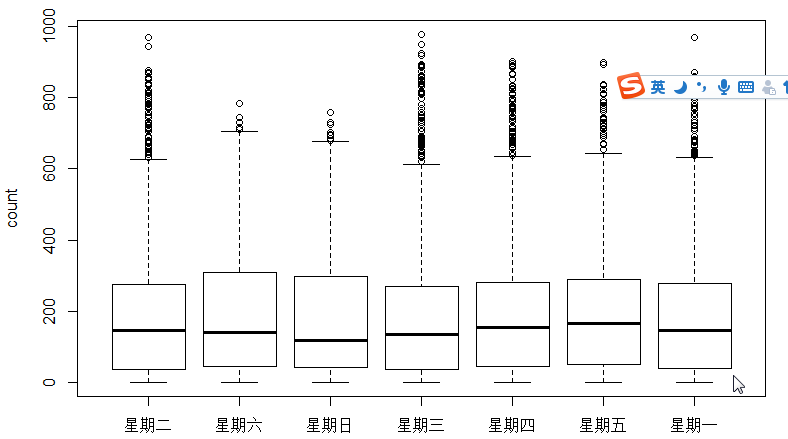
4-boxplot-day.png
接下来用相关系数cor检验用户,温度,体感温度,湿度,风速的关系。
相关系数:变量之间的线性关联度量,检验不同数据的相关程度。
取值范围[-1,1],越接近0越不相关。
从运算结果可以看出,使用人群与风速呈负相关,比温度影响还大。

cor.png
接下来就是将时间等因素用决策树分类,然后用随机森林来预测。随机森林和决策树的算法。听起来很高大上,其实现在也很常用了,所以一定要学会。
决策树模型是 一种简单易用的非参数分类器。它不需要对数据有任何的先验假设,计算速度较快,结果容易解释,而且稳健性强,不怕噪声数据和缺失数据。
决策树模型的基本计 算步骤如下:先从n个自变量中挑选一个,寻找最佳分割点,将数据划分为两组。针对分组后数据,将上述步骤重复下去,直到满足某种条件。
在决策树建模中需要解决的重要问题有三个:
如何选择自变量
如何选择分割点
确定停止划分的条件
做出注册用户和小时的决策树,
train$hour1<-as.integer(train$hour1)
d<-rpart (registered~hour1,data=train)
rpart .plot(d) >
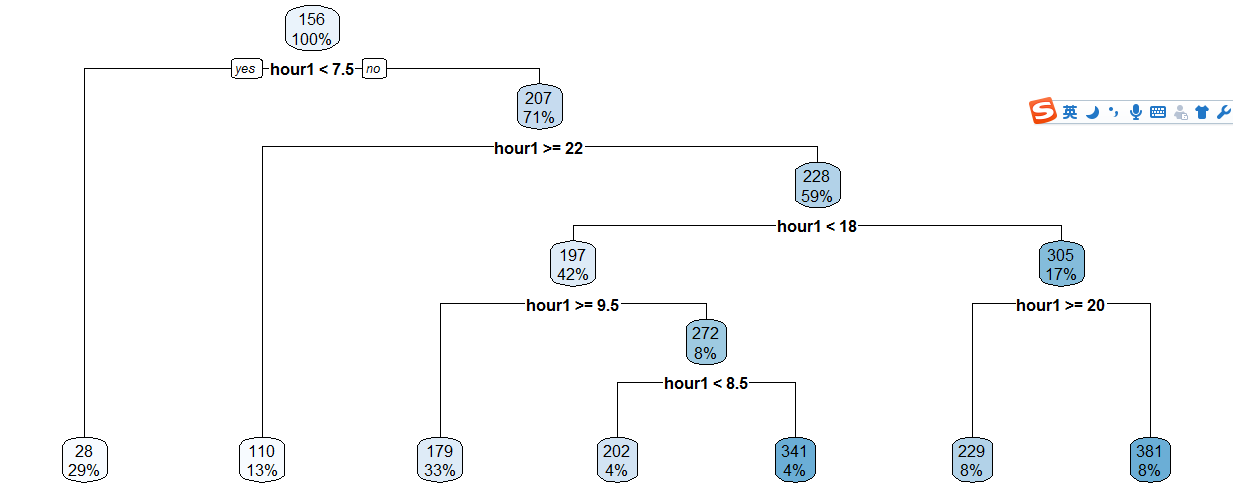
3-raprt-hour1.png
然后就是根据决策树的结果手动分类,所以还满占代码的...
train$hour1
<-as.integer(train$hour1)
data$dp_reg=0
data$dp_reg[data$hour1 <7.5]=1
data$dp_reg[data$hour1> =22]=2
data$dp_reg[data$hour1 >=9.5 & data$hour1<18]=3
data$dp_reg[data$hour1> =7.5 & data$hour1<18]=4
data$dp_reg[data$hour1> =8.5 & data$hour1<18]=5
data$dp_reg[data$hour1> =20 & data$hour1<20]=6
data$dp_reg[data$hour1> =18 & data$hour1<20]=7
同理,做出 (小时 | 温度) X (注册 | 随意用户) 等决策树,继续手动分类....
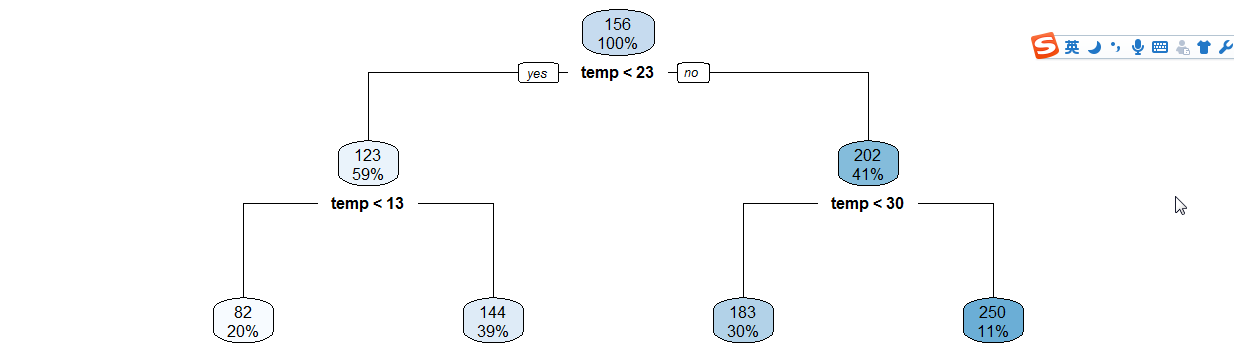
3-raprt-temp.png
年份月份,周末假日等手动分类
data$year_part=0
data$month <-month(data$datatime)
data$year_part [data$year=='2011']=1
data$year_part [data$year=='2011' & data $month>3]
= 2
data$year_part[data$year=='2011' & data $month>6]
= 3
data$year_part[data$year=='2011' & data $month>9]
= 4
data$day_type=""
data$day _type [data$holiday ==0 & data$workingday==0]
="weekend"
data$day_type[data$holiday==1] ="holiday"
data$day_type[data$holiday ==0 & data$workingday==1]
="working day"
data$weekend=0
data$weekend [data$day= ="Sunday"|data$day=
=" Saturday "] =1
接下来用随机森林语句预测
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,再在其中选取最优的特征。这样决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
ntree指定随机森林所包含的决策树数目,默认为500,通常在性能允许的情况下越大越好;
mtry指定节点中用于二叉树的变量个数,默认情况下数据集变量个数的二次方根(分类模型)或三分之一(预测模型)。一般是需要进行人为的逐次挑选,确定最佳的m值―摘自datacruiser笔记。这里我主要学习,所以虽然有10000多数据集,但也只定了500。就这500我的小电脑也跑了半天。
train<-data
set.seed (1234)
train$logreg <-log(train$registered+1)
test$logcas <-log(train$casual+1)
fit1 <-randomForest (logreg~hour1+ workingday
+ day + holiday + day_ type+ temp_reg+ humidity
+ atemp + windspeed + season+ weather+ dp_ reg+
weekend + year+year _part ,train ,importance =
TRUE , ntree = 250)
pred1 <-predict (fit1,train)
train $logreg <-pred1
这里不知道怎么回事,我的day和day_part加进去就报错,只有删掉这两个变量计算,还要研究修补。
然后用exp函数还原
train$registered<-exp(train$logreg)-1
train$casual<-exp(train$logcas)-1
train$count<-test$casual+train$registered
最后把20日后的日期截出来,写入新的csv文件上传。
train2<-train[as.integer
(day(data$datetime))> = 20 ,]
submit_final <-data.frame (datetime= test$
datetime ,count= test$count)
write.csv(submit _final,"submit_ final.csv
", row .names = F)
python大数据分析实例-Python大数据处理案例相关推荐
- python大数据分析实例-Python实现的大数据分析操作系统日志功能示例
本文实例讲述了Python实现的大数据分析操作系统日志功能.分享给大家供大家参考,具体如下: 一 代码 1.大文件切分 import os import os.path import time def ...
- python大数据分析实例-python大数据分析代码案例
#查询用户余额代码案例 import sys import MySQLdb import pandas as pd optmap = { 'dbuser' : 'aduser', 'dbpass' : ...
- 使用python数据分析的研究意义_大数据分析语言Python的价值和意义
Python提供了大量用于处理大数据的库.就开发代码而言,您还可以比其他任何编程语言更快地使用Python处理大数据.这两个方面使世界各地的开发人员能够将Python视为大数据项目的首选语言.要获得有 ...
- python3.x版本的保留字总数是多少_Python3.6.5版本的保留字总数是:()-智慧树大数据分析的python基础章节答案...
大数据分析的python基础:Python3.6.5版本的保留字总数是:()[?????] A:29 B:33 C:16 D:27 大数据分析的python基础章节测试答案: 33 更多相关问题 20 ...
- python在数据分析方面的应用、下列说法正确_智慧树知到大数据分析的python基础答案...
智慧树知到大数据分析的python基础答案 在派生类中可以通过 " 基类名 . 方法名 ()" 的方式来调用基类中的方法 . 下面代码的执行结果是 : ( ) a = 10.99 ...
- 向大家介绍我的新书:《基于股票大数据分析的Python入门实战》
我在公司里做了一段时间Python数据分析和机器学习的工作后,就尝试着写一本Python数据分析方面的书.正好去年有段时间股票题材比较火,就在清华出版社夏老师指导下构思了这本书.在这段特殊时期内,夏老 ...
- 基于股票大数据分析的Python入门实战(视频教学版)的插图汇总
在我写的这本书,<基于股票大数据分析的Python入门实战(视频教学版)>里,用能吸引人的股票案例,带领大家入门Python的语法,数据分析和机器学习. 京东链接是这个:https://i ...
- 大数据分析培训课程python时间序列ARIMAX模型
什么是ARIMAX模型? 如果您已经阅读了有关用于估计时间序列数据的模型的系列大数据分析培训课程python时间序列ARIMAX模型教程,则您已经熟悉3种主要方法- 自回归,移动平均值和积分. 所有这 ...
- python大数据结课报告_2020知到大数据分析的PYTHON基础结课答案
2020知到大数据分析的PYTHON基础结课答案 房产新闻 2020-10-02 02:28128未知admin 2020知到大数据分析的PYTHON基础结课答案 更多相关问题 Mike is so ...
最新文章
- C#并行开发_Thread/ThreadPool, Task/TaskFactory, Parallel
- C# 的EF框架怎么连接Oracle数据库
- IOS开发之UIView
- Adobe CTO:Android将超预期获50%份额
- 入门快应用的另一种姿势
- 不定宽高的DIV,垂直水平居中
- 【Oracle】truncate分区表
- vc6 往mdb写入信息_HBase运维 | 一张表写入异常引起的HBase Replication 队列堆积
- nlp基础—4.搜索引擎中关键技术讲解
- Linux源码安装PHP7.3.1
- 对计算机病毒防治最科学的方法是什么,常见的计算机病毒防治措施有什么
- Android原生开发如何深入进阶?完整版开放下载
- 深入理解 ceph mgr
- wps页眉怎么设置不同页码_Word:单双页页眉页码不同怎么设置?不同章节重新编码怎么设置?...
- barman备份软件离线安装渡劫文
- 【游戏客户端】剧情系统
- cup过高是什么意思_铁蛋白升高是什么原因?
- 2022年上半年软考成绩查询时间 和方法如下:
- 百度地图-设置地图最小、最大级别
- 12306 原因:系统繁忙,请稍后重试!