GitHub的MySQL高可用性实践
GitHub使用MySQL作为所有非git项目的主要数据存储,因此MySQL的可用性对于GitHub的运维来说至关重要。站点本身、GitHub的API、身份验证等都需要数据库访问。我们运行多个MySQL集群来服务我们的不同服务和任务。我们的集群使用经典的主-副设置,其中集群的单个节点(主节点)能够接受写操作。其它集群节点(副节点)异步更新主节点的变更并服务我们的读流量。
\\
主节点的可用性特别地重要。主节点不可用时,集群就不能接受写操作:任何需要持久化的写操作都不能被持久化。任何传入的变更,例如提交代码、提问题、用户创建、代码审查、新建代码库等等,都会失败。
\\
为了支持写操作,我们显然需要有一个可用的写节点,即集群的主节点。但同样重要的是,我们需要能够识别,或者发现,那个节点。
\\
遇到一个故障时,比如主节点崩溃的场景,我们必须确保存在一个新的主节点,并且能够快速通告其身份。检测故障、运行故障恢复以及通告新主节点身份所花费的时间组成了总宕机时间。
\\
本文阐述了GitHub的MySQL高可用性和主服务发现解决方案,这个方案使得我们能够可靠地进行跨数据中心运维、克服数据中心隔离的影响并实现故障时的短宕机时间。
\\
高可用性目标
\\
本文描述的解决方案是对GitHub先前实现的高可用性(HA)解决方案的迭代和改进。随着我们规模的扩大,我们的MySQL HA策略必须适应变化。我们希望对我们的MySQL和GitHub的其它服务运用相似的HA策略。
\\
当考虑高可用性和服务发现时,一些问题可以指导你找到一个恰当的解决方案。这些问题包括但不限于:
\\
- 你能容忍的宕机时间是多久?\\t
- 崩溃检测的可靠性如何?你能容忍假阳性(过早进行故障恢复)吗?\\t
- 故障恢复的可靠性如何?它在哪些情况下会失败?\\t
- 解决方案跨数据中心能力如何?在低延迟和高延迟网络的能力如何?\\t
- 解决方案能克服完整的数据中心故障或网络隔离的影响吗?\\t
- 如果有的话,什么机制能够防止或减轻脑裂现象(两个服务器都宣称是指定集群的主节点,都独立地彼此无意识地接受写操作)?\\t
- 你能够承受数据丢失吗?到什么程度?\
为了说明上述一些问题,让我们先看一下我们之前的HA迭代以及为什么我们要改变它。
\\
远离基于VIP和DNS的服务发现
\\
在我们之前的迭代中,我们使用:
\\
- orchestrator用于故障监听和故障恢复\\t
- VIP和DNS用于发现主节点\
在那个迭代中,客户端通过使用一个名称,例如mysql-writer-1.github.net来发现写节点。这个名称解析为主节点获取的虚拟IP地址(Virtual IP address,VIP)。
\\
因此,平常的时候,客户端会只解析这个名称,连接解析到的IP地址,然后找到正在另一端监听的主节点。
\\
这个副本拓扑,跨越3个不同的数据中心:
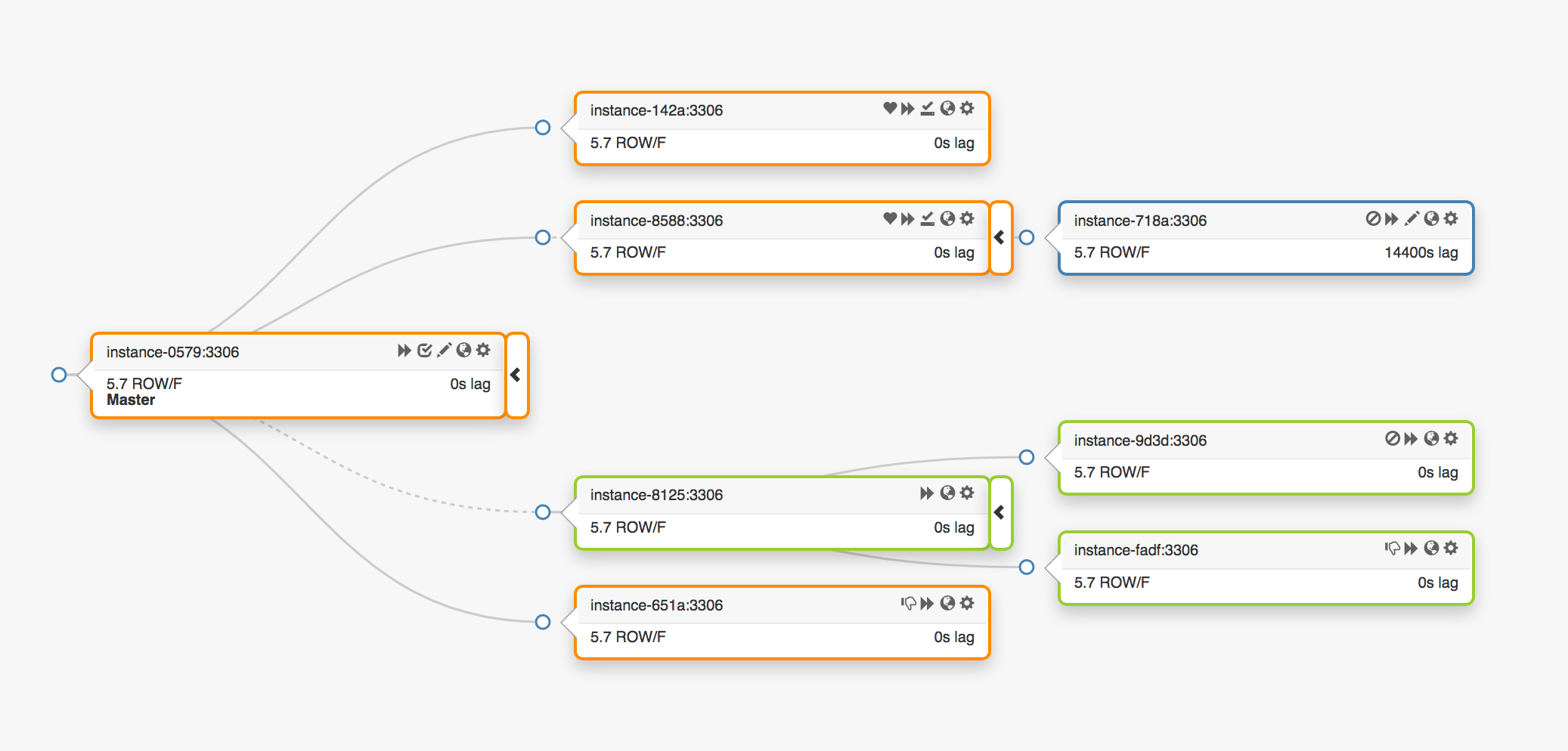
\\
当发生一个主节点故障事件时,一个新的服务器(副本之一),必须被提升为主节点。
\\
orchestrator将监测到一个故障,提升一个新的主节点,然后采取行动重新分配名称/VIP。客户端并不准确地知道主节点的身份:它们所知道的只是一个名称,而那个名称现在一定解析到了新的主节点。然而,注意:
\\
VIP是协作的:它们被数据库服务器本身声明和拥有。为了获取或释放一个VIP,一个服务器必须发送一个ARP请求。在新提升的主节点获取这个VIP之前,拥有这个VIP的服务器必须先释放这个VIP。这有一些不如人意的效果:
\\
- \\t
一个故障恢复操作按顺序首先会请求挂掉的主节点释放VIP,然后请求新提升的主节点获取这个VIP。但如果老的主节点无法访问或者拒绝释放VIP呢?假设在那台服务器上一开始发生了一个故障,那么它也很可能不会及时响应或者根本不响应。
\\\t
- 我们会面临裂脑处境:两个主机声称拥有相同的VIP。不同的客户端根据最短网络路径,可能会连接到其中任何一个服务器。\\t\t
- 这个问题的根源是依赖于两个独立服务器的合作,而这种设置是不可靠的。\\t
\\t
- 即使旧的主节点合作,这个工作流也浪费了宝贵的时间:切换到新的主节点时,需要等待与旧的主节点的联系。\\t
- 而且当VIP改变时,不能保证现有的客户端与旧的服务器的连接断开,从而导致我们仍面临裂脑处境。\
在我们的设置中,VIP与物理地址绑定。它们属于一个交换机或路由器。因此,我们只能将VIP重新分配给相互定位的服务器。特别是,在某些情况下,我们不能将VIP分配给在不同数据中心提升的服务器,并且必须更改DNS。
\\
- DNS的变化需要更长的时间来传播。客户端会为了预配置时间而缓存DNS名称。一个跨数据中心的故障意味着更长的宕机时间:让所有客户端意识到新主节点的身份需要花费更长时间。\
仅仅这些限制就足以促使我们去寻找一种新的解决方案,但还有更多的顾虑:
\\
- 主节点通过
pt-heartbeat服务来自我注入心跳,从而达到延迟测量和节流控制的目的。这个服务必须在新提升的主节点上开启。如果可能的话,这个服务会在旧的主节点上会被关停。\\t - 同样地,Pseudo-GTID注入是由主节点自我管理的。它需要在新的主节点上开启,而且最好在旧的主节点上关停。\\t
- 新的主节点被设置为可写的。如果可能的话,旧的主节点被设置为
read_only。\
这些额外的步骤的执行时间构成了总宕机时间的一部分,并且引入了它们自己的故障和冲突。
\\
这个解决方案是有效的,而且GitHub已经有运行良好的非常成功的MySQL故障恢复措施,但是我们想要在以下方面提升我们的高可用性:
\\
- 不依赖数据中心。\\t
- 克服数据中心故障的影响。\\t
- 移除不可靠的协作工作流。\\t
- 减少总宕机时间。\\t
- 尽可能实现无损故障恢复。\
GitHub的高可用性方案:orchestrator、Consul和GLB
\\
我们的新策略以及附带的改进,解决或者减轻了上述的许多担忧。在目前的高可用性设置中:
\\
- orchestrator用来运行故障监听和故障恢复。我们使用了如下图所示的一个跨数据中心的orchestrator/raft。\\t
- Hashicorp公司的用于服务发现的Consul。\\t
- 作为客户端和写操作节点之间的代理层的GLB/HAProxy。\\t
- 用于网络路由的
anycast。\
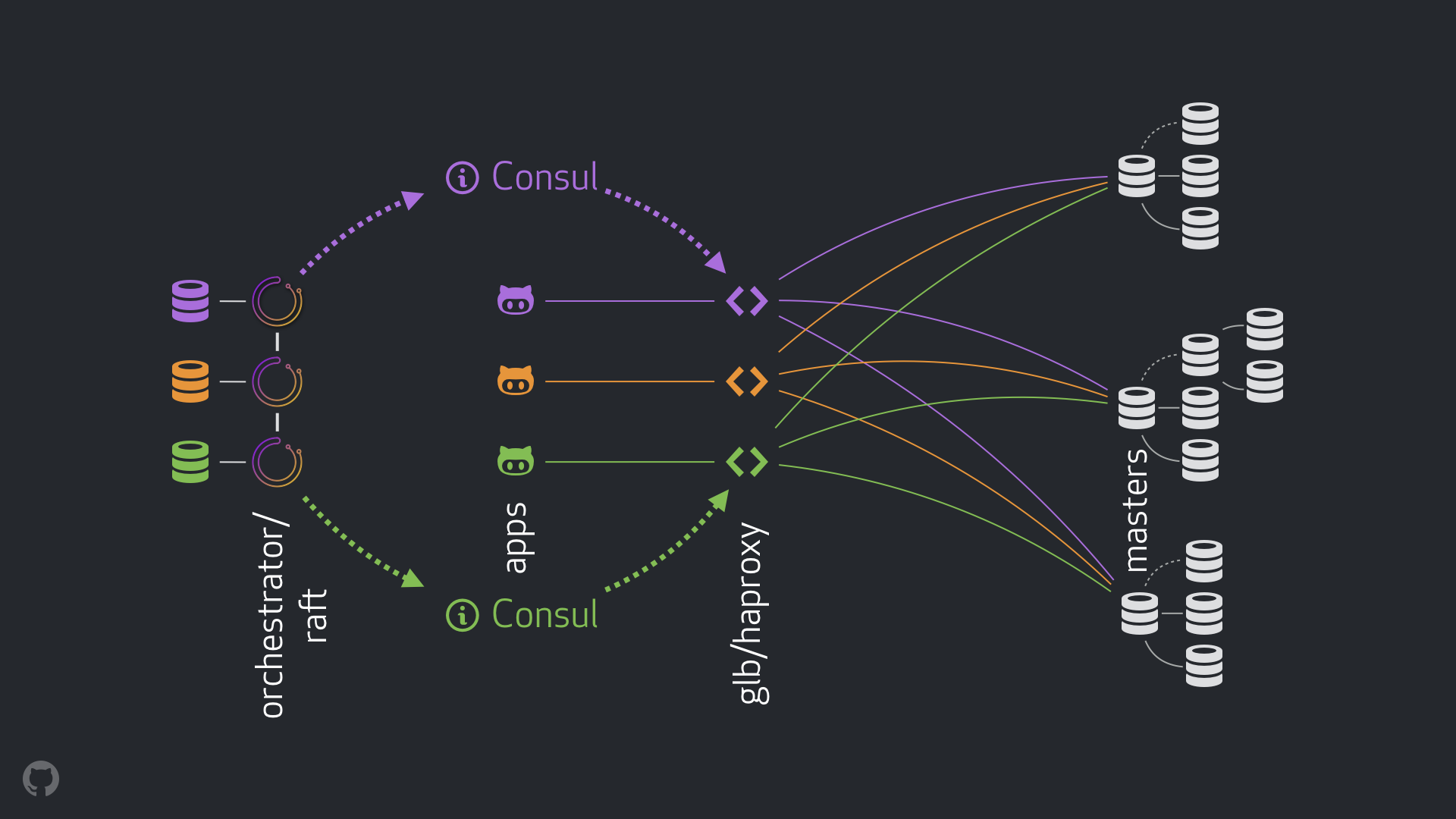
\新设置完全删除了VIP和DNS更改。并且在引入更多组件的同时,我们使得组件解耦并简化了任务,还使用了稳健的解决方案。详解如下:
\\
一个普通的工作流
\\
平常,App通过GLB/HAProxy连接到写操作节点。
\\
App不会意识到主节点的身份。和以前一样,它们使用一个名称。例如,cluster1的主节点会是mysql-writer-1.github.net。然而,在我们目前的设置中,这个名称会被解析到一个任播(anycast)IP。
\\
通过anycast方法,这个名称在任何地方都被解析为相同的IP,但是流量会根据客户端位置分别进行路由。特别地,我们的每个数据中心都在多个区域部署了GLB(我们的高可用负载均衡)。到mysql-writer-1.github.net的流量通常路由到本地数据中心的GLB集群。因此,所有的客户端都是由本地代理服务的。
\\
我们在HAProxy上运行GLB。我们的HAProxy有写操作池:每个MySQL集群一个池,而每个池有一个后端服务器作为这个集群的主节点。所有的GLB/HAProxy区域在所有的数据中心都拥有相同的写操作池,而它们都指向这些池中完全相同的后端服务器。因此,如果一个App想要向mysql-writer-1.github.net写入,这跟它与哪个GLB服务器连接无关。它将总是被路由到cluster1主节点。
\\
就App而言,服务发现在GLB终止,并且永远不需要重新发现。流量都是在GLB上路由到正确的目的地。
\\
那么,GLB如何知道将哪些服务器作为后端列表,以及我们如何将更改传播到GLB?
\\
Consul的服务发现
\\
Consul作为一种服务发现解决方案而闻名,并且还提供DNS服务。然而在我们的解决方案中,我们用它作为一个高可用的键值对(KV)存储器。
\\
我们使用Consul的KV存储器写入集群主节点的身份。对于每个集群,都有一套KV记录表明集群的主节点的fqdn、port、ipv4和ipv6。
\\
每个GLB/HAProxy节点都运行consul-template:一个监听Consul数据变化的服务(在我们的案例中:是指集群主节点数据的变化)。console-template会生成一个有效的配置文件,并且能够基于配置的变化重新加载HAProxy。
\\
因此,Consul中每个主节点身份的改变都被每个GLB/HAProxy观测,然后重新配置自身,将新的主节点设置为一个集群的后端池的单个实体,然后重新加载以反映那些变化。
\\
在GitHub,我们在每个数据中心都有一个Consul设置,而且每个设置都是高可用的。然而,这些设置是彼此独立的。它们不会彼此复制,也不共享任何数据。
\\
那么,Consul是如何得知变化的呢?这些信息又是如何跨平台分布的呢?
\\
orchestrator/raft
\\
我们运行一个orchestrator/raft设置:orchestrator节点通过raft共识相互通信。我们每个数据中心有1到2个orchestrator节点。
\\
orchestrator负责故障检测、MySQL故障恢复并将主节点的变更通知Consul。故障恢复由单个orchestrator/raft领导节点维护,但是集群现在有一个新的主节点这个变更消息是通过raft机制传播给所有orchestrator节点的。
\\
当orchestrator节点接收到主节点变更消息时,它们都会通知他们的本地Consul设置:它们各自调用一次KV写操作。拥有1个以上orchestrator的数据中心将会向Consul有多次(等同的)写操作。
\\
整合工作流
\\
在一个主节点宕机场景:
\\
orchestrator节点监测到故障。\\torchestrator/raft领导开始一次恢复措施,提升一个新的主节点。\\torchestrator/raft将主节点变更通告给所有raft集群节点\\t- 每个
orchestrator/raft成员接收到一个领导变更通知。它们各自在本地Consul的KV存储器中更新新的主节点的身份。\\t - 每个GLB/HAProxy都运行了
consul-template,监控Consul的KV存储中的变更,然后重新配置和加载HAProxy。\\t - 客户端流量被重定向到新的主节点。\
每个组件都职责清晰,而且整个设计既解耦又简单。orchestrator不需要知道负载均衡器。Consul不需要知道信息来自哪里。代理只关心Consul。客户端只关心代理。
\\
此外:
\\
- 无需传播DNS变更。\\t
- 没有TTL。\\t
- 这个流程不需要挂掉的主节点的合作。它很大程度上被忽略了。\
更多细节
\\
为了进一步保障这个流程,我们还做了如下工作:
\\
- \\t
HAProxy配置了一个非常短的
hard-stop-after。当它用写操作池中的一个新的后端服务器重新加载时,它会自动终止任何现存的与旧的主节点的连接。\\\t
- 通过
hard-stop-after,我们甚至不需要来自客户端的配合,而且这样减轻了裂脑场景。值的注意的是,这并不是严密的,在我们杀死旧连接之前会过去一段时间。但是在那之后,我们就可以放心不会出现令人讨厌的意外。\\t
\\t
- 通过
- 我们并没有严格要求Consul在所有时间都是可用的。事实上,我们只需要它在故障恢复时可用。如果Consul碰巧挂掉了,GLB会继续使用上次已知的值操作,不会采取剧烈的行动。\\t
- GLB被设置来验证新提升的主节点的身份。类似于我们的上下文感知MySQL池,在后端服务器进行检查,来确认它确实是一个写操作节点。如果碰巧删除了Consul中的主节点信息,没有问题;空白的条目会被忽略。如果我们在Consul中误写入了一个非主节点服务器的名称,没有问题;GLB会拒绝更新它并使用上次已知的状态运行。\
我们会在下面章节中进一步解决担忧并追求高可用性目标。
\\
orchestrator/raft故障检测
\\
orchestrator使用一种整体方案来检测故障,因此是非常可靠的。我们不观测假阳性:我们不会过早启动故障恢复,因此不会遭受不必要的宕机时间。
\\
orchestrator/raft进一步解决了一个完整的数据中心网络隔离的情况(即数据中心围栏)。数据中心网络隔离会引起混淆:那个数据中心中的服务器能够彼此通信。是它们与其它数据中心网络隔离了?还是其它数据中心被网络隔离了?
\\
在一个orchestrator/raft设置中,raft领导节点是运行故障恢复的节点。领导节点是指获得大多数群体支持的节点。我们的orchestrator节点部署就是这样,没有单个数据中心占大多数支持,任何n-1个数据中心占大多数支持。
\\
在一个完整的数据中心网络隔离事件中,那个数据中心中的orchestrator节点与其他数据中心中的对等节点断开连接。因此,在隔离的数据中心中的orchestrator节点不能成为raft集群的领导节点。如果任何这种节点碰巧成为领导节点,它也会下台。一个新的领导节点会从其它数据中心分配。这个领导节点将获得所有其它数据中心的支持,而这些数据中心能够彼此通信。
\\
因此,orchestrator节点就是网络隔离的数据中心之外的一个节点。在一个隔离的数据中心应该有一个主节点,orchestrator将启动故障恢复,用可用数据中心之一里的一个服务器取代它。我们通过将决策委托给非隔离数据中心中的群体来减轻数据中心隔离。
\\
更快的通告
\\
可以通过更快速地通告主节点变更来进一步减少总宕机时间。这如何实现呢?
\\
当orchestrator开始故障恢复时,它观测可被提升的服务器群。理解复制原则并遵从暗示和限制,能够基于最佳做法作出优化的决策。
\\
需要意识到,可用于提升的服务器也是一个理想的候选者,例如:
\\
- 没有什么可以阻止服务器的提升(而且用户已经潜在暗示这些服务器是首选提升对象)\\t
- 这些服务器能够将其所有的兄弟节点作为复制品\
在这种情况,orchestrator首先将服务器设置为可写的,然后迅速通告服务器的提升(写入Consul KV),同时异步开始修复复制树(这个操作通常会花费更多时间)。
\\
很可能当我们的GLB服务器完全重新加载时,复制树已经完好无损了,但这不是严格必需的。服务器可以接收写操作!
\\
半同步复制
\\
在MySQL的半同步复制中,在变更已经提交到一个或多个副本之前,主服务器不会承认这个事务提交。这提供了一种实现无损故障恢复的方法:任何提交到主节点的变更都已经应用或者等待被应用到某个副本。
\\
一致性伴随着成本:可用性风险。如果没有副本确认收到变更,主节点会阻塞并且写操作会停顿。幸运的是,有一个超时配置,超过超时时间,主节点能够恢复到异步复制模式,使得写操作再次可用。
\\
我们将我们的超时配置设置为一个合理的低值:500ms。这足够将主节点的变更传递给本地数据中心副本以及远程的数据中心。有了这个超时,我们就可以观测完美的半同步行为(不回滚到异步复制),同时在确认失败的情况下会感受到一个可接受的非常短的阻塞时间。
\\
我们在本地数据中心副本上启用半同步,而且在主节点挂掉事件中,我们期望(尽管并不严格强制)无损故障恢复。但是,我们不会期望一个完整的数据中心故障的无损故障恢复,因为它的代价非常大。
\\
在进行半同步超时实验时,我们还观察到一种对我们有利的现象:我们能够在主节点故障中影响理想的候选者的身份。通过在指定服务器上启用半同步并将它们标记为候选者,我们能够通过影响故障结果来减少总宕机时间。我们在实验中观察到,我们通常能够提升理想的候选者并因此快速进行通告。
\\
心跳注入
\\
我们选择在任何地方任何时间管理pt-heartbeat服务的开启/关闭,而不是只在提升/降级的主节点上管理pt-heartbeat服务的开启/关闭。这需要一些补丁,改变它们的read_only状态或者完全奔溃,以便使pt-heartbeat与服务器一致。
\\
在我们当前设置中,pt-heartbeat服务运行在主节点和副本上。在主节点上,它们生成心跳事件。在副本上,它们标识服务器是read_only并周期性检查它们的状态。一旦一个服务器被提升为主节点,那个服务器上的pt-heartbeat将其标识为可写的,并开始注入心跳事件。
\\
orchestrator所有权委托
\\
我们进一步委托给orchestrator:
\\
- Preudo-GTID注入\\t
- 将提升的主节点设置为可写的并清除它的复制状态\\t
- 如果可能的话,将旧的主节点设置为
read_only\
在新的主节点上,这减少了摩擦。被提升的主节点明显需要是活跃的和可访问的,否则我们不会提升它。那么,可以让orchestrator直接将变更应用到提升的主节点上。
\\
限制和缺陷
\\
代理层使得App意识不到主节点的身份,同时它还对主节点屏蔽了App的身份。主节点看到的都是来自代理层的连接,而我们丢失了真正连接来源的信息。
\\
随着分布式系统的发展,我们仍然面临未处理过的场景。
\\
尤其是,在一个数据中心隔离场景中,假设主节点是在隔离的数据中心,那个数据中心的App仍然能够向主节点写入。一旦网络恢复,这可能导致状态不一致。我们通过从非常孤立的数据中心实现一个可靠的STONITH来减轻这种裂脑现象。像之前一样,主节点降级之前会经过一些时间,并且会存在一段时间的裂脑。避免裂脑现象的运维成本非常高。
\\
存在更多场景:故障恢复时Consul宕机;部分数据中心隔离;其它场景等。我们明白,在这种性质的分布式系统中,不可能关闭所有的漏洞,因此我们关注最重要的场景。
\\
结果
\\
我们的orchestrator/GLB/Consul设置提供了:
\\
- 可靠的故障检测\\t
- 不依赖数据中心的故障恢复\\t
- 典型的无损故障恢复\\t
- 数据中心网络隔离支持\\t
- 减轻裂脑现象(更多工作仍在进行中)\\t
- 没有合作依赖\\t
- 大部分场景下的
10-13秒的总宕机时间\\t- 总宕机时间在非常少的场景下会长达
20秒,在极端情况下会长达25秒。\\t
\
- 总宕机时间在非常少的场景下会长达
结论
\\
orchestratoion/proxy/service-discovery范式在解耦架构中使用了众所周知且令人信赖的组件,使得它更容易部署、运维和观测,并且每个组件都可以独立地扩大或缩小规模。我们将不断测试我们的设置,从而不断寻求改进。
\\
关于作者
\\

Shlomi Noach 是一名软件工程师、DBA和MySQL极客,供职于GitHub。
网站 | GitHub简介 | Twitter简介
\\
查看英文原文:MySQL High Availability at GitHub
\\
感谢张婵对本文的审校。
GitHub的MySQL高可用性实践相关推荐
- Prometheus 的云上 MySQL 监控实践
一.背景 MySQL 8.0是当前Oracle公司一直在大力宣传的新版本,从架构到性能均有显著变化,同时,随着kubernetes的普及,为更好的提升资源利用率,可以进行MySQL上云的探索.MySQ ...
- 淘宝商品库MySQL优化实践的学习
淘宝商品库MySQL优化实践的学习 淘宝商品库是淘宝网最核心的数据库之一,采用MySQL主备集群的架构,特点是数据量大且增长速度快,读多写少,对安全性要求高,并发请求高.由于MySQL最初的设计不是用 ...
- mysql主从复制实践之单数据库多实例
1.主从复制数据库实战环境准备 MySQL主从复制实践对环境的要求比较简单,可以是单机单数据库多实例的环境,也可以是两台服务器之间,每台服务器都部署一个独立的数据库的环境.本文以单机数据库多实例的环境 ...
- 【译】适合dba和开发者的mysql最佳实践
[文章作者:孙立 链接:http://www.cnblogs.com/sunli/ 更新时间:2010-09-19] 这是今天开始在南非秘鲁利马开始举行OTN LAD Tour的上,我要进行的一个my ...
- Docker 启动 MySQL 最佳实践
Docker 启动 MySQL 最佳实践 本文主要介绍使用 Docker 启动 MySQL 服务的最佳实践,Docker 镜像来自 docker 官方镜像. 启动一个 MySql 5.7 实例 关于版 ...
- Mysql高可用性实施方案
Mysql高可用性实施方案 陆地 2012-11-30 目录 一.实施测试环境:.... 2 二.系统架构图.... 2 三.Mysql的安装步骤.... 3 四.主从双机热备配置步骤(异步复制功能) ...
- MySQL - 高可用性:少宕机即高可用?
MySQL - 高可用性:少宕机即高可用? 原文:MySQL - 高可用性:少宕机即高可用? 我们之前了解了复制.扩展性,接下来就让我们来了解可用性.归根到底,高可用性就意味着 "更少的宕机 ...
- Mysql存储过程实践
Mysql存储过程实践 一.目的 1.掌握存储过程的功能与作用 2.掌握存储过程的创建与管理的方法 二.内容 用于企业管理的员工管理数据库,数据库名为YGGL,包含员工信息表Employees.部门信 ...
- GitHub在线MySQL DDL工具gh-ost安装文档
GitHub开源MySQL Online DDL工具gh-ost安装文档 查看GitHub开源的MySQL在线DDL工具gh-ost官方文档,以及google一圈都没有发现gh-ost的安装文档,于是 ...
最新文章
- 刘宇与小白健康:一个理想主义者的互联网“众包”实践
- 人工智能正在永远改变药理学
- python 回溯法 子集树模板 系列 —— 3、0-1背包问题
- rsync+shell脚本完成自动化备份
- .NET Core 已经实现了PHP JIT,现在PHP是.NET上的一门开发语言
- C main()参数
- Android面试系列文章2018之内存管理之UI卡顿篇
- CPU Cache Line:CPU缓存行/缓存块
- mysql的varchar与text对比
- :没有此sdk或暂不支持此sdk模拟_即构SDK7月迭代:新增支持按通道设置延迟模式,大大减少卡顿...
- 有关Unity编辑器
- python 异常处理高级形式例子_Python 异常处理的实例详解
- UE4运行时交互工具框架
- matlab图像放大程序,图像放大并进行BiCubic插值 Matlab/C++代码
- python导入自定义模块_python引入不同文件夹下的自定义模块方法
- 国家公祭日悼念:黑白网页背景设置教程
- 云笔记+心情日记类APP推荐
- 打造百亿量级、亿级日活SDK的十大关键要点
- mysql中select使用方法,MySQL中select语句介绍及使用示例
- 函数图像变换的规律,以一元函数和二元函数为例来说明,对多元函数同样适用。...