用Python深入理解跳跃表原理及实现
最近看 Redis 的实现原理,其中讲到 Redis 中的有序数据结构是通过跳跃表来进行实现的。第一次听说跳跃表的概念,感到比较新奇,所以查了不少资料。其中,网上有部分文章是按照如下方式描述跳跃表的:

这种描述便于理解,很容易让人理解到跳跃表是建立了类似索引的东西,从而提高效率的。但是,这样描述给人的感觉是,数据有多份存储,每份数据有两个指针,指向下层数据的指针和指向右面数据的指针。然而实际并不是这样的,实际的数据结构如下:

即:并非由多份数据,而是每份数据有多层指针。
那么,什么是跳跃表,跳跃表有什么特点呢?
- Skip lists are data structures that use probabilistic balancing rather than strictly enforced balancing. As a result, the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
从定义中可以看出,跳跃表是为了解决平衡树插入或者删除操作过于复杂而进行设计的。的确,平衡树在插入或者删除时,需要维持平衡而进行过多的操作,学过数据结构的同学想到平衡树、红黑树等都不寒而栗吧。而跳跃表则没有这种问题,采用了随机的思想简化了维持平衡的过程,而保持查找的时间复杂度依旧是O(log N)。
跳跃表有如下特点:
(1) 每个跳跃表由很多层结构组成;
(2) 每一层都是一个有序链表,且第一个节点是头节点;
(3) 最底层的有序链表包含所有节点;
(4) 每个节点可能有多个指针,这与节点所包含的层数有关;
(5) 跳跃表的查找、插入、删除的时间复杂度均为O(log N)。
从上面的结构也可以看出,跳跃表的核心思想就是,每一个节点既包含指向下一个节点的指针,也可能包含很多个指向后续节点的指针,这样在查找、插入、删除某个节点的过程中,可以避免一些不必要的节点,从而提高效率。
所以,每个节点的数据结构设计如下:
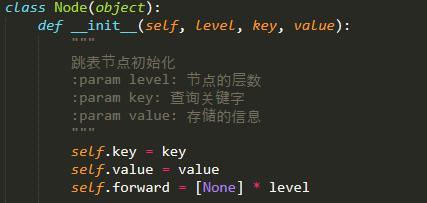
跳跃表的设计如下:

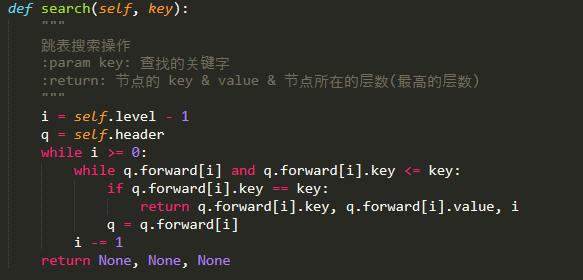
那么,如何进行查找呢?
假设查找5,那么在查找的过程中,需要从最高层开始查找(毕竟,越高层越表示索引嘛,很可能一下子就找到数据了),如果元素小于5,则一直向右查找。若遇到大于5的,则降低一层,在下一层继续查找。查找的流程如下图所示:

查找的代码如下:
插入的过程是怎么样的呢?
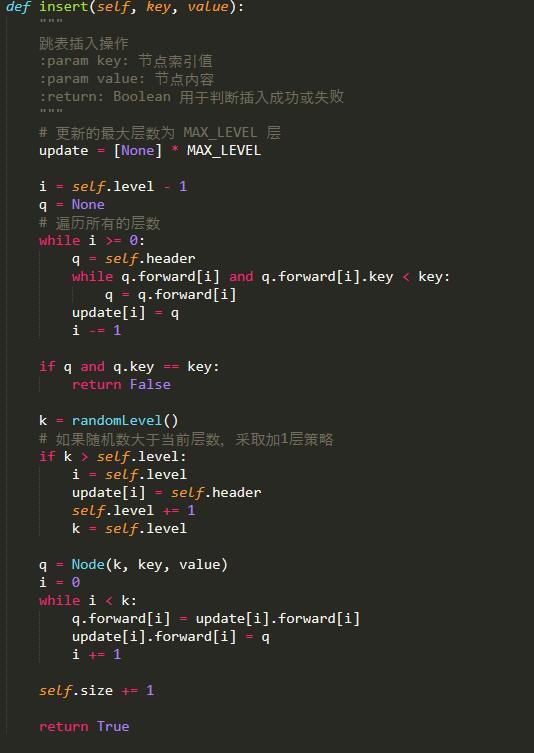
插入的过程包括如下4个步骤:
1、首先,需要找到每一层要插入节点的位置,并保存(用于后续调整指针);
2、确定该节点包含的层数,初始化要插入的节点;
3、相关的指针的调整;
4、若跳跃表层数增加,需要调整Header节点。
如下图,若要插入key 为4.5的节点,先要找到需要插入的位置,如图中黄线所示,然后随机生成一个层数(范围是1层到当前跳跃表层数+1,随机数生成器可以自行设计),初始化该节点,然后进行调整指针。

假设随机生成的层数为3,那么插入后为:

是不是比平衡树简单多了?当然,如果随机生成的层数为 当前跳跃表层数+1,那么跳跃表层数增加一层,header节点需要增加一层。
Python实现如下:
删除操作呢?跟插入操作类似,但是更为简单,只需要如下3个步骤:
1、首先,需要找到每一层要删除节点的位置,并保存(用于后续调整指针);
2、相关的指针的调整;
3、若层数减少,需要调整跳跃表层数和Header节点。
如果删除6这个节点,找到相应的位置,然后调整指针即可:

删除后的结果为:

Python代码实现为:
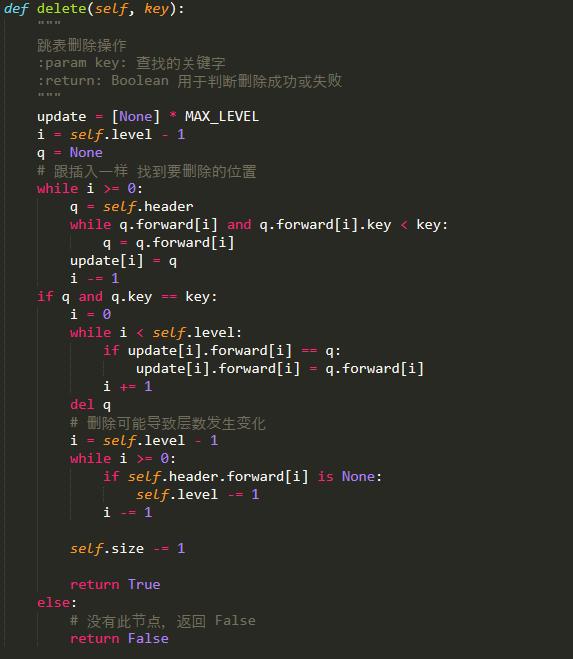
这里需要注意,如果删除元素后导致层数发生变化,那么需要对header节点进行调整的,即降低一层。
跳跃表的原理及实现你是否深入理解了?
转载于:https://www.cnblogs.com/python960410445/p/10299168.html
用Python深入理解跳跃表原理及实现相关推荐
- Redis 跳跃表原理
跳跃表 跳跃表 (skiplist) 是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针从而达到快速访问节点的目的. 跳跃表是 redis 有序集合 zset 的底层实现方式之一.(当元 ...
- 跳跃表 mysql_跳跃表原理与实践
---恢复内容开始--- 像是redis中有序集合就使用到了跳跃表. 场景:商品总数量有几十万件,对应数据库商品表的几十万条记录.需要根据不同字段正序或者倒叙做精确或全量查询,而且性能有硬性要求. 如 ...
- 跳跃表原理及redis跳跃表的应用
跳跃表的实现还是一个链表,是一个有序的链表,在遍历的时候基于比较,但普通链表只能遍历,跳跃表加入了一个层(也叫索引)的概念,层数越高的元素越少,每次先从高层查找,再逐渐降层,直到找到合适的位置.从图中 ...
- Redis中ZSet的底层数据结构跳跃表skiplist,你真的了解吗?
欢迎大家关注我的微信公众号[老周聊架构],Java后端主流技术栈的原理.源码分析.架构以及各种互联网高并发.高性能.高可用的解决方案. 一.前言 老周写这篇文章的初衷是这样的,之前项目中有大量使用 R ...
- redis跳跃表与二分查找
一 前言 本篇内容主要是讲解redis跳跃表的基础概念,科普一下读者知道有这种随机数据结构的概念,. 公众号:知识追寻者 知识追寻者(Inheriting the spirit of open sou ...
- Redis:只刷面试题,怎可能进大厂,多理解原理(跳跃表、集合、压缩列表)
aas Redis 没有直接使用C 语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串) ,而是自己构建了一种名为简单动态字符串(simple dynamic string, SDS ) ...
- Redis 为什么这么快? Redis 的有序集合 zset 的底层实现原理是什么? —— 跳跃表 skiplist
Redis有序集合 zset 的底层实现--跳跃表skiplist Redis简介 Redis是一个开源的内存中的数据结构存储系统,它可以用作:数据库.缓存和消息中间件. 它支持多种类型的数据结构,如 ...
- 跳跃表的原理和实现以及应用
目录 跳跃表的原理 跳跃表的实现步骤分析 代码实现 跳跃表的应用 跳跃表的原理 学过数据结构的都知道,在单链表中查询一个元素的时间复杂度为O(n),即使该单链表是有序的,我们也不能通过2分的方式缩减时 ...
- python模块之HTMLParser之穆雪峰的案例(理解其用法原理)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之HTMLParser之穆雪峰的案例(理解其用法原理) #http://www.cnblog ...
最新文章
- N35-第九周作业-张同学
- MySQL_项目7: 各部门工资最高的员工(难度:中等)
- ORM 一对一 以及csrf 的简单用法
- [cpp] 字符数组,字符指针,sizeof,strlen总结
- Exchange 2016 (登陸賬號匯出電子郵件地址)
- mybatis学习7之动态sql
- Javascript 面向对象编程定义接口的一种方法
- sql三张表的搜索要满足5种搜索条件的模糊搜索_面试三轮我倒在了一道 SQL 题上……| 原力计划...
- C# Memory Cache 踩坑记录
- Lua字符串及模式匹配
- Java设计模式学习02——工厂模式
- 小技巧 ----- 关于Java中的System.arraycopy()
- 飞天技术汇大视频专场:全民视频时代下的创新技术之路
- spark编程基础python版 pdf_《Spark编程基础(Scala版)》.PDF
- Ubuntu阿里源镜像
- 人工智能 - 语音识别的技术原理是什么
- nagios监控系统
- 人生感悟经典哲理句子,句句都是人生哲理!
- 【寻找最佳小程序】02期:腾讯旅游首款小工具“旅行小账本”——创意及研发过程大起底
- 李宏毅机器学习【深度学习】(0)【机器学习】