关于机器学习中的一些常用方法的补充
前言
机器学习相关算法数量庞大,很难一一穷尽,网上有好事之人也评选了相关所谓十大算法(可能排名不分先后),它们分别是:
1. 决策树
2. 随机森林算法
3. 逻辑回归
4. 支持向量机
5. 朴素贝叶斯
6. K最近邻算法
7. C均值算法
8. Adaboost 算法
9. 神经网络
10. 马尔可夫
当然不同的评价标准会产生完全不同的结果,但上述10个算法在笔者看来可能还是比较靠谱的,因为至少它们具有一定的代表性。
在Spark的机器学习工具中(MLLIB),它将机器学习相关方法分为了四类:回归、聚类、分类及协同过滤,这种分类方法也比较合理;对于我们而言可能最为常见的就是回归、聚类及分类相关算法;例如最小二乘法、线性回归(包括岭回归及LASSO回归)、C均值聚类、混合高斯聚类、球面聚类、决策树及随机森林、朴素贝叶斯、二分类或多分类的支持向量机等,在笔者的文章中或多或少都有涉及,但目前未知对于神经网络还未进行更多的讨论,当然神经网络除了具有分类作用(无论是有监督、无监督还是半监督的方式,它还可以被用作编码或压缩(受限玻尔兹曼机,即RBM),这种应用就可能无法归类到上述任何四种方法中,类似的包括各类对数据降维(主成分分析或奇异值分解)或升维(最主要的是核方法)的算法,一般而言,它们不会被单独应用,而总是和其它方法一起使用。
在本文中,将会给出一些其它的、常见的机器学习相关方法,这主要包括用于分类的K近邻方法、用于规则挖掘的Apriori方法以及比较流行的出于Google的PageRank方法;其实还有一大类用于文本相关数据挖掘的方法,如TFIDF、LDA以及文本向量化方法Word2Vec等也是非常重要的机器学习方法,但笔者打算单独行文进行论述,因为它们还是有非常不同的特质。
K近邻分类
从本质而言,K近邻方法是一种分类算法,它可以不通过训练而达到对目标数据分类的效果;而它进行分类的依据实际上是还是根据空间的距离,至于是采用什么样的距离度量函数,则可以进行选择,但一般而言,还是使用欧氏空间下的欧氏距离,当然也可以使用曼哈顿距离或切比雪夫距离。
以下定义数据x和其近邻:

对于上述定而言,分母部分是一个常数K,就是对于数据x到底取几个近邻样本数据,而分子部分则表示,对于K个近邻而言,类别是i的个数;那么确定数据x到底属于哪个类别则就是通过类似投票的方式来确定,即在这些K的数据中,哪种类别数量多,则x就是相应的类别,形式化的表示如下:
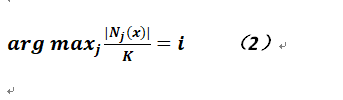
具体算法流程如下:
算法:K近邻算法
输入:训练数据集(这些数据包含类标)及其测试对象
输出:测试对象所述类别(假设共c个类别)
1. 根据给定的距离测度函数,在训练集中找到与测试对象最近邻的K个对象,对K个近邻分别统计它们所述类别数量;
2. 将测试对象归入数量最多的那个类。
当训练样本最够多时,最近邻算法能够取得较好的效果,而对于其错误率,相关人士也给出了判断。
令N个样本下最近邻的平均错误率为![]() ,样本x的最近邻为x',平均错误率则定义如下:
,样本x的最近邻为x',平均错误率则定义如下:
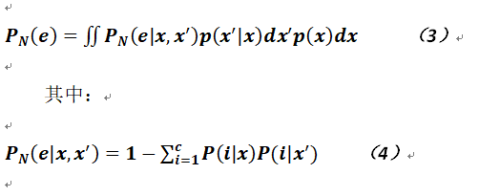
在公式4中的累加部分就是测试数据被正确分类的概率,而用1减去这个概率则显然就是分类错误了;对于公式3而言,只不过是一个贝叶斯公式而已,具体推导如下:
对于误差e及x和x'的联合分布,针对x和x'求取边缘分布并用贝叶斯公式展开(因为联合分布无法获得,而条件分布易于得到):
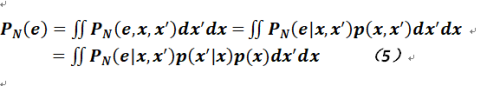
当样本数量趋向于无穷时,这个平均错误率将十分接近贝叶斯错误率。
以上就是经典的K近邻算法,而在这种算法中每个近邻对最终分类的决策都是等同的,但在一些场合下这个并不总是一定的,那么就可以考虑一种所谓加权的K近邻算法,当然这时如果K等于1就没有什么意义,一般情况下我们考虑根据距离进行加权,即距离查询点(就是之前的测试点)越近权值越大,而反之则离查询点越远权值越小,于是基于距离加权的K近邻分类方法表示如下:

从上面的分析可以看出,无论是经典的K近邻算法或者是距离加权K近邻算法,对于一个查询点而言,都需要遍历整个训练集,而且如果训练集及查询点的维度较高,则运算量会变得非常巨大,那么就有必要采取一些加速的方法,这里主要有几种:
其一,对于高维情况,可以采用特征的一个子集来计算数据之间的距离,而且可以优先选择方差较大的特征属性,显而易见,这样可以较为明显地减少计算量从而达到较快地进行分类的目的;
其二,直接将对分类毫无帮助的样本点删除,以达到缩减训练集的目的,从而减少运算量,也就是可以考虑删除被同类样本点包裹的那些数据;
其三,利用所谓kd树对训练数据进行预处理,其做法主要是不断地寻找各个属性的中位数所对应的样本,然后将其作为根节点,对数据进行两两分离,最后形成一个二叉搜索树,在查询时可以比原方法获得快得多的计算性能。
Apriori关联规则挖掘
就关联规则挖掘本身而言,可能无法归类于回归、聚类或分类这些范畴中,而可能和协同过滤倒是有些渊源(协同过滤中可能最为著名的应用便是推荐),Apriori也是笔者较早听说的数据挖掘的算法之一(主要是拜韩家炜教授的《数据挖掘》一书所赐),而另一个非常著名的算法可能就是KMeans(又被称作C均值)。
因为关联规则的挖掘似乎天生就和购物篮有关系?这里经常有个被已经玩坏的例子,就是“买啤酒时同时会买尿不湿”。关联规则的挖掘从本质上而言也是一类无监督的算法。
Apriori关联规则挖掘正是为了发现数据中可能存在的相关关系而提出的无监督方法(另外一类著名的无监督算法主要指数据聚类,受限玻尔兹曼机也是无监督的)。以下较为形式化地定义下这个关联规则挖掘问题。
令I={i1, i2, ... , im}是m个待研究的项(Item)构成的有限集合,现给定事务(Transaction)集合T={T1, T2, ..., Tn},其中对于事务集合中的每个元素而言,有Ti={ i1, i2, ... , ik},它是I的子集,被成为k-项集。如果对于I的子集X,存在事物T包含X,则成该事务T包含X。一条关联规则的形式如![]() ,其中X和Y都是I的子集,而且X和Y交集为空。
,其中X和Y都是I的子集,而且X和Y交集为空。
其实从上述较为形式化的定义可以直观地感受到,关联规则就是发现哪些事情会同时发生的!比如在超市购物时,哪些物品会被同时购买(就是上述那个烂大街的例子),但事情同时发生时到底是必然还是偶然呢?这可能只能从发生概率来解释了,以下就是关于关联规则的支持度和可信度定义。
关联规则的支持度定义为X与Y同时出现在一次事务中的可能性,由X项和Y项在样本数据集合中同时出现的事务数占总事务数的比例来定义,如下:

对于关联规则而言,只有同时满足一定的支持度和可信度阈值要求,方能作为正式的关联规则。
Apriori关联规则算法包含两个主要部分,其一是在给定的最小支持度阈值和数据下,在数据中寻找频度大于最小支持度的项集,超过最小支持度而且由k个项构成的集合称为k-大项集或大项集,使用符号Lk来记录之,Lk的项集又被成为频繁项集,而且一个k-项集的支持度超过最小支持度的必要条件是k-项集的全部子集都在k-大项集之中;算法第二部分是找出可信度超过阈值的项集。算法的核心主要在第一部分。
为了直观起见,以下先举个例子,以说明算法是如何工作的,此例子来源于王星等编著的《大数据分析:方法和应用》一书。
下表是一个购物篮数据,有5次购买记录。
|
购物篮序号 |
A |
B |
C |
|
T1 |
1 |
0 |
0 |
|
T2 |
0 |
1 |
0 |
|
T3 |
1 |
1 |
1 |
|
T4 |
1 |
1 |
0 |
|
T5 |
0 |
1 |
1 |
在上表中,Ti表示第i笔交易,如A=1则表示购买了物品A,否则没有购买。那么也可以使用下表来表示项集。
|
事务序号 |
项集 |
|
T1 |
A |
|
T2 |
B |
|
T3 |
ABC |
|
T4 |
AB |
|
T5 |
BC |
先假定支持度和可信度分别为0.4和0.6,则算法执行过程如下所示:
先搜索1-项集,找出频繁1-项集L1={A,B,C};
在频繁1-项集中生成2-项集,如{AB,BC,AC},然后在其上找出频繁2-项集:L2={AB,BC}
在频繁2-项集的基础上生成3-项集{ABC},然后在其上找出频繁3-项集,但是由于其已经低于设定的支持度阈值(支持度为0.2),故算法结束。
以下是算法的第二步,就是在频繁集的基础上找出关联规则,如下:
规则1:支持度0.4,可信度0.67,![]()
规则2:支持度0.4,可信度0.5,![]()
规则3:支持度0.4,可信度1,![]() (这里可信度为1就是因为只要出现项C就会出现项B)
(这里可信度为1就是因为只要出现项C就会出现项B)
对于第一部分频繁集的发现,比较形式化的算法描述如下(Ck为候选k-项集;这个算法步骤来源于较为原始的文档):
算法:Apriori频繁集发现
输入:交易数据,支持度阈值、可信度阈值
输出:频繁集
L1={频繁项集};
for(k=1; Lk is not null; k++) {
Ck+1 = 由Lk扩张生成;
for 每增加一个事务T do
对所有Ck+1中的项集,如果也包含T,则频数加1;
Lk+1 = Ck+1如果满足支持度大于等于最小支持度;
}
return ![]()
当然,关联规则挖掘的算法远不止一个Apriori,还有如GRI、Carma等算法,而且上述算法还不是最优形式。
PageRank
顾名思义,PageRank主要就是用于给网页排名之用的,它是Google创始人拉里佩奇和谢尔盖布林于1997年构建早期的搜索系统原型时提出的链接分析算法;该算法是一个对网页好坏的一个评估,其级别从0到10,一般一个网页有4分就不错了;其基本原理非常简单,就是某一页Pi的排名是根据其它链接它的页面Pj排名之和而得到的。
不过说起来较为简单,但实际上还不是那么容易,因为如果引用页面Pj同时又引用了其它页面则需要将排名得分其除以引用的页面数量,形式化的定义如下:
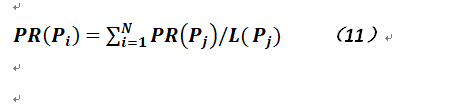
这里PR表示页面的排名,而L表示获取页面的链接数函数;显然对于一个页面组成的集合,可以定义一个矩阵来表示页面之间的链接情况,当被考察的页面相当之多时,这个矩阵就趋向于稀疏。
由于在实际情况中,存在一些页面不链接其它任何页面(即出度为零),而只被其它页面所链接,这样造成这个矩阵中存在相当多的零,则我们将公式修改为如下形式:

不过无论这个页面排名是什么样的形式,可以看出其解是一个向量,而对这个向量的求解过程就是PageRank的核心所在。
在求解之初,不失一般性的,我们先把解向量全部赋值成1,然后我们可以把页面之间的链接关系矩阵改写成一个概率转移矩阵(转移到几个页面,相应地其概率就是几分之几;如有三个需要评分的页面,其中A可以链接到B和C,而B可以链接到C,而C能链接到A,则A的跳转几率就是1/2、1/2,如此类推)。
现令矩阵:
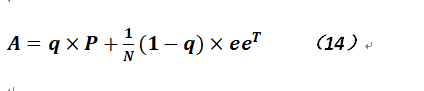
在上式中P就是概率转移阵,而e则是全1的列向量(那么![]() 就变为全1的矩阵,注意不是
就变为全1的矩阵,注意不是![]() ,否则结果就是一个实数),而令我们求解的网页排名向量为R,则R:
,否则结果就是一个实数),而令我们求解的网页排名向量为R,则R:
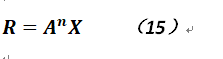
可以证明公式15,当n趋向于无穷时,X无限接近于R;其中道理在于:由于矩阵A是一个非常返的、不可约的(就是网页连通图中均是连通的,不存在孤立的图节点)近似马尔科夫概率转移阵,其定理保证了收敛性(一般关于随机过程论的著作上均有相关解释,这个应该也不用佩奇来证明吧,可能有些文献上讲到这个部分时有一定错误),而且这个方法保证了算法的鲁棒性,即无论X的初值取何初值,算法总会在若干步后收敛。
具体算法流程如下(以下使用幂法进行求解):
算法:求解PageRank
输入:网页及其链接关系
输出:网页排名
将X的初值全部设成1
R=AX;
while(true) {
if(||X-R||1 <ε){
return R;
} else {
X=R;
R=AX;
}
}
算法中||X-R||1<ε是用于判断算法是否收敛的条件,它可以使用向量的1范数(即各元素绝对值相加)。
当然,算法的难点并不在于其复杂性(其实好像算法本身一点也不复杂)或者其数学道理(这个类似马尔科夫转移阵的方法也没有多少深奥的道理),而在于当面对浩如烟海的页面时,这个矩阵就会变得异常稀疏,这对存储和计算都是巨大的挑战,故需要使用一些分布式计算方法进行处理;另外,在后来的实践中好像又添加了一些限制性的参数以防垃圾连接的存在。
转载于:https://blog.51cto.com/13345387/1980951
关于机器学习中的一些常用方法的补充相关推荐
- ML与Optimality:最优化理论(GD随机梯度下降/QN拟牛顿法/CG共轭梯度法/L-BFGS/TR置信域/GA遗传算法/SA模拟退火算法)在机器学习中的简介、常用方法、案例应用之详细攻略
ML与Optimality:最优化理论(GD随机梯度下降/QN拟牛顿法/CG共轭梯度法/L-BFGS/TR置信域/GA遗传算法/SA模拟退火算法)在机器学习中的简介.常用方法.案例应用之详细攻略 目录 ...
- Python机器学习中的数学原理详解(补充勘误表)
数学是机器学习和数据科学的基础,任何期望涉足相关领域并切实领悟具体技术与方法的人都无法绕过数学这一关.在一篇题为<放弃幻想,搞AI必须过数学关>的网文中,作者一针见血地指出想从事AI相关工 ...
- 机器学习中的相似性度量 (转)
在做分类时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间的"距离"(Distance).采用什么样的方法计算 ...
- 机器学习中的模型评价、模型选择及算法选择
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载. 正确使用模型评估.模型选择和算法选择技术无论是对机器学习学术研究还是工业场景应用都至关重要.本文将对这三个任务的相关技术 ...
- 10个例子带你了解机器学习中的线性代数
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达 转自:机器之心 本文介绍了 10 个常见机器学习案例,这些案例需要 ...
- 独家 | 机器学习中的四种分类任务(附代码)
作者:Jason Brownlee 翻译:陈丹 校对:杨毅远 全文约4400字,建议阅读18分钟 本文为大家介绍了机器学习中常见的四种分类任务.分别是二分类.多类别分类.多标签分类.不平衡分类,并提供 ...
- 深度解析机器学习中的置信区间(附代码)
作者:Jason Brownlee 翻译:和中华 校对:丁楠雅 本文约4000字,建议阅读15分钟. 本文介绍了置信区间的概念以及如何计算置信区间和bootstrap置信区间. 机器学习很多时候需要估 ...
- 应用在机器学习中的聚类数据集产生方法
简 介: 本文根据 机器学习中常用的聚类数据集生成方法 中的内容进行编辑实验和整理而得.并在之后对于聚类数据库生成进行不断的补充. 关键词: 机器学习,聚类算法,数据集合 §01 直接生成 这类方 ...
- 欧几里得范数_机器学习中的范数究竟是个什么鬼?
今天说一个深度学习和机器学习里面经常出现,但是未必人人都能 get 到直观感受的概念:范数,英文名叫 norm. 1.直观感受 本质上来讲,范数是用来衡量一个向量(vector)的规模的,我个人觉得中 ...
最新文章
- 芯片内亿万的晶体管制程工艺
- CCN:拥有雄厚实力的BCH将成为下一轮牛市的催化剂
- macbook Pro 上安装Windows 的方法(双系统运行)
- jQuey基础思维导图梳理1
- ubuntu18.04 更改apt源
- MPU6050开发 -- 卡尔曼滤波
- linux性能测试命令h,Linux性能测试 pmap命令详解
- 华为ensp小实验(路由下发+Easy IP+单臂路由+OSPF+Rip)
- Java Web的web.xml文件作用及基本配置(转)
- go java性能_服务端I/O性能大比拼:Node、PHP、Java和Go
- 修改Netbeas的注释结构
- matlab 散点 面,求大神指点绘制空间内散点图的包络面,,,散点程序如下
- Fiddler 抓包(一)—iOS
- Java面试题整理二(侧重SSH框架)
- 像程序员一样思考——解决问题
- nmap扫描常用命令
- 桌面级显卡天梯图(显卡性能对比图.2018.11)
- 斗鱼显示弹幕服务器连接失败,斗鱼看不到弹幕的解决方法步骤
- S7-1200使用集成库FB285控制G120变频器的基本步骤
- iOS微信实现第三方登录的方法