MIT自然语言处理第五讲:最大熵和对数线性模型(第一部分)
自然语言处理:最大熵和对数线性模型
Natural Language Processing: Maximum Entropy and Log-linear Models
作者:Regina Barzilay(MIT,EECS Department, October 1, 2004)
译者:我爱自然语言处理(www.52nlp.cn ,2009年4月25日)
上一讲主要内容回顾(Last time):
* 基于转换的标注器(Transformation-based tagger)
* 基于隐马尔科夫模型的标注器(HMM-based tagger)
遗留的内容(Leftovers):
a) 词性分布(POS distribution)
i. 在Brown语料库中按歧义程度排列的词型数目(The number of word types in Brown corpus by degree of ambiguity):
无歧义(Unambiguous)只有1个标记: 35,340
歧义(Ambiguous) 有2-7个标记: 4,100
2个标记:3,764
3个标记:264
4个标记:61
5个标记:12
6个标记:2
7个标记:1
b) 无监督的TBL(Unsupervised TBL)
i. 初始化(Initialization):允许的词性列表(a list of allowable part of speech tags)
ii. 转换(Transformations): 在上下文C中将一个单词的标记从χ变为Y (Change the tag of a word from χ to Y in context C, where γ ∈ χ).
例子(Example): “From NN VBP to VBP if previous tag is NNS”
iii. 评分标准(Scoring criterion):
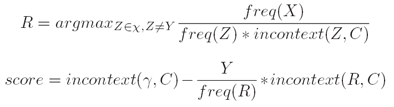
这一讲主要内容(Today):
* 最大熵模型(Maximum entropy models)
* 与对数线性模型的联系(Connection to log-linear models)
* 优化方法(Optimization methods)
一般问题描述(The General Problem):
a) 给定输入域χ(We have some input domain χ);
b) 给定标记集γ(We have some label set γ);
c) 目标(Goal):对于任何x ∈ χ 及 y ∈γ学习一个条件概率P(y|x) (learn a conditional probability P(y|x)for any x ∈ χ and y ∈ γ )。
一、 词性标注(POS tagging):
a) 例子:Our/PRP$ enemies/NNS are/VBP innovative/JJ and/CC resourceful/JJ ,/, and/CC so/RB are/VB we/PRP ?/?.
i. 输入域(Input domain):χ是可能的“历史”(χ is the set of possible histories);
ii. 标记集(Label set):γ是所有可能的标注标记(γ is the set of all possible tags);
iii. 目标(Goal):学习一个条件概率P(tag|history)(learn a conditional probability P(tag|history))。
b) 表现形式(Representation):
i. “历史”是一个4元组(t1,t2,w[1:n],i) (History is a 4-tuples (t1,t2,w[1:n],i);
ii. t1,t2是前两个标记(t1,t2 are the previous two tags)
iii. w[1:n]是输入句子中的n个单词(w[1:n]are the n words in the input sentence)
iv. i 是将要被标注的单词的位置索引(i is the index of the word being tagged)
χ是所有可能的“历史”集合(χis the set of all possible histories)
附:课程及课件pdf下载MIT英文网页地址:
http://people.csail.mit.edu/regina/6881/
转载于:https://www.cnblogs.com/renly/archive/2013/01/07/2849905.html
MIT自然语言处理第五讲:最大熵和对数线性模型(第一部分)相关推荐
- MIT自然语言处理第五讲:最大熵和对数线性模型
MIT自然语言处理第五讲:最大熵和对数线性模型(第一部分) 自然语言处理:最大熵和对数线性模型 Natural Language Processing: Maximum Entropy and Log ...
- MIT自然语言处理第三讲:概率语言模型(第一、二、三部分)
MIT自然语言处理第三讲:概率语言模型(第一部分) 自然语言处理:概率语言模型 Natural Language Processing: Probabilistic Language Modeling ...
- MIT自然语言处理第二讲:单词计数(第一、二部分)
MIT自然语言处理第二讲:单词计数(第一部分) 自然语言处理:单词计数 Natural Language Processing: (Simple) Word Counting 作者:Regina Ba ...
- MIT自然语言处理第四讲:标注
MIT自然语言处理第四讲:标注(第一部分) 自然语言处理:标注 Natural Language Processing: Tagging 作者:Regina Barzilay(MIT,EECS Dep ...
- MIT自然语言处理第一讲:简介和概述(第三部分)
自然语言处理:背景和概述 Natural Language Processing:Background and Overview 作者:Regina Barzilay(MIT,EECS Departm ...
- 【机器学习】对数线性模型之Logistic回归、SoftMax回归和最大熵模型
来源 | AI小白入门 作者 | 文杰 编辑 | yuquanle 完整代码见:原文链接 1. Logistic回归 分类问题可以看作是在回归函数上的一个分类.一般情况下定义二值函数,然而二值函数 ...
- MIT自然语言处理第三讲:概率语言模型(第四、五、六部分)
MIT自然语言处理第三讲:概率语言模型(第四部分) 自然语言处理:概率语言模型 Natural Language Processing: Probabilistic Language Modeling ...
- MIT自然语言处理第二讲:单词计数(第三、四部分)
MIT自然语言处理第二讲:单词计数(第三部分) 自然语言处理:单词计数 Natural Language Processing: (Simple) Word Counting 作者:Regina Ba ...
- 对数线性模型之一(逻辑回归), 广义线性模型学习总结
经典线性模型自变量的线性预测就是因变量的估计值. 广义线性模型:自变量的线性预测的函数是因变量的估计值.常见的广义线性模型有:probit模型.poisson模型.对数线性模型等等.对数线性模型里有: ...
最新文章
- linux日志idProduct,linux – 机器ID是uuid吗?
- centos8.2 hyper第一代 第二代_欧洲第一代法王以工程师身份加入拳头游戏,网友齐呼:是真的牛...
- ai的弹窗点了都不响应_【评价集合】拼多多评价,你所不知道的点都在这里!...
- 简单的视频采集demo
- Hive Fetch Task
- SVN错误:Attempted to lock an already-locked dir
- php随机数字不重复使等式成立_当随机数遇上量子
- DM368 Uboot
- oracle jet auto,如何启用sqlplus的AutoTrace功能
- php 微信支付md5签名,微信支付回调验证签名处理
- Spring基础面试题-同步更新
- Android开发笔记(一百七十一)使用Glide加载网络图片
- 数据库的范式总结(待续)
- Teamviewer 曝重大安全漏洞,攻击者可任意控制用户或属乌龙事件!(内附安全处理建议)...
- 合肥工业大学机器人技术期末_机器人技术基础期末考试复习资料
- 字体磅数与字号对照表
- 『paddle』paddleclas 学习笔记:图像识别
- 数据库身份证号用什么类型_《PHP和MySQL Web 开发》第8章 设计Web数据库
- 破解压缩包密码的正确思路原理
- c/c++游戏编程之Easyx图形库基础