python爬虫招聘-Python爬虫抓取智联招聘(基础版)
原标题:Python爬虫抓取智联招聘(基础版)

作者:C与Python实战
「若你有原创文章想与大家分享,欢迎投稿。」
对于每个上班族来说,总要经历几次换工作,如何在网上挑到心仪的工作?如何提前为心仪工作的面试做准备?今天我们来抓取智联招聘的招聘信息,助你换工作成功!
运行平台:Windows
Python版本:Python3.6
IDE:Sublime Text
其他工具:Chrome浏览器
1、网页分析1.1 分析请求地址
以北京海淀区的python工程师为例进行网页分析。打开智联招聘首页,选择北京地区,在搜索框输入"python工程师",点击"搜工作":

接下来跳转到搜索结果页面,按"F12"打开开发者工具,然后在"热门地区"栏选择"海淀",我们看一下地址栏:

由地址栏后半部分searchresult.ashx?jl=北京&kw=python工程师&sm=0&isfilter=1&p=1&re=2005可以看出,我们要自己构造地址了。接下来要对开发者工具进行分析,按照如图所示步骤找到我们需要的数据:Request Headers和Query String Parameters:
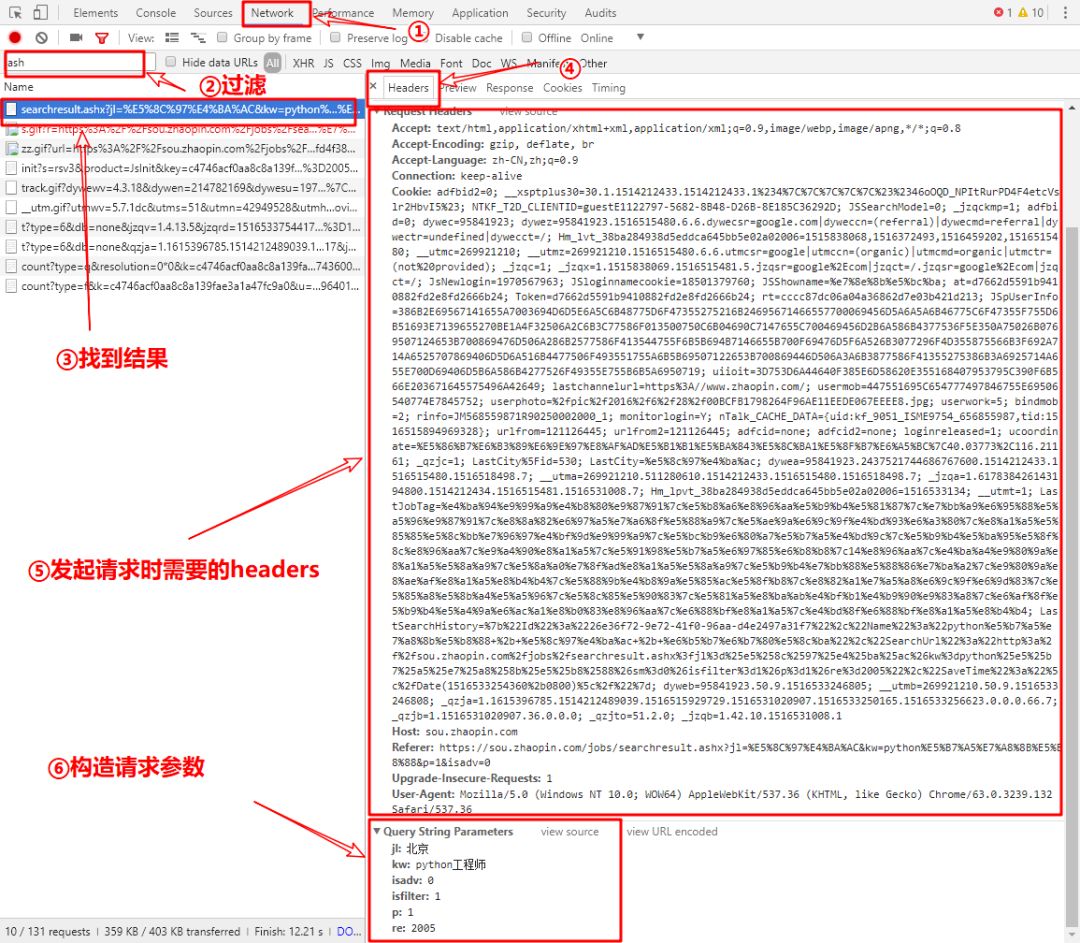
构造请求地址:
paras = {
'jl': '北京', # 搜索城市
'kw': 'python工程师', # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': 1, # 页数
're': 2005# region的缩写,地区,2005代表海淀
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?'+ urlencode(paras)
请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
1.2 分析有用数据
接下来我们要分析有用数据,从搜索结果中我们需要的数据有:职位名称、公司名称、公司详情页地址、职位月薪:

通过网页元素定位找到这几项在HTML文件中的位置,如下图所示:

用正则表达式对这四项内容进行提取:
# 正则表达式进行解析
pattern = re.compile(' (.*?) .*?' # 匹配职位信息
' (.*?) .*?' # 匹配公司网址和公司名称
' (.*?) ', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
注意:解析出来的部分职位名称带有标签,如下图所示:

那么在解析之后要对该数据进行处理剔除标签,用如下代码实现:
foritem initems:
job_name = item[ 0]
job_name = job_name.replace( '', '')
job_name = job_name.replace( '', '')
yield{
'job': job_name,
'website': item[ 1],
'company': item[ 2],
'salary': item[ 3]
}
2、写入文件
我们获取到的数据每个职位的信息项都相同,可以写到数据库中,但是本文选择了csv文件,以下为百度百科解释:
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
由于python内置了csv文件操作的库函数,所以很方便:
importcsv
defwrite_csv_headers(path, headers):
'''
写入表头
'''
withopen(path, 'a', encoding= 'gb18030', newline= '') asf:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
defwrite_csv_rows(path, headers, rows):
'''
写入行
'''
withopen(path, 'a', encoding= 'gb18030', newline= '') asf:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
3、进度显示
要想找到理想工作,一定要对更多的职位进行筛选,那么我们抓取的数据量一定很大,几十页、几百页甚至几千页,那么我们要掌握抓取进度心里才能更加踏实啊,所以要加入进度条显示功能。
本文选择tqdm 进行进度显示,来看一下酷炫结果(图片来源网络):

执行以下命令进行安装:pip install tqdm。
简单示例:
fromtqdm importtqdm
fromtime importsleep
fori intqdm(range( 1000)):
sleep( 0.01)
4、完整代码
以上是所有功能的分析,如下为完整代码:
#-*- coding: utf-8 -*-
importre
importcsv
importrequests
fromtqdm importtqdm
fromurllib.parse importurlencode
fromrequests.exceptions importRequestException
defget_one_page(city, keyword, region, page):
'''
获取网页html内容并返回
'''
paras = {
'jl': city, # 搜索城市
'kw': keyword, # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': page, # 页数
're': region # region的缩写,地区,2005代表海淀
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?'+ urlencode(paras)
try:
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers)
# 通过状态码判断是否获取成功
ifresponse.status_code == 200:
returnresponse.text
returnNone
exceptRequestException ase:
returnNone
defparse_one_page(html):
'''
解析HTML代码,提取有用信息并返回
'''
# 正则表达式进行解析
pattern = re.compile( '(.*?).*?'# 匹配职位信息
'
(.*?).*?'# 匹配公司网址和公司名称
'
(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
foritem initems:
job_name = item[ 0]
job_name = job_name.replace( '', '')
job_name = job_name.replace( '', '')
yield{
'job': job_name,
'website': item[ 1],
'company': item[ 2],
'salary': item[ 3]
}
defwrite_csv_file(path, headers, rows):
'''
将表头和行写入csv文件
'''
# 加入encoding防止中文写入报错
# newline参数防止每写入一行都多一个空行
withopen(path, 'a', encoding= 'gb18030', newline= '') asf:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
f_csv.writerows(rows)
defwrite_csv_headers(path, headers):
'''
写入表头
'''
withopen(path, 'a', encoding= 'gb18030', newline= '') asf:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
defwrite_csv_rows(path, headers, rows):
'''
写入行
'''
withopen(path, 'a', encoding= 'gb18030', newline= '') asf:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
defmain(city, keyword, region, pages):
'''
主函数
'''
filename = 'zl_'+ city + '_'+ keyword + '.csv'
headers = [ 'job', 'website', 'company', 'salary']
write_csv_headers(filename, headers)
fori intqdm(range(pages)):
'''
获取该页中所有职位信息,写入csv文件
'''
jobs = []
html = get_one_page(city, keyword, region, i)
items = parse_one_page(html)
foritem initems:
jobs.append(item)
write_csv_rows(filename, headers, jobs)
if__name__ == '__main__':
main( '北京', 'python工程师', 2005, 10)
上面代码执行效果如图所示:
执行完成后会在py同级文件夹下会生成名为:zl_北京_python工程师.csv的文件,打开之后效果如下:

- The End -
责任编辑:
python爬虫招聘-Python爬虫抓取智联招聘(基础版)相关推荐
- Python爬虫项目:抓取智联招聘信息
来自https://mp.weixin.qq.com/s/0SzLGqv2p0-IWSN3r8bOHA ''' Python爬虫之五:抓取智联招聘基础版 该文件运行后会产生一个代码,保存在这个Pyth ...
- Python爬虫:抓取智联招聘岗位信息和要求(进阶版)
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于腾讯云 作者:王强 ( 想要学习Python?Python学习交流群 ...
- python 爬虫学习:抓取智联招聘网站职位信息(二)
在第一篇文章(python 爬虫学习:抓取智联招聘网站职位信息(一))中,我们介绍了爬取智联招聘网站上基于岗位关键字,及地区进行搜索的岗位信息,并对爬取到的岗位工资数据进行统计并生成直方图展示:同时进 ...
- Python | 爬虫抓取智联招聘(基础版)
对于每个上班族来说,总要经历几次换工作,如何在网上挑到心仪的工作?如何提前为心仪工作的面试做准备?今天我们来抓取智联招聘的招聘信息,助你换工作成功! 运行平台: Windows Python版本: ...
- Python爬虫:抓取智联招聘岗位信息和要求(基础版)
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于腾讯云 作者:王强 ( 想要学习Python?Python学习交流群 ...
- 北京python爬虫招聘信息_Python爬虫:抓取智联招聘岗位信息和要求(基础版)
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于腾讯云 作者:王强 ( 想要学习Python?Python学习交流群 ...
- Python爬虫抓取智联招聘(基础版)
对于每个上班族来说,总要经历几次换工作,如何在网上挑到心仪的工作?如何提前为心仪工作的面试做准备?今天我们来抓取智联招聘的招聘信息,助你换工作成功! 运行平台: Windows Python版本: ...
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- python爬取智联招聘网_python爬取智联招聘工作岗位信息
1 # coding:utf-8 2 # auth:xiaomozi 3 #date:2018.4.19 4 #爬取智联招聘职位信息 5 6 7 import urllib 8 from lxml i ...
最新文章
- JS获取DOM元素的八种方法
- LintCode 402: Continuous Subarray Sum
- 中柏平板u盘启动_中柏电脑如何设置BIOS U盘启动
- linux服务端开发vs2012,Vs2012在Linux开发中的应用(1):开发环境
- 2.2大数据采集技术
- ict中的it和ct_ICT.Social – IT专业人员的社交网络
- php常用字体大小,推荐:PHP编辑器常用的几种字体下载
- 读书笔记:遇见未知的自己
- 牛客刷题记录之语法入门选择结构篇
- 解决安装Ubuntu系统卡在载入界面,显示正在安装open vm tools
- IOS 获取网络图片的大小 改变 图片色值 灰度什么的方法集合
- A. 贝壳找房性价比
- js 苹果手机点击事件 兼容
- Chapter3:根轨迹法(上)
- i.MX8MPlus中的CLK子系统
- 关于赛车游戏制作的一点体会
- Python读写文件rb,wb,ab模式
- Linux设备模型——设备驱动模型和sysfs文件系统解读笔记
- 从零开始搭建一个HTTPS网站
- 2020年高教社杯全国大学生数学建模竞赛C题 第一问详细解答+代码