在.NET中使用iTextSharp创建/读取PDF报告: Part I [翻译]
原文地址:Create/Read Advance PDF Report using iTextSharp in C# .NET: Part I By Debopam Pal, 27 Nov 2013
到PDF原文介绍了iTextSharp这个类库,并演示了一些基本的操作,基本属于入门级别的,可惜作者并没有在编写后续的文章。
恰好自己也在学习这个类库,想实现一个导出ASPX页面到PDF的功能,如作者所说,网上找到的示例好多都是针对旧版本iTextSharp编写的,还有些驴唇不对马嘴,而且,很多照抄的连验证都省了,一点价值都没有。这篇文章算是详实的入门文章,实例也都基本操作了一遍实现没有问题。
ps.:第一次翻译老外的文章,英语水平一般,有些地方词不达意,还望海涵,如果出入希望帮忙指出。
文章内容
- 简介
- 要求
- 安装步骤
- 6步创建PDF文档
- 关联PDF文档的页面大小
- 设置PDF文档背景色
- 设置PDF文档边距
- 设置PDF文档文字对齐方式
- 设置PDF文档的元信息或属性
- 创建多页文档
- 从已有文档创建新的PDF文档
- 使用Layer为PDF文档添加水印
- 使用Removing Layer移除刚刚创建Layer水印的PDF文档
- 在创建过程为每一页添加水印
- E在不存盘的情况下,导出/打印/输出PDF文件到客户端
下面内容是在更新版本后添加的: - 设置PDF浏览参数
- 加密PDF文档
- 声明
- 参考文献
- 历史
简介
最近我一直在寻找一个高级的工具来创建复杂的PDF报告用在C#.NET中,我找到了iTextSharp.主要的问题是iTextSharp.缺乏文档。好吧,有少量的C#代码例子,但是那些对初学者来说是不够的并且这些示例代码都是建立在iTextSharp的旧版本上,在最新版本上有很多变化。所以,对初学者来说转换旧版本到新版本比较困难。此外,我认为假如我写一篇关于iTextSharp的文章,它能帮助我同时也能作为日后的参考,我将为每一个功能点书写示例。老实说,在这篇文章,我编写的所有示例,你都能在《iText in Action, Second Edition》这本书的第一节找到,这本书是针对Java开发者编写的。我将在我的文章中解释[从java到c#]这本书余下章节的所有的示例.所以,如果有人对这个库(iTextSharp)感兴趣,这里将是一个好的开始。
想知道关于(iTextSharp)的更多细节,可以通过他们的官方网站了解
要求
- 编译这个类库,你需要一个C#2008(vs2008)编译器或者更高版本,Visual Studio 2008 or Visual C# 2008 Express Edition
- 这个库代码运行在:
- .NET 2.0
- .NET 3.0
- .NET 3.5
- .NET 4.0
- .NET 4.0 Client Profile
- .NET 4.5
- .NET 4.5 Client Profile
安装
- 你需要安装 NuGet package
或者 你可以从下面这个SourceForge的链接下载DLL,然后参照下面步骤:
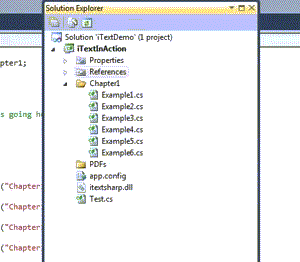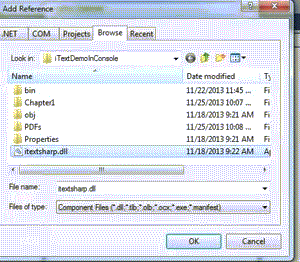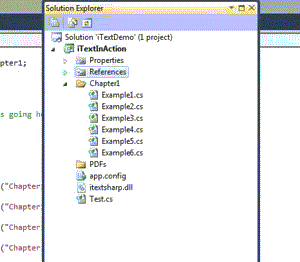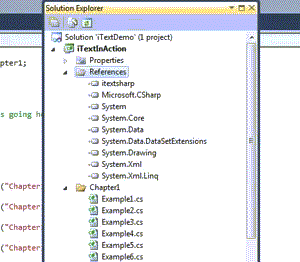
- 添加引用BlahBlah(步骤如下,翻译掠过). Just see the image below:
- 你需要引入到C#文件中的命名空间:
iTextSharp.textiTextSharp.text.pdf
快速入门
6步创建一个PDF文档:
- Step 1: 创建一个
System.IO.FileStream对象:
FileStream fs = new FileStream("Chapter1_Example1.pdf", FileMode.Create, FileAccess.Write, FileShare.None);
- Step 2: 创建一个
iTextSharp.text.Document对象:
Document doc = new Document();- Step 3: 创建一个
iTextSharp.text.pdf.PdfWriter对象: 它有助于把Document书写到特定的FileStream:
PdfWriter writer = PdfWriter.GetInstance(doc, fs);
- Step 4: 打开 Document:
doc.Open();
- Step 5: 创建一个 iTextSharp.text.Paragraph 对象并添加到Document里:
doc.Add(new Paragraph("Hello World"));
- Step 6: 关闭 Document:
doc.Close();
关联PDF文档的页面大小:
创建一个特定大小的页面,我们需要创建一个iTextSharp.text.Rectangle 对象同时传递一个页面大小的参数到它的构造函数里面,下面是定义页面大小的方法:
- 第一种定义一个版面大小的方式:
通过定义像素或者英寸定义一个页面尺寸。注意:在iTextSharp里面页面大小的单位是‘point。72point=1英寸。假设我们需要一个宽度=2英寸&高度=10英寸的PDF文件,那么我们需要144pt&72pt,让我们看下该怎么做:
Rectangle rec = new Rectangle(144, 720);
- 第二种定义版面大小的方式:
使用内建的iTextSharp.text.PageSize类定义:Rectangle rec2 = new Rectangle(PageSize.A4);
下面是内建的版面大小。. 完整的页面大小说明链接 Documentation of Page Size:
_11X17A0A1A10A2A3A4A4_LANDSCAPEA5A6A7A8A9ARCH_AARCH_BARCH_CARCH_DARCH_EB0B1B10B2B3B4B5B6B7B8B9CROWN_OCTAVOCROWN_QUARTODEMY_OCTAVODEMY_QUARTOEXECUTIVEFLSAFLSEHALFLETTERID_1ID_2ID_3LARGE_CROWN_OCTAVOLARGE_CROWN_QUARTOLEDGERLEGALLEGAL_LANDSCAPELETTERLETTER_LANDSCAPENOTEPENGUIN_LARGE_PAPERBACKPENGUIN_SMALL_PAPERBACKPOSTCARDROYAL_OCTAVOROYAL_QUARTOSMALL_PAPERBACKTABLOID
- 第三种定义版面大小的方式:
反转文档的高度变成宽度&反之亦然:Rectangle rec3 = new Rectangle(PageSize.A4.Rotate());
现在,把刚刚的这个 iTextSharp.text.Rectangle 对象 (任意一个)也就是上面的 'rec',或者 'rec2'或者 'rec3'加入iTextSharp.text.Document's 的构造函数中:
Document doc = new Document(rec);
设置PDF文档背景色:
有几种方式来设置背景色:
- 第一种方法:
需要使用对象iTextSharp.text.BaseColor. 实例化BaseColor 采用System.Drawing.Color (.NET)对象或者你也可以用传递RGB值的形式来定义:rec.BackgroundColor = new BaseColor(System.Drawing.Color.WhiteSmoke);
- 第二种方法:
需要使用对象iTextSharp.text.pdf.CMYKColor. CMYKColor 通过传递 CMYK 值的方式来构造:rec2.BackgroundColor = new CMYKColor(25, 90, 25, 0);
设置PDF文档边距:
页边距可以像设置版面大小一样来定义
加入我们设置如下的页边距:
- Left : 0.5 inch
- Right : 1 inch
- Top : 1.5 inch
- Bottom : 2.5 inch
所以我们需要分别设置页面的 Left, Right, Top, Bottom 页边距使用point单位,因为我们知道 iTextSharp 中是使用point作为单位的,并且 72 points = 1 inch.
- Left : 36pt => 0.5 inch
- Right : 72pt => 1 inch
- Top : 108pt => 1.5 inch
- Bottom : 180pt => 2.5 inch
实现如下:
Document doc = new Document(PageSize.A4, 36, 72, 108, 180);
设置PDF文档文字对齐方式:
Alignment 是iTextSharp.text.Paragraph对象的属性. iTextSharp 提供了各种对齐方式. 可以通过iTextSharp.text.Element 类设置对其.以下是iTextSharp提供的对齐方式:
ALIGN_BASELINE[^]ALIGN_BOTTOM[^]ALIGN_CENTER[^]ALIGN_JUSTIFIED[^]ALIGN_JUSTIFIED_ALL[^]ALIGN_LEFT[^]ALIGN_MIDDLE[^]ALIGN_RIGHT[^]ALIGN_TOP[^]ALIGN_UNDEFINED[^]
我们已经知道在 iTextSharp.text.Document 的构造函数中需要iTextSharp.text.Paragraph 对象,所以在创建Paragraph对象以后我们可以设置它的对齐方式,我们可以在Document创建过程把Prargraph传递进去.
实现如下:
Paragraph para = new Paragraph("Hello World Hello World Hello World Hello World Hello World Hello World Hello World Hello World Hello World Hello World Hello World");
// Setting paragraph's text alignment using iTextSharp.text.Element class
para.Alignment = Element.ALIGN_JUSTIFIED;
// Adding this 'para' to the Document object
doc.Add(para);
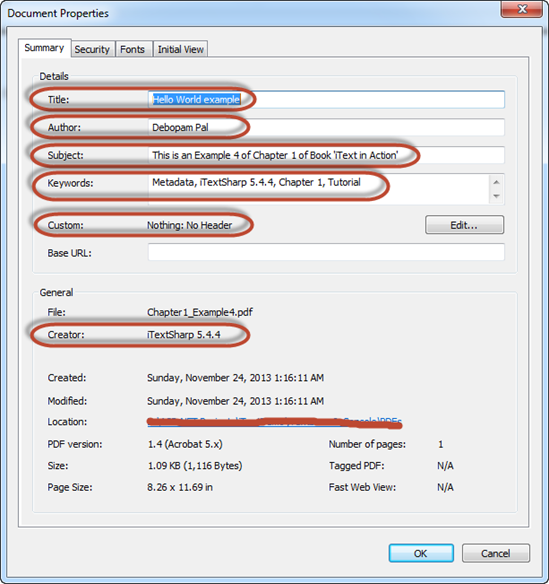
设置PDF文档的元信息或属性:
下面这些PDF文档的元信息 你可以通过iTextSharp.text.Document创建的对象doc(上文的doc)里面的方法来设置:
- Author Name[^]
- Creation Date[^]
- Creator Name[^]
- Header Name & Content[^]
- Keywords[^]
- Langugae[^]
- Producer[^]
- Subject[^]
- Title[^]
下面是他们的一些实现:
// Setting Document properties e.g.
// 1. Title
// 2. Subject
// 3. Keywords
// 4. Creator
// 5. Author
// 6. Header
doc.AddTitle("Hello World example");
doc.AddSubject("This is an Example 4 of Chapter 1 of Book 'iText in Action'");
doc.AddKeywords("Metadata, iTextSharp 5.4.4, Chapter 1, Tutorial");
doc.AddCreator("iTextSharp 5.4.4");
doc.AddAuthor("Debopam Pal");
doc.AddHeader("Nothing", "No Header");
现在,打开一个PDF文档后,右键->属性,你会看到刚才设置的信息:
创建多页文档:
我们可以通过iTextSharp.text.Document的NewPage()方法创建新页面,我们来创建5个PDF文档(页面) :
for (int i = 1; i <= 5; i++)
{doc.NewPage();doc.Add(new Paragraph(string.Format("This is a page {0}", i)));
}
从已有文档创建新的PDF文档:
我们可以使用iTextSharp.text.pdf.PdfReader对象读取一个PDF文档,然后使用 iTextSharp.text.pdf.PdfStamper对象来把它写到另一个PDF文档。实现如下:
string originalFile = "Original.pdf";
string copyOfOriginal = "Copy.pdf";
using (FileStream fs = new FileStream(originalFile, FileMode.Create, FileAccess.Write, FileShare.None))
using (Document doc = new Document(PageSize.LETTER))
using (PdfWriter writer = PdfWriter.GetInstance(doc, fs))
{doc.Open();doc.Add(new Paragraph("Hi! I'm Original"));doc.Close();
}
PdfReader reader = new PdfReader(originalFile);
using (FileStream fs = new FileStream(copyOfOriginal, FileMode.Create, FileAccess.Write, FileShare.None))
// Creating iTextSharp.text.pdf.PdfStamper object to write
// Data from iTextSharp.text.pdf.PdfReader object to FileStream object
using (PdfStamper stamper = new PdfStamper(reader, fs)) { }
使用Layer为PDF文档添加水印:
再iTextSharp中,PDF文档创建后可以添加水印,在这里我将使用iTextSharp.text.pdf.PdfLayer为已有的PDF文档(Original.pdf)添加水印。实现如下:
string watermarkedFile = "Watermarked.pdf";
// Creating watermark on a separate layer
// Creating iTextSharp.text.pdf.PdfReader object to read the Existing PDF Document
PdfReader reader1 = new PdfReader(originalFile);
using (FileStream fs = new FileStream(watermarkedFile, FileMode.Create, FileAccess.Write, FileShare.None))
// Creating iTextSharp.text.pdf.PdfStamper object to write Data from iTextSharp.text.pdf.PdfReader object to FileStream object
using (PdfStamper stamper = new PdfStamper(reader1, fs))
{// Getting total number of pages of the Existing Documentint pageCount = reader1.NumberOfPages;// Create New Layer for WatermarkPdfLayer layer = new PdfLayer("WatermarkLayer", stamper.Writer);// Loop through each Pagefor (int i = 1; i <= pageCount; i++){// Getting the Page SizeRectangle rect = reader1.GetPageSize(i);// Get the ContentByte objectPdfContentByte cb = stamper.GetUnderContent(i);// Tell the cb that the next commands should be "bound" to this new layercb.BeginLayer(layer);cb.SetFontAndSize(BaseFont.CreateFont(BaseFont.HELVETICA, BaseFont.CP1252, BaseFont.NOT_EMBEDDED), 50);PdfGState gState = new PdfGState();gState.FillOpacity = 0.25f;cb.SetGState(gState);cb.SetColorFill(BaseColor.BLACK);cb.BeginText();cb.ShowTextAligned(PdfContentByte.ALIGN_CENTER, watermarkText, rect.Width / 2, rect.Height / 2, 45f);cb.EndText();// Close the layercb.EndLayer();}
}
实现结果如下:

使用Removing Layer移除刚刚创建Layer水印的PDF文档:
Whenever we add Layer in PDF Document, then the content of the Layer resides under OCG Group. So if I remove this Layer we can remove the content of the Layer also e.g. here it is Watermark Text. To remove all the Layers from PDF Document, you have to remove OCG Group completely from the Document usingreader.Catalog.Remove(PdfName.OCPROPERTIES). Now follow the Steps below to remove the Watermark Text from Layer:
- Read the existing watermarked document using
iTextSharp.text.pdf.PdfReader's object - Taking each Page in the
iTextSharp.text.pdf.PdfDictionary's object usingGetPageN(int pageNumber)method ofiTextSharp.text.pdf.PdfReader's object. - Taking the Content of the Page in the
iTextSharp.text.pdf.PdfArray's object usingGetAsArray(PdfName.CONTENTS)method ofiTextSharp.text.pdf.PdfDictionary's object - Loop through this array and Get each element as
iTextSharp.text.pdf.PRStream's object usingGetAsStream(int arrayIndex)method ofiTextSharp.text.pdf.PdfArray's object - Convert each stream into Bytes using Static method
GetStreamBytes(PRStream stream)ofiTextSharp.text.pdf.PdfReaderclass - Convert these Bytes into String using
System.Text.Encoding.ASCII.GetString(byte[] bytes)method - Search for the String "/OC" and also the
Watermarked Text. If found then remove it by giving it zero length and zero data using two methods:Put()&SetData()ofiTextSharp.text.pdf.PRStreamclass - Write this modified document exists in the
readerto a new document usingiTextSharp.text.pdf.PdfStamper's object
Lets Implement it:
// Removing the layer created above
// 1. First we bind a reader to the watermarked file
// 2. Then strip out a branch of things
// 3. Finally use a simple stamper to write out the edited reader
PdfReader reader2 = new PdfReader(watermarkedFile);// NOTE: This will destroy all layers in the Document, only use if you don't have any addtional layers
// Remove the OCG group completely from the Document: reader2.Catalog.Remove(PdfName.OCPROPERTIES);// Clean up the reader, optional
reader2.RemoveUnusedObjects();// Placeholder variables
PRStream stream;
string content;
PdfDictionary page;
PdfArray contentArray;// Get the number of pages
int pageCount2 = reader2.NumberOfPages;// Loop through each page
for (int i = 1; i <= pageCount2; i++)
{// Get the pagepage = reader2.GetPageN(i);// Get the raw contentcontentArray = page.GetAsArray(PdfName.CONTENTS);if (contentArray != null){// Loop through contentfor (int j = 0; j < contentArray.Size; j++){stream = (PRStream)contentArray.GetAsStream(j);// Convert to a String, NOTE: you might need a different encoding herecontent = System.Text.Encoding.ASCII.GetString(PdfReader.GetStreamBytes(stream));//Look for the OCG token in the stream as well as our watermarked textif (content.IndexOf("/OC") >= 0 && content.IndexOf(watermarkText) >= 0){//Remove it by giving it zero length and zero datastream.Put(PdfName.LENGTH, new PdfNumber(0));stream.SetData(new byte[0]);}}}
}// Write the content out
using (FileStream fs = new FileStream(unwatermarkedFile, FileMode.Create, FileAccess.Write, FileShare.None))
using (PdfStamper stamper = new PdfStamper(reader2, fs)) { }
在创建过程为每一页添加水印:
Now, we already know that, watermark cannot be add during Page creation, it have to add after document creation. So, I've created a class PDFWriterEvents which implements the interface iTextSharp.text.pdf.IPdfPageEventand modify the event OnStartPage. This interface contains a set of events from the Openning & to Closing the PDF Document. The events are following:
public void OnOpenDocument(PdfWriter writer, Document document)public void OnCloseDocument(PdfWriter writer, Document document)public void OnStartPage(PdfWriter writer, Document document)public void OnEndPage(PdfWriter writer, Document document)public void OnParagraph(PdfWriter writer, Document document, float paragraphPosition)public void OnParagraphEnd(PdfWriter writer, Document document, float paragraphPosition)public void OnChapter(PdfWriter writer, Document document, float paragraphPosition, Paragraph title)public void OnChapterEnd(PdfWriter writer, Document document, float paragraphPosition)public void OnSection(PdfWriter writer, Document document, float paragraphPosition, int depth, Paragraph title)public void OnSectionEnd(PdfWriter writer, Document document, float paragraphPosition)public void OnGenericTag(PdfWriter writer, Document document, Rectangle rect, String text)
You may modify other events accroding to your needs which occured against a particular action. Let see the which I've created:
// Creating Watermark inside OnStartPage Event by implementing IPdfPageEvent interface
// So that, dusring Page Creation, Watermark will be create
class PDFWriterEvents : IPdfPageEvent
{string watermarkText;float fontSize = 80f;float xPosition = 300f;float yPosition = 800f;float angle = 45f;public PDFWriterEvents(string watermarkText, float fontSize = 80f, float xPosition = 300f, float yPosition = 400f, float angle = 45f){this.watermarkText = watermarkText;this.xPosition = xPosition;this.yPosition = yPosition;this.angle = angle;}public void OnOpenDocument(PdfWriter writer, Document document) { }public void OnCloseDocument(PdfWriter writer, Document document) { }public void OnStartPage(PdfWriter writer, Document document){try{PdfContentByte cb = writer.DirectContentUnder;BaseFont baseFont = BaseFont.CreateFont(BaseFont.HELVETICA, BaseFont.WINANSI, BaseFont.EMBEDDED);cb.BeginText();cb.SetColorFill(BaseColor.LIGHT_GRAY);cb.SetFontAndSize(baseFont, fontSize);cb.ShowTextAligned(PdfContentByte.ALIGN_CENTER, watermarkText, xPosition, yPosition, angle);cb.EndText();}catch (DocumentException docEx){throw docEx;}}public void OnEndPage(PdfWriter writer, Document document) { }public void OnParagraph(PdfWriter writer, Document document, float paragraphPosition) { }public void OnParagraphEnd(PdfWriter writer, Document document, float paragraphPosition) { }public void OnChapter(PdfWriter writer, Document document, float paragraphPosition, Paragraph title) { }public void OnChapterEnd(PdfWriter writer, Document document, float paragraphPosition) { }public void OnSection(PdfWriter writer, Document document, float paragraphPosition, int depth, Paragraph title) { }public void OnSectionEnd(PdfWriter writer, Document document, float paragraphPosition) { }public void OnGenericTag(PdfWriter writer, Document document, Rectangle rect, String text) { }
}
Lets see how & when you use the object of this class:
using (FileStream fs = new FileStream("Watermark_During_Page_Creation.pdf", FileMode.Create, FileAccess.Write, FileShare.None))
using (Document doc = new Document(PageSize.LETTER))
using (PdfWriter writer = PdfWriter.GetInstance(doc, fs))
{writer.PageEvent = new PDFWriterEvents("This is a Test");doc.Open();doc.Add(new Paragraph("This is a page 1"));doc.Close();
}
See, OnStartPage event called during adding a new paragraph. So I don't need to add watermark later
在不存盘的情况下,导出/打印/输出PDF文件到客户端:
We can create PDF File in memory by creatig System.IO.MemorySystem's object. Lets see:
using (MemoryStream ms = new MemoryStream())
using(Document document = new Document(PageSize.A4, 25, 25, 30, 30))
using(PdfWriter writer = PdfWriter.GetInstance(document, ms))
{document.Open();document.Add(new Paragraph("Hello World"));document.Close();writer.Close();ms.Close();Response.ContentType = "pdf/application";Response.AddHeader("content-disposition", "attachment;filename=First_PDF_document.pdf");Response.OutputStream.Write(ms.GetBuffer(), 0, ms.GetBuffer().Length);
}
设置PDF浏览参数:
The values of the different ViewerPreferences were originally stored in iTextSharp.text.pdf.PdfWriter class as an integer constant. You can set the ViewerPreferences by following two ways:
- By setting property
ViewerPreferencesofiTextSharp.text.pdf.PdfWriterclass. To know all theViewerPreferencesand its purpose, please read this first. E.g.-writer.ViewerPreferences = PdfWriter.HideMenubar;
- By calling method
AddViewerPreference(PdfName key, PdfObject value)ofiTextSharp.text.pdf.PdfWriter's object. To know whichvalueis appropiate for whichkey, read thisfirst. E.g.-writer.AddViewerPreference(PdfName.HIDEMENUBAR, new PdfBoolean(true));
加密PDF文档:
By SetEncryption() method of iTextSharp.text.pdf.PdfWriter's object, we can encrypt a PDF document. Read full documentation of this method here. To know all the encryption types, click here. E.g.-
writer.SetEncryption(PdfWriter.STRENGTH40BITS, null, null, PdfWriter.ALLOW_COPY);
声明
Please download the source code for detail. I hope you'll understand as the source code is documented. If any doubt, just post your comment below. Thank you.
参考文献
- iText Official Website
- iText in Action, Second Edition
- Core iText API Documentation
- RubyPdf Blog - iText# in Action
- Create PDFs in ASP.NET - getting started with iTextSharp
- Basic PDF Creation Using iTextSharp - Part I
历史
25th Nov, 2013: PART-I Release. PART-II will release soon
许可
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
转载于:https://www.cnblogs.com/buyixiaohan/p/3690341.html
在.NET中使用iTextSharp创建/读取PDF报告: Part I [翻译]相关推荐
- html如何读取pdf,html页面读取PDF小案例
html页面 引用 js添加 window.onload = function (){ var success = new PDFObject({ url: pdf文件路径 }).embed(&quo ...
- .net core 使用 iTextSharp 导入 Adobe Acrobat Pro 创建的PDF模板及生成表格,然后导出PDF
因为是第一次接触这种东西,对于我这个工作经验不到一年的新人程序员来说,头已经快爆炸了,在查询了"巨多"的资料后,终于给弄出来了 = = ,代码应该不是很好看,能跑就行( 创建PDF ...
- python中读取文件内容-深入学习python解析并读取PDF文件内容的方法
这篇文章主要学习了python解析并读取PDF文件内容的方法,包括对学习库的应用,python2.7和python3.6中python解析PDF文件内容库的更新,包括对pdfminer库的详细解释和应 ...
- python实现:读取PDF文件中的英文单词,并将前二十个高频词储存到一个docx文档中
总体思路如下: 1.读取PDF文件,将其中的英文单词提取出来 2.获得每个英文单词的词频,通过字典将英文单词及其词频配对 3.将英文单词按照词频由大到小排序 4.创建并写入docx文档 首先打开PDF ...
- Java 读取PDF中表格的工具
目录 1.方法1:Spire.PDF 1.1 Maven仓库下载导入 1.2 读取PDF中的表格 1.2.1 代码 1.2.2 表格内容 1.2.3 读取结果 2.方法2:Tabula 2.1 Mav ...
- java读取pdf_Java 读取PDF中的文本和图片的方法
本文将介绍通过Java程序来读取PDF文档中的文本和图片的方法.分别调用方法extractText()和extractImages()来读取. 使用工具:Free Spire.PDF for Java ...
- Spark _24 _读取JDBC中的数据创建DataFrame/DataSet(MySql为例)(三)
两种方式创建DataSet 现在数据库中创建表不能给插入少量数据. javaapi: package SparkSql;import org.apache.spark.SparkConf; impor ...
- 蜗牛爱课- iOS中plist的创建,数据写入与读取
iOS中plist的创建,数据写入与读取功能创建一个test.plist文件 -(void)triggerStorage { NSArray *paths=NSSearchPathForDir ...
- vb.net读取excel并写入dgv_读取PDF中的表格写入EXCEL?30行代码搞定
办公自动化系列+1 现在,各类数据分析的书籍,都可以在网上找到PDF版本: 同时,百度文库.各类数据统计文库.行业研究等众多论文报告,是通过PDF的形式去展示输出的: 但是,令人都头疼的是,各类数据分 ...
最新文章
- tf.data.Dataset.from_tensor_slices 的用法
- 如何判断照片是否ps
- iOS开发拓展篇——如何把项目托管到GitHub
- Python 数据科学入门
- 前端学习(1383):多人管理项目3
- 边缘计算精华问答 | 5G是否会“逼退”4G?
- mysql seconds_behind_master_MySQL中的seconds_behind_master的理解
- python opencv调用cuda_Win10使用VS2019从源码编译OpenCV 4.4 + CUDA 11.0 + Cudnn 8.0 + python3
- chrome jsp 显示不正常_selenium+java谷歌浏览器 网站打开不正常
- Openstack+Kubernetes+Docker微服务实践之路--基础设施
- Android 所遇问题(一)
- UDP socket编程: C++发送 | C#接收
- matlab如何仿真递推型dft算法,并联型有源滤波器的设计与仿真
- 思科ccnp网络工程师必备技能ICMPv6协议概述详解
- MacOS Aria2GUI配置
- 使用uniapp开发微信小程序的人脸采集功能/人脸识别功能
- 度数换算_视力表、近视度数换算方法(实用珍藏版)
- 最优化算法学习笔记+个人总结(一)
- 将来用NFC也能付支付宝、微信里的钱?NFC Forum发布一项新规范
- XFS,让新闻“真”起来