Facebook开源工具包LASER,支持93种语言
为了加速自然语言处理(NLP)在更多语言上进行零样本迁移,Facebook 扩展并增强了LASER(Language-Agnostic SEntence Representations)工具包,并将其开源。这是第一个成功探索大型多语种句子表示并与广大NLP社区共享的工具。
该工具包现在可以使用90多种语言和28种不同的字母表。LASER通过将所有语言联合嵌入到单个共享空间(而不是为每种语言分别建立单独的模型)来实现这些结果。我们现在免费提供多语言编码器和PyTorch代码,以及针对100多种语言的多语言测试集。
LASER打开了从一种语言(如英语)到其他几种语言(包括训练数据极为有限的语言)进行NLP模型零样本迁移的大门。LASER是第一个使用单一模型处理各种语言的库,包括低资源语言(如卡拜尔语和维吾尔语),以及中国的吴语等方言。有朝一日,这项工作可以帮助Facebook和其他公司推出一些特定的NLP功能,例如,使用一种语言将电影评论分类为正面或负面,然后再使用其他100多种语言发布。
性能和功能亮点
LASER为XNLI语料库14种语言中的13种带来了更高的零样本跨语言自然语言推理准确率。它还在跨语言文档分类(MLDoc语料库)方面获得了很好的结果。我们的句子嵌入在并行语料库挖掘方面也有很好的表现,在BUCC(BUCC是在2018年举行的一个构建和使用可比较语料库研讨会)共享任务中将四个语言对中的三个提升到了一个新的技术水平。除了LASER工具包,我们在Tatoeba语料库的基础上共享了100多种语言对齐句子的测试集。使用这个数据集,我们的句子嵌入在多语言相似性搜索中获得了很好的结果,即使是低资源语言也是如此。
LASER还提供了其他的一些好处:
- 它提供了极快的性能,在GPU上每秒处理多达2,000个句子。
- 句子编码器使用PyTorch实现,只有很少的外部依赖。
- 低资源语言可以从多种语言的联合训练中受益。
- 该模型支持在一个句子中使用多种语言。
- 随着新语言的添加,性能会有所提高,因为系统会学会识别语言族的特征。
通用的语言无关性句子嵌入
LASER的句子向量表示对于输入语言和NLP任务都是通用的。它将语言的句子映射到高维空间中的一个点,目标是让语言中的相同语句最终出现在同一邻域中。该表示可以被视为语义向量空间中的一种通用语言。我们已经观察到,空间中的距离与句子的语义紧密程度密切相关。
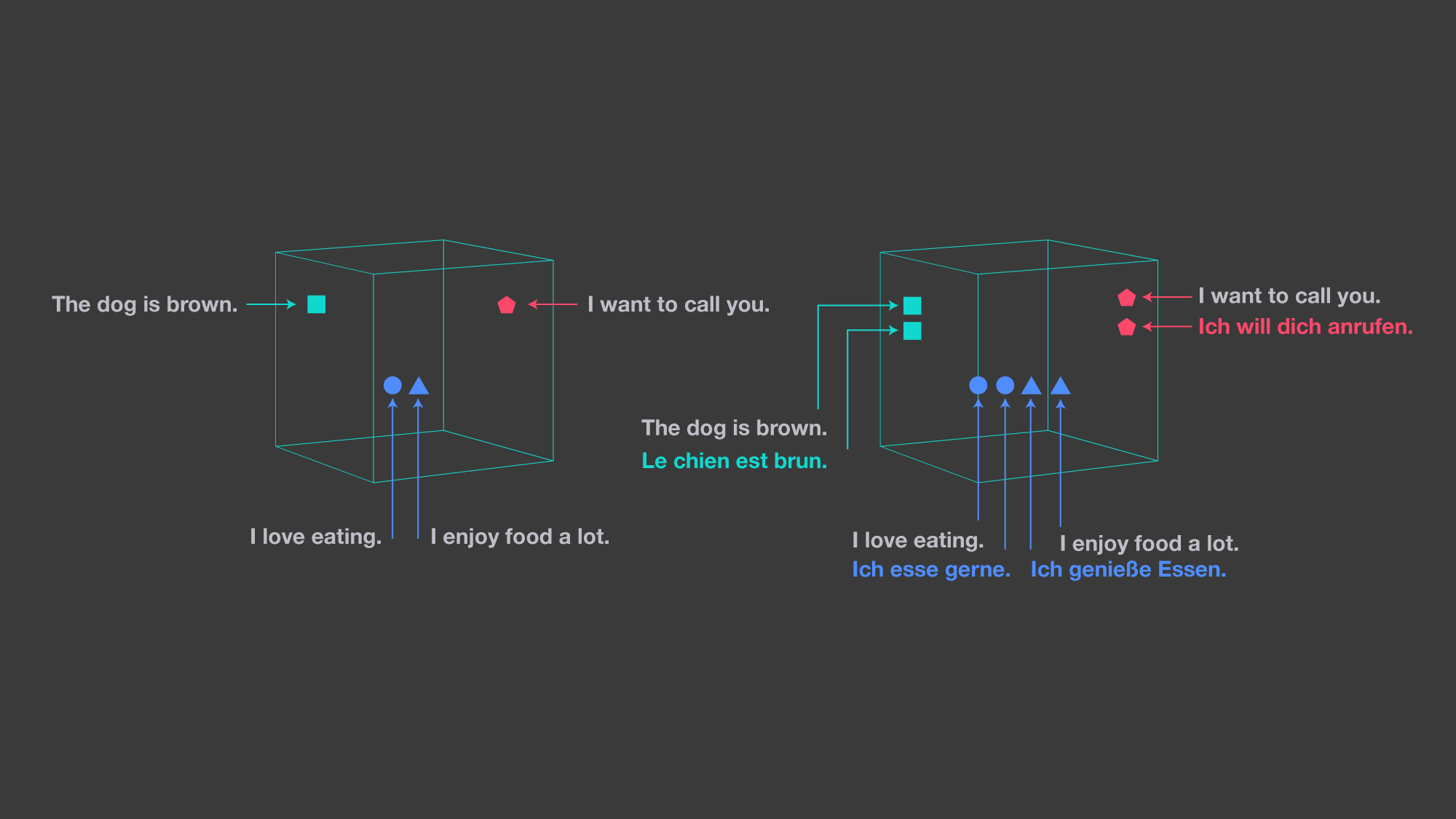
左边的图像显示了单语嵌入空间。右侧图像说明了LASER的方法,它将所有语言嵌入到一个共享空间中。
我们的方法建立在与神经机器翻译相同的基础技术之上:编码器/解码器方法,也称为序列到序列处理。我们为所有输入语言使用一个共享编码器,并使用共享解码器生成输出语言。编码器是五层双向LSTM(长短期记忆)网络。与神经机器翻译相比,我们不使用注意机制,而是使用1,024维固定大小的向量来表示输入句子。它是通过对BiLSTM的最后状态进行最大池化得到的。我们因此能够比较句子的表示形式,并将它们直接输入分类器中。
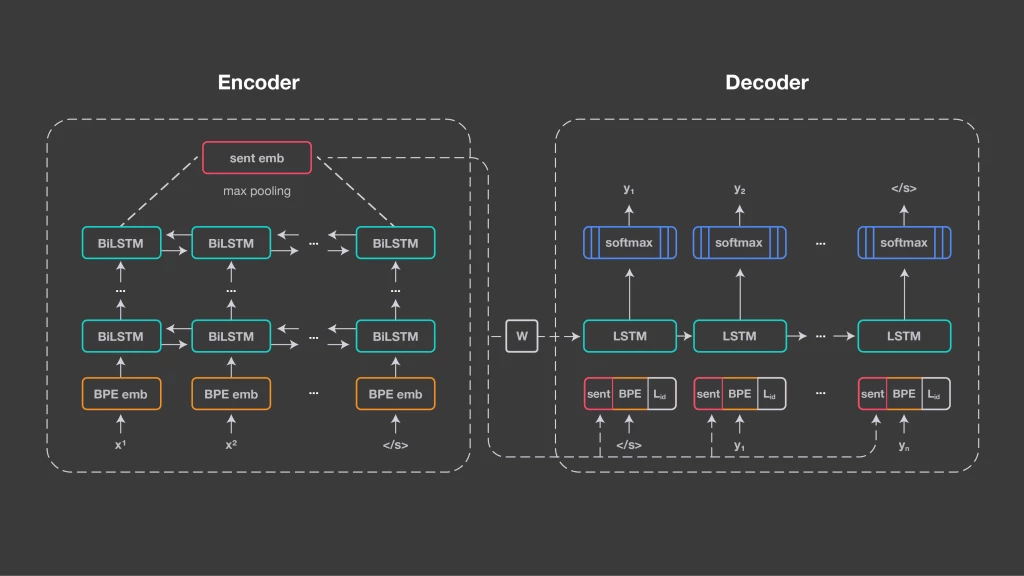
方法架构
这些句子嵌入用于初始化解码器LSTM,通过线性变换以及在每个时间步骤上将其连接到输入嵌入。编码器和解码器之间没有其他的连接,因为我们希望通过句子嵌入捕获到输入序列的所有相关信息。
我们必须告诉解码器要生成哪种语言。它需要一个语言标识,也就是在每个时间步骤上连接到输入和句子嵌入的标识。我们使用具有50,000个操作的联合字节对编码(BPE)词汇表,在所有连接的训练语料库上进行训练。由于编码器没有指示输入语言的显式信号,因此编码器需要学习与语言无关的表示。我们基于公共并行数据的2.23亿个句子(它们与英语或西班牙语对齐)训练我们的系统。对于每个迷你批次,我们随机选择一种输入语言,让系统将句子翻译成英语或西班牙语。大多数语言都与目标语言保持一致,虽然这不是必需的。
我们刚开始训练了不到10种欧洲语言,所有语言都使用了相同的拉丁文字。后来,我们逐渐增加到Europarl语料库中提供的21种语言,结果表明,随着我们添加的语言越来越多,多语言迁移性能也得到了提升。系统学习了语言家族的通用特征。通过这种方式,低资源语言可以从同一族高资源语言的资源中获益。
这可能可以通过使用在所有语言的连接上训练的共享BPE词汇表来实现。我们对每种语言BPE词汇表分布之间的对称Kullback-Leiber距离进行了分析和聚类,结果显示,Kullback-Leiber距离与语言家族具有几乎完美的相关性。

LASER自动发现各种语言之间的关系,与语言学家手动定义的语言家族非常吻合。
我们意识到,单个共享的BiLSTM编码器可以处理多个脚本。我们逐渐扩展到所有可以识别免费并行文本的语言。被纳入LASER的93种语言包括SVO顺序(例如英语)、SOV顺序(例如孟加拉语和突厥语)、VSO顺序(例如塔加路语和柏柏尔语),甚至是VOS顺序(例如马达加斯加语)的语言。
我们的编码器可以推广到未使用的语言(甚至是单语文本)。我们发现了它在一些区域语言上表现良好,例如阿斯图里亚斯语、法罗语、弗里斯兰语、卡舒比语、北摩鹿加语马来语、皮埃蒙特语、斯瓦比亚语和索布语。所有这些语言都在不同程度上与其他主要语言有一些相似之处,但它们的语法或特定词汇有所不同。

LASER在XNLI语料库上的零样本迁移性能
零样本跨语言的自然语言推理
我们的模型在跨语言自然语言推理(NLI)中获得了良好的效果。在这项任务上的表现是一个强有力的指标,它能够很好地说明这个模型是如何表达一个句子的意思的。我们针对英语训练NLI分类器,然后将其应用于所有目标语言,不需要进行微调或使用目标语言资源。在14种语言中,有8种语言的零样本性能表现在英语的5%以内,包括俄语、中文和越南语等。我们在斯瓦希里语和乌尔都语等低资源语言上也取得了很好的成绩。最后,LASER在14种语言中的13种语言上的表现优于所有以前的零样本迁移方法。
与之前的方法不同,之前的方法需要一个英语句子,而我们的系统是完全多语言的,并且支持不同语言的任意前提和假设组合。
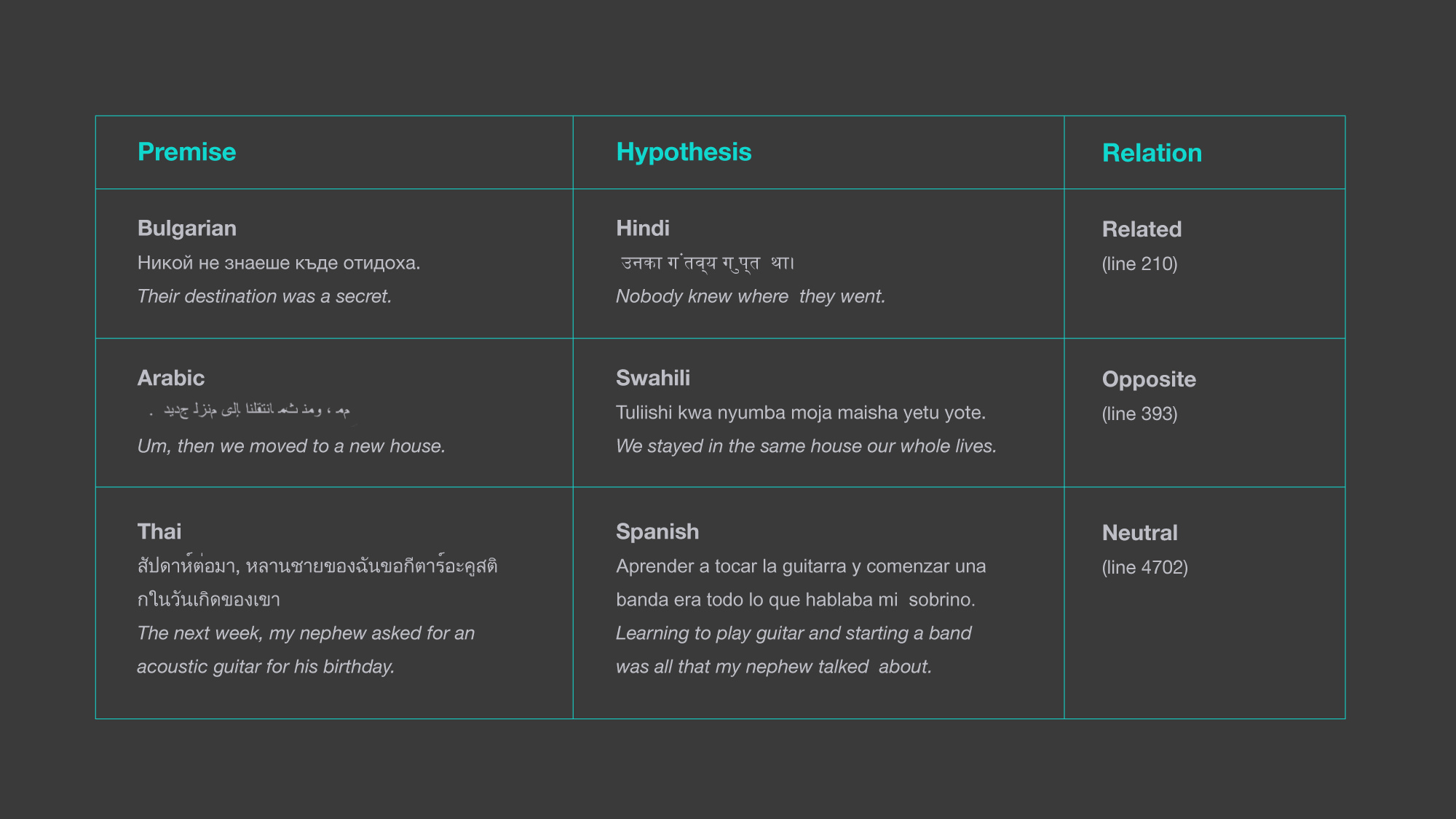
LASER如何在不同语言的XNLI语料库中确定句子之间的关系。以前的方法只考虑相同语言的前提和假设。
同样的句子编码器也被用于挖掘大量单语文本中的并行数据。我们只需要计算所有句子对之间的距离,并选择最接近的句子对。我们考虑了最近句子和其他最近句子之间的距离,以此来进一步改进该方法。我们使用了Facebook的 FAISS库来高效执行这个搜索。
我们在共享BUCC任务上的表现远远超过了现有水平。我们的系统明显是为完成这个任务而开发的。我们将德语/英语的F1得分从85.5提高到96.2,法语/英语从81.5提高到93.9,俄语/英语从81.3提高到93.3,汉语/英语从77.5提高到92.3。正如这些示例所示,我们的结果在所有语言中都是高度同质的。
该方法的详细信息可以在这篇研究论文中找到:https://arxiv.org/abs/1812.10464。
同样的方法也适用于使用任意语言对在90多种语言中挖掘并行数据。预计这将显著改善许多依赖于并行训练数据的NLP应用程序,包括低资源语言的神经机器翻译。
未来的应用
LASER还可以用于其他相关任务。例如,多语言语义空间特性可用于解释一个句子或搜索具有类似含义的句子——可以使用相同的语言,也可以使用LASER目前支持的93种其他语言中的任意一种。我们将继续改进我们的模型,在现有的93种语言基础上增加更多的语言。
英文原文:https://code.fb.com/ai-research/laser-multilingual-sentence-embeddings/
Facebook开源工具包LASER,支持93种语言相关推荐
- Facebook 开源工具包 LASER,支持 93 种语言
为了加速自然语言处理(NLP)在更多语言上进行零样本迁移,Facebook 扩展并增强了 LASER(Language-Agnostic SEntence Representations)工具包,并将 ...
- Facebook增强版LASER开源:零样本迁移学习,支持93种语言
来源| Facebook AI 研究院 译者 | Linstancy 责编 | 琥珀 出品 | AI 科技大本营(ID:rgznai100) [导语]为了加速自然语言处理 (NLP) 在更多语言上实现 ...
- Facebook 开源增强版 LASER 库:可实现 93 种语言的零样本迁移...
雷锋网 AI 科技评论按:去年 12 月份,Facebook 在论文中提出了一种可学习 93 种语言的联合多语言句子表示的架构,该架构仅使用一个编码器,就可以在不做任何修改的情况下实现跨语言迁移,为自 ...
- Facebook 开源增强版 LASER 库:可实现 93 种语言的零样本迁移
雷锋网 AI 科技评论按:去年 12 月份,Facebook 在论文中提出了一种可学习 93 种语言的联合多语言句子表示的架构,该架构仅使用一个编码器,就可以在不做任何修改的情况下实现跨语言迁移,为自 ...
- 让AI触类旁通93种语言:Facebook最新多语种句嵌入来了
夏乙 发自 凹非寺 量子位 出品 | 公众号 QbitAI 搞定一种语言之后,是不是很希望算法能在近百种语言上无缝迁移? AI真能无师自通,对于我们这些"因为语言不通而分散在各处" ...
- 在元宇宙里怎么交朋友?Meta发布跨语种交流语音模型,支持128种语言无障碍对话...
来源:AI前线 本文约1500字,建议阅读5分钟 本文为你介绍 XLS-R--一套用于各类语音任务的新型自监督模型. 改名 Meta 之后,Facebook 的元宇宙愿景正在一点点实现.这一次,Fac ...
- Meta发布支持128种语言的新语音模型:指向元宇宙跨语种交流,可在线试玩
晓查 发自 凹非寺 量子位 报道 | 公众号 QbitAI Facebook AI(bushi),更准确地说是Meta AI,刚刚发布了自监督语音处理模型XLS-R,共支持128种语言. 这项技术与M ...
- 有道智云智能语音服务全面升级 最多可支持44种语言和方言
原标题:有道智云智能语音服务全面升级 最多可支持44种语言和方言 有道智云·AI开放平台智能语音服务全面升级,支持40多个小语种的语音识别.及翻译!现在开通注册即送50元体验金免费体验!戳一下了解详情 ...
- ABBYY PDF Transformer+ Pro可以支持189种语言
2019独角兽企业重金招聘Python工程师标准>>> ABBYY PDF Transformer+ Pro版支持189种语言,包括我们人类的自然语言.人造语言以及正式语言.受支持的 ...
最新文章
- SSH框架实现仿淘宝购物demo
- 接口 500_python接口的自我修炼之路
- QuantLib 101之Swap
- 区间树(segment tree)
- cmd 取消点击锁定功能
- proto3与proto2的区别
- php lumen timestamp,Lumen 5.4 时区设置
- 中国移动MM的免流量费策略太不靠谱
- Linux查看网卡是千兆还是万兆网卡
- SD/SDHC卡下载UBOOT 的注意事项
- C/C++ 实验设备管理系统
- VS+Qt+C++银行排队叫号系统
- 引擎系列学习【一】Color Model(颜色模型)
- MySQL 架构与 SQL 执行流程
- DHT21程序,DHT21与DHT11的不同处
- 在Xcode中使用C++与Objective-C混编
- 04-20.eri-test GKE(Google K8S Engine)上的Intellij远程调试Java应用程序
- 2023最新SSM计算机毕业设计选题大全(附源码+LW)之java水果生鲜销售系统7826c
- 若多张表互为外键约束,如何删除
- GIT 无法拉取,因为存在未提交的更改。 在重新拉取前提交或撤消更改