【转载】自然语言推理介绍
原文链接
自然语言推理介绍
自然语言推理作为自然语言理解的一个重要组成部分,在整个自然语言理解中扮演着重要的角色,接下里我将对自然语言推理的现状做一简单总结,以下内容是我的小组分享的记录版。
自然语言推理简介

自然语言推理主要是判断两个句子(Premise, Hypothesis)或者两个词之间的语义关系,为了保证模型能够集中在语义理解上,该任务最终退化为一个分类任务,目前类别主要是三分类(Entailment,Contradiction,Neutral)。目前对这三类有各种各样的定义,但是我认为这三类的分类依据还是要落在语义理解上,通过语义关系来确定类别。

那为什么要研究自然语言推理呢?简单来讲,机器学习的整个系统可以分为两块,输入,输出。输入要求我们能够输入一个机器能理解的东西,并且能够很好的表现出数据的特点,输出就是根据需要,生成我们需要的结果。也可以说整个机器学习可以分为Input Representation和Output Generation。因此,如何全面的表示输入就变得非常重要了。而自然语言推理是一个分类任务,使用准确率就可以客观有效的评价模型的好坏;这样我们就可以专注于语义理解和语义表示。并且如果这部分做得好的话,例如可以生成很好的句子表示的向量,那么我们就可以将这部分成果轻易迁移到其他任务中,例如对话,问答等。这一切都说明了研究自然语言推理是一个非常重要但是非常有意义的事情。
以下是自然语言推理推理的发展历程
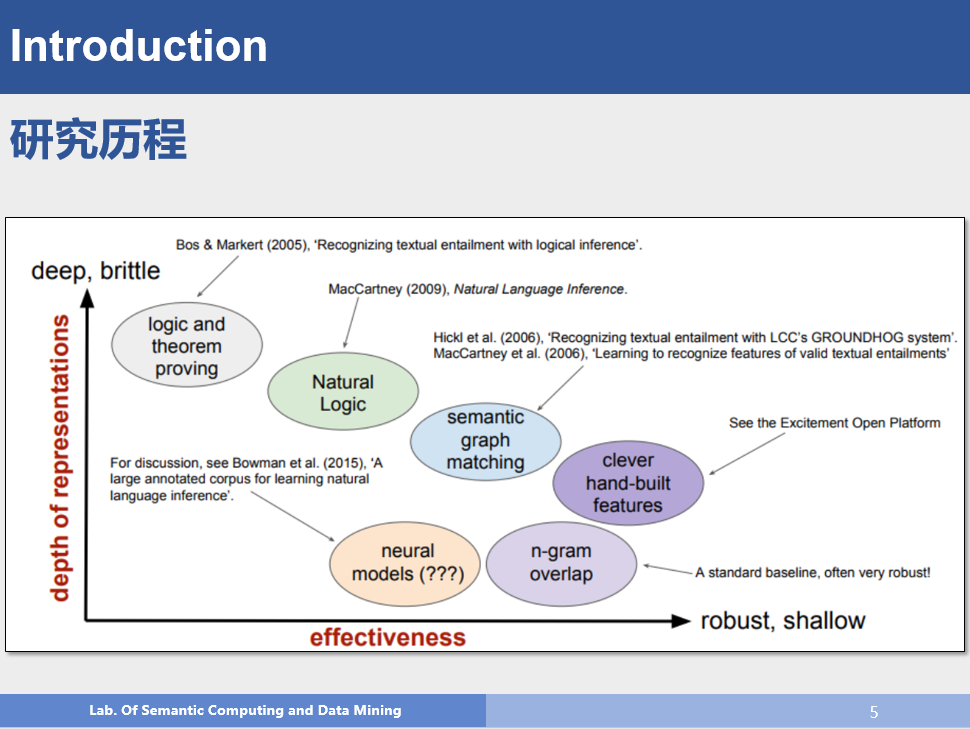
相关数据
上一部分对自然语言推理进行了一个大致的介绍。众所周知,数据对模型非常重要,而且深度神经网络也是高度依赖数据的,那么我们来对目前的数据进行一个简单的梳理

这是自然语言推理领域一个非常重要的数据集,相关信息如上图所示,斯坦福大学通过众包的方式生成了这个自然语言推理领域第一个大规模人工标注的数据集,从此自然语言推理进入深度学习时代。
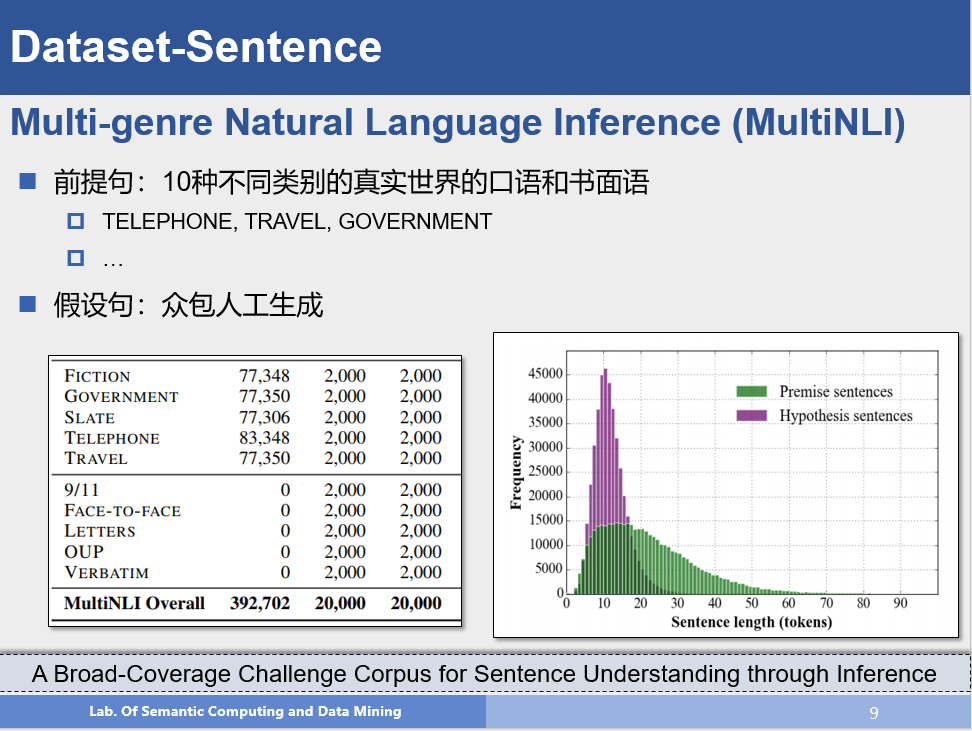
这个数据集和SNLI比较类似,但是它的前提句子来自真实场景的数据,因此在数据上更贴近现实一些,同时,每一条数据包含了类别信息。

这个数据集就更加贴近现实了,前提句和假设句全都来自真实场景,人工的作用放到了对每一条数据打标签,因此数据本身的人工影响就变小了。但是该数据全部来自科学问答,因此在类别上可能略显单一。

该数据集和前边不同的地方在于它是四个前提句对应一个假设句,这样在进行推理分类时,不仅需要考虑前提句和假设句的关系,还需要考虑前提句之间的相关关系,因此推理难度更大,但是这些文本句子全都来自image captioning工作,文本本身人工较少,因此文本质量上可能不如前者。但这也是一个很有意思的方向。
当然,还有很多其他的数据集,例如SICK, Add-one RTE, JOCI等,都是从不同角度对语义理解提出了一个要求。可以说自然语言推理领域目前正是百花齐放,十分繁荣。
一些方法
词级别的推理
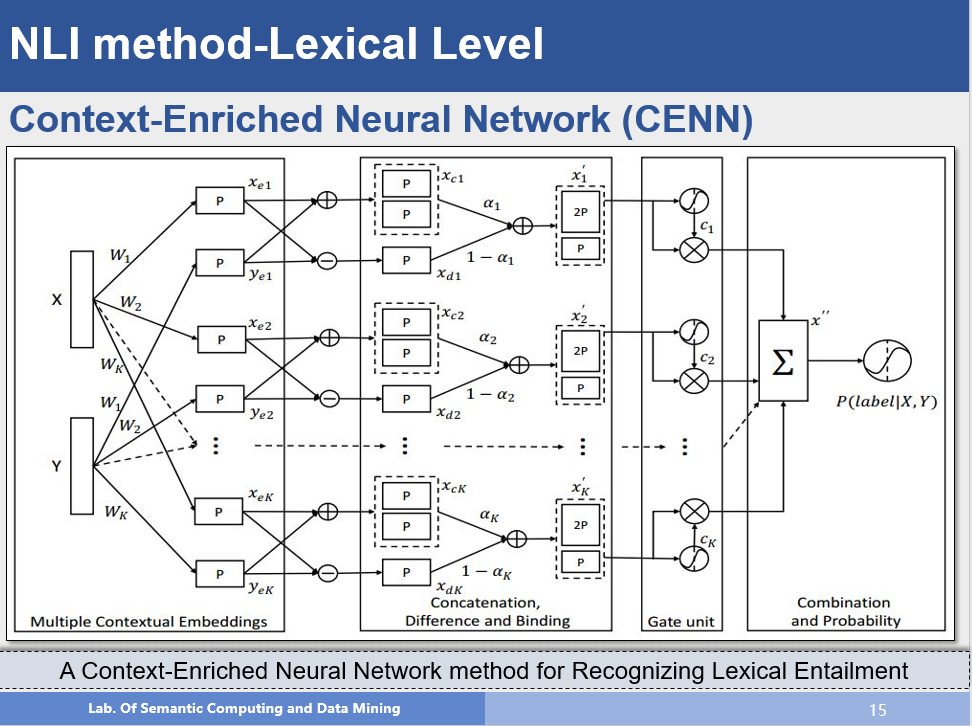
该方法主要研究的是词级别的推理。有研究表明,词具有不同方面的语义信息,例如book在名词角度可以表示为:书,但在动词角度可以表示为:预定;因此使用单一的向量可能无法有效区分这些内容,因此作者提出利用不同的上下文来获取词在不同角度的语义信息,例如:选取中心词周围的名词来表示它的topic信息,选取中心词周围的动词来表示它的function信息。这样对每个词就都有不同的语义向量表示,然后通过网络结构对相关信息进行拼接,最后考虑到不同的推理关系可能需要的信息时不同的,例如:上下位关系:狗-动物,可能需要的是topic相关的信息,因果关系:攻击-受伤,可能需要的更多的是function的信息,因此作者通过一个门结构计算出每种语义表示对推理关系的影响程度,然后进行加权求和,最后进行分类。并且该方法的可扩展性非常好,从网络结构上看,我们可以增加不同的语义表示,模型的结构和参数规模并不会有太大的提升,这也可以认为是模型的一个优点。
句子级别的推理
句子级别的推理可以分为两部分,基于句子语义编码的方法和基于词匹配的方法,前者是首先将一个句子编码为向量,然后分析两个向量之间的关系;后者考虑更多的是词之间的匹配关系,不一定有句子的语义向量表示。
句子语义编码方法
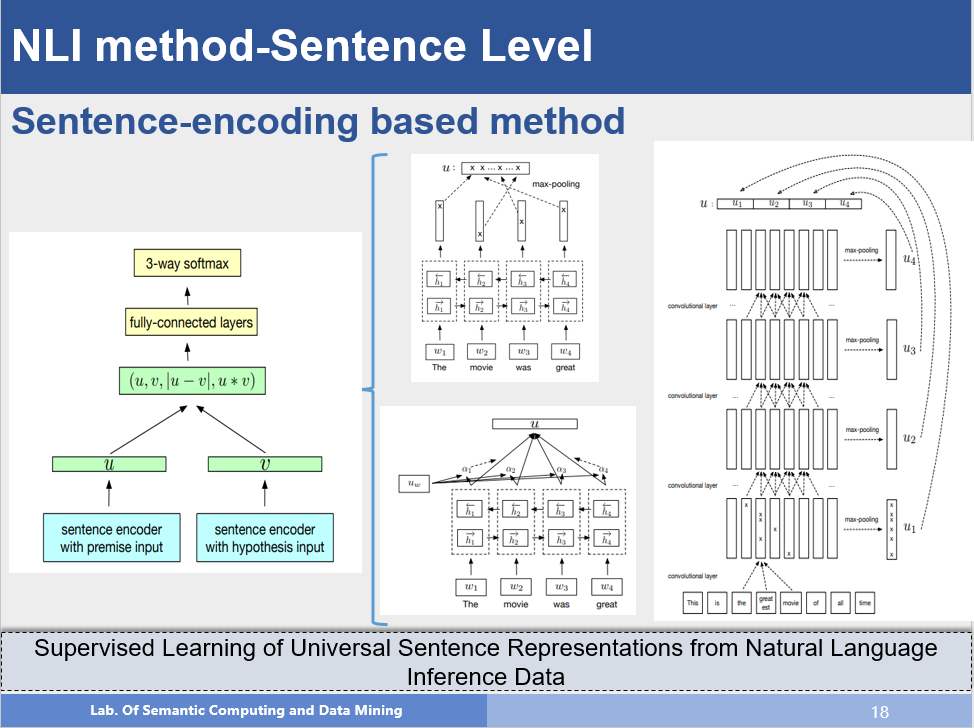
该方法就是句子编码的方法,首先左图展现了这类方法的一般结构,首先通过不同的方法得到每个句子的语义向量表示;在此基础上,对两个向量作拼接,相减,点乘来得到两个语义向量之间的关系,最后通过一个MLP进行分类,右图就是句子编码部分可以采用的方法,例如:通过双向LSTM,得到隐层状态,对隐层状态做max-pooling或者做attention,得到的加权表示就只句子的语义向量表示,最右边的图示利用了CNN的结构,我们都知道CNN是建立输入之间的局部关系,那么作者使用了多层的CNN,通过多层卷积,底层获取的是local部分的信息,那么越往上就可以得到更长范围内的信息,从而对句子语义进行建模,这也是一种很不错的方法。
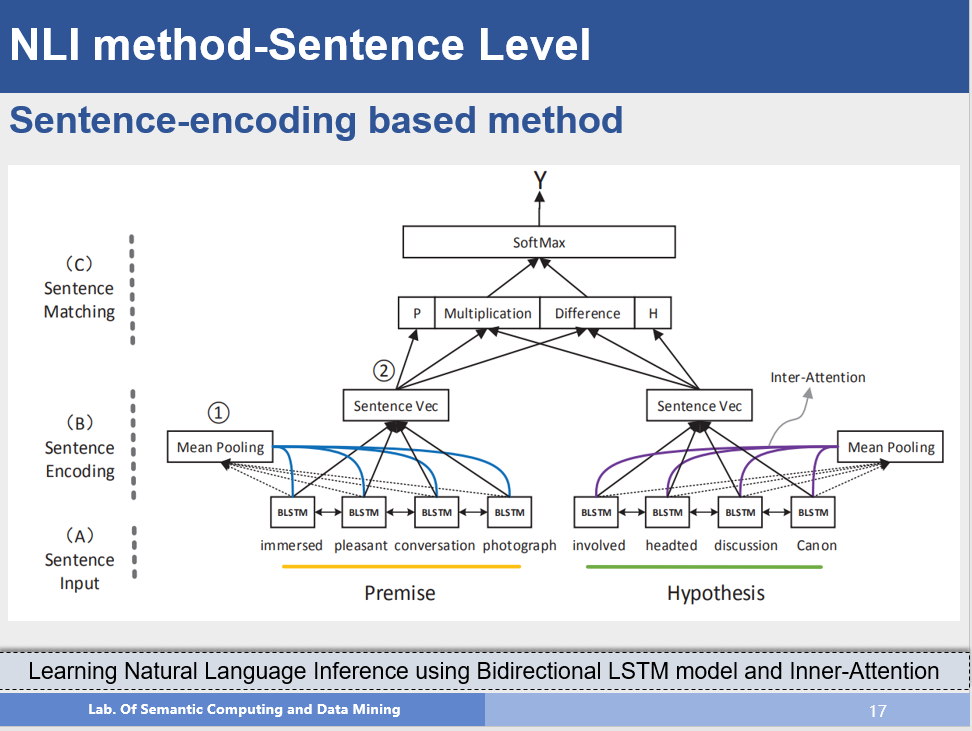
这个方法是对注意力机制(Attention Mechanism)的一种有效利用,我们可以清晰看出来,作者先对BiLSTM的隐层状态进行mean pooling,在此基础上,利用注意力机制得到句子中那些词对语义表示比较重要,然后对隐层状态进行加权求和,就得到了句子表示的向量,最后就是常用的框架。从该方法中我们也可以看到句子编码模型的基本结构。
词匹配方法
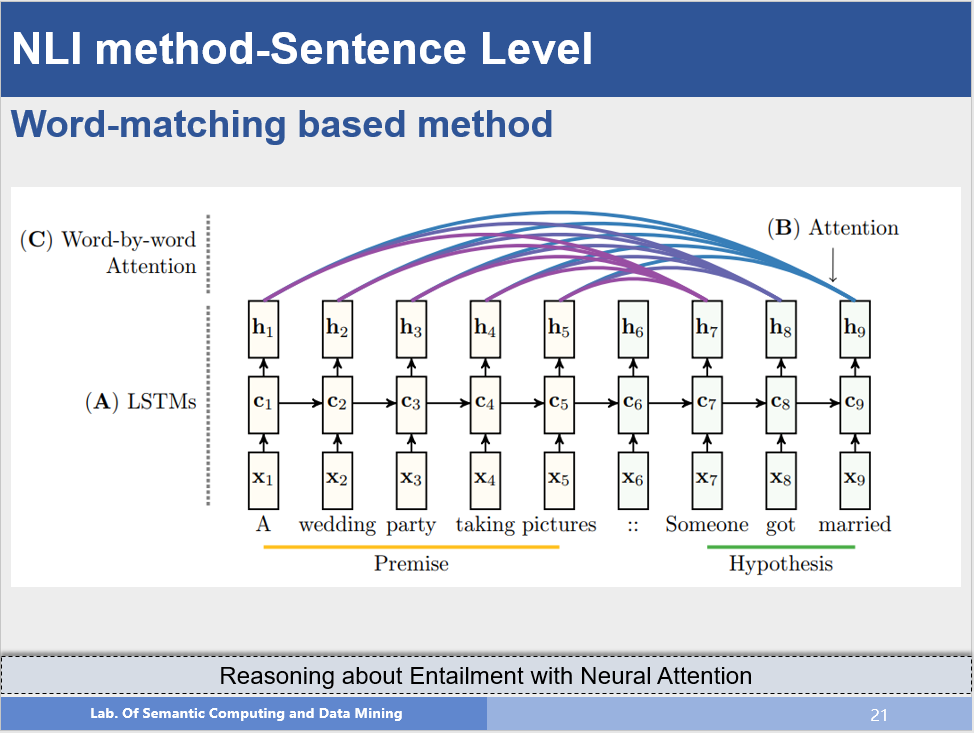
该方法是词匹配方法的一个代表工作,首先作者使用两个LSTM来处理两个句子,并且后一个LSTM的隐层使用前一个LSTM的最后一个状态初始化,在此基础上,作者在求后一个句子的隐层状态时,使用注意力机制考虑前提句子的每一个词的隐层状态,建立词之间的匹配关系,最后利用最后一个隐层状态作为最后分类的依据,在这个方法中我们看到,其实并没有句子语义向量的表示。
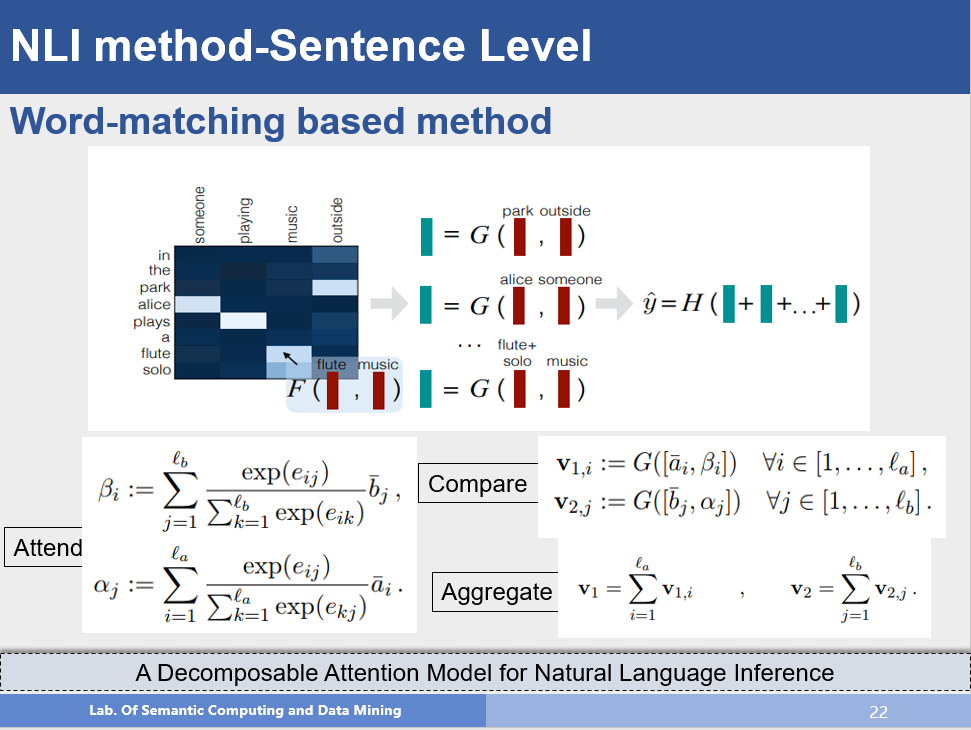
该方法在词匹配上进行了更深入的研究,不仅仅是计算他们的匹配程度,而是先求前提句中的每个词和假设句中的所有词之间的attention,并使用假设句中所有词乘以attention分布,来表示前提句中的每个词,这样就使用了对方的语义来表示自己,假设句也是一样。然后将得到的结果和原始的表示作拼接,通过变换,最后求一个和,得到句子的表示进行分类,该方法也是目前比较流行的方法,通过使用对方的语义来表示自己,从而对语义关系进行更好的建模。
问题
Accuracy
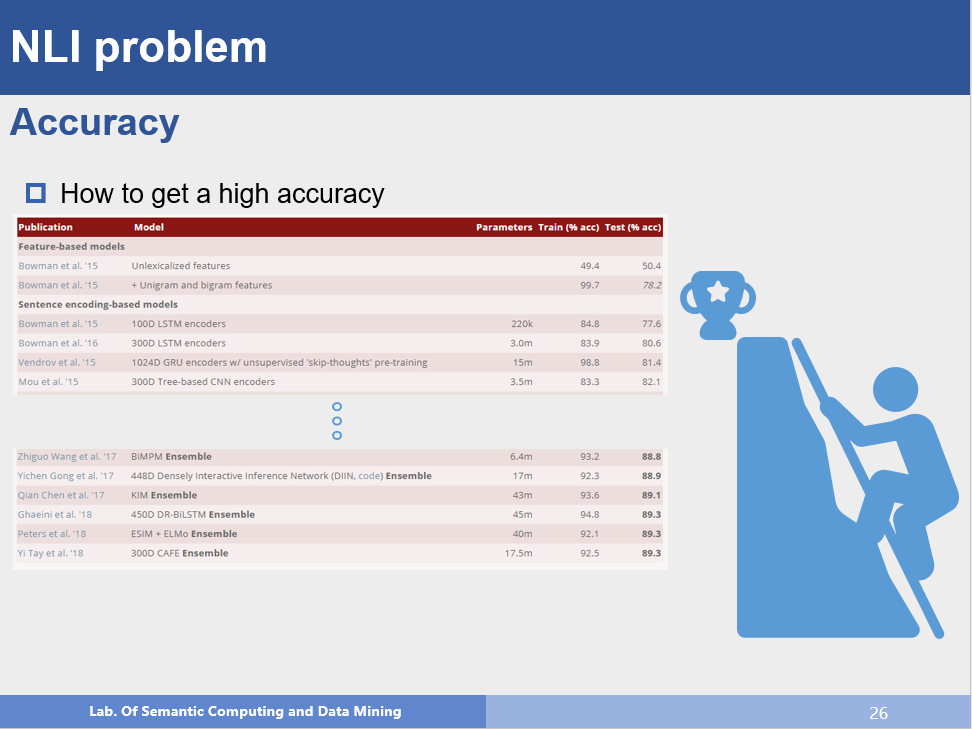
这是第一个也是很重要的问题,目前在SNLI数据集上,最好的结果已经做到89.3%,那么接下来如何提升准确率呢?这是一个值得思考的问题。
Lexical Knowledge

这个问题很有意思,从数据上考虑,他只是修改了前提句中的一个词得到假设句,对于我们人类来说,进行这样的区分十分容易,但是由于两个句子之间的词的高重合度,模型可能会认为这两个输入是一致的,尤其是不同的两个词属于同一类的时候,他们的词向量表示会更相似。如果数据中有这样的例子,那模型肯定没问题,但如果训练数据中没有这样的例子,但实际上如果模型能够很好地理解语义,这个应该不是问题,而事实上这对模型来说是一个巨大的问题,对于这些词级别的不同,模型该如何去衡量呢?
Annotation Artifacts

这也是一个很有意思的问题,如前边所介绍的,数据集都是使用了人工,尤其是有一些数据集的假设句子全都是人写的,理论上来说人写的句子肯定比模型生成的好,但是人写的句子也有一些特点,例如推理关系是Entailment的时候,可能假设句的一些名词是前提句的上位词(woman->people),如果是Contradiction的时候,那么假设句中可能就有很多否定词之类的。这些特点其实很好理解,但是如果模型发现了这些特征,那么它甚至可以只用假设句就能进行分类,但结果正确并没有什么用,模型并没有真正理解语义。如图作者进行了一些统计分析,可以看到有一些词和标签是有着紧密联系了,可以直接用这些词进行分类,但这些对语义理解并没有什么帮助。因此如何避免这些情况,准确理解语义也是一个非常重要的研究内容。
最后
以上就是我针对自然语言推理的一个简单介绍,作为自然语言理解的一个重要组成部分,这里边还是有很多很有意思的内容值得研究的。♪(^∀^●)ノ
【转载】自然语言推理介绍相关推荐
- MIT开放式课程“自然语言处理”介绍
MIT开放式课程"自然语言处理"介绍 发表于 2009年01月2号 由 52nlp 从订阅的Google快讯上知道这个"麻省理工学院"开放式课程网页" ...
- WSDM Cup 2019自然语言推理任务获奖解题思路
WSDM(Web Search and Data Mining,读音为Wisdom)是业界公认的高质量学术会议,注重前沿技术在工业界的落地应用,与SIGIR一起被称为信息检索领域的Top2. 刚刚在墨 ...
- NLP自然语言处理-机器学习和自然语言处理介绍(五)
NLP自然语言处理-机器学习和自然语言处理介绍-知识抽取构建流程 1.什么是知识抽取 知识抽取,即从不同来源.不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱. 知识抽取的三个基本任 ...
- Textual Entailment(自然语言推理-文本蕴含) - AllenNLP
自然语言推理是NLP高级别的任务之一,不过自然语言推理包含的内容比较多,机器阅读,问答系统和对话等本质上都属于自然语言推理.最近在看AllenNLP包的时候,里面有个模块:文本蕴含任务(text en ...
- 自然语言推理入门:ESIM
Enhanced LSTM for Natural Language Inference ESIM是ACL2017的一篇论文,在当时成为各个NLP比赛的杀器,直到现在仍是入门自然语言推理值得一读的文章 ...
- 自然语言推理:微调BERT
自然语言推理:微调BERT Natural Language Inference: Fine-Tuning BERT SNLI数据集上的自然语言推理任务设计了一个基于注意力的体系结构.现在通过微调BE ...
- 自然语言推理:使用注意力机制
自然语言推理:使用注意力机制 Natural Language Inference: Using Attention 自然语言推理任务和SNLI数据集.鉴于许多模型都是基于复杂和深层架构的,Parik ...
- 自然语言推理和数据集
自然语言推理和数据集 Natural Language Inference and the Dataset 情绪分析的问题.此任务旨在将单个文本序列分类为预定义的类别,例如一组情感极性.然而,当需要判 ...
- AllenNLP系列文章之六:Textual Entailment(自然语言推理-文本蕴含)
自然语言推理是NLP高级别的任务之一,不过自然语言推理包含的内容比较多,机器阅读,问答系统和对话等本质上都属于自然语言推理.最近在看AllenNLP包的时候,里面有个模块:文本蕴含任务(text en ...
最新文章
- 搜索(DFS)---好友关系的连通分量数目
- css 横线_CSS-画一个太极阴阳图
- 大数据【企业级360°全方位用户画像】标签系统介绍
- ASP.NET 3.5核心编程学习笔记(18):数据绑定表达式
- 芸众商城社交电商系统V2.2.64
- 人从众!中秋小长假全国铁路预计发送旅客4600万人次
- 英语形容词的排列顺序
- iOS---iPhoneXs iPhoneXs Max iPhoneXr
- 基于Multisim的波形发生器
- 使用MD5加密的登陆demo
- caffe源码学习:Blobs
- 学习如何合理的配置服务器
- 5214页PDF的进阶架构师学习笔记,阿里巴巴内部Jetpack宝典意外流出
- 自然语言处理2——语言学基础
- Your CLT does not support macOS 11
- Java上机实践四实验一机动车
- McAfee白名单设置
- 关于精简(函数化)因为输入数据多条而导致的冗杂代码的总结
- 【Mybatis】缓存
- 图像去模糊算法 循序渐进 附完整代码