[paper] multi-human parsing (MHP) (Zhao et al., 2018) dataset.
Towards Real World Human Parsing: Multiple-Human Parsing in the Wild
Paper: https://arxiv.org/pdf/1705.07206.pdf
提出多人语义分割数据集:4980张图片(训练/验证/测试:3000/1000/980),每张包含2-16人,18个语义标签。
多人分割模型MH-Parser包含5个组件:
Representation learner (FCN提特征)
Global parser (用特征生成分割图)
Candidate nominator (RPN生成bbox)
Local parser (使用特征和bbox生成局部分割)
Global-local aggregator (结合全局和局部信息得到最终每个人的分割)
we introduce the Multiple-Human Parsing (MHP) dataset, which contains multiple persons in a real world scene per single image.
The MHP dataset contains various numbers of persons (from 2 to 16) per image with 18 semantic classes for each parsing annotation. Persons appearing in the MHP images present sufficient variations in pose, occlusion and interaction.
To tackle the multiple-human parsing problem, we also propose a novel Multiple-Human Parser (MH-Parser), which considers both the global context and local cues for each person in the parsing process.
Introduction
all the human parsing datasets only contain one person per image, while usually multiple persons appear simultaneously in a realistic scene.
Previous work on human parsing mainly focuses on the problem of parsing in controlled and simplified conditions.
simultaneous presence of multiple persons.
we tackle the problem of person detection and human parsing simultaneously so that both the global information and the local information are employed.
contributions:
We introduce the multiple-human parsing problem that extends the research scope of human parsing and matches real world scenarios better in various applications.
We construct a new large-scale benchmark, named Multiple-Human Parsing (MHP) dataset, to advance the development of relevant techniques.
We propose a novel MH-Parser model for multiple-human parsing, which integrates global context as well as local cues for human parsing and significantly outperforms the naive “detect-and-parse” approach.
Related work
Human parsing
Instance-aware object segmentation
The MHP dataset
this is the first large scale dataset focusing on multiple-human parsing.
4980 images, each image contains 2 to 16 humans, totally there are 14969 person level annotations.
Image collection and annotation methodology
we manually specify several underlying relationships (e.g., family, couple, team, etc.), and several possible scenes (e.g., sports, conferences, banquets, etc.)
The first task is manually counting the number of foreground persons and duplicating each image into several copies according to that number.
the second is to assign the fine-grained pixel-wise label for each instance.
Dataset statistics
training/validation/test: 3000/1000/980 (randomly choose)
The images in the MHP dataset contain diverse human numbers, appearances, viewpoints and relationships (see Figure 1).
Multiple-Human Parsing Methods
MH-Parser
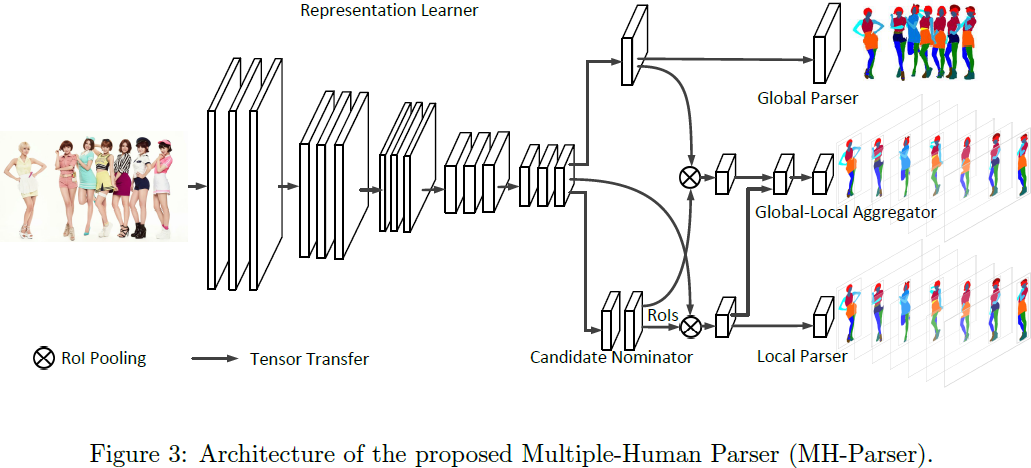
The proposed MH-Parser has five components:
Representation learner
We use a trunk network to learn rich and discriminative representations. we preserve the spatial information of the image by employing fully convolutional neural networks.
images and annotations => representations
Global parser
capture the global information of the whole image. The global parser takes the representation from the representation learner and generates a semantic parsing map of the whole image.
representations => a semantic parsing map of the whole image
Candidate nominator
We use a candidate nominator to generate local regions of interest. The candidate nominator consists of a Region Proposal Network (RPN).
representations => candidate box
Local parser
give a fine-grained prediction of the semantic parsing labels for each person in the image.
representations, candidate box => semantic parsing labels for each person
Global-local aggregator
leverages both the global and local information when performing the parsing task of each person.
the hidden representations from both the local parser and the global parser => a set of semantic parsing predictions for each candidate box
Detect-and-parse baseline
In the detection stage, we use the representation learner and the candidate nominator as the detection model.
In the parsing stage, we use the representation learner and the local prediction as the parsing model.
Experiments
Performance evaluation
The goal of multiple-human parsing is to accurately detect the persons in one image and generate semantic category predictions for each pixel in the detected regions.
Mean average precision based on pixel (mAPpmAPp)
we adopt pixel-level IOU of different semantic categories on a person.
Percentage of correctly segmented body parts (PCP)
evaluate how well different semantic categories on a human are segmented.
Global Mean IOU
evaluates how well the overall parsing predictions match the overall global parsing labels.
Implementation details
representation learner
adopt a residual network [19] with 50 layers, contains all the layers in a standard residual network except the fully connected layers.
input: an image with the shorter side resized to 600 pixels and the longer side no larger than 1000 pixels
output: 1/16 of the spatial dimension of the input image
global parser
add a deconvolution layer after the representation learner.
output: a feature map with spatial dimension 1/8 of the input image
candidate nominator
use region proposal network (RPN) to generate region proposals.
output: region proposals
local parser
based on the region after Region of Interest (ROI) pooling from the representation learner and the size after pooling is 40.
global-local aggregator
the local part is from the hidden layer in the local parser, and the global part uses the feature after ROI pooling from the hidden layer of the global parser with the same pooled size.
The network is optimized with one image per batch and the optimizer used is Adam [20].
Experimental analysis
Overall performance evaluation
RL stands for the representation learner, G means the global parser, L denotes the local parser, A for aggregator.
Qualitative comparison
We can see that the MH-Parser captures more fine-grained details compared to the global parser, as some categories with a small number of pixels are accurately predicted.
Conclusion and future work
In this paper, we introduced the multiple-human parsing problem and a new large-scale MHP dataset for developing and evaluating multiple-human parsing models.
We also proposed a novel MH-Parser algorithm to address this new challenging problem and performed detailed evaluations of the proposed method with different baselines on the new benchmark dataset.
--------------------- 作者:lijiancheng0614 来源:CSDN 原文:https://blog.csdn.net/lijiancheng0614/article/details/73195221?utm_source=copy 版权声明:本文为博主原创文章,转载请附上博文链接!
[paper] multi-human parsing (MHP) (Zhao et al., 2018) dataset.相关推荐
- [paper] Multiple Human Parsing
Towards Real World Human Parsing: Multiple-Human Parsing in the Wild Paper: https://arxiv.org/pdf/17 ...
- 多人部件解析--Towards Real World Human Parsing: Multiple-Human Parsing in the Wild
Towards Real World Human Parsing: Multiple-Human Parsing in the Wild https://arxiv.org/abs/1705.0720 ...
- 【论文阅读】Graphonomy: Universal Human Parsing via Graph Transfer Learning通过图迁移学习进行的通用人体解析
Problem问题 人体解析是指将在图像中捕获的人分割成多个语义上一致的区域,例如, 身体部位和衣物.作为一种细粒度的语义分割任务,它比仅是寻找人体轮廓的人物分割更具挑战性. 人体解析对于以人为中心的 ...
- Human Parsing 数据预处理使用指南
CIHP_PGN使用指南 # 1.进入目录 & 激活conda cd ~/cz/CIHP_PGN && conda activate CIHP_PGN # 2.处理数据(已将m ...
- Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing
0.Abstract : 说明本篇文章的主要工作 : 一是提出了一个用于人体解析的大数据集 Look into Person (LIP), 这个数据集相比之前的数据集更大,覆盖情景更多,更复杂,作者还 ...
- 人物交互(human object interaction)论文汇总-2018年
1. Detecting and Recognizing Human-Object Interactions 1.1 总述 中心思想是以人为中心.假设是一个人的外表信息(姿态.衣服.动作等)是确定与他 ...
- Neural Motifs: Scene Graph Parsing with Global Context (CVPR 2018) 运行复现遇到的一些坑以及解决方法
写在前面 首先,感谢这篇文章 https://blog.csdn.net/weixin_38651565/article/details/87901172 的作者 @jiayan97 和他有很多交流帮 ...
- [paper] CE2P
Devil in the Details: Towards Accurate Single and Multiple Human Parsing CE2P是一个端到端的人体解析的框架,现已开源,代码连 ...
- 如何用深度学习生成图片(GAN, pix2pix, CycleGAN和pix2pixHD)
本文翻译.总结自朱俊彦的线上报告,主要讲了如何用机器学习生成图片. 来源:Games2018 Webinar 64期 :Siggraph 2018优秀博士论文报告 人员信息 主讲嘉宾 姓名:朱俊彦(J ...
最新文章
- windows 7 SDK和DDK下载地址
- pycharm变量存_pycharm不为人知的功能们
- 机器学习6/100天-Logistic实践
- 使用MTL库求解最小二乘解
- 项目管理实践之版本控制工具SVN在Windows平台下的平台搭建
- 【收藏】一千行 MySQL 学习笔记
- 190819每日一句
- kafka connect分布式安装
- 软件开发设计文档模版
- JS 延时函数 setTimeout 或者 rxjs 写法
- 解读 | 数据分析师(含转行)的面试简历如何写?
- 激活win7 home版 administrator
- Python基于OpenCV的土壤裂缝分割系统[源码&部署教程]
- 牛客 哔哩哔哩校招编程真题 给定一个整数数组,判断其中是否有3个数和为N 二分经典 三数之和
- 一步步教你如何在Ubuntu虚拟机中安装QEMU并模拟模拟arm 开发环境(一)uImage u-boot
- undefsafe原型链[网鼎杯 2020 青龙组]notes
- 【简单实用】一台主机两个人使用,互不影响~~~
- 炫酷3D相册❤ 520七夕情人节表白网页制作❤(HTML+CSS+JavaScript)
- 【原创】常用元器件(电阻)选型之阻值有多少-cayden20220910
- 青蛙与蚊子(C++结构体练习题)
热门文章
- php swfupload handlers.js,swfupload使用代码说明
- 竞态条件的赋值_《Java并发编程实战》读书笔记一:基础知识
- C语言十进制转换成二进制源码
- rea t插件 vscode_推荐VSCode12个比较实用的插件
- 2017,公司必须换掉的六种人,别心软!
- js 事件函数中的参数带换行符或换行标签都不能起作用的解决方法
- 下一步,该怎么做空中国概念股?
- 赛迪顾问2010-2011年度中国信息安全产品市场研究年度报告
- php crypt返回的是对象还是字符串,php – 将字符串与哈希值进行比较时,Crypt函数不起作用...
- easyui treegrid 获取新添加行inserted_18行JavaScript代码构建一个倒数计时器