Deep Learning(深度学习)学习笔记整理系列
一、概述
Artificial Intelligence,也就是人工智能,就像长生不老和星际漫游一样,是人类最美好的梦想之一。虽然计算机技术已经取得了长足的进步,但是到目前为止,还没有一台电脑能产生“自我”的意识。是的,在人类和大量现成数据的帮助下,电脑可以表现的十分强大,但是离开了这两者,它甚至都不能分辨一个喵星人和一个汪星人。
图灵(图灵,大家都知道吧。计算机和人工智能的鼻祖,分别对应于其著名的“图灵机”和“图灵测试”)在 1950 年的论文里,提出图灵试验的设想,即,隔墙对话,你将不知道与你谈话的,是人还是电脑。这无疑给计算机,尤其是人工智能,预设了一个很高的期望值。但是半个世纪过去了,人工智能的进展,远远没有达到图灵试验的标准。这不仅让多年翘首以待的人们,心灰意冷,认为人工智能是忽悠,相关领域是“伪科学”。
但是自 2006 年以来,机器学习领域,取得了突破性的进展。图灵试验,至少不是那么可望而不可及了。至于技术手段,不仅仅依赖于云计算对大数据的并行处理能力,而且依赖于算法。这个算法就是,Deep Learning。借助于 Deep Learning 算法,人类终于找到了如何处理“抽象概念”这个亘古难题的方法。
2012年6月,《纽约时报》披露了Google Brain项目,吸引了公众的广泛关注。这个项目是由著名的斯坦福大学的机器学习教授Andrew Ng和在大规模计算机系统方面的世界顶尖专家JeffDean共同主导,用16000个CPU Core的并行计算平台训练一种称为“深度神经网络”(DNN,Deep Neural Networks)的机器学习模型(内部共有10亿个节点。这一网络自然是不能跟人类的神经网络相提并论的。要知道,人脑中可是有150多亿个神经元,互相连接的节点也就是突触数更是如银河沙数。曾经有人估算过,如果将一个人的大脑中所有神经细胞的轴突和树突依次连接起来,并拉成一根直线,可从地球连到月亮,再从月亮返回地球),在语音识别和图像识别等领域获得了巨大的成功。
项目负责人之一Andrew称:“我们没有像通常做的那样自己框定边界,而是直接把海量数据投放到算法中,让数据自己说话,系统会自动从数据中学习。”另外一名负责人Jeff则说:“我们在训练的时候从来不会告诉机器说:‘这是一只猫。’系统其实是自己发明或者领悟了“猫”的概念。”

2013年1月,在百度年会上,创始人兼CEO李彦宏高调宣布要成立百度研究院,其中第一个成立的就是“深度学习研究所”(IDL,Institue of Deep Learning)。

机器学习虽然发展了几十年,但还是存在很多没有良好解决的问题:

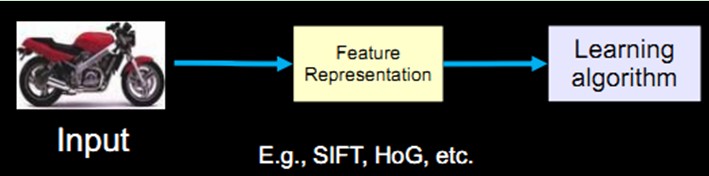
例如图像识别、语音识别、自然语言理解、天气预测、基因表达、内容推荐等等。目前我们通过机器学习去解决这些问题的思路都是这样的(以视觉感知为例子):

而中间的三部分,概括起来就是特征表达。良好的特征表达,对最终算法的准确性起了非常关键的作用,而且系统主要的计算和测试工作都耗在这一大部分。但,这块实际中一般都是人工完成的。靠人工提取特征。
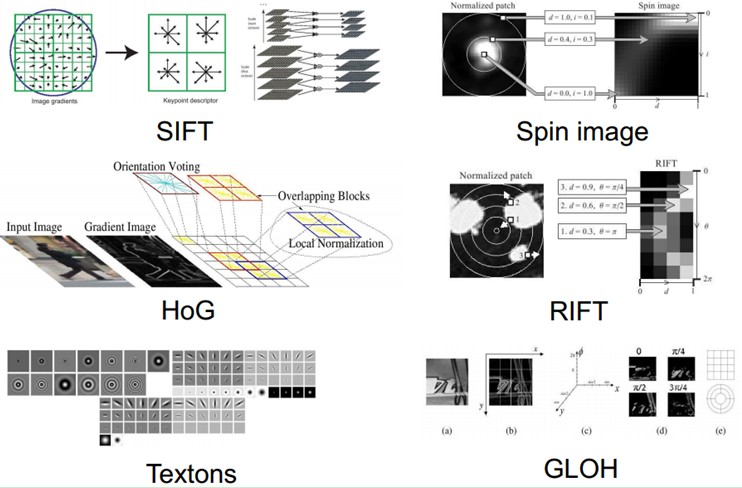
近几十年以来,认知神经科学、生物学等等学科的发展,让我们对自己这个神秘的而又神奇的大脑不再那么的陌生。也给人工智能的发展推波助澜。
然后,他们在小猫的眼前,展现各种形状、各种亮度的物体。并且,在展现每一件物体时,还改变物体放置的位置和角度。他们期望通过这个办法,让小猫瞳孔感受不同类型、不同强弱的刺激。
这个发现激发了人们对于神经系统的进一步思考。神经-中枢-大脑的工作过程,或许是一个不断迭代、不断抽象的过程。
这里的关键词有两个,一个是抽象,一个是迭代。从原始信号,做低级抽象,逐渐向高级抽象迭代。人类的逻辑思维,经常使用高度抽象的概念。
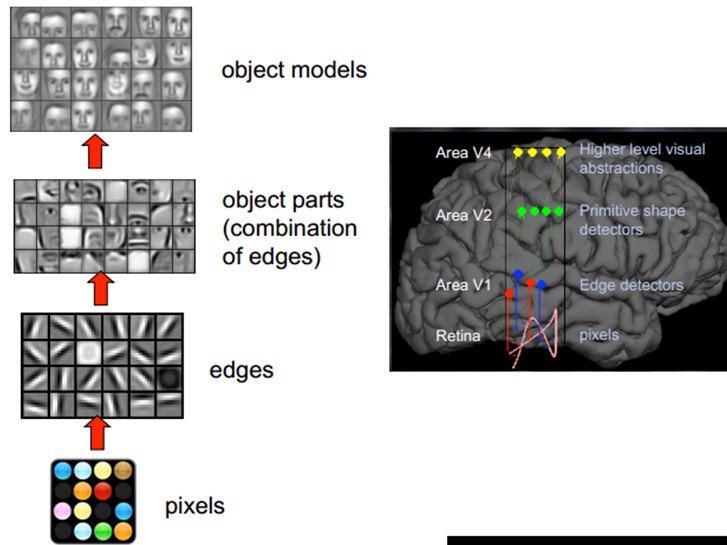
这个生理学的发现,促成了计算机人工智能,在四十年后的突破性发展。
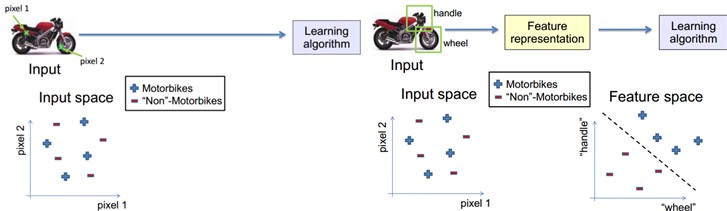
特征是机器学习系统的原材料,对最终模型的影响是毋庸置疑的。如果数据被很好的表达成了特征,通常线性模型就能达到满意的精度。那对于特征,我们需要考虑什么呢?

1995 年前后,Bruno Olshausen和 David Field 两位学者任职 Cornell University,他们试图同时用生理学和计算机的手段,双管齐下,研究视觉问题。
Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在叠加碎片 S[k] 时的权重系数。
为解决这个问题,Bruno Olshausen和 David Field 发明了一个算法,稀疏编码(Sparse Coding)。
1)选择一组 S[k],然后调整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
Bruno Olshausen和 David Field 的算法结果,与 David Hubel 和Torsten Wiesel 的生理发现,不谋而合!
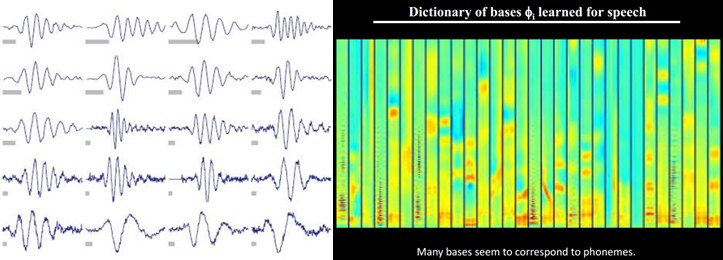
另外,大牛们还发现,不仅图像存在这个规律,声音也存在。他们从未标注的声音中发现了20种基本的声音结构,其余的声音可以由这20种基本结构合成。
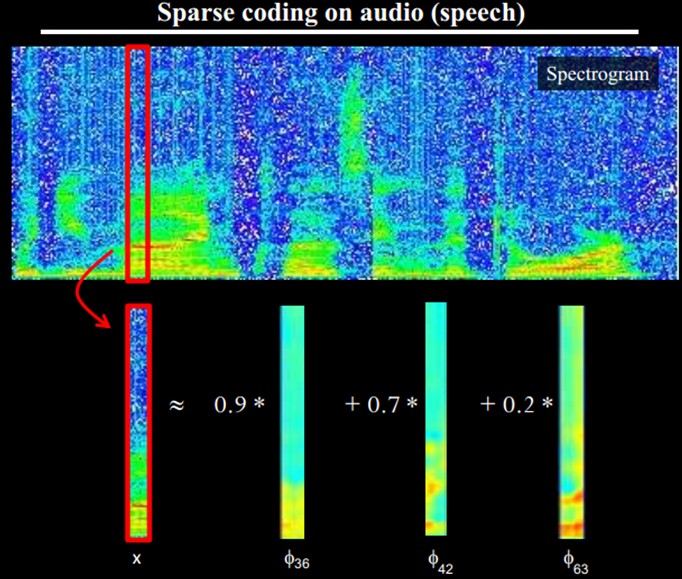
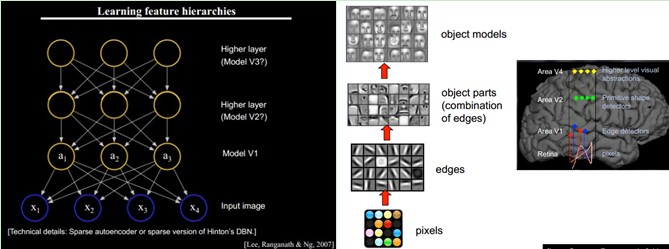
直观上说,就是找到make sense的小patch再将其进行combine,就得到了上一层的feature,递归地向上learning feature。

一个人在看一个doc的时候,眼睛看到的是word,由这些word在大脑里自动切词形成term,在按照概念组织的方式,先验的学习,得到topic,然后再进行高层次的learning。
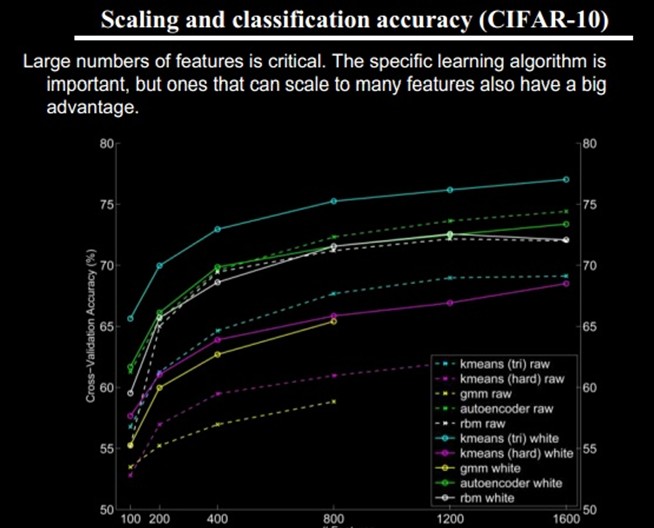
我们知道需要层次的特征构建,由浅入深,但每一层该有多少个特征呢?
任何一种方法,特征越多,给出的参考信息就越多,准确性会得到提升。但特征多意味着计算复杂,探索的空间大,可以用来训练的数据在每个特征上就会稀疏,都会带来各种问题,并不一定特征越多越好。
对于深度学习来说,其思想就是对堆叠多个层,也就是说这一层的输出作为下一层的输入。通过这种方式,就可以实现对输入信息进行分级表达了。
六、浅层学习(Shallow Learning)和深度学习(Deep Learning)
七、Deep learning与Neural Network
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习是无监督学习的一种。
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
1)比较容易过拟合,参数比较难tune,而且需要不少trick;
2)训练速度比较慢,在层次比较少(小于等于3)的情况下效果并不比其它方法更优;
Deep learning与传统的神经网络之间有相同的地方也有很多不同。
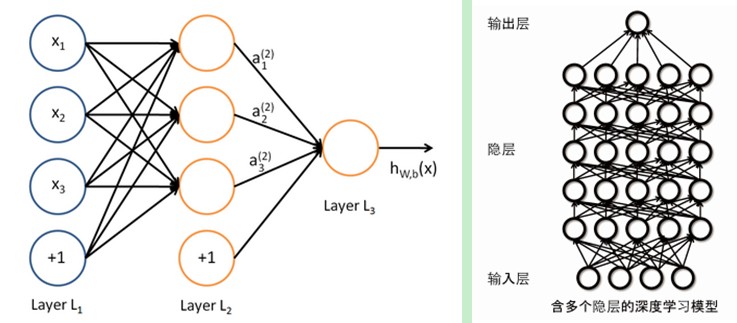
BP算法作为传统训练多层网络的典型算法,实际上对仅含几层网络,该训练方法就已经很不理想。深度结构(涉及多个非线性处理单元层)非凸目标代价函数中普遍存在的局部最小是训练困难的主要来源。
(2)收敛到局部最小值:尤其是从远离最优区域开始的时候(随机值初始化会导致这种情况的发生);
(3)一般,我们只能用有标签的数据来训练:但大部分的数据是没标签的,而大脑可以从没有标签的的数据中学习;
如果对所有层同时训练,时间复杂度会太高;如果每次训练一层,偏差就会逐层传递。这会面临跟上面监督学习中相反的问题,会严重欠拟合(因为深度网络的神经元和参数太多了)。
2)当所有层训练完后,Hinton使用wake-sleep算法进行调优。
1)使用自下上升非监督学习(就是从底层开始,一层一层的往顶层训练):
采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,是和传统神经网络区别最大的部分(这个过程可以看作是feature learning过程):
2)自顶向下的监督学习(就是通过带标签的数据去训练,误差自顶向下传输,对网络进行微调):
九、Deep Learning的常用模型或者方法
9.1、AutoEncoder自动编码器
Deep Learning最简单的一种方法是利用人工神经网络的特点,人工神经网络(ANN)本身就是具有层次结构的系统,如果给定一个神经网络,我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得到了输入I的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
具体过程简单的说明如下:
1)给定无标签数据,用非监督学习学习特征:
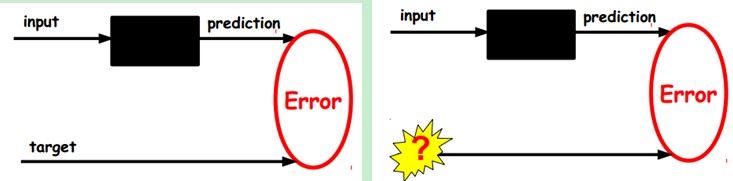
在我们之前的神经网络中,如第一个图,我们输入的样本是有标签的,即(input, target),这样我们根据当前输出和target(label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢?
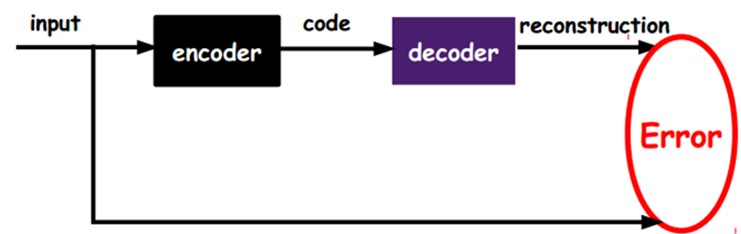
如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。
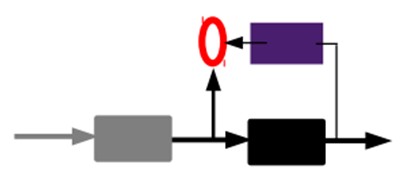
2)通过编码器产生特征,然后训练下一层。这样逐层训练:
那上面我们就得到第一层的code,我们的重构误差最小让我们相信这个code就是原输入信号的良好表达了,或者牵强点说,它和原信号是一模一样的(表达不一样,反映的是一个东西)。那第二层和第一层的训练方式就没有差别了,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的code,也就是原输入信息的第二个表达了。其他层就同样的方法炮制就行了(训练这一层,前面层的参数都是固定的,并且他们的decoder已经没用了,都不需要了)。
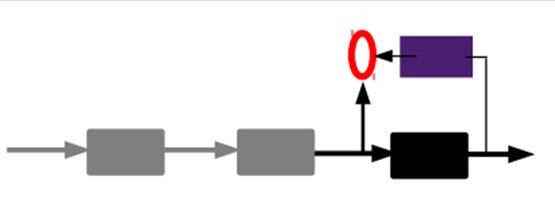
3)有监督微调:
经过上面的方法,我们就可以得到很多层了。至于需要多少层(或者深度需要多少,这个目前本身就没有一个科学的评价方法)需要自己试验调了。每一层都会得到原始输入的不同的表达。当然了,我们觉得它是越抽象越好了,就像人的视觉系统一样。
到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如罗杰斯特回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。
也就是说,这时候,我们需要将最后层的特征code输入到最后的分类器,通过有标签样本,通过监督学习进行微调,这也分两种,一个是只调整分类器(黑色部分):
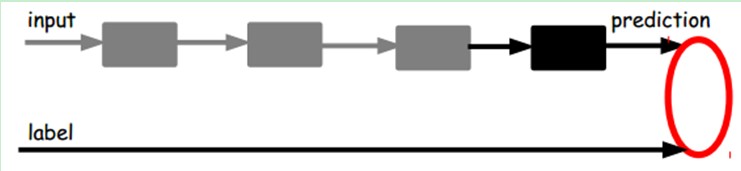
另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)
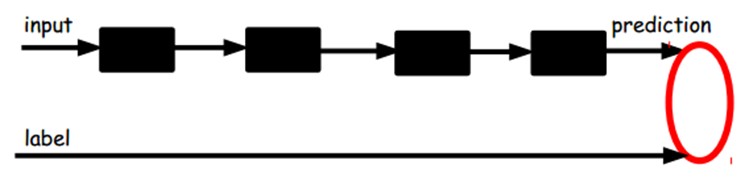
一旦监督训练完成,这个网络就可以用来分类了。神经网络的最顶层可以作为一个线性分类器,然后我们可以用一个更好性能的分类器去取代它。
在研究中可以发现,如果在原有的特征中加入这些自动学习得到的特征可以大大提高精确度,甚至在分类问题中比目前最好的分类算法效果还要好!
AutoEncoder存在一些变体,这里简要介绍下两个:
Sparse AutoEncoder稀疏自动编码器:
当然,我们还可以继续加上一些约束条件得到新的Deep Learning方法,如:如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
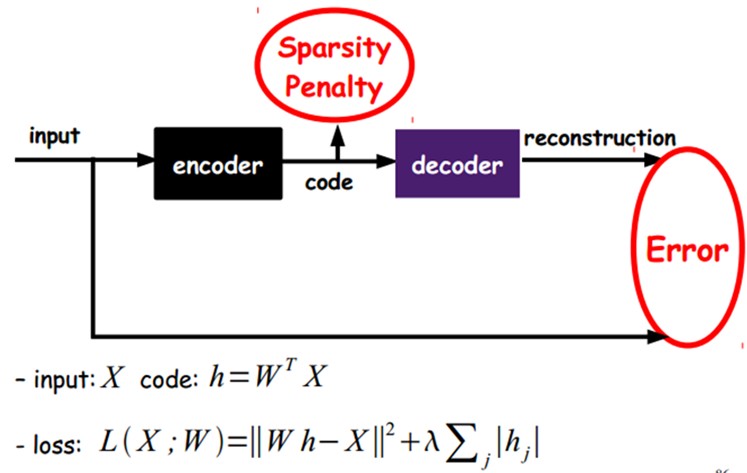
如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
Denoising AutoEncoders降噪自动编码器:
降噪自动编码器DA是在自动编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪声污染过的输入。因此,这就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。DA可以通过梯度下降算法去训练。
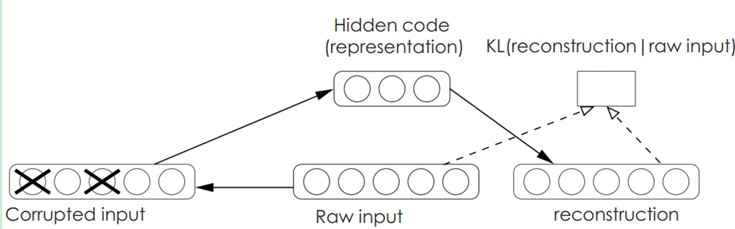
9.2、Sparse Coding稀疏编码
如果我们把输出必须和输入相等的限制放松,同时利用线性代数中基的概念,即O = a1*Φ1 + a2*Φ2+….+ an*Φn, Φi是基,ai是系数,我们可以得到这样一个优化问题:
Min |I – O|,其中I表示输入,O表示输出。
通过求解这个最优化式子,我们可以求得系数ai和基Φi,这些系数和基就是输入的另外一种近似表达。
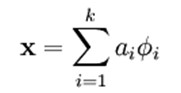
因此,它们可以用来表达输入I,这个过程也是自动学习得到的。如果我们在上述式子上加上L1的Regularity限制,得到:
Min |I – O| + u*(|a1| + |a2| + … + |an |)
这种方法被称为Sparse Coding。通俗的说,就是将一个信号表示为一组基的线性组合,而且要求只需要较少的几个基就可以将信号表示出来。“稀疏性”定义为:只有很少的几个非零元素或只有很少的几个远大于零的元素。要求系数 ai 是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。同时,比如与初级视觉皮层的类比过程也因此得到了提升(人脑有大量的神经元,但对于某些图像或者边缘只有很少的神经元兴奋,其他都处于抑制状态)。
稀疏编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。虽然形如主成分分析技术(PCA)能使我们方便地找到一组“完备”基向量,但是这里我们想要做的是找到一组“超完备”基向量来表示输入向量(也就是说,基向量的个数比输入向量的维数要大)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数ai不再由输入向量唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。(详细过程请参考:UFLDL Tutorial稀疏编码)
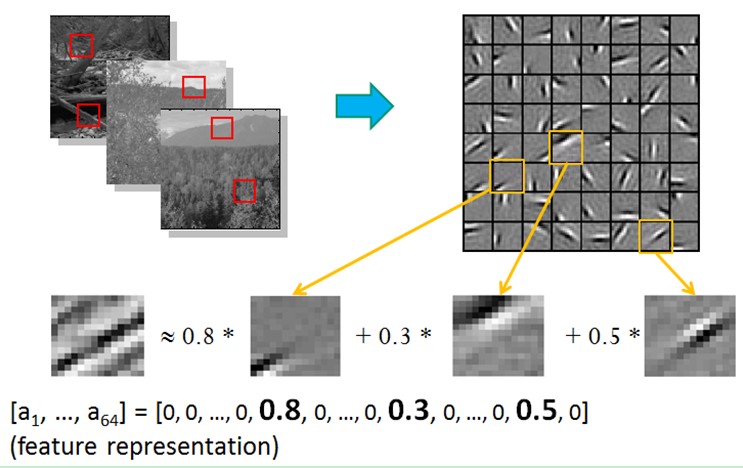
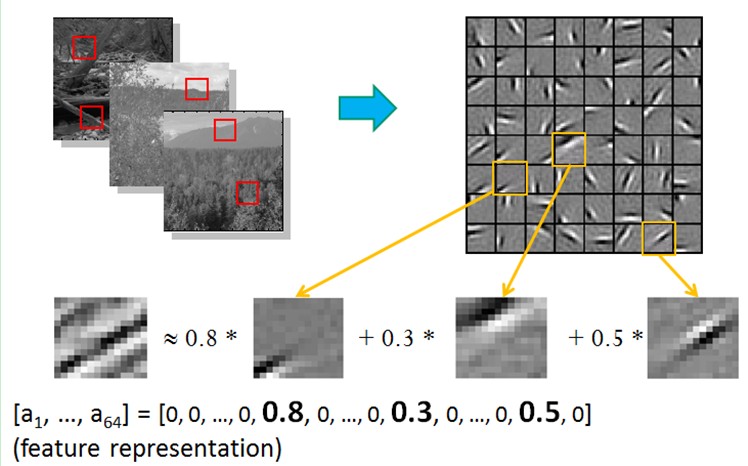
比如在图像的Feature Extraction的最底层要做Edge Detector的生成,那么这里的工作就是从Natural Images中randomly选取一些小patch,通过这些patch生成能够描述他们的“基”,也就是右边的8*8=64个basis组成的basis,然后给定一个test patch, 我们可以按照上面的式子通过basis的线性组合得到,而sparse matrix就是a,下图中的a中有64个维度,其中非零项只有3个,故称“sparse”。
这里可能大家会有疑问,为什么把底层作为Edge Detector呢?上层又是什么呢?这里做个简单解释大家就会明白,之所以是Edge Detector是因为不同方向的Edge就能够描述出整幅图像,所以不同方向的Edge自然就是图像的basis了……而上一层的basis组合的结果,上上层又是上一层的组合basis……(就是上面第四部分的时候咱们说的那样)
Sparse coding分为两个部分:
1)Training阶段:给定一系列的样本图片[x1, x 2, …],我们需要学习得到一组基[Φ1, Φ2, …],也就是字典。
稀疏编码是k-means算法的变体,其训练过程也差不多(EM算法的思想:如果要优化的目标函数包含两个变量,如L(W, B),那么我们可以先固定W,调整B使得L最小,然后再固定B,调整W使L最小,这样迭代交替,不断将L推向最小值。EM算法可以见我的博客:“从最大似然到EM算法浅解”)。
训练过程就是一个重复迭代的过程,按上面所说,我们交替的更改a和Φ使得下面这个目标函数最小。
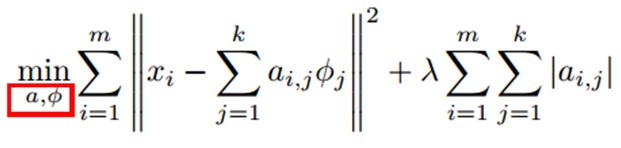
每次迭代分两步:
a)固定字典Φ[k],然后调整a[k],使得上式,即目标函数最小(即解LASSO问题)。
b)然后固定住a [k],调整Φ [k],使得上式,即目标函数最小(即解凸QP问题)。
不断迭代,直至收敛。这样就可以得到一组可以良好表示这一系列x的基,也就是字典。
2)Coding阶段:给定一个新的图片x,由上面得到的字典,通过解一个LASSO问题得到稀疏向量a。这个稀疏向量就是这个输入向量x的一个稀疏表达了。
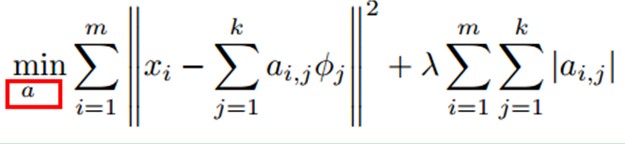
例如:

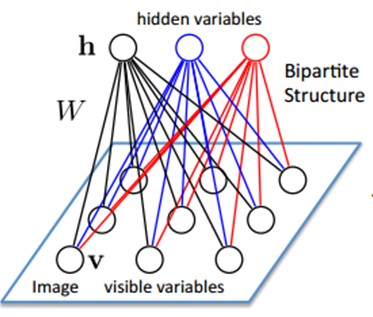
9.3、Restricted Boltzmann Machine (RBM)限制波尔兹曼机
假设有一个二部图,每一层的节点之间没有链接,一层是可视层,即输入数据层(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值),同时假设全概率分布p(v,h)满足Boltzmann 分布,我们称这个模型是Restricted BoltzmannMachine (RBM)。
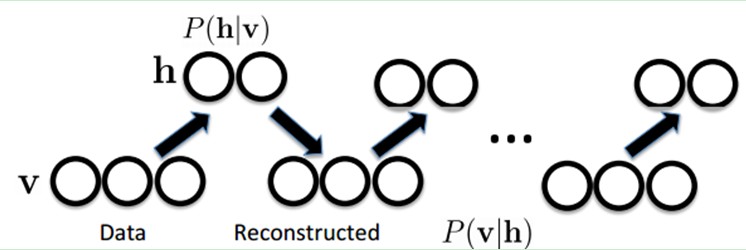
下面我们来看看为什么它是Deep Learning方法。首先,这个模型因为是二部图,所以在已知v的情况下,所有的隐藏节点之间是条件独立的(因为节点之间不存在连接),即p(h|v)=p(h1|v)…p(hn|v)。同理,在已知隐藏层h的情况下,所有的可视节点都是条件独立的。同时又由于所有的v和h满足Boltzmann 分布,因此,当输入v的时候,通过p(h|v) 可以得到隐藏层h,而得到隐藏层h之后,通过p(v|h)又能得到可视层,通过调整参数,我们就是要使得从隐藏层得到的可视层v1与原来的可视层v如果一样,那么得到的隐藏层就是可视层另外一种表达,因此隐藏层可以作为可视层输入数据的特征,所以它就是一种Deep Learning方法。
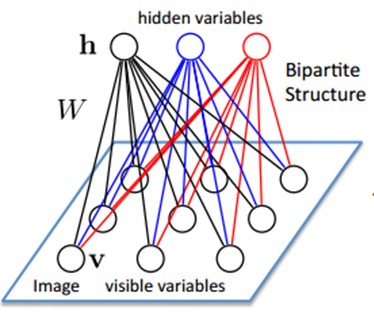
如何训练呢?也就是可视层节点和隐节点间的权值怎么确定呢?我们需要做一些数学分析。也就是模型了。
联合组态(jointconfiguration)的能量可以表示为:
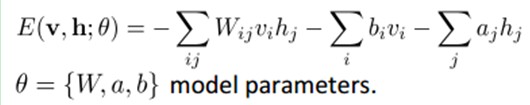
而某个组态的联合概率分布可以通过Boltzmann 分布(和这个组态的能量)来确定:

因为隐藏节点之间是条件独立的(因为节点之间不存在连接),即:
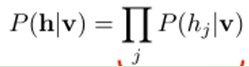
然后我们可以比较容易(对上式进行因子分解Factorizes)得到在给定可视层v的基础上,隐层第j个节点为1或者为0的概率:
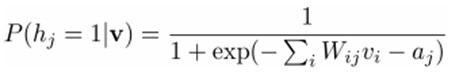
同理,在给定隐层h的基础上,可视层第i个节点为1或者为0的概率也可以容易得到:
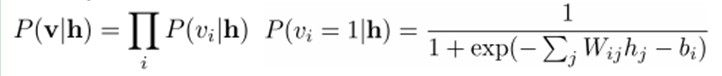
给定一个满足独立同分布的样本集:D={v(1), v(2),…, v(N)},我们需要学习参数θ={W,a,b}。
我们最大化以下对数似然函数(最大似然估计:对于某个概率模型,我们需要选择一个参数,让我们当前的观测样本的概率最大):
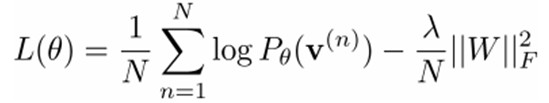
也就是对最大对数似然函数求导,就可以得到L最大时对应的参数W了。
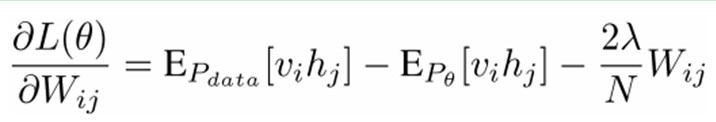
如果,我们把隐藏层的层数增加,我们可以得到Deep Boltzmann Machine(DBM);如果我们在靠近可视层的部分使用贝叶斯信念网络(即有向图模型,当然这里依然限制层中节点之间没有链接),而在最远离可视层的部分使用Restricted Boltzmann Machine,我们可以得到DeepBelief Net(DBN)。
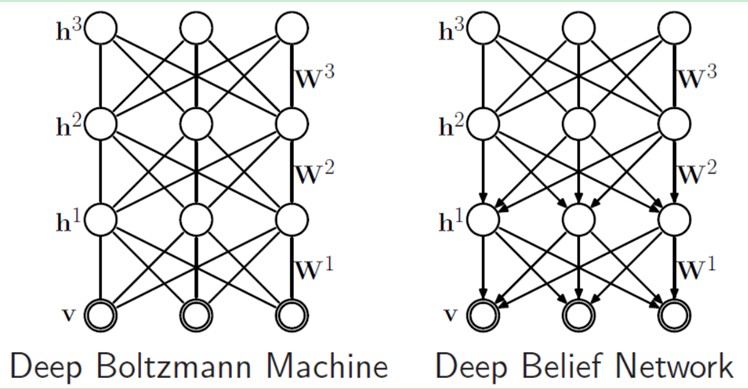
9.4、Deep Belief Networks深信度网络
DBNs是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和 P(Label|Observation)都做了评估,而判别模型仅仅而已评估了后者,也就是P(Label|Observation)。对于在深度神经网络应用传统的BP算法的时候,DBNs遇到了以下问题:
(1)需要为训练提供一个有标签的样本集;
(2)学习过程较慢;
(3)不适当的参数选择会导致学习收敛于局部最优解。
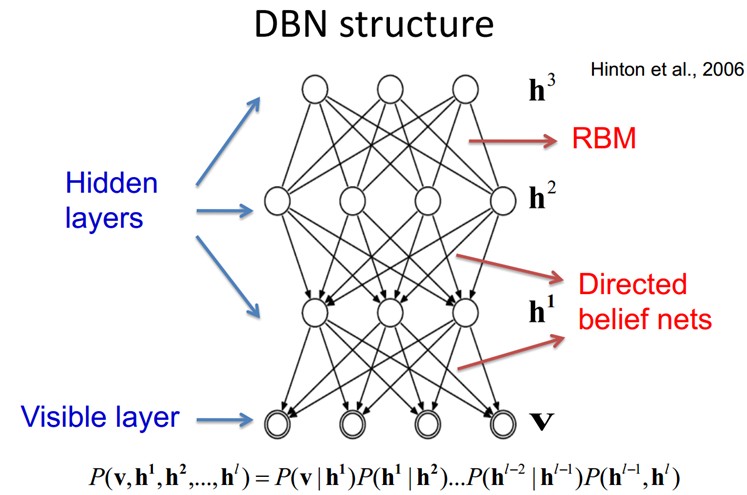
DBNs由多个限制玻尔兹曼机(Restricted Boltzmann Machines)层组成,一个典型的神经网络类型如图三所示。这些网络被“限制”为一个可视层和一个隐层,层间存在连接,但层内的单元间不存在连接。隐层单元被训练去捕捉在可视层表现出来的高阶数据的相关性。
首先,先不考虑最顶构成一个联想记忆(associative memory)的两层,一个DBN的连接是通过自顶向下的生成权值来指导确定的,RBMs就像一个建筑块一样,相比传统和深度分层的sigmoid信念网络,它能易于连接权值的学习。
最开始的时候,通过一个非监督贪婪逐层方法去预训练获得生成模型的权值,非监督贪婪逐层方法被Hinton证明是有效的,并被其称为对比分歧(contrastive divergence)。
在这个训练阶段,在可视层会产生一个向量v,通过它将值传递到隐层。反过来,可视层的输入会被随机的选择,以尝试去重构原始的输入信号。最后,这些新的可视的神经元激活单元将前向传递重构隐层激活单元,获得h(在训练过程中,首先将可视向量值映射给隐单元;然后可视单元由隐层单元重建;这些新可视单元再次映射给隐单元,这样就获取新的隐单元。执行这种反复步骤叫做吉布斯采样)。这些后退和前进的步骤就是我们熟悉的Gibbs采样,而隐层激活单元和可视层输入之间的相关性差别就作为权值更新的主要依据。
训练时间会显著的减少,因为只需要单个步骤就可以接近最大似然学习。增加进网络的每一层都会改进训练数据的对数概率,我们可以理解为越来越接近能量的真实表达。这个有意义的拓展,和无标签数据的使用,是任何一个深度学习应用的决定性的因素。
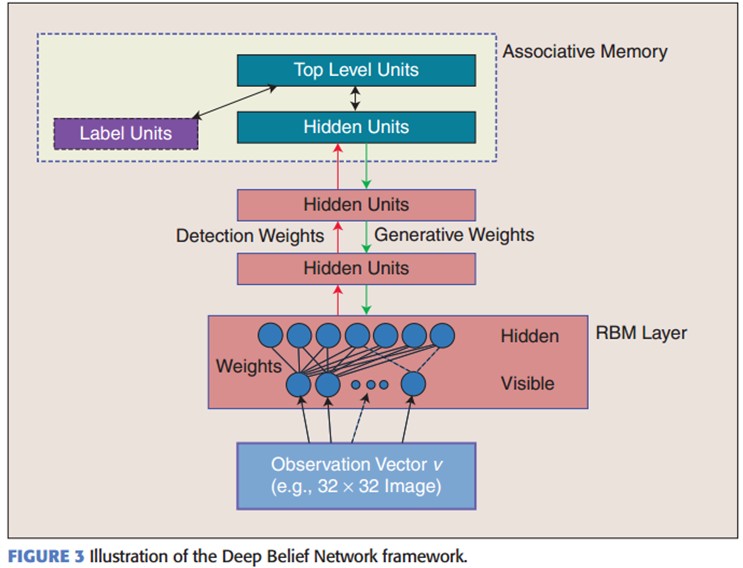
在最高两层,权值被连接到一起,这样更低层的输出将会提供一个参考的线索或者关联给顶层,这样顶层就会将其联系到它的记忆内容。而我们最关心的,最后想得到的就是判别性能,例如分类任务里面。
在预训练后,DBN可以通过利用带标签数据用BP算法去对判别性能做调整。在这里,一个标签集将被附加到顶层(推广联想记忆),通过一个自下向上的,学习到的识别权值获得一个网络的分类面。这个性能会比单纯的BP算法训练的网络好。这可以很直观的解释,DBNs的BP算法只需要对权值参数空间进行一个局部的搜索,这相比前向神经网络来说,训练是要快的,而且收敛的时间也少。
DBNs的灵活性使得它的拓展比较容易。一个拓展就是卷积DBNs(Convolutional Deep Belief Networks(CDBNs))。DBNs并没有考虑到图像的2维结构信息,因为输入是简单的从一个图像矩阵一维向量化的。而CDBNs就是考虑到了这个问题,它利用邻域像素的空域关系,通过一个称为卷积RBMs的模型区达到生成模型的变换不变性,而且可以容易得变换到高维图像。DBNs并没有明确地处理对观察变量的时间联系的学习上,虽然目前已经有这方面的研究,例如堆叠时间RBMs,以此为推广,有序列学习的dubbed temporal convolutionmachines,这种序列学习的应用,给语音信号处理问题带来了一个让人激动的未来研究方向。
目前,和DBNs有关的研究包括堆叠自动编码器,它是通过用堆叠自动编码器来替换传统DBNs里面的RBMs。这就使得可以通过同样的规则来训练产生深度多层神经网络架构,但它缺少层的参数化的严格要求。与DBNs不同,自动编码器使用判别模型,这样这个结构就很难采样输入采样空间,这就使得网络更难捕捉它的内部表达。但是,降噪自动编码器却能很好的避免这个问题,并且比传统的DBNs更优。它通过在训练过程添加随机的污染并堆叠产生场泛化性能。训练单一的降噪自动编码器的过程和RBMs训练生成模型的过程一样。
9.5、Convolutional Neural Networks卷积神经网络
卷积神经网络是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。
CNNs是受早期的延时神经网络(TDNN)的影响。延时神经网络通过在时间维度上共享权值降低学习复杂度,适用于语音和时间序列信号的处理。
CNNs是第一个真正成功训练多层网络结构的学习算法。它利用空间关系减少需要学习的参数数目以提高一般前向BP算法的训练性能。CNNs作为一个深度学习架构提出是为了最小化数据的预处理要求。在CNN中,图像的一小部分(局部感受区域)作为层级结构的最低层的输入,信息再依次传输到不同的层,每层通过一个数字滤波器去获得观测数据的最显著的特征。这个方法能够获取对平移、缩放和旋转不变的观测数据的显著特征,因为图像的局部感受区域允许神经元或者处理单元可以访问到最基础的特征,例如定向边缘或者角点。
1)卷积神经网络的历史
1962年Hubel和Wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念,1984年日本学者Fukushima基于感受野概念提出的神经认知机(neocognitron)可以看作是卷积神经网络的第一个实现网络,也是感受野概念在人工神经网络领域的首次应用。神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
通常神经认知机包含两类神经元,即承担特征抽取的S-元和抗变形的C-元。S-元中涉及两个重要参数,即感受野与阈值参数,前者确定输入连接的数目,后者则控制对特征子模式的反应程度。许多学者一直致力于提高神经认知机的性能的研究:在传统的神经认知机中,每个S-元的感光区中由C-元带来的视觉模糊量呈正态分布。如果感光区的边缘所产生的模糊效果要比中央来得大,S-元将会接受这种非正态模糊所导致的更大的变形容忍性。我们希望得到的是,训练模式与变形刺激模式在感受野的边缘与其中心所产生的效果之间的差异变得越来越大。为了有效地形成这种非正态模糊,Fukushima提出了带双C-元层的改进型神经认知机。
Van Ooyen和Niehuis为提高神经认知机的区别能力引入了一个新的参数。事实上,该参数作为一种抑制信号,抑制了神经元对重复激励特征的激励。多数神经网络在权值中记忆训练信息。根据Hebb学习规则,某种特征训练的次数越多,在以后的识别过程中就越容易被检测。也有学者将进化计算理论与神经认知机结合,通过减弱对重复性激励特征的训练学习,而使得网络注意那些不同的特征以助于提高区分能力。上述都是神经认知机的发展过程,而卷积神经网络可看作是神经认知机的推广形式,神经认知机是卷积神经网络的一种特例。
2)卷积神经网络的网络结构
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
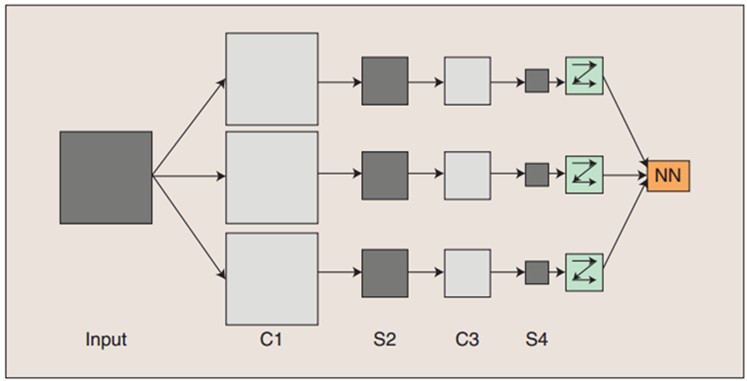
图:卷积神经网络的概念示范:输入图像通过和三个可训练的滤波器和可加偏置进行卷积,滤波过程如图一,卷积后在C1层产生三个特征映射图,然后特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图。这些映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
一般地,C层为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。卷积神经网络中的每一个特征提取层(C-层)都紧跟着一个用来求局部平均与二次提取的计算层(S-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。
3)关于参数减少与权值共享
上面聊到,好像CNN一个牛逼的地方就在于通过感受野和权值共享减少了神经网络需要训练的参数的个数。那究竟是啥的呢?
下图左:如果我们有1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话(每个隐层神经元都连接图像的每一个像素点),就有1000x1000x1000000=10^12个连接,也就是10^12个权值参数。然而图像的空间联系是局部的,就像人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样,我们就可以减少连接的数目,也就是减少神经网络需要训练的权值参数的个数了。如下图右:假如局部感受野是10x10,隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。比原来减少了四个0(数量级),这样训练起来就没那么费力了,但还是感觉很多的啊,那还有啥办法没?
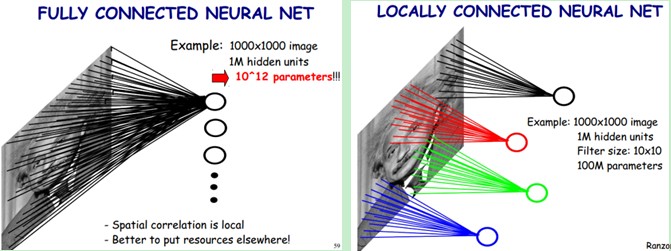
我们知道,隐含层的每一个神经元都连接10x10个图像区域,也就是说每一个神经元存在10x10=100个连接权值参数。那如果我们每个神经元这100个参数是相同的呢?也就是说每个神经元用的是同一个卷积核去卷积图像。这样我们就只有多少个参数??只有100个参数啊!!!亲!不管你隐层的神经元个数有多少,两层间的连接我只有100个参数啊!亲!这就是权值共享啊!亲!这就是卷积神经网络的主打卖点啊!亲!(有点烦了,呵呵)也许你会问,这样做靠谱吗?为什么可行呢?这个……共同学习。
好了,你就会想,这样提取特征也忒不靠谱吧,这样你只提取了一种特征啊?对了,真聪明,我们需要提取多种特征对不?假如一种滤波器,也就是一种卷积核就是提出图像的一种特征,例如某个方向的边缘。那么我们需要提取不同的特征,怎么办,加多几种滤波器不就行了吗?对了。所以假设我们加到100种滤波器,每种滤波器的参数不一样,表示它提出输入图像的不同特征,例如不同的边缘。这样每种滤波器去卷积图像就得到对图像的不同特征的放映,我们称之为Feature Map。所以100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元。到这个时候明了了吧。我们这一层有多少个参数了?100种卷积核x每种卷积核共享100个参数=100x100=10K,也就是1万个参数。才1万个参数啊!亲!(又来了,受不了了!)见下图右:不同的颜色表达不同的滤波器。
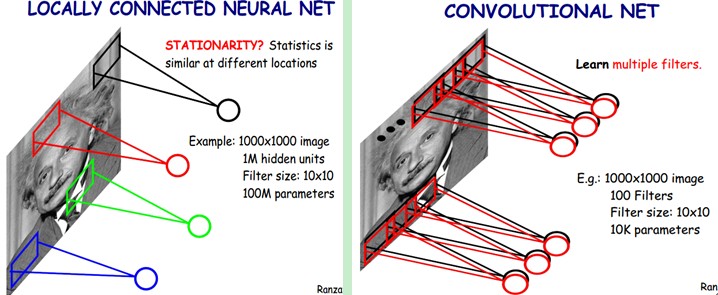
嘿哟,遗漏一个问题了。刚才说隐层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。那么隐层的神经元个数怎么确定呢?它和原图像,也就是输入的大小(神经元个数)、滤波器的大小和滤波器在图像中的滑动步长都有关!例如,我的图像是1000x1000像素,而滤波器大小是10x10,假设滤波器没有重叠,也就是步长为10,这样隐层的神经元个数就是(1000x1000 )/ (10x10)=100x100个神经元了,假设步长是8,也就是卷积核会重叠两个像素,那么……我就不算了,思想懂了就好。注意了,这只是一种滤波器,也就是一个Feature Map的神经元个数哦,如果100个Feature Map就是100倍了。由此可见,图像越大,神经元个数和需要训练的权值参数个数的贫富差距就越大。
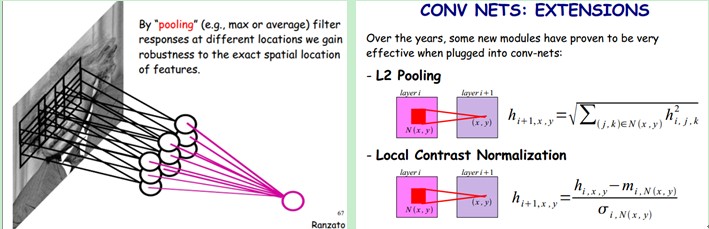
需要注意的一点是,上面的讨论都没有考虑每个神经元的偏置部分。所以权值个数需要加1 。这个也是同一种滤波器共享的。
总之,卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。
4)一个典型的例子说明
一种典型的用来识别数字的卷积网络是LeNet-5(效果和paper等见这)。当年美国大多数银行就是用它来识别支票上面的手写数字的。能够达到这种商用的地步,它的准确性可想而知。毕竟目前学术界和工业界的结合是最受争议的。
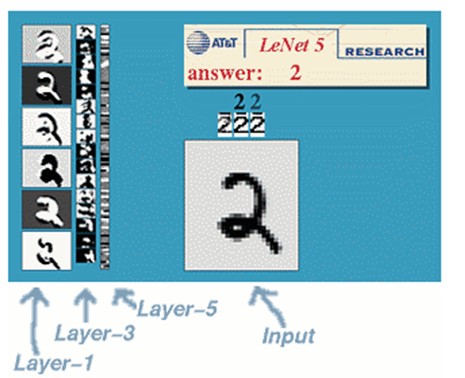
那下面咱们也用这个例子来说明下。
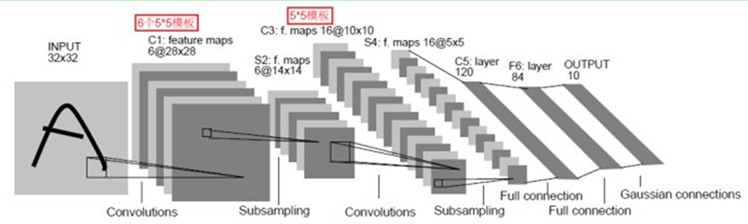
LeNet-5共有7层,不包含输入,每层都包含可训练参数(连接权重)。输入图像为32*32大小。这要比Mnist数据库(一个公认的手写数据库)中最大的字母还大。这样做的原因是希望潜在的明显特征如笔画断电或角点能够出现在最高层特征监测子感受野的中心。
我们先要明确一点:每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。
C1层是一个卷积层(为什么是卷积?卷积运算一个重要的特点就是,通过卷积运算,可以使原信号特征增强,并且降低噪音),由6个特征图Feature Map构成。特征图中每个神经元与输入中5*5的邻域相连。特征图的大小为28*28,这样能防止输入的连接掉到边界之外(是为了BP反馈时的计算,不致梯度损失,个人见解)。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。
S2层是一个下采样层(为什么是下采样?利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息),有6个14*14的特征图。特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数计算。可训练系数和偏置控制着sigmoid函数的非线性程度。如果系数比较小,那么运算近似于线性运算,亚采样相当于模糊图像。如果系数比较大,根据偏置的大小亚采样可以被看成是有噪声的“或”运算或者有噪声的“与”运算。每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。S2层有12个可训练参数和5880个连接。
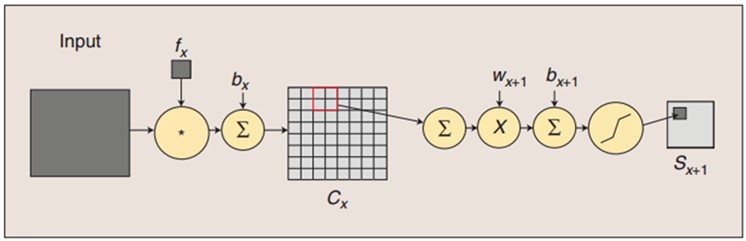
图:卷积和子采样过程:卷积过程包括:用一个可训练的滤波器fx去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征map了),然后加一个偏置bx,得到卷积层Cx。子采样过程包括:每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个大概缩小四倍的特征映射图Sx+1。
所以从一个平面到下一个平面的映射可以看作是作卷积运算,S-层可看作是模糊滤波器,起到二次特征提取的作用。隐层与隐层之间空间分辨率递减,而每层所含的平面数递增,这样可用于检测更多的特征信息。
C3层也是一个卷积层,它同样通过5x5的卷积核去卷积层S2,然后得到的特征map就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征map了。这里需要注意的一点是:C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合(这个做法也并不是唯一的)。(看到没有,这里是组合,就像之前聊到的人的视觉系统一样,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分)。
刚才说C3中每个特征图由S2中所有6个或者几个特征map组合而成。为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。第一,不完全的连接机制将连接的数量保持在合理的范围内。第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。
例如,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。这样C3层有1516个可训练参数和151600个连接。
S4层是一个下采样层,由16个5*5大小的特征图构成。特征图中的每个单元与C3中相应特征图的2*2邻域相连接,跟C1和S2之间的连接一样。S4层有32个可训练参数(每个特征图1个因子和一个偏置)和2000个连接。
C5层是一个卷积层,有120个特征图。每个单元与S4层的全部16个单元的5*5邻域相连。由于S4层特征图的大小也为5*5(同滤波器一样),故C5特征图的大小为1*1:这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层而非全相联层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1*1大。C5层有48120个可训练连接。
F6层有84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有10164个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给sigmoid函数产生单元i的一个状态。
最后,输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
使用这种分布编码而非更常用的“1 of N”编码用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。原因是大多数时间非分布编码的输出必须为0。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目标。因为与sigmoid不同,他们在输入空间的较好限制的区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大弯曲的点处。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。
5)训练过程
神经网络用于模式识别的主流是有指导学习网络,无指导学习网络更多的是用于聚类分析。对于有指导的模式识别,由于任一样本的类别是已知的,样本在空间的分布不再是依据其自然分布倾向来划分,而是要根据同类样本在空间的分布及不同类样本之间的分离程度找一种适当的空间划分方法,或者找到一个分类边界,使得不同类样本分别位于不同的区域内。这就需要一个长时间且复杂的学习过程,不断调整用以划分样本空间的分类边界的位置,使尽可能少的样本被划分到非同类区域中。
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。卷积网络执行的是有导师训练,所以其样本集是由形如:(输入向量,理想输出向量)的向量对构成的。所有这些向量对,都应该是来源于网络即将模拟的系统的实际“运行”结果。它们可以是从实际运行系统中采集来的。在开始训练前,所有的权都应该用一些不同的小随机数进行初始化。“小随机数”用来保证网络不会因权值过大而进入饱和状态,从而导致训练失败;“不同”用来保证网络可以正常地学习。实际上,如果用相同的数去初始化权矩阵,则网络无能力学习。
训练算法与传统的BP算法差不多。主要包括4步,这4步被分为两个阶段:
第一阶段,向前传播阶段:
a)从样本集中取一个样本(X,Yp),将X输入网络;
b)计算相应的实际输出Op。
在此阶段,信息从输入层经过逐级的变换,传送到输出层。这个过程也是网络在完成训练后正常运行时执行的过程。在此过程中,网络执行的是计算(实际上就是输入与每层的权值矩阵相点乘,得到最后的输出结果):
Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二阶段,向后传播阶段
a)算实际输出Op与相应的理想输出Yp的差;
b)按极小化误差的方法反向传播调整权矩阵。
6)卷积神经网络的优点
卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
流的分类方式几乎都是基于统计特征的,这就意味着在进行分辨前必须提取某些特征。然而,显式的特征提取并不容易,在一些应用问题中也并非总是可靠的。卷积神经网络,它避免了显式的特征取样,隐式地从训练数据中进行学习。这使得卷积神经网络明显有别于其他基于神经网络的分类器,通过结构重组和减少权值将特征提取功能融合进多层感知器。它可以直接处理灰度图片,能够直接用于处理基于图像的分类。
卷积网络较一般神经网络在图像处理方面有如下优点: a)输入图像和网络的拓扑结构能很好的吻合;b)特征提取和模式分类同时进行,并同时在训练中产生;c)权重共享可以减少网络的训练参数,使神经网络结构变得更简单,适应性更强。
7)小结
CNNs中这种层间联系和空域信息的紧密关系,使其适于图像处理和理解。而且,其在自动提取图像的显著特征方面还表现出了比较优的性能。在一些例子当中,Gabor滤波器已经被使用在一个初始化预处理的步骤中,以达到模拟人类视觉系统对视觉刺激的响应。在目前大部分的工作中,研究者将CNNs应用到了多种机器学习问题中,包括人脸识别,文档分析和语言检测等。为了达到寻找视频中帧与帧之间的相干性的目的,目前CNNs通过一个时间相干性去训练,但这个不是CNNs特有的。
呵呵,这部分讲得太啰嗦了,又没讲到点上。没办法了,先这样的,这样这个过程我还没有走过,所以自己水平有限啊,望各位明察。需要后面再改了,呵呵。
十、总结与展望
1)Deep learning总结
深度学习是关于自动学习要建模的数据的潜在(隐含)分布的多层(复杂)表达的算法。换句话来说,深度学习算法自动的提取分类需要的低层次或者高层次特征。高层次特征,一是指该特征可以分级(层次)地依赖其他特征,例如:对于机器视觉,深度学习算法从原始图像去学习得到它的一个低层次表达,例如边缘检测器,小波滤波器等,然后在这些低层次表达的基础上再建立表达,例如这些低层次表达的线性或者非线性组合,然后重复这个过程,最后得到一个高层次的表达。
Deep learning能够得到更好地表示数据的feature,同时由于模型的层次、参数很多,capacity足够,因此,模型有能力表示大规模数据,所以对于图像、语音这种特征不明显(需要手工设计且很多没有直观物理含义)的问题,能够在大规模训练数据上取得更好的效果。此外,从模式识别特征和分类器的角度,deep learning框架将feature和分类器结合到一个框架中,用数据去学习feature,在使用中减少了手工设计feature的巨大工作量(这是目前工业界工程师付出努力最多的方面),因此,不仅仅效果可以更好,而且,使用起来也有很多方便之处,因此,是十分值得关注的一套框架,每个做ML的人都应该关注了解一下。
当然,deep learning本身也不是完美的,也不是解决世间任何ML问题的利器,不应该被放大到一个无所不能的程度。
2)Deep learning未来
深度学习目前仍有大量工作需要研究。目前的关注点还是从机器学习的领域借鉴一些可以在深度学习使用的方法,特别是降维领域。例如:目前一个工作就是稀疏编码,通过压缩感知理论对高维数据进行降维,使得非常少的元素的向量就可以精确的代表原来的高维信号。另一个例子就是半监督流行学习,通过测量训练样本的相似性,将高维数据的这种相似性投影到低维空间。另外一个比较鼓舞人心的方向就是evolutionary programming approaches(遗传编程方法),它可以通过最小化工程能量去进行概念性自适应学习和改变核心架构。
Deep learning还有很多核心的问题需要解决:
(1)对于一个特定的框架,对于多少维的输入它可以表现得较优(如果是图像,可能是上百万维)?
(2)对捕捉短时或者长时间的时间依赖,哪种架构才是有效的?
(3)如何对于一个给定的深度学习架构,融合多种感知的信息?
(4)有什么正确的机理可以去增强一个给定的深度学习架构,以改进其鲁棒性和对扭曲和数据丢失的不变性?
(5)模型方面是否有其他更为有效且有理论依据的深度模型学习算法?
探索新的特征提取模型是值得深入研究的内容。此外有效的可并行训练算法也是值得研究的一个方向。当前基于最小批处理的随机梯度优化算法很难在多计算机中进行并行训练。通常办法是利用图形处理单元加速学习过程。然而单个机器GPU对大规模数据识别或相似任务数据集并不适用。在深度学习应用拓展方面,如何合理充分利用深度学习在增强传统学习算法的性能仍是目前各领域的研究重点。
十一、参考文献和Deep Learning学习资源(持续更新……)
先是机器学习领域大牛的微博:@余凯_西二旗民工;@老师木;@梁斌penny;@张栋_机器学习;@邓侃;@大数据皮东;@djvu9……
(1)Deep Learning
http://deeplearning.net/
(2)Deep Learning Methods for Vision
http://cs.nyu.edu/~fergus/tutorials/deep_learning_cvpr12/
(3)Neural Network for Recognition of Handwritten Digits[Project]
http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi
(4)Training a deep autoencoder or a classifier on MNIST digits
http://www.cs.toronto.edu/~hinton/MatlabForSciencePaper.html
(5)Ersatz:deep neural networks in the cloud
http://www.ersatz1.com/
(6)Deep Learning
http://www.cs.nyu.edu/~yann/research/deep/
(7)Invited talk "A Tutorial on Deep Learning" by Dr. Kai Yu (余凯)
http://vipl.ict.ac.cn/News/academic-report-tutorial-deep-learning-dr-kai-yu
(8)CNN - Convolutional neural network class
http://www.mathworks.cn/matlabcentral/fileexchange/24291
(9)Yann LeCun's Publications
http://yann.lecun.com/exdb/publis/index.html#lecun-98
(10) LeNet-5, convolutional neural networks
http://yann.lecun.com/exdb/lenet/index.html
(11) Deep Learning 大牛Geoffrey E. Hinton's HomePage
http://www.cs.toronto.edu/~hinton/
(12)Sparse coding simulation software[Project]
http://redwood.berkeley.edu/bruno/sparsenet/
(13)Andrew Ng's homepage
http://robotics.stanford.edu/~ang/
(14)stanford deep learning tutorial
http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
(15)「深度神经网络」(deep neural network)具体是怎样工作的
http://www.zhihu.com/question/19833708?group_id=15019075#1657279
(16)A shallow understanding on deep learning
http://blog.sina.com.cn/s/blog_6ae183910101dw2z.html
(17)Bengio's Learning Deep Architectures for AI
http://www.iro.umontreal.ca/~bengioy/papers/ftml_book.pdf
(18)andrew ng's talk video:
http://techtalks.tv/talks/machine-learning-and-ai-via-brain-simulations/57862/
(19)cvpr 2012 tutorial:
http://cs.nyu.edu/~fergus/tutorials/deep_learning_cvpr12/tutorial_p2_nnets_ranzato_short.pdf
(20)Andrew ng清华报告听后感
http://blog.sina.com.cn/s/blog_593af2a70101bqyo.html
(21)Kai Yu:CVPR12 Tutorial on Deep Learning Sparse Coding
(22)Honglak Lee:Deep Learning Methods for Vision
(23)Andrew Ng :Machine Learning and AI via Brain simulations
(24)Deep Learning 【2,3】
http://blog.sina.com.cn/s/blog_46d0a3930101gs5h.html
(25)deep learning这件小事……
http://blog.sina.com.cn/s/blog_67fcf49e0101etab.html
(26)Yoshua Bengio, U. Montreal:Learning Deep Architectures
(27)Kai Yu:A Tutorial on Deep Learning
(28)Marc'Aurelio Ranzato:NEURAL NETS FOR VISION
(29)Unsupervised feature learning and deep learning
http://blog.csdn.net/abcjennifer/article/details/7804962
(30)机器学习前沿热点–Deep Learning
http://elevencitys.com/?p=1854
(31)机器学习——深度学习(Deep Learning)
http://blog.csdn.net/abcjennifer/article/details/7826917
(32)卷积神经网络
http://wenku.baidu.com/view/cd16fb8302d276a200292e22.html
(33)浅谈Deep Learning的基本思想和方法
http://blog.csdn.net/xianlingmao/article/details/8478562
(34)深度神经网络
http://blog.csdn.net/txdb/article/details/6766373
(35)Google的猫脸识别:人工智能的新突破
http://www.36kr.com/p/122132.html
(36)余凯,深度学习-机器学习的新浪潮,Technical News程序天下事
http://blog.csdn.net/datoubo/article/details/8577366
(37)Geoffrey Hinton:UCLTutorial on: Deep Belief Nets
(38)Learning Deep Boltzmann Machines
http://web.mit.edu/~rsalakhu/www/DBM.html
(39)Efficient Sparse Coding Algorithm
http://blog.sina.com.cn/s/blog_62af19190100gux1.html
(40)Itamar Arel, Derek C. Rose, and Thomas P. Karnowski: Deep Machine Learning—A New Frontier in Artificial Intelligence Research
(41)Francis Quintal Lauzon:An introduction to deep learning
(42)Tutorial on Deep Learning and Applications
(43)Boltzmann神经网络模型与学习算法
http://wenku.baidu.com/view/490dcf748e9951e79b892785.html
(44)Deep Learning 和 Knowledge Graph 引爆大数据革命
http://blog.sina.com.cn/s/blog_46d0a3930101fswl.html
(45)……
计算机视觉、机器学习相关领域论文和源代码大集合--持续更新……
zouxy09@qq.com
http://blog.csdn.net/zouxy09
注:下面有project网站的大部分都有paper和相应的code。Code一般是C/C++或者Matlab代码。
最近一次更新:2013-3-17
一、特征提取Feature Extraction:
· SIFT [1] [Demo program][SIFT Library] [VLFeat]
· PCA-SIFT [2] [Project]
· Affine-SIFT [3] [Project]
· SURF [4] [OpenSURF] [Matlab Wrapper]
· Affine Covariant Features [5] [Oxford project]
· MSER [6] [Oxford project] [VLFeat]
· Geometric Blur [7] [Code]
· Local Self-Similarity Descriptor [8] [Oxford implementation]
· Global and Efficient Self-Similarity [9] [Code]
· Histogram of Oriented Graidents [10] [INRIA Object Localization Toolkit] [OLT toolkit for Windows]
· GIST [11] [Project]
· Shape Context [12] [Project]
· Color Descriptor [13] [Project]
· Pyramids of Histograms of Oriented Gradients [Code]
· Space-Time Interest Points (STIP) [14][Project] [Code]
· Boundary Preserving Dense Local Regions [15][Project]
· Weighted Histogram[Code]
· Histogram-based Interest Points Detectors[Paper][Code]
· An OpenCV - C++ implementation of Local Self Similarity Descriptors [Project]
· Fast Sparse Representation with Prototypes[Project]
· Corner Detection [Project]
· AGAST Corner Detector: faster than FAST and even FAST-ER[Project]
· Real-time Facial Feature Detection using Conditional Regression Forests[Project]
· Global and Efficient Self-Similarity for Object Classification and Detection[code]
· WαSH: Weighted α-Shapes for Local Feature Detection[Project]
· HOG[Project]
· Online Selection of Discriminative Tracking Features[Project]
二、图像分割Image Segmentation:
· Normalized Cut [1] [Matlab code]
· Gerg Mori’ Superpixel code [2] [Matlab code]
· Efficient Graph-based Image Segmentation [3] [C++ code] [Matlab wrapper]
· Mean-Shift Image Segmentation [4] [EDISON C++ code] [Matlab wrapper]
· OWT-UCM Hierarchical Segmentation [5] [Resources]
· Turbepixels [6] [Matlab code 32bit] [Matlab code 64bit] [Updated code]
· Quick-Shift [7] [VLFeat]
· SLIC Superpixels [8] [Project]
· Segmentation by Minimum Code Length [9] [Project]
· Biased Normalized Cut [10] [Project]
· Segmentation Tree [11-12] [Project]
· Entropy Rate Superpixel Segmentation [13] [Code]
· Fast Approximate Energy Minimization via Graph Cuts[Paper][Code]
· Efficient Planar Graph Cuts with Applications in Computer Vision[Paper][Code]
· Isoperimetric Graph Partitioning for Image Segmentation[Paper][Code]
· Random Walks for Image Segmentation[Paper][Code]
· Blossom V: A new implementation of a minimum cost perfect matching algorithm[Code]
· An Experimental Comparison of Min-Cut/Max-Flow Algorithms for Energy Minimization in Computer Vision[Paper][Code]
· Geodesic Star Convexity for Interactive Image Segmentation[Project]
· Contour Detection and Image Segmentation Resources[Project][Code]
· Biased Normalized Cuts[Project]
· Max-flow/min-cut[Project]
· Chan-Vese Segmentation using Level Set[Project]
· A Toolbox of Level Set Methods[Project]
· Re-initialization Free Level Set Evolution via Reaction Diffusion[Project]
· Improved C-V active contour model[Paper][Code]
· A Variational Multiphase Level Set Approach to Simultaneous Segmentation and Bias Correction[Paper][Code]
· Level Set Method Research by Chunming Li[Project]
· ClassCut for Unsupervised Class Segmentation[code]
· SEEDS: Superpixels Extracted via Energy-Driven Sampling [Project][other]
三、目标检测Object Detection:
· A simple object detector with boosting [Project]
· INRIA Object Detection and Localization Toolkit [1] [Project]
· Discriminatively Trained Deformable Part Models [2] [Project]
· Cascade Object Detection with Deformable Part Models [3] [Project]
· Poselet [4] [Project]
· Implicit Shape Model [5] [Project]
· Viola and Jones’s Face Detection [6] [Project]
· Bayesian Modelling of Dyanmic Scenes for Object Detection[Paper][Code]
· Hand detection using multiple proposals[Project]
· Color Constancy, Intrinsic Images, and Shape Estimation[Paper][Code]
· Discriminatively trained deformable part models[Project]
· Gradient Response Maps for Real-Time Detection of Texture-Less Objects: LineMOD [Project]
· Image Processing On Line[Project]
· Robust Optical Flow Estimation[Project]
· Where's Waldo: Matching People in Images of Crowds[Project]
· Scalable Multi-class Object Detection[Project]
· Class-Specific Hough Forests for Object Detection[Project]
· Deformed Lattice Detection In Real-World Images[Project]
· Discriminatively trained deformable part models[Project]
四、显著性检测Saliency Detection:
· Itti, Koch, and Niebur’ saliency detection [1] [Matlab code]
· Frequency-tuned salient region detection [2] [Project]
· Saliency detection using maximum symmetric surround [3] [Project]
· Attention via Information Maximization [4] [Matlab code]
· Context-aware saliency detection [5] [Matlab code]
· Graph-based visual saliency [6] [Matlab code]
· Saliency detection: A spectral residual approach. [7] [Matlab code]
· Segmenting salient objects from images and videos. [8] [Matlab code]
· Saliency Using Natural statistics. [9] [Matlab code]
· Discriminant Saliency for Visual Recognition from Cluttered Scenes. [10] [Code]
· Learning to Predict Where Humans Look [11] [Project]
· Global Contrast based Salient Region Detection [12] [Project]
· Bayesian Saliency via Low and Mid Level Cues[Project]
· Top-Down Visual Saliency via Joint CRF and Dictionary Learning[Paper][Code]
· Saliency Detection: A Spectral Residual Approach[Code]
五、图像分类、聚类Image Classification, Clustering
· Pyramid Match [1] [Project]
· Spatial Pyramid Matching [2] [Code]
· Locality-constrained Linear Coding [3] [Project] [Matlab code]
· Sparse Coding [4] [Project] [Matlab code]
· Texture Classification [5] [Project]
· Multiple Kernels for Image Classification [6] [Project]
· Feature Combination [7] [Project]
· SuperParsing [Code]
· Large Scale Correlation Clustering Optimization[Matlab code]
· Detecting and Sketching the Common[Project]
· Self-Tuning Spectral Clustering[Project][Code]
· User Assisted Separation of Reflections from a Single Image Using a Sparsity Prior[Paper][Code]
· Filters for Texture Classification[Project]
· Multiple Kernel Learning for Image Classification[Project]
· SLIC Superpixels[Project]
六、抠图Image Matting
· A Closed Form Solution to Natural Image Matting [Code]
· Spectral Matting [Project]
· Learning-based Matting [Code]
七、目标跟踪Object Tracking:
· A Forest of Sensors - Tracking Adaptive Background Mixture Models [Project]
· Object Tracking via Partial Least Squares Analysis[Paper][Code]
· Robust Object Tracking with Online Multiple Instance Learning[Paper][Code]
· Online Visual Tracking with Histograms and Articulating Blocks[Project]
· Incremental Learning for Robust Visual Tracking[Project]
· Real-time Compressive Tracking[Project]
· Robust Object Tracking via Sparsity-based Collaborative Model[Project]
· Visual Tracking via Adaptive Structural Local Sparse Appearance Model[Project]
· Online Discriminative Object Tracking with Local Sparse Representation[Paper][Code]
· Superpixel Tracking[Project]
· Learning Hierarchical Image Representation with Sparsity, Saliency and Locality[Paper][Code]
· Online Multiple Support Instance Tracking [Paper][Code]
· Visual Tracking with Online Multiple Instance Learning[Project]
· Object detection and recognition[Project]
· Compressive Sensing Resources[Project]
· Robust Real-Time Visual Tracking using Pixel-Wise Posteriors[Project]
· Tracking-Learning-Detection[Project][OpenTLD/C++ Code]
· the HandVu:vision-based hand gesture interface[Project]
· Learning Probabilistic Non-Linear Latent Variable Models for Tracking Complex Activities[Project]
八、Kinect:
· Kinect toolbox[Project]
· OpenNI[Project]
· zouxy09 CSDN Blog[Resource]
· FingerTracker 手指跟踪[code]
九、3D相关:
· 3D Reconstruction of a Moving Object[Paper] [Code]
· Shape From Shading Using Linear Approximation[Code]
· Combining Shape from Shading and Stereo Depth Maps[Project][Code]
· Shape from Shading: A Survey[Paper][Code]
· A Spatio-Temporal Descriptor based on 3D Gradients (HOG3D)[Project][Code]
· Multi-camera Scene Reconstruction via Graph Cuts[Paper][Code]
· A Fast Marching Formulation of Perspective Shape from Shading under Frontal Illumination[Paper][Code]
· Reconstruction:3D Shape, Illumination, Shading, Reflectance, Texture[Project]
· Monocular Tracking of 3D Human Motion with a Coordinated Mixture of Factor Analyzers[Code]
· Learning 3-D Scene Structure from a Single Still Image[Project]
十、机器学习算法:
· Matlab class for computing Approximate Nearest Nieghbor (ANN) [Matlab class providing interface toANN library]
· Random Sampling[code]
· Probabilistic Latent Semantic Analysis (pLSA)[Code]
· FASTANN and FASTCLUSTER for approximate k-means (AKM)[Project]
· Fast Intersection / Additive Kernel SVMs[Project]
· SVM[Code]
· Ensemble learning[Project]
· Deep Learning[Net]
· Deep Learning Methods for Vision[Project]
· Neural Network for Recognition of Handwritten Digits[Project]
· Training a deep autoencoder or a classifier on MNIST digits[Project]
· THE MNIST DATABASE of handwritten digits[Project]
· Ersatz:deep neural networks in the cloud[Project]
· Deep Learning [Project]
· sparseLM : Sparse Levenberg-Marquardt nonlinear least squares in C/C++[Project]
· Weka 3: Data Mining Software in Java[Project]
· Invited talk "A Tutorial on Deep Learning" by Dr. Kai Yu (余凯)[Video]
· CNN - Convolutional neural network class[Matlab Tool]
· Yann LeCun's Publications[Wedsite]
· LeNet-5, convolutional neural networks[Project]
· Training a deep autoencoder or a classifier on MNIST digits[Project]
· Deep Learning 大牛Geoffrey E. Hinton's HomePage[Website]
· Multiple Instance Logistic Discriminant-based Metric Learning (MildML) and Logistic Discriminant-based Metric Learning (LDML)[Code]
· Sparse coding simulation software[Project]
· Visual Recognition and Machine Learning Summer School[Software]
十一、目标、行为识别Object, Action Recognition:
· Action Recognition by Dense Trajectories[Project][Code]
· Action Recognition Using a Distributed Representation of Pose and Appearance[Project]
· Recognition Using Regions[Paper][Code]
· 2D Articulated Human Pose Estimation[Project]
· Fast Human Pose Estimation Using Appearance and Motion via Multi-Dimensional Boosting Regression[Paper][Code]
· Estimating Human Pose from Occluded Images[Paper][Code]
· Quasi-dense wide baseline matching[Project]
· ChaLearn Gesture Challenge: Principal motion: PCA-based reconstruction of motion histograms[Project]
· Real Time Head Pose Estimation with Random Regression Forests[Project]
· 2D Action Recognition Serves 3D Human Pose Estimation[Project]
· A Hough Transform-Based Voting Framework for Action Recognition[Project]
· Motion Interchange Patterns for Action Recognition in Unconstrained Videos[Project]
· 2D articulated human pose estimation software[Project]
· Learning and detecting shape models [code]
· Progressive Search Space Reduction for Human Pose Estimation[Project]
· Learning Non-Rigid 3D Shape from 2D Motion[Project]
十二、图像处理:
· Distance Transforms of Sampled Functions[Project]
· The Computer Vision Homepage[Project]
· Efficient appearance distances between windows[code]
· Image Exploration algorithm[code]
· Motion Magnification 运动放大 [Project]
· Bilateral Filtering for Gray and Color Images 双边滤波器 [Project]
· A Fast Approximation of the Bilateral Filter using a Signal Processing Approach [Project]
十三、一些实用工具:
· EGT: a Toolbox for Multiple View Geometry and Visual Servoing[Project] [Code]
· a development kit of matlab mex functions for OpenCV library[Project]
· Fast Artificial Neural Network Library[Project]
十四、人手及指尖检测与识别:
· finger-detection-and-gesture-recognition [Code]
· Hand and Finger Detection using JavaCV[Project]
· Hand and fingers detection[Code]
十五、场景解释:
· Nonparametric Scene Parsing via Label Transfer [Project]
十六、光流Optical flow:
· High accuracy optical flow using a theory for warping [Project]
· Dense Trajectories Video Description [Project]
· SIFT Flow: Dense Correspondence across Scenes and its Applications[Project]
· KLT: An Implementation of the Kanade-Lucas-Tomasi Feature Tracker [Project]
· Tracking Cars Using Optical Flow[Project]
· Secrets of optical flow estimation and their principles[Project]
· implmentation of the Black and Anandan dense optical flow method[Project]
· Optical Flow Computation[Project]
· Beyond Pixels: Exploring New Representations and Applications for Motion Analysis[Project]
· A Database and Evaluation Methodology for Optical Flow[Project]
· optical flow relative[Project]
· Robust Optical Flow Estimation [Project]
· optical flow[Project]
十七、图像检索Image Retrieval:
· Semi-Supervised Distance Metric Learning for Collaborative Image Retrieval [Paper][code]
十八、马尔科夫随机场Markov Random Fields:
· Markov Random Fields for Super-Resolution [Project]
· A Comparative Study of Energy Minimization Methods for Markov Random Fields with Smoothness-Based Priors [Project]
十九、运动检测Motion detection:
· Moving Object Extraction, Using Models or Analysis of Regions [Project]
· Background Subtraction: Experiments and Improvements for ViBe [Project]
· A Self-Organizing Approach to Background Subtraction for Visual Surveillance Applications [Project]
· changedetection.net: A new change detection benchmark dataset[Project]
· ViBe - a powerful technique for background detection and subtraction in video sequences[Project]
· Background Subtraction Program[Project]
· Motion Detection Algorithms[Project]
· Stuttgart Artificial Background Subtraction Dataset[Project]
· Object Detection, Motion Estimation, and Tracking[Project]
Deep Learning源代码收集-持续更新…
zouxy09@qq.com
http://blog.csdn.net/zouxy09
收集了一些Deep Learning的源代码。主要是Matlab和C++的,当然也有python的。放在这里,后续遇到新的会持续更新。下表没有的也欢迎大家提供,以便大家使用和交流。谢谢。
最近一次更新:2013-9-22
Theano
http://deeplearning.net/software/theano/
code from: http://deeplearning.net/
Deep Learning Tutorial notes and code
https://github.com/lisa-lab/DeepLearningTutorials
code from: lisa-lab
A Matlab toolbox for Deep Learning
https://github.com/rasmusbergpalm/DeepLearnToolbox
code from: RasmusBerg Palm
deepmat
Matlab Code for Restricted/Deep BoltzmannMachines and Autoencoder
https://github.com/kyunghyuncho/deepmat
code from: KyungHyun Cho http://users.ics.aalto.fi/kcho/
Training a deep autoencoder or a classifieron MNIST digits
http://www.cs.toronto.edu/~hinton/MatlabForSciencePaper.html
code from: Ruslan Salakhutdinov and GeoffHinton
CNN - Convolutional neural network class
http://www.mathworks.cn/matlabcentral/fileexchange/24291
Code from: matlab
Neural Network for Recognition ofHandwritten Digits (CNN)
http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi
cuda-convnet
A fast C++/CUDA implementation ofconvolutional neural networks
http://code.google.com/p/cuda-convnet/
matrbm
a small library that can train RestrictedBoltzmann Machines, and also Deep Belief Networks of stacked RBM's.
http://code.google.com/p/matrbm/
code from: Andrej Karpathy
Exercise from UFLDL Tutorial:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
and tornadomeet’s bolg: http://www.cnblogs.com/tornadomeet/tag/Deep%20Learning/
and https://github.com/dkyang/UFLDL-Tutorial-Exercise
Conditional Restricted Boltzmann Machines
http://www.cs.nyu.edu/~gwtaylor/publications/nips2006mhmublv/code.html
from Graham Taylor http://www.cs.nyu.edu/~gwtaylor/
Factored Conditional Restricted BoltzmannMachines
http://www.cs.nyu.edu/~gwtaylor/publications/icml2009/code/index.html
from Graham Taylor http://www.cs.nyu.edu/~gwtaylor/
Marginalized Stacked Denoising Autoencodersfor Domain Adaptation
http://www1.cse.wustl.edu/~mchen/code/mSDA.tar
code from: http://www.cse.wustl.edu/~kilian/code/code.html
Tiled Convolutional Neural Networks
http://cs.stanford.edu/~quocle/TCNNweb/pretraining.tar.gz
http://cs.stanford.edu/~pangwei/projects.html
tiny-cnn:
A C++11 implementation of convolutionalneural networks
https://github.com/nyanp/tiny-cnn
myCNN
https://github.com/aurofable/18551_Project/tree/master/server/2009-09-30-14-33-myCNN-0.07
Adaptive Deconvolutional Network Toolbox
http://www.matthewzeiler.com/software/DeconvNetToolbox2/DeconvNetToolbox.zip
http://www.matthewzeiler.com/
Deep Learning手写字符识别C++代码
http://download.csdn.net/detail/lucky_greenegg/5413211
from: http://blog.csdn.net/lucky_greenegg/article/details/8949578
convolutionalRBM.m
A MATLAB / MEX / CUDA-MEX implementation ofConvolutional Restricted Boltzmann Machines.
https://github.com/qipeng/convolutionalRBM.m
from: http://qipeng.me/software/convolutional-rbm.html
rbm-mnist
C++ 11 implementation of Geoff Hinton'sDeep Learning matlab code
https://github.com/jdeng/rbm-mnist
Learning Deep Boltzmann Machines
http://web.mit.edu/~rsalakhu/www/code_DBM/code_DBM.tar
http://web.mit.edu/~rsalakhu/www/DBM.html
Code provided by Ruslan Salakhutdinov
Efficient sparse coding algorithms
http://web.eecs.umich.edu/~honglak/softwares/fast_sc.tgz
http://web.eecs.umich.edu/~honglak/softwares/nips06-sparsecoding.htm
Linear Spatial Pyramid Matching UsingSparse Coding for Image Classification
http://www.ifp.illinois.edu/~jyang29/codes/CVPR09-ScSPM.rar
http://www.ifp.illinois.edu/~jyang29/ScSPM.htm
SPAMS
(SPArse Modeling Software) is anoptimization toolbox for solving various sparse estimation problems.
http://spams-devel.gforge.inria.fr/
sparsenet
Sparse coding simulation software
http://redwood.berkeley.edu/bruno/sparsenet/
fast dropout training
https://github.com/sidaw/fastdropout
http://nlp.stanford.edu/~sidaw/home/start
Deep Learning of Invariant Features viaSimulated Fixations in Video
http://ai.stanford.edu/~wzou/deepslow_release.tar.gz
http://ai.stanford.edu/~wzou/
Sparse filtering
http://cs.stanford.edu/~jngiam/papers/NgiamKohChenBhaskarNg2011_Supplementary.pdf
k-means
http://www.stanford.edu/~acoates/papers/kmeans_demo.tgz
others:
http://deeplearning.net/software_links/
Deep Learning(深度学习)学习笔记整理系列相关推荐
- Deep Learning(深度学习)学习笔记整理系列之(五)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(二)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(八)
Deep Learning(深度学习)学习笔记整理系列之(八) 分类: Deep Learning 机器学习 Linux驱动2013-04-10 11:4257652人阅读评论(25)收藏举报 ...
- Deep Learning(深度学习)学习笔记整理系列三
Deep Learning(深度学习)学习笔记整理系列 声明: 1)该Deep Learning的学习系列是整理自网上很大牛和机器学习专家所无私奉献的资料的.具体引用的资料请看参考文献.具体的版本声明 ...
- Deep Learning(深度学习)学习笔记整理系列之常用模型
Deep Learning(深度学习)学习笔记整理系列之常用模型(四.五.六.七) 九.Deep Learning的常用模型或者方法 9.1.AutoEncoder自动编码器 Deep Learnin ...
- Deep Learning(深度学习)学习笔记整理系列之(七)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- 【转载】Deep Learning(深度学习)学习笔记整理系列
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-0 ...
- Deep Learning(深度学习)学习笔记整理系列之(三)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(一)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-0 ...
- Deep Learning(深度学习)学习笔记整理系列 | @Get社区
Deep Learning(深度学习)学习笔记整理系列 | @Get社区 Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net ...
最新文章
- ajax 的理论以及需要的常用参数
- 修改class文件_VM实战(六) - 通过案例深入学习class文件结构原理
- 《JavaScript语言精髓与编程实践》读书笔记二
- 农民思考互联网时代农民的未来
- Java EE 7 / JAX-RS 2.0 – REST上的CORS
- vue中使用cookies和crypto-js实现记住密码和加密
- 蓝桥杯 基础练习 回文数
- ACM之八数码问题----BFS搜索----数独游戏的模拟(下)
- ubuntu以安装包方式安装jdk13
- JS获取IP、MAC和主机名的五种方法
- windows系统搭建图像识别开发环境
- Devcpp使用技巧
- html文本框隐藏按钮,隐藏input输入框的增减按钮
- python 爬取12306验证码
- PeopleSoft
- OS学习笔记-17(清华大学慕课)进程的同步和互斥
- FI---SAP汇率损益处理方法
- MPEG4 笔记2(FTYP,MOOV,MVHD)
- 【已解决】error: ‘xxx’ is not a member of ‘xxx’
- 一分钟了解“查期刊的SCI分区”