详细讲解MapReduce二次排序过程
2019独角兽企业重金招聘Python工程师标准>>> 
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hive等工具, 很少有再写MapReduce的了.
这里整理一下MapReduce中经常用到的二次排序的方法, 全当复习.
简介
二次排序(secondary sort)问题是指在Reduce阶段对某个键关联的值排序. 利用二次排序技术,可以对传入Reduce的值完成 升序/降序 排序.
MapReduce框架会自动对Map生成的键完成排序. 所以, 在启动Reduce之前,中间文件 key-value 是按照key有序的(而不是按照值有序). 它们的值得顺序有可能是任意的.
二次排序解决方案
对Reduce中的值排序至少有两种方案, 这两种方案在MapReduce/Hadoop 和 Spark框架中都可以使用.
- 第一种方案是让
Reduce读取和缓存给定key的所有的value, 然后在Reduce中对这些值完成排序.(例如: 把一个key对应的所有value放到一个Array或List中,再排序). 但是这种方式有局限性, 如果数据量较少还可以使用,如果数据量太大,一个Reduce中放不下所有的值,就会导致内存溢出(OutOfMemory). - 第二种方式是使用
MapReduce框架来对值进行排序. 因为MapReduce框架会自动对Map生成的文件的key进行排序, 所以我们把需要排序的value增加到这个key上,这样让框架对这个new_key进行排序,来实现我们的目标.
第二种方法小结:
- 使用值键转换设计模式:构造一个组合的中间key,
new_key(k, v1), 其中v1是次键(secondary key). - 让
MapReduce执行框架完成排序. - 重写分区器,使组合键
(k, v1)按照之前单独的k进行分区.
示例
假设有一组科学实验的温度数据如下:
有4列分别为: 年, 月, 日, 温度.
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30
2000,11,24,-40
2000,01,12,10
...
我们需要输出每一个年-月的温度,并且值按照升序排序.
所以输出如下:
(2000-11),[-40,20,30]
(2000-01),[10]
(2000-12),[-20,10]
MapReduce二次排序实现细节
要实现二次排序的特性,还需要一些java的插件类, 去告诉MapReduce框架一些信息:
- 如何对
Reduce的键排序. - 如何对
Map产出的数据进行分区,进到不同的Reduce. - 如何对
Reduce中的数据进行分组.
组合键的排序顺序
要实现二次排序, 我们需要控制组合键的排序顺序,以及Reduce处理键的顺序.
首先组合键的组成由(年-月 + 温度)一起组成, 如下图:
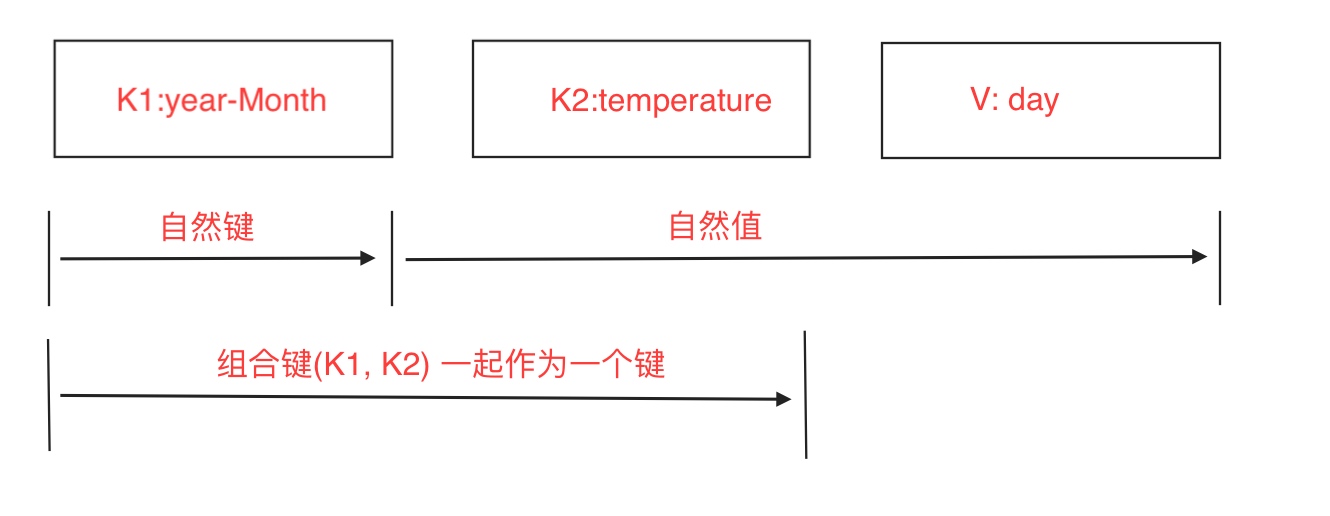 

把temperature的数据放到键中之后, 我们还要指定这个组合键排序方式. 使用DateTemperaturePair对象保存组合键, 重写其compareTo()方法指定排序顺序.
Hadoop中,如果需要持久存储定制数据类型(如DateTemperaturePair),必须实现Writable接口. 如果要比较定制数据类型, 他们还必须实现另外一个接口WritableComparable. 示例代码如下:
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
...
public class DateTemperaturePair implements Writable, WritableComparable<DateTemperaturePair> {private Text yearMonth = new Text(); //自然键private Text day = new Text();private IntWritable temperature = new IntWritable(); // 次键...@Override/*** 这个比较器将控制键的排序顺序* /public int compareTo(DateTemperaturePair pair) {int compareValue = this.yearMonth.compareTo(pair.getYearMonth());if (compareValue == 0) {compareValue = temperature.compareTo(pair.getTemperature());}return compareValue; //升序排序//return -1 * compareValue; //降序排序}
}
定制分区器
分区器默认会根据Map产出的key来决定数据进到哪个Reduce.
在这里,我们需要根据yearMonth来分区把数据入到不同的Reduce中, 但是我们的键已经变成了(yearMonth + temperature)的组合了. 所以需要定制分区器来根据yearMonth进行数据分区,把相同的yearMonth入到一个Reduce中. 代码如下:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class DateTemperaturePartitioner extends Partitioner<DateTemperaturePair, Text> {@Overridepublic int getPartition(DatetemperaturePair pair, Text text, int numberOfPartitions) {//确保分区数非负return math.abs(pair.getYearMonth().hashCode() % numberOfPartitions);}
}
Hadoop提供了一个插件体系,允许在框架中注入定制分区器代码. 我们在驱动累中完成这个工作,如下:
import org.apache.hadoop.mapreduce.Job;
...
Job job = ...;
...
job.setPartitionerClass(TemperaturePartitioner.class);
分组比较器
分组比较器会控制哪些键要分组到一个Reduce.reduce()方法中调用.
默认是按照key分配, 这里我们期望的是按照组合key(yearMonth + temperature) 中的yearMonth分配, 所以需要重写分组方法.
如下:
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class DateTemperatureGroupingComparator extends WritableComparator {public DateTemperatureGroupingComparator() {super(DateTemperaturePair.class, true);}@Override/*** 比较器控制哪些键要分组到一个reduce()方法调用*/public int compare(WritableComparable wc1, WritableComparable wc2) {DateTemperaturePair pair = (DateTemperaturePair) wc1;DateTemperaturePair pair2 = (DateTemperaturePair) wc12;return pair.getYearMonth().compareTo(pair2.getYearMonth());}
}
在驱动类中注册比较器:
job.setGroupingComparatorClass(YearMonthGroupingComparator.class);
使用插件的数据流
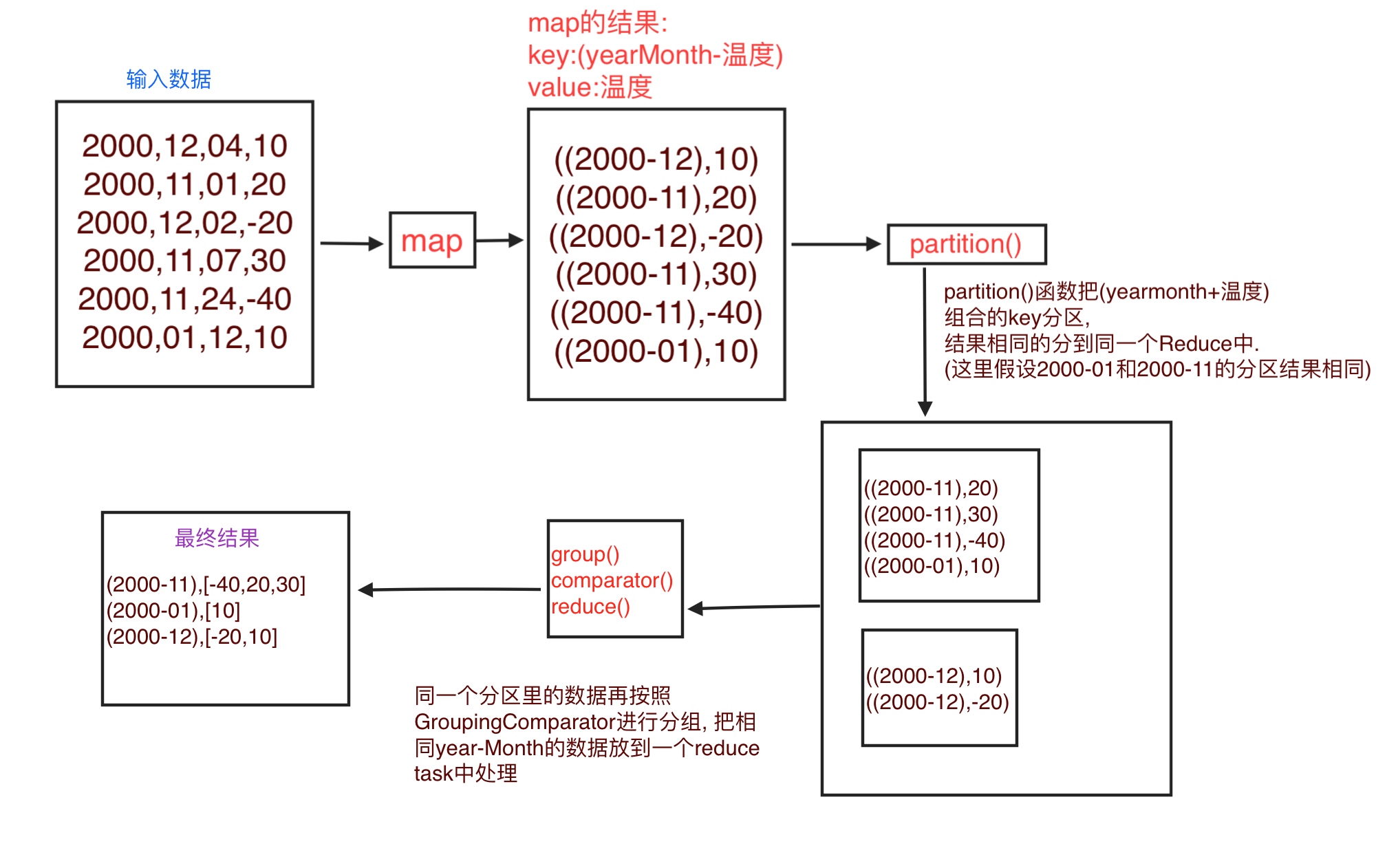 

原理总结
MapReduce框架默认会按照key来进行分区,排序,分组.
我们需要排序的时候使用key+value所以我们把key变成了新key, (firstkey, secondkey) 对应为(yearMonth, 温度) .
但是又不想在分区 和 分组的时候使用新key, 所以自己写了Partitioner 和 GroupingComparator 来指定使用组合key中的firstkey来分区,分组.
--Posted from Rpc
转载于:https://my.oschina.net/wangt10/blog/3050044
详细讲解MapReduce二次排序过程相关推荐
- 总结:详细讲解MapReduce过程(整理补充)
从启动和资源调度来看MapReduce过程 Hadoop 1.x版本 首先-先了解一下必知概念 From:MapReduce工作原理图文详解,JobTracker和TaskTracker概述 客户端( ...
- Hadoop Mapreduce分区、分组、二次排序过程详解
2019独角兽企业重金招聘Python工程师标准>>> 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partition ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - par ...
- MapReduce二次排序
2019独角兽企业重金招聘Python工程师标准>>> 默认情况下,Map输出的结果会对Key进行默认的排序,但是有时候需要对Key排序的同时还需要对Value进行排序,这时候就要用 ...
- Java Set接口详细讲解 TreeSet的定制排序和自然排序
Set接口概述 Set接口是Collection的子接口,set接口没有提供额外的方法 Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败. Set 判断 ...
- MapReduce二次排序分区,分组优化
自定义分组 NameGroup package test;import org.apache.hadoop.io.RawComparator; import org.apache.hadoop.io. ...
- hadoop之MapReduce自定义二次排序流程实例详解
一.概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的.在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求 ...
- 跨境电商如何向国外出售商品?流程详细讲解-跨境知道
相对于国内电商狼争虎斗,竞争激烈,跨境电商就是一块还待开垦的沃土. 虽然跨境电商比国内电商涉及的工作环节和流程复杂得多,但随着政策.平台.技术的发展与扶持,向国外出售商品的阻碍越来越少,很多掘金者都希 ...
- 推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF/TDM/Airbnb Embedding/Item2vec等)、召回路径简介、多路召回融合]
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排).系统架构.常见问题.算法项目实战总结.技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排 ...
最新文章
- 数据结构与算法(8-2)有序表查找(折半查找(二分查找)、插值查找)
- 计算机查找文件的速度,如何快速搜索文件_怎么加快电脑里的文件搜索速度
- Step by step通过online方式做product archiving
- 洛谷 P3469 [POI2008]BLO-Blockade (Tarjan,割点)
- iconsvg image怎么变为path_昆凌是怎么收服天王周杰伦的?这几招太高明了
- IntelliJ Idea学习笔记001--- IntelliJ Idea常用快捷键列表
- 部署Vista – 第2部分:理解Windows安装程序和Windows映像文件格式
- 判断一个字符串出现次数最多的字符,并返回这个字符和次数
- java ftp 250状态码_FTP状态码
- 无人机行业的机遇与挑战
- 比夏洛克还厉害:人工智能开始协助警方破案
- 基于python的opencv的学习
- 天气预报接口_001_天气预报API
- Excel只保留2位小数,删掉其他小数位
- Could not load extension class org.apache.cxf.transport.http_jetty.JettyDestinationFactory.
- React-Native 知识点小结
- 人机交互-1-人机交互概述
- python之np.narray与 list 相互转换
- 2021新年算法小专题—2.股票买卖利润(Java)
- 电竞专业与计算机专业,2021电竞专业的大学排名 电竞专业主要上什么课程
热门文章
- linux存储--从内核文件系统看文件读写过程(四)
- div css导航栏设计,CSS+DIV设计实例:超酷的竖排导航栏
- 云服务器如何导入文件,如何将文件导入云服务器中
- Bokeh中图形与组件的布局简介 | Bokeh 小册子
- 新口令范筹(Token Scope)- viewables:read
- Linux 最简单的驱动程序hello world
- 深入 理解 Statement 和 PreparedStatement
- [转:Pro ASP.NET MVC 5中的例子]使用MVC4,Ninject,EF,Moq,构建一个真实的应用电子商务SportsStore...
- solr4.1 DataImport MYSQL批量导入
- 《陶哲轩实分析》引理17.2.4证明_导数的唯一性