Scrapy结合Mysql爬取天气预报入库
创建Scrapy工程:
scrapy startproject weather2定义Items(items.py):
import scrapyclass Weather2Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()weatherDate = scrapy.Field()weatherDate2 = scrapy.Field()weatherWea = scrapy.Field()weatherTem1 = scrapy.Field()weatherTem2 = scrapy.Field()weatherWin = scrapy.Field()编写Spider(spiders/weatherSpider.py):
import scrapy
from weather2.items import Weather2Item class CatchWeatherSpider(scrapy.Spider):name = 'CatchWeather2'allowed_domains = ['weather.com.cn']start_urls = ["http://www.weather.com.cn/weather/101280101.shtml"]def parse(self, response):for sel in response.xpath('//*[@id="7d"]/ul/li'):item = Weather2Item()item['weatherDate'] = sel.xpath('h1/text()').extract() item['weatherDate2'] = sel.xpath('h2/text()').extract()item['weatherWea'] = sel.xpath('p[@class="wea"]/text()').extract()item['weatherTem1'] = sel.xpath('p[@class="tem tem1"]/span/text()').extract() + sel.xpath('p[@class="tem tem1"]/i/text()').extract()item['weatherTem2'] = sel.xpath('p[@class="tem tem2"]/span/text()').extract() + sel.xpath('p[@class="tem tem2"]/i/text()').extract()item['weatherWin'] = sel.xpath('p[@class="win"]/i/text()').extract()yield itemname:定义蜘蛛的名字。
allowed_domains: 包含构成许可域的基础URL,供蜘蛛去爬。
start_urls: 是一个URL列表,蜘蛛从这里开始爬。蜘蛛从start_urls中的URL下载数据,所有后续的URL将从这些数据中获取。
数据来源是http://www.weather.com.cn/weather/101280101.shtml,101280101是广州的城市编号
这里用到了xpath分析html,感觉好简单
测试运行:
scrapy crawl CatchWeather2结果片断:
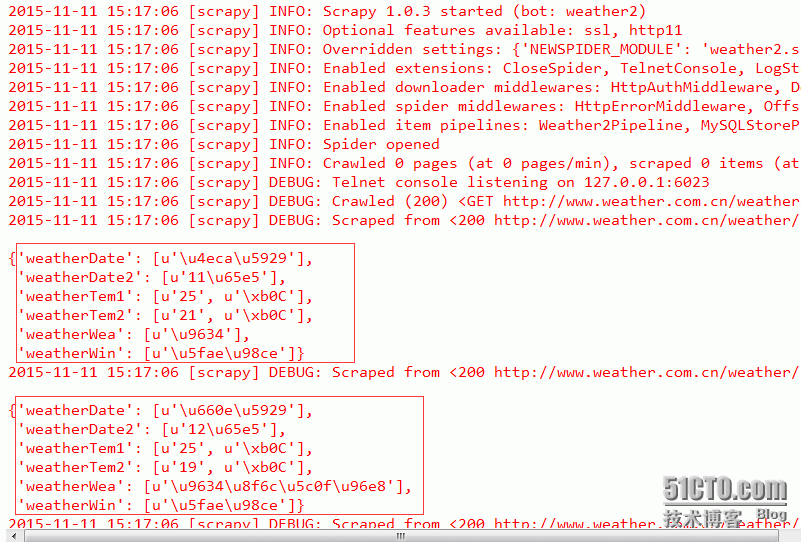
已经拿到我们想要的数据
创建数据库:
CREATE TABLE `yunweiApp_weather` (`id` int(11) NOT NULL AUTO_INCREMENT,`weatherDate` varchar(10) DEFAULT NULL,`weatherDate2` varchar(10) NOT NULL,`weatherWea` varchar(10) NOT NULL,`weatherTem1` varchar(10) NOT NULL,`weatherTem2` varchar(10) NOT NULL,`weatherWin` varchar(10) NOT NULL,`updateTime` datetime NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8;创建PipeLines():
import MySQLdb
import datetimeDEBUG = Trueif DEBUG:dbuser = 'lihuipeng'dbpass = 'lihuipeng'dbname = 'game_main'dbhost = '192.168.1.100'dbport = '3306'
else:dbuser = 'root'dbpass = 'lihuipeng'dbname = 'game_main'dbhost = '127.0.0.1'dbport = '3306'class MySQLStorePipeline(object):def __init__(self):self.conn = MySQLdb.connect(user=dbuser, passwd=dbpass, db=dbname, host=dbhost, charset="utf8", use_unicode=True)self.cursor = self.conn.cursor()#清空表:self.cursor.execute("truncate table yunweiApp_weather;")self.conn.commit() def process_item(self, item, spider): curTime = datetime.datetime.now() try:self.cursor.execute("""INSERT INTO yunweiApp_weather (weatherDate, weatherDate2, weatherWea, weatherTem1, weatherTem2, weatherWin, updateTime) VALUES (%s, %s, %s, %s, %s, %s, %s)""", (item['weatherDate'][0].encode('utf-8'), item['weatherDate2'][0].encode('utf-8'),item['weatherWea'][0].encode('utf-8'),item['weatherTem1'][0].encode('utf-8'),item['weatherTem2'][0].encode('utf-8'),item['weatherWin'][0].encode('utf-8'),curTime,))self.conn.commit()except MySQLdb.Error, e:print "Error %d: %s" % (e.args[0], e.args[1])return item修改setting.py启用pipelines:
ITEM_PIPELINES = {#'weather2.pipelines.Weather2Pipeline': 300,'weather2.pipelines.MySQLStorePipeline': 400,
}
后面的数字只是一个权重,范围在0-1000内即可
重新测试运行:
scrapy crawl CatchWeather2结果:
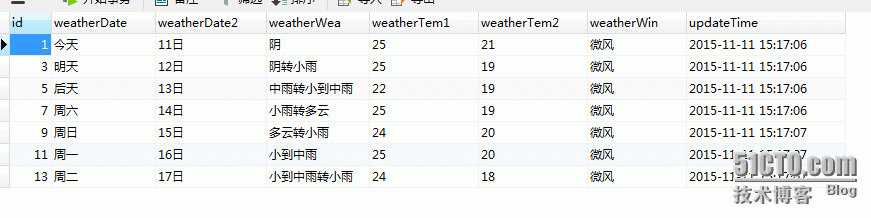 结合运维后台随便展示一下:
结合运维后台随便展示一下:
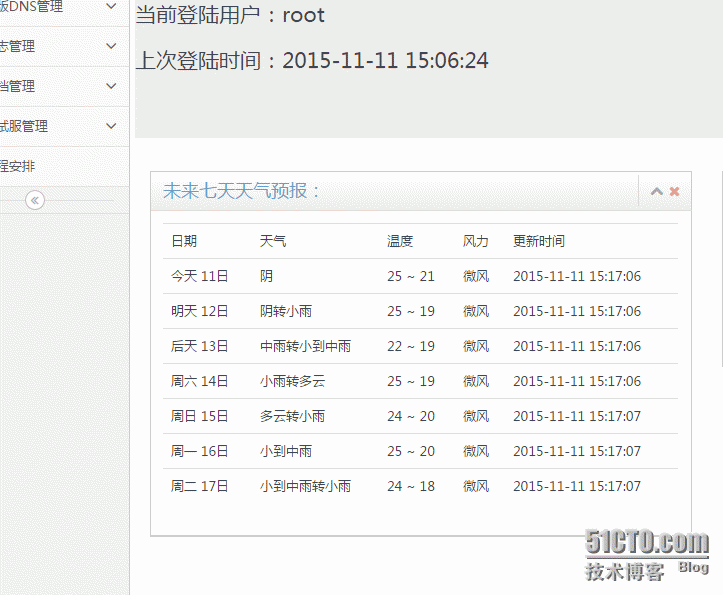
搞完收工~~
转载于:https://blog.51cto.com/lihuipeng/1711852
Scrapy结合Mysql爬取天气预报入库相关推荐
- 跌跌撞撞尝试Scrapy+Selenium+MySQL爬取与存储东方财富网股票数据
目录 网页信息 爬虫框架 stock_spider.py(爬虫文件) items.py (爬取字段命名) middlewares.py(Selenium中间件) pipelines.py settin ...
- mysql scrapy 重复数据_大数据python(scrapy)爬虫爬取招聘网站数据并存入mysql后分析...
基于Scrapy的爬虫爬取腾讯招聘网站岗位数据视频(见本头条号视频) 根据TIOBE语言排行榜更新的最新程序语言使用排行榜显示,python位居第三,同比增加2.39%,为什么会越来越火,越来越受欢迎 ...
- Scrapy+MySQL爬取去哪儿网
Scrapy+MySQL爬取去哪儿旅游[超详细!!!] 基于Python语言,利用Scrapy框架爬取信息,并持久化存储在MySQL 文章目录 Scrapy+MySQL爬取去哪儿旅游[超详细!!!] ...
- Python3爬取影片入库
Python3爬取影片入库 1.服务器说明 [root@openshift maoyan]# cat /etc/redhat-release CentOS Linux release 7.4.1708 ...
- 手把手教你使用scrapy框架来爬取北京新发地价格行情(理论篇)
点击上方"Python爬虫与数据挖掘",进行关注 回复"书籍"即可获赠Python从入门到进阶共10本电子书 今 日 鸡 汤 博观而约取,厚积而薄发. 大家好! ...
- python3 scrapy实战:爬取拉勾网招聘数据至数据库(反爬虫)
首先注明:感谢拉勾网提供的权威.质量的数据,本人抱着学习的态度,不愿增加其服务器负担,与dos攻击. 由于后面准备做一个大一点的数据分析项目,所以前提需要获取大量的有质量和权威的信息,其中一个获取点便 ...
- python爬取天气预报并发送短信_Python3爬虫教程之利用Python实现发送天气预报邮件...
前言 此次的目标是爬取指定城市的天气预报信息,然后再用Python发送邮件到指定的邮箱. 下面话不多说了,来一起看看详细的实现过程吧 一.爬取天气预报 1.首先是爬取天气预报的信息,用的网站是中国天气 ...
- Scrapy翻页爬取示例——列表页、详情页
Scrapy翻页爬取示例--列表页.详情页 引言: 本人最近在帮助同事们爬取一批英-泰双语数据,顺带复习了一下scrapy爬虫相关的知识.下面以简单的小项目为例,一起来开始吧! 示例一:爬取列表页 本 ...
- 使用python3.7中的scrapy框架,爬取起点小说
这几天在学习scrapy框架,感觉有所收获,便尝试使用scrapy框架来爬取一些数据,对自己阶段性学习进行一个小小的总结 本次爬取的目标数据是起点中文网中的免费作品部分,如下图: 本次一共爬取了100 ...
最新文章
- c++的uint8不赋值_2021国考 | 用对方法后,赋值法竟然变得如此简单!
- boost::math模块计算 Bessel 和 Neumann 函数的零点的测试程序
- 【AWSL】之Linux源代码编译及配置yum源(tar 解包、./configure配置软件模块、make)
- 异步fifo_FPGA设计基础——FIFO的应用
- 前端html5CSS3颜色表示法
- 898A. Rounding#数的舍入
- java和vue2.0
- 快速搭建Nextcloud+OnlyOffice私有云办公平台
- 【本地差分隐私与随机响应代码实现】差分隐私代码实现系列(十三)
- c# 数组中的空值_C# 数据操作系列 - 1. SQL基础操作
- android node编码,android studio中的Node.js
- Wolfram 语言之父 Stephen Wolfram :编程的未来
- Web 开发中使用了 Vim 作为主编辑器之后......
- 如何格式化基于 Intel 的 Mac?
- Perforce client - p4常见用法
- MSDEV.EXE 版本
- 华为softco直接用语音服务器注册IMS返回403错误代码
- 宿主机无法访问docker容器的坑
- 最详细新版网课联盟27刷网课平台源码+安装教程+最新模板+下载地址
- 【宇麦科技】某新能源企业的群晖nas存储方案:让“海量数据”跑出“加速度”
热门文章
- asp.net中关于点击页面一个控件,弹出框的制作
- 解决远程连接mysql很慢的问题(mysql_connect 打开连接慢)
- java面试精典问答
- Windows PE资源表编程(枚举资源树)
- C语言经典例16-最大公约数和最小公倍数
- 【数字信号处理】线性常系数差分方程 ( 根据 “ 线性常系数差分方程 “ 与 “ 边界条件 “ 确定系统是否是 “ 线性时不变系统 “ 案例 | 使用递推方法证明 )
- 【Groovy】MOP 元对象协议与元编程 ( 方法注入 | 使用 Category 分类进行方法注入的优缺点 )
- 【C 语言】字符串操作 ( strlen 与 sizeof 函数 | 计算 字符串长度 与 内存块大小 )
- 【字节码插桩】Android 打包流程 | Android 中的字节码操作方式 | AOP 面向切面编程 | APT 编译时技术
- 【Android 安装包优化】使用 lib7zr.so 动态库处理压缩文件 ( 拷贝 lib7zr.so 动态库头文件到 Android 工程中 | 配置 CMakeLists.txt 构建脚本 )