零基础学python爬虫-我是如何零基础开始能写Python爬虫的

刚开始接触爬虫的时候,简直惊为天人,十几行代码,就可以将无数网页的信息全部获取下来,自动选取网页元素,自动整理成结构化的文件。
利用这些数据,可以做很多领域的分析、市场调研,获得很多有价值的信息。这种技能不为我所用实在可惜,于是果断开始学习。
- ❶ -并非开始都是最容易的
刚开始对爬虫不是很了解,又没有任何的计算机、编程基础,确实有点懵逼。从哪里开始,哪些是最开始应该学的,哪些应该等到有一定基础之后再学,也没个清晰的概念。
因为是 Python 爬虫嘛,Python 就是必备的咯,那先从 Python 开始吧。于是看了一些教程和书籍,了解基本的数据结构,然后是列表、字典、元组,各种函数和控制语句(条件语句、循环语句)。
学了一段时间,才发现自己还没接触到真正的爬虫呢,而且纯理论学习很快就忘了,回去复习又太浪费时间,简直不要太绝望。把 Python 的基础知识过了一遍之后,我竟然还没装一个可以敲代码的IDE,想想就哭笑不得。
- ❷ -开始直接上手
转机出现在看过一篇爬虫的技术文章后,清晰的思路和通俗易懂的语言让我觉得,这才是我想学的爬虫。于是决定先配一个环境,试试看爬虫到底是怎么玩的。(当然你可以理解为这是浮躁,但确实每个小白都想去做直观、有反馈的事情)
因为怕出错,装了比较保险的 Anaconda,用自带的 Jupyter Notebook 作为IDE来写代码。看到很多人说因为配置环境出各种BUG,简直庆幸。很多时候打败你的,并不是事情本身,说的就是爬虫配置环境这事儿。
遇到的另一个问题是,Python 的爬虫可以用很多包或者框架来实现,应该选哪一种呢?我的原则就是是简单好用,写的代码少,对于一个小白来说,性能、效率什么的,统统被我 pass 了。于是开始接触 urllib、美丽汤(BeautifulSoup),因为听别人说很简单。
我上手的***个案例是爬取豆瓣的电影,无数人都推荐把豆瓣作为新手上路的实例,因为页面简单且反爬虫不严。照着一些爬取豆瓣电影的入门级例子开始看,从这些例子里面,了解了一点点爬虫的基本原理:下载页面、解析页面、定位并抽取数据。
当然并没有去系统看 urllib 和 BeautifulSoup 了,我需要把眼前实例中的问题解决,比如下载、解析页面,基本都是固定的语句,直接用就行,我就先不去学习原理了。

用 urllib 下载和解析页面的固定句式
当然 BeautifulSoup 中的基本方法是不能忽略的,但也无非是 find、get_text() 之类,信息量很小。就这样,通过别人的思路和自己查找美丽汤的用法,完成了豆瓣电影的基本信息爬取。
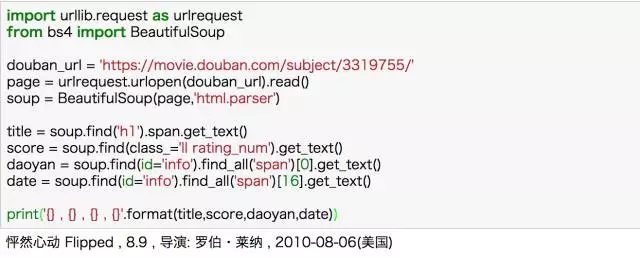
用 BeautifulSoup 爬取豆瓣电影详情
- ❸ -爬虫渐入佳境
有了一些套路和形式,就会有目标,可以接着往下学了。还是豆瓣,自己去摸索爬取更多的信息,爬取多部电影,多个页面。这个时候就发现基础不足了,比如爬取多个元素、翻页、处理多种情况等涉及的语句控制,又比如提取内容时涉及到的字符串、列表、字典的处理,还远远不够。
再回去补充 Python 的基础知识,就很有针对性,而且能马上能用于解决问题,也就理解得更深刻。这样直到把豆瓣的TOP250图书和电影爬下来,基本算是了解了一个爬虫的基本过程了。
BeautifulSoup 还算不错,但需要花一些时间去了解一些网页的基本知识,否则一些元素的定位和选取还是会头疼。
后来认识到 xpath 之后相见恨晚,这才是入门必备利器啊,直接Chrome复制就可以了,指哪打哪。即便是要自己写 xpath,以w3school上几页的 xpath 教程,一个小时也可以搞定了。requests 貌似也比 urllib 更好用,但摸索总归是试错的过程,试错成本就是时间。

requests+xpath 爬取豆瓣TOP250图书信息
- ❹ -跟反爬虫杠上了
通过 requests+xpath,我可以去爬取很多网站网站了,后来自己练习了小猪的租房信息和当当的图书数据。爬拉勾的时候就发现问题了,首先是自己的请求根本不会返回信息,原来要将自己的爬虫伪装成浏览器,终于知道别人代码中那一坨 headers 信息是干啥的了�。

在爬虫中添加 headers 信息,伪装成真实用户
接着是各种定位不到元素,然后知道了这是异步加载,数据根本不在网页源代码中,需要通过抓包来获取网页信息。于是在各种 JS、XHR的文件中 preview,寻找包含数据的链接。
当然知乎还好,本身加载的文件不多,找到了 json 文件直接获取对应的数据。(这里要安利一个chrome插件:jsonview,让小白轻松看懂 json 文件)
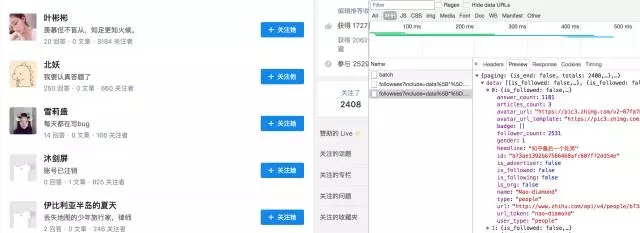
浏览器抓取 JavaScript 加载的数据
在这里就对反爬虫有了认识,当然这还是最基本的,更严格的IP限制、验证码、文字加密等等,可能还会遇到很多难题。但是目前的问题能够解决不就很好了吗,逐个击破才能更高效地学习。
比如后来在爬其他网站的时候就被封了IP,简单的可以通过 time.sleep() 控制爬取频率的方法解决,限制比较严格或者需要保证爬取速度,就要用代理IP来解决。
当然,后来也试了一下 Selenium,这个就真的是按照真实的用户浏览行为(点击、搜索、翻页)来实现爬虫,所以对于那些反爬虫特别厉害的网站,又没有办法解决,Selenium 是一个超级好用的东东,虽然速度稍微慢点。
- ❺ -尝试强大的 Scrapy 框架
有了 requests+xpath 和抓包大法,就可以做很多事情了,豆瓣各分类下的电影,58同城、知乎、拉勾这些网站基本都没问题。不过,当爬取的数据量级很大,而且需要灵活地处理各个模块的话,会显得很力不从心。
于是了解到强大的 Scrapy 框架,它不仅能便捷地构建 Request,还有强大的 Selector 能够方便地解析 Response,然而最让人惊喜的还是它超高的性能,可以将爬虫工程化、模块化。

Scrapy 框架的基本组件
学会 Scrapy,自己去尝试搭建了简单的爬虫框架,在做大规模数据爬去的时候能够结构化、工程化地思考大规模的爬取问题,这使我可以从爬虫工程的维度去思考问题。
当然 Scrapy 本身的 selector 、中间件、spider 等会比较难理解,还是建议结合具体的例子,参考别人的代码,去理解其中实现的过程,这样能够更好地理解。
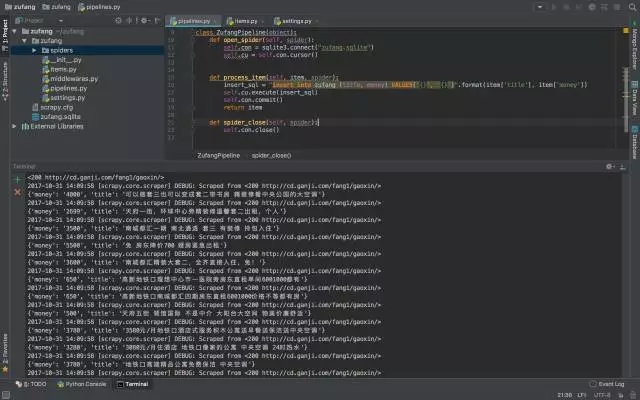
用 Scrapy 爬取了大量租房信息
- ❻ -本地文件搞不动了,上数据库
爬回来大量的数据之后就发现,本地的文件存起来非常不方便,即便存下来了,打开大文件电脑会卡得很严重。怎么办呢?果断上数据库啊,于是开始入坑 MongoDB。结构化、非结构化的数据都能够存储,安装好 PyMongo,就可以方便地在 Python 中操作数据库了。
MongoDB 本身安装会比较麻烦,如果自己一个人去折腾,很有可能会陷入困境。刚开始安装的时候也是出现各种BUG,幸得大神小X指点,解决了很多问题。
当然对于爬虫这一块,并不需要多么高深的数据库技术,主要是数据的入库和提取,顺带掌握了基本的插入、删除等操作。总之,能够满足高效地提取爬下来的数据就OK了。
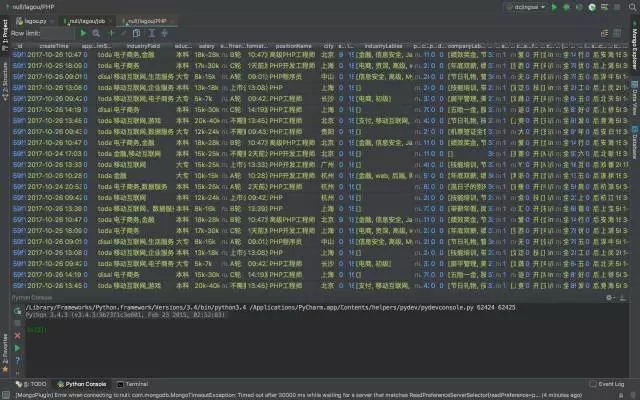
爬取拉勾招聘数据并用 MongoDB 存储
- ❼ -传说中的分布式爬虫
这个时候,基本上很大一部分的网页都能爬了,瓶颈就集中到爬取大规模数据的效率。因为学了 Scrapy,于是自然地接触到一个很厉害的名字:分布式爬虫。
分布式这个东西,一听不明觉厉,感觉很恐怖,但其实就是利用多线程的原理让多个爬虫同时工作,除了前面学过的 Scrapy 和 MongoDB,好像还需要了解 Redis。
Scrapy 用于做基本的页面爬取,MongoDB 用于存储爬取的数据,Redis 则用来存储要爬取的网页队列,也就是任务队列。
分布式这东西看起来很吓人,但其实分解开来,循序渐进地学习,也不过如此。
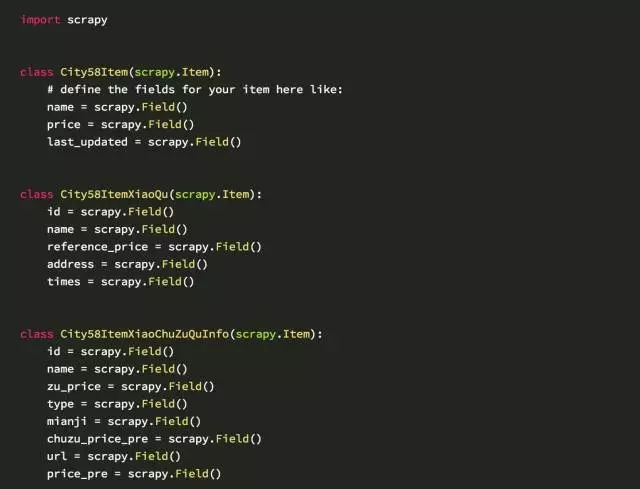
分布式爬58同城:定义项目内容部分
零基础学习爬虫,坑确实比较多,总结如下:
1.环境配置,各种安装包、环境变量,对小白太不友好;
2.缺少合理的学习路径,上来 Python、HTML 各种学,极其容易放弃;
3.Python有很多包、框架可以选择,但小白不知道哪个更友好;
4.遇到问题甚至不知道如何描述,更不用说去寻找解决办法;
5.网上的资料非常零散,而且对小白不友好,很多看起来云里雾里;
6.有些东西看似懂了,但结果自己写代码还是很困难;
……………………
所以跟我一样,很多人爬坑***的体会是:尽量不要系统地去啃一些东西,找一个实际的项目(从豆瓣这种简单的入手),直接开始就好。
【编辑推荐】
【责任编辑:庞桂玉 TEL:(010)68476606】
点赞 0
零基础学python爬虫-我是如何零基础开始能写Python爬虫的相关推荐
- 零基础学cad要多久_零基础学UI设计要学多久?能学会吗?
完全没有基础学习UI设计的你,是不是很想知道有没有什么速成的方法呢?想尽快成为UI设计师?零基础学UI设计要学多久?怎么学好?这些都是小白们十分关心的问题. 其实学习是没有什么速成方法的,只有适合自己 ...
- 零基础学cad要多久_零基础学一年日语能到n几,日语零基础到一级要学多久
零基础学一年日语能到n几?这个说不好,但是以你很努力的情况来说,一年时间是完全可以从零基础学到N1的. 学习分为两种情况:自学.报班.自学:时间成本高且效率低.不适合惰性群体每天学习四小时,每周五天, ...
- python工程师-我是如何转行成为了一名Python工程师
原标题:我是如何转行成为了一名Python工程师 我是14年毕业,专业是建筑环境与设备工程.当时由于不想做本专业画管道图纸工作,转到偏市场营销类的岗位.前两年在沈阳,后来朋友在北京开了一家空气净化器公 ...
- python 脑洞_从说韩语到写Python,这个数据媛的脑洞有毒吧
你好,Hello,안녕하세요, こんにちは,我是会说四门语言,但是日语可以忽略,韩语也差不多已经忘记,转而写R和Python的语言学迷妹聂大哥. 我要说的脑洞有毒的数据媛就是我计己,哈哈.正式入坑数据 ...
- python安卓版汉化版-手机随时随地写Python,还可以开发安卓APP,太厉害了!
python, 近五年最为火爆的编程语言,语法优雅,类库丰富,一行代码即可完成 Java 十行代码量. 本次,舞剑来推荐一款手机端使用 Python 的APP. QPython QPython是安卓上 ...
- python html做界面_用Html来写Python桌面软件的UI界面-htmlPy
在写Python软件的时候,一般用命令行就行了,但是某些特殊情况下(主管要求),需要写一个还能看的界面提供给客户的情况下,那就必须要用到Python的UI包. 试用了很多种: 因为一直用的Python ...
- 0基础学编程树莓派和python_零基础学编程:树莓派和Python
目录 第1 章 编程基础知识和环境准备 1 1.1 零基础的小白能学会编程吗 . 2 1.1.1 为什么要学编程 . 2 1.1.2 兴趣是最好的老师 . 3 1.1.3 为什么零基础的自学编程者,大 ...
- 0基础学编程树莓派和python_零基础学编程树莓派和Python
目录 第1 章 编程基础知识和环境准备 1 1.1 零基础的小白能学会编程吗 . 2 1.1.1 为什么要学编程 . 2 1.1.2 兴趣是最好的老师 . 3 1.1.3 为什么零基础的自学编程者,大 ...
- python 3 5_零基础学Python3(5):基础运算符(上)
人生苦短,我选Python 前文传送门 前言 前面我们讲了变量的基础操作,本文我们接着讲运算符. 运算符根据用途可以分为以下这么几类:算术运算符 比较运算符 赋值运算符 逻辑运算符 成员运算符 身份运 ...
最新文章
- Overlay 网络 — VxLAN 虚拟可扩展局域网协议
- python安装没有pip选项_python-3.x – 在ubuntu上没有pip的python安装
- Java 并发编程-不懂原理多吃亏(送书福利)
- Zabbix数据库需要多大硬盘
- boost::remove_copy_if相关的测试程序
- 容器学习 之 容器命令(八)
- 以Spring方式构建企业Java应用程序
- 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下!
- 电商场景下,如何处理消费过程中的重复消息?
- Black Hat | PE Tree:BlackBerry 发布PE文件开源逆向工具
- Scratch-Q版三国小人物角色素材分享,值得您的收藏!
- stm8单片机程序加密方法 id加密技巧
- 论文 查重 知网 万方 paperpass
- zebra扫码枪复位_条码扫描枪设置使用说明详解
- 网上邻居的计算机用户名与密码是什么,访问网上邻居需要用户名和密码解决办法...
- Windows系统自带工具介绍
- Matplotlib 箱线图
- 将正负值分别显示的函数
- CAD看图如何在电脑上快速找到并打开指定CAD图纸
- 【Jsp】第六课 Jsp简介和初步使用
热门文章
- java导出模板 pdf设置字体_有哪些相见恨晚的PPT模板网站?
- Java多线程闲聊(二):活锁和死锁
- DDOS SYN Flood攻击、DNS Query Flood, CC攻击简介——ddos攻击打死给钱。限网吧、黄网、博彩,,,好熟悉的感觉有木有...
- Kubernetes——自动扩展容器!假设你突然需要增加你的应用;你只需要告诉deployment一个新的 pod 副本总数即可...
- influx测试——单条读性能很差,大约400条/s,批量写性能很高,7万条/s,总体说来适合IOT数据批量存,根据tag查和过滤场景,按照时间顺序返回...
- mysql text 不可指定默认值
- docker 部署 nginx
- 2019春第一次课程设计实验报告
- 灵光一现的trick
- 事件驱动模式--Reactor