如何找到Kafka集群的吞吐量极限?\n
Kafka是非常流行的分布式流式处理和大数据消息队列解决方案,在技术行业已经得到了广泛采用,在Dropbox也不例外。Kafka在Dropbox的很多分布式系统数据结构中发挥着重要的作用:数据分析、机器学习、监控、搜索和流式处理,等等。在Dropbox,Kafka集群由Jetstream团队负责管理,他们的主要职责是提供高质量的Kafka服务。他们的一个主要目标是了解Kafka在Dropbox基础设施中的吞吐量极限,这对于针对不同用例做出适当的配置决策来说至关重要。最近,他们创建了一个自动化测试平台来实现这一目标。这篇文章将分享他们所使用的方法和一些有趣的发现。
更多干货内容请关注微信公众号“AI前线”(ID:ai-front)
测试平台
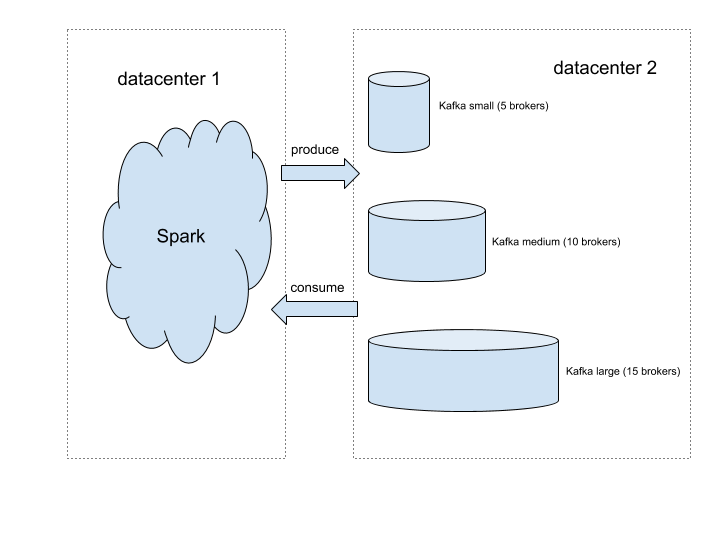
上图描绘了本文所使用的测试平台的设置。我们在Spark中使用Kafka客户端,这样就可以以任意规模生成和消费流量。我们搭建了三个不同大小的Kafka集群,要调整集群大小,只需要将流量重定向到不同的集群。我们创建了一个Kafka主题,用于生成测试流量。为简单起见,我们将流量均匀地分布在Kafka broker之间。为实现这一目标,我们创建了测试主题,分区数量是broker数量的10倍,这样每个broker都是10个分区的首领。因为写入单个分区是串行的,所以如果每个broker的分区太少会导致写入竞争,从而限制了吞吐量。根据我们的实验,10是一个恰到好处的数字,可以避免写入竞争造成吞吐量瓶颈。
由于基础设施的分布式特性,客户端遍布在美国的不同地区。因为测试流量远低于Dropbox网络主干的限制,所以我们可以安全地假设跨区域流量的限制也适用于本地流量。
是什么影响了工作负载?
有一系列因素会影响Kafka集群的工作负载:生产者数量、消费者群组数量、初始消费者偏移量、每秒消息数量、每条消息的大小,以及所涉及的主题和分区的数量,等等。我们可以自由地设置参数,因此,很有必要找到主导的影响因素,以便将测试复杂性降低到实用水平。
我们研究了不同的参数组合,最后得出结论,我们需要考虑的主要因素是每秒产生的消息数(mps)和每个消息的字节大小(bpm)。
流量模型
我们采取了正式的方法来了解Kafka的吞吐量极限。特定的Kafka集群都有一个相关联的流量空间,这个多维空间中的每一个点都对应一个Kafka流量模式,可以通过参数向量来表示:\u0026lt;mps、bpm、生产者数量、消费者群组数量、主题数量……\u0026gt;。所有不会导致Kafka过载的流量模式都形成了一个封闭的子空间,其表面就是Kafka集群的吞吐量极限。
对于初始测试,我们选择将mps和bpm作为吞吐量极限的基础,因此流量空间就降到二维平面。这一系列可接受的流量形成了一个封闭的区域,找到Kafka的吞吐量极限相当于绘制出该区域的边界。
自动化测试
为了以合理的精度绘制出边界,我们需要用不同的设置进行数百次实验,通过手动操作的方式是不切实际的。因此,我们设计了一种算法,无需人工干预即可运行所有的实验。
过载指示器
我们需要找到一系列能够以编程方式判断Kafka健康状况的指标。我们研究了大量的候选指标,最后锁定以下这些:
IO线程空闲低于20%:这意味着Kafka用于处理客户端请求的工作线程池太忙而无法处理更多工作负载。
同步副本集变化超过50%:这意味着在50%的时间内至少有一个broker无法及时复制首领的数据。
Jetstream团队还使用这些指标来监控Kafka运行状况,当集群承受过大压力时,这些指标会首当其冲发出信号。
找到边界
为了找到一个边界点,我们让bpm维度固定,并尝试通过更改mps值来让Kafka过载。当我们有一个安全的mps值和另一个导致集群接近过载的mps值时,边界就找到了。我们将安全的值视为边界点,然后通过重复这个过程来找到整条边界线,如下所示:
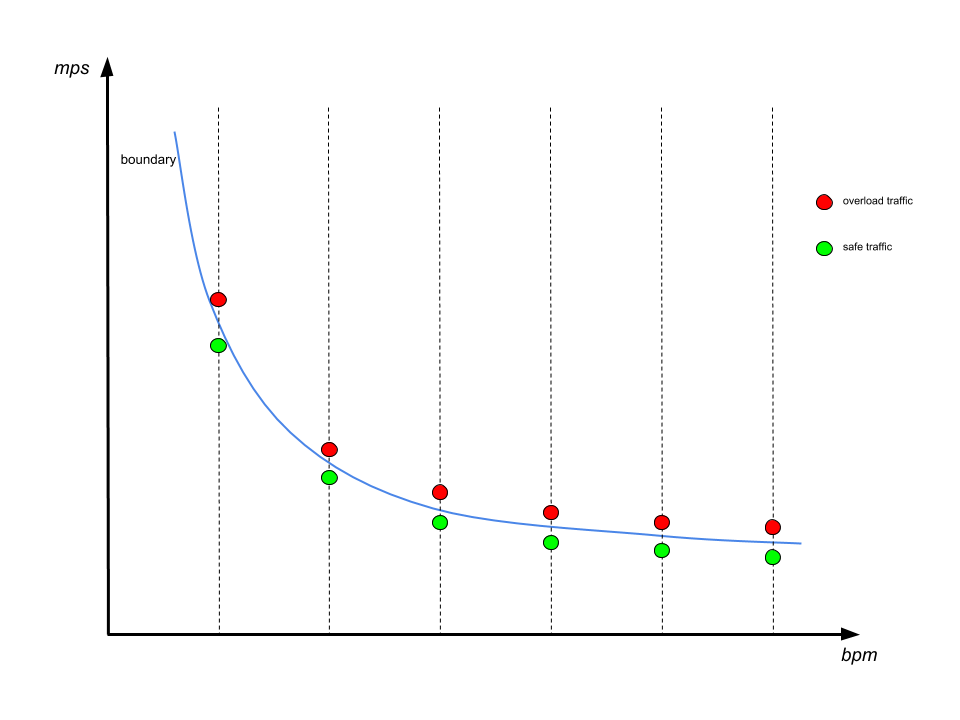
值得注意的是,我们调整了具有相同生产速率的生产者(用np表示),而不是直接调整mps。主要是因为批处理方式导致单个生产者的生产速率不易控制。相反,改变生产者的数量可以线性地缩放流量。根据我们早期的研究,单独增加生产者数量不会给Kafka带来明显的负载差异。
我们通过二分查找来寻找单边界点。二分查找从一个非常大的np[0,max]窗口开始,其中max是一个肯定会导致过载的值。在每次迭代中,选择中间值来生成流量。如果Kafka在使用这个值时发生过载,那么这个值将成为新的上限,否则就成为新的下限。当窗口足够窄时,停止该过程。我们将对应于当前下限的mps值视为边界。
结果
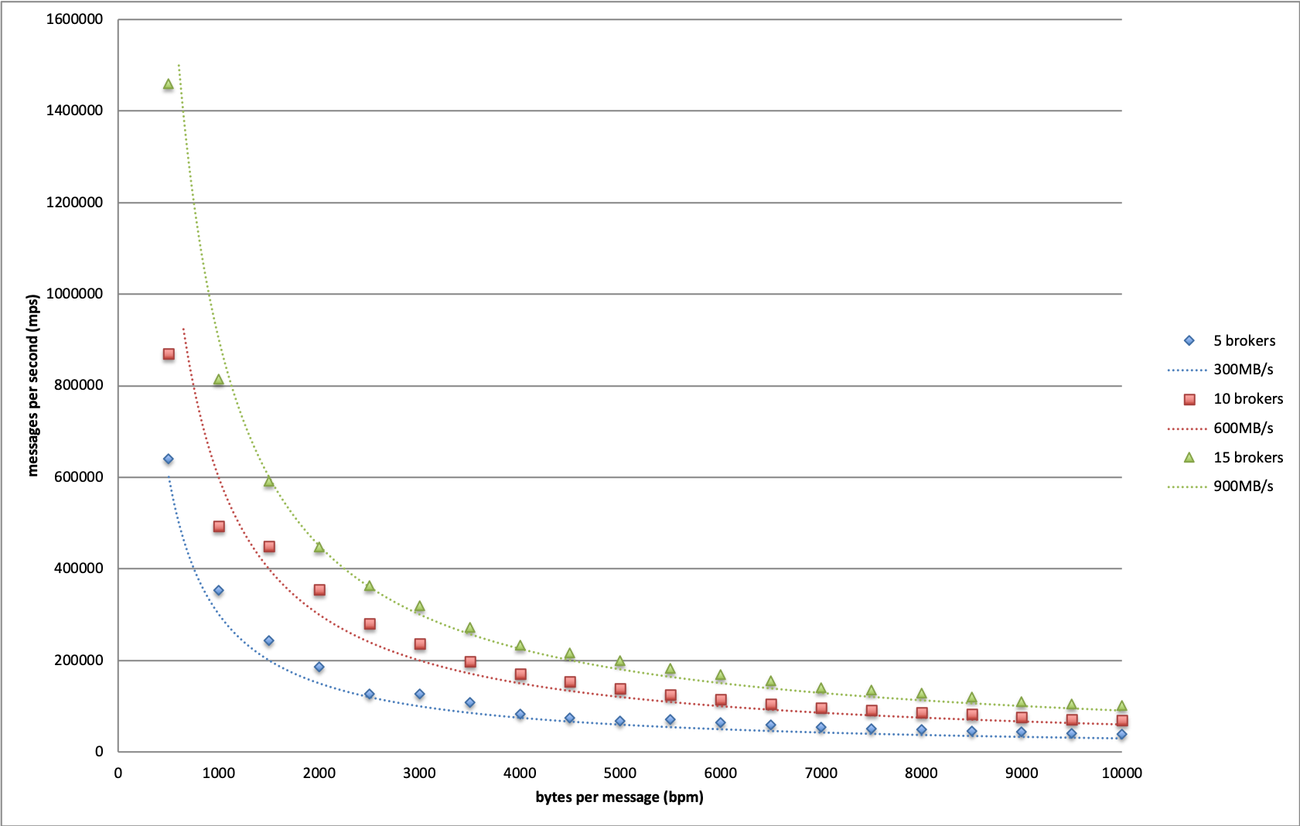
我们在上图中绘制了不同大小的Kafka的边界。基于这个结果,我们可以得出结论,Dropbox基础设施可以承受的最大吞吐量为每个broker 60MB/s。
值得注意的是,这只是一个保守的极限,因为我们测试用的消息大小完全是随机的,主要是为了最小化Kafka内部消息压缩机制所带来的影响。在生产环境中,Kafka消息通常遵循某种模式,因为它们通常由相似的过程生成,这为压缩优化提供了很大的空间。我们测试了一个极端情况,消息全部由相同的字符组成,这个时候我们可以看到更高的吞吐量极限。
此外,当有5个消费者群组订阅测试主题时,这个吞吐量限制仍然有效。换句话说,当读取吞吐量是当前5倍时,仍然可以实现这样的写入吞吐量。当消费者群组增加到5个以上时,随着网络成为瓶颈,写入吞吐量开始下降。因为Dropbox生产环境中的读写流量比远低于5,所以我们得到的极限适用于所有生产集群。
这个结果为将来的Kafka配置提供了指导基础。假设我们允许最多20%的broker离线,那么单个broker的最大安全吞吐量应为60MB/s * 0.8 ~= 50MB/s。有了这个,我们可以根据未来用例的估算吞吐量来确定集群大小。
对未来工作的影响
这个平台和自动化测试套件将成为Jetstream团队的一笔宝贵的财富。当我们切换到新硬件、更改网络配置或升级Kafka版本时,可以重新运行这些测试并获得新的吞吐量极限。我们可以应用相同的方法来探索其他影响Kafka性能的因素。最后,这个平台可以作为Jetstream的测试平台,以便模拟新的流量模式或在隔离环境中重现问题。
总结
在这篇文章中,我们提出了一种系统方法来了解Kafka的吞吐量极限。值得注意的是,我们是基于Dropbox的基础设施得到的这些结果,因此,由于硬件、软件栈和网络条件的不同,我们得到的数字可能不适用于其他Kafka实例。我们希望这里介绍的技术能够帮助读者去了解他们自己的Kafka系统。
英文原文:
https://blogs.dropbox.com/tech/2019/01/finding-kafkas-throughput-limit-in-dropbox-infrastructure/

如何找到Kafka集群的吞吐量极限?\n相关推荐
- 吞吐量达到瓶颈后下降_如何找到 Kafka 集群的吞吐量极限?
Kafka 是非常流行的分布式流式处理和大数据消息队列解决方案,在技术行业已经得到了广泛采用,在 Dropbox 也不例外.Kafka 在 Dropbox 的很多分布式系统数据结构中发挥着重要的作用: ...
- 几种常见的Kafka集群监控工具「送书」
本文选自电子工业出版社的新书<kafka进阶>,推荐一下. 送书规则:文末留言,精选精彩留言,对留言点赞最多的4位包邮送书一本~ 截止时间:2022.06.20 8:00 一个功能健全的 ...
- 如何查看kafka每个话题一共分了几个分区_如何决定kafka集群中话题的分区的数量...
http://blog.csdn.net/greenappple/article/details/50933872 如何决定kafka集群中topic,partition的数量,这是许多kafka用户 ...
- kafka 丢弃数据_20条关于Kafka集群应对高吞吐量的避坑指南
Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Relic(数据智能平台).Uber.Square(移动支付公司)等大型公司用来构建可扩展的.高吞吐量的.高可靠的实时数 ...
- ELK+Kafka集群日志分析系统
因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部署 3 2) Elasticsear ...
- 大数据 -- zookeeper和kafka集群环境搭建
一 运行环境 从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器.我们配置三台主机名分别为zy1,zy2,zy3. 我们通过阿里云可以获取主机的公网ip地址,如下: 通过secu ...
- 单机简单搭建一个kafka集群(没有进行内核参数和JVM的调优)
1.JDK安装 在我的部署单节点kafka的博客里有相关的方法.(https://www.cnblogs.com/ToBeExpert/p/9789486.html )zookeeper和kafka的 ...
- 10 Kafka集群与运维
Kafka集群与运维 10.1 集群应用场景 10.1.1 消息传递 Kafka可以很好地替代传统邮件代理.消息代理的使用有多种原因(将处理与数据生产者分离,缓冲未处理的消息等).与大多数邮件系统相比 ...
- 4.2.9 Kafka集群与运维, 应用场景, 集群搭建, 集群监控JMX(度量指标, JConsole, 编程获取, Kafka Eagle)
目录 3.1 集群应用场景 1 消息传递 2 网站活动路由 3 监控指标 4 日志汇总 5 流处理 6 活动采集 7 提交日志 总结 3.2 集群搭建 3.2.1 Zookeeper集群搭建 3.2. ...
最新文章
- Android之HttpClient 和HttpResponse 小结
- Java AIO 编程
- linux 升级centos7,Linux之从Centos 6.x 升级Centos7
- python自带的对称算法_一种基于对称算法和专用加载模块的Python程序模块加密方法...
- 浅析软件开发项目中的需求分析
- springcloud gateway介绍
- VMware Tools安装教程
- java 判断手机运营商_JS正则表达式判断手机号所属运营商
- JAVA后台对接苹果APNS(VOIP)实现推送
- 有哪些比较好用的录音软件【精品合集】
- 针对开放平台的架构理解
- 时空数据可视化_穿越时空的可视化4陆地导航的上半生
- python信号端点检测_语音信号端点检测
- java 获取今天或者某一天是星期几/周几以及几号的方法
- 小米/红米手机如何通过USB数据线把手机网络共享给电脑
- 【2020可用】Python使用 imaplib imapclient连接网易邮箱提示 Unsafe Login. Please contact kefu@188.com for help 的解决办法
- 帝特dt 5010/5011/5018驱动
- 打印机服务Print Spooler启动后又自动关闭的解决办法
- 输入月份查询对应的季节
- 双馈风力发电机直接功率控制simulink Matlab模型 采用直接功率控制的矢量控制策略