三种字符编码:ASCII、Unicode和UTF-8
什么是字符编码?
计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
ASCII编码:
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A 的编码是65,小写字母 z 的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
Unicode编码:
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
ASCII编码和Unicode编码的区别:
1)ASCII编码是1个字节,而Unicode编码通常是2个字节,举例如下。
字母 A 用ASCII编码是十进制的65,二进制的01000001;
字符 0 用ASCII编码是十进制的48,二进制的00110000,注意字符 '0' 和整数 0 是不同的;
汉字 中 已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
如果把ASCII编码的 A 用Unicode编码,只需要在前面补0就可以,因此, A 的Unicode编码是00000000 01000001。
UTF-8编码:
新问题的出现:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
因此,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | - | 01001110 00101101 |
11100100 10111000 10101101 |
从上面的表格可以发现UTF-8编码一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
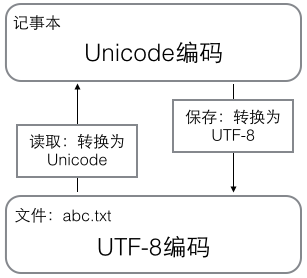
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
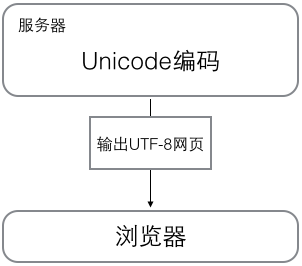
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
三种字符编码:ASCII、Unicode和UTF-8相关推荐
- 常见的三种字符编码ASCII、Unicode、UTF-8
发展史 ASCII 码 -> Unicode -> UTF-8 背景 计算机内部,信息都已二进制储存,每一个二进制位有 0 或 1 两种状态,采用 8 个 二进制位 (bit) 作为一个字 ...
- 字符编码:ASCII,Unicode(UTF-8)
1. ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte). ...
- 常见三种字符编码的区别:ASCII、Unicode、UTF-8
什么是字符编码? 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255( ...
- 一文带你弄懂C++中的ANSI、Unicode和UTF8三种字符编码及相互转换
目录 1.概述 2.Visual Studio中的字符编码 3.ANSI窄字节编码 4.Unicode宽字节编码 5.UTF8编码
- 字符编码 ASCII,Unicode和UTF-8的关系
转自:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143166410626 ...
- 编程通用知识 字符编码(ascii,unicode,utf-8)
ascii,unicode,utf-x都是文字和数字的映射, 因为计算机只能存储数字. ascii 1.早起用8位二进制来编码英文(最前面以为是0,实际只用了7位),既产生了128个元素的ascii码 ...
- 字符编码ASCII、Unicode 、UTF-8 及实例汉字与Unicode码的相互转化
字符编码ASCII.Unicode .UTF-8 及实例汉字与Unicode码的相互转化 ASCII 码 我们知道,计算机内部,所有信息最终都是一个二进制值.每一个二进制位(bit)有0和1两种状态, ...
- 字符编码、Unicode原理、数据流压缩Zlib与Miniz的实现
字符集和字符编码的区别和联系 字符集:多个字符的集合.例如 GB2312 是中国国家标准的简体中文字符集,GB2312 收录简化汉字(6763 个)及一般符号.序号.数字.拉丁字母.日文假名.希腊字母 ...
- 一种字符编码猜测工具的实现方法
2019独角兽企业重金招聘Python工程师标准>>> 摘要 自从进入计算机时代后,人们创造了许多编码,来表示各国的语言文字.这些编码从一开始设计时,就没有考虑到要和其它编码兼容,它 ...
最新文章
- 三层代码讲解--第一课
- 淘宝天猫网站停止支持IE6、IE7浏览器,你还在用xp吗?
- 几个经典的TCP通信函数
- [English20091217]英语口语444句
- 文件上传漏洞——upload-labs(1-10)
- qhfl-9 微信模板消息推送
- Vue.nextTick和Vue.$nextTick
- 《终身成长》读书笔记(part4)--创造性并不是出自灵感的神奇行为,而是努力工作和倾情奉献的结果
- Arduino笔记-WeMos D1开发环境搭建及亮灯
- 《江南》、乌镇、《似水年华》
- 重修 mongoDB 系列(一) 配置环境
- Unet实现文档图像去噪、去水印
- 【GIS导论】实验一 桌面GIS的功能与菜单操作
- 怎么解决计算机键盘驱动,解决键盘失灵、安装更新键盘驱动方法
- Sentaurus入门(1):工艺仿真
- 矩阵分析(2)--正规矩阵、正交矩阵
- 查看linux进程日志,查看linux日志_查看linux日志的方法
- 2021-10-17
- win10如何一键还原系统
- 人生需要执著——从二本三战到985博士