华中科大提出EAT-NAS方法:提升大规模神经模型搜索速度
神经模型搜索(Neural Architecture Search,NAS)是一种自动化的模型结构搜索方法,旨在代替深度学习专家选择最优的网络模型结构。传统的NAS方法都是针对小规模数据库设计的,直接迁移到大型数据库上无法保证模型的预测效果。针对这一缺陷,华中科大与地平线合作提出了一种针对大规模NAS问题的弹性结构迁移方法EAT-NAS,该方法大大加快了在如ImageNet这种大型数据库上的搜索进程。与现有的大规模NAS方法相比,EAT-NAS在八块Titan X配置的机器上仅需要5天就可以完成整个搜索过程,显著减少了搜索时间,并且得到的最优模型仍具有较高的准确度。我们对该方法做了简要介绍,本文是AI前线第67篇论文导读。
背景
由人类专家设计神经网络架构,通常需要繁琐的实验过程还容易出现错误。为了让这个过程更加高效化,许多神经结构搜索方法(Neural Architecture Methods,NAS)被提出。先不说结果如何,大部分NAS方法都需要非常昂贵的计算资源。例如2017年ICLR的论文《Neural architecture search with reinforcement learning》使用了800块GPU在CIFAR-10图像分类任务上花费了28天的时间进行搜索。CIFAR-10只是一个非常小规模的数据库,而实际应用的情景往往都是大规模的数据,因此NAS方法在大规模数据库上的局限性成为了阻碍其发展的关键因素。
许多现有的NAS方法通过在小规模数据库上进行结构搜索,然后针对大规模数据库对深度和宽度进行手动调整。这一机制广泛的应用于NAS领域。但是由于大规模数据库与小规模数据库之间域的不同,在小规模数据库上的模型搜索算法应用于大规模数据库时,并不能保证其效果。
在这篇论文中,作者针上述的限制,提出了一种更合理的解决方案。作者使用迁移学习的方法从将针对小规模任务的结构应用到大规模任务上并进行微调。更详细地,作者使用了基于弹性框架的NAS方法——联赛选择,即首先使用现有的方法在小数据库上搜索神经框架,然后将上一步得到的框架作为初始化种子再在大型数据库上进行搜索。
总得来说,这篇文章的亮点主要可概括为:
提出一种弹性结构迁移机制(Elastic Architecture Transfer Machanism)用来弥补大规模任务和小型任务上进行结构搜索的差异。
由于使用了小规模数据库上的最优模型作为大型任务的初始化种子,该方法有效节省了在大规模数据库上进行模型搜索的时间。
在节省了计算资源的情况下,最终的模型仍然能达到不错的性能。
相关方法
本文提出的EAT-NAS方法,是在基于进化算法(Evolutionary Algorithm,EA)的NAS方法上进行改进的。进化算法在NAS领域的应用非常广泛,其详细算法如下表所示:

该算法首先在搜索空间中使用随机生成的P模型对种群进行初始化,随后将每个模型在数据库上进行训练和评估以获得模型的准确率。在每个进化周期里,S是从种群中随机采样的模型。其中分数最高的模型M_best和分数最低的模型M_worst会被选出进行下一步处理。对M_best添加一些变换即可得到变异的模型,变异的模型会被添加到种群中进行训练、评价,同时M_worst会被移除。上述的搜索进程便被称为联赛选择算法。最终,再对前k个效果最好的模型进行重训练,选择其中最好的模型即可完成整个搜索过程。
本文算法
在将模型结构用于大规模数据库时,许多NAS方法只不过是依赖人类专家的先验知识,手动地修改模型的宽度和深度。与这些方法不同,EAT-NAS对基本模型结构的各个元素进行微调得到最终可以适应大规模数据库的模型,这些元素包括结构、尺度、操作等。通过使用在小规模数据库上搜索得到的基本模型,EAT算法可以有效地加速大规模任务上模型的搜索进程。
1 算法框架
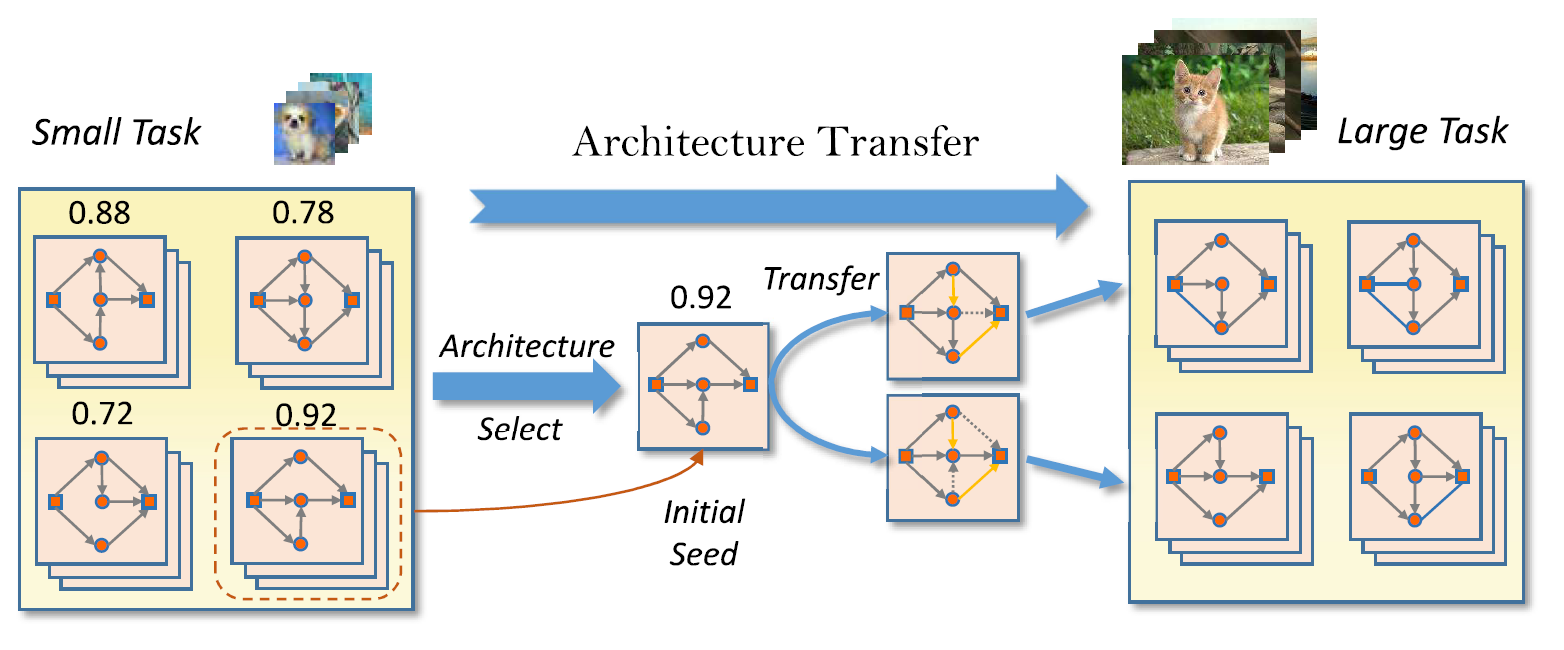
图 1 弹性结构迁移算法框架
EAT-NAS的基本思想如上图所示,首先使用进化算法在小型任务上搜索最优模型,然后将其作为第二阶段的初始化种子,再使用进化算法对大规模任务进行搜索。由于使用了小任务上的最佳模型对大任务的初始种群做初始化,在大规模任务上的搜索进程明显会比从零开始的收敛速度快得多。作者使用了种群质量判别函数(Population Quality)以便在进化过程中对模型种群做出更好的评价。此外,作者在第二阶段使用了后代结构生成器(offspring architecture generator)来产生新的结构。为了同时对模型的准确度和尺寸进行优化,作者使用了Pareto优化进行求解,Pareto优化是多目标优化问题中一种求最优解集的方法。
2 搜索空间
对于结构搜索来说,确定一个好的搜索空间是非常必要的。作者使用了MobileNetV2作为骨架网络,整个网络的结构如下图所示:
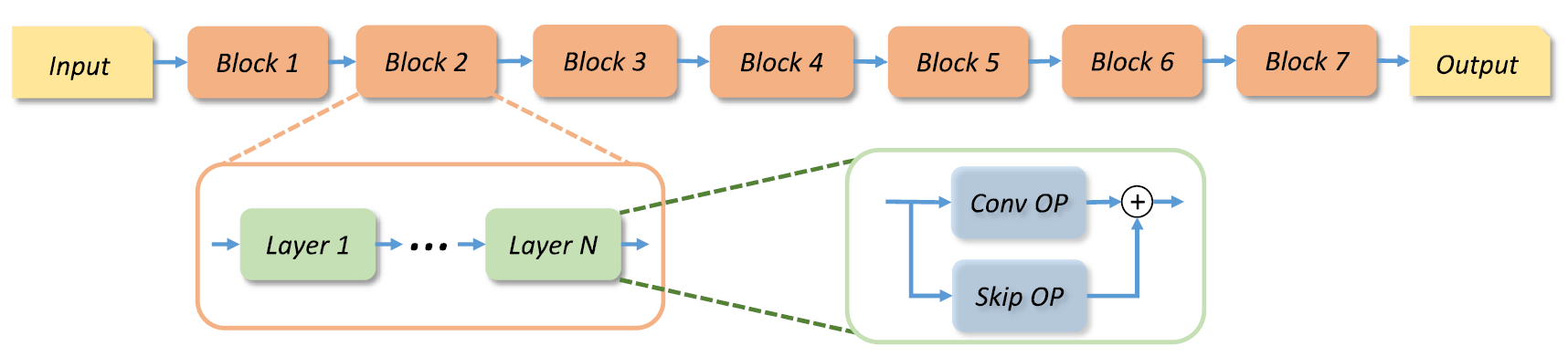
图 2 基于MobileNetV2的骨干网络结构
网络被分为了多个block,每个block的结构彼此不同,它们各自包含了多个层,每个层表示一种在当前block中进行的多次的操作。对于每个block,作者给出了更详细的选择条件:
卷积操作:深度可分离卷积(SepConv)、膨胀率为{3,6}的移动反转瓶颈卷积(MBConv)。
卷积核大小:3X3,5X5,7X7
跳跃连接:每层之间是否添加跳跃连接。
宽度因子:输出相对于输入的宽度扩张比率[0.5, 1.0, 1.5, 2.0]
深度因子:每个block包含的层数[1, 2, 3, 4]
其中,每个block的第一层默认丢弃降采样和宽度扩张操作。
作者在搜索空间中使用了编码的方式表示网络结构,以便对神经结构进行操作。整个网络可以使用一个block集合来表示:
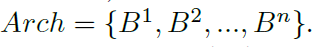
每个block包含了上述的五个元素,因此使用一个元组对其进行表示:
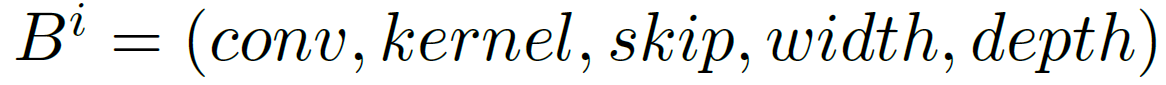
所有对网络结构进行的操作都通过改变编码的形式进行。
3 种群质量
在训练过程中,仅根据模型预测的精确度不足以判断其是否收敛。尤其是在搜索空间中,参数是共享的,这就更加难以判断精度的提高是由于参数共享还是由于更好的模型性能。因此作者提出了一种自定义的函数近似地评估模型种群质量:
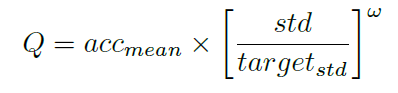
其中,acc_mean表示种群中模型的平均精确度,std表示模型精度的标准差,w是由超参数进行控制的权重因子:
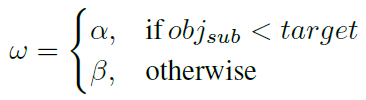
4 规模搜索
许多NAS方法都会基于先验知识,将模型的规模设为一个固定值。EAT-NAS则在深度和宽度层面上,都对模型的结构进行了搜索。为了加速搜索的过程,作者使用了两种不同的方法分别在深度和宽度层面进行参数共享。
- 宽度层面的共享算法如下表所示,除了共享的参数以外,K_l的其余参数均使用随机初始化。

- 深度层面的共享方法如下所示,其中U和W分别是含有l_u层的两个相关的block的参数,这里使用W的参数对U进行共享。
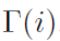 是一个服从正态分布的参数随机初始化函数。
是一个服从正态分布的参数随机初始化函数。
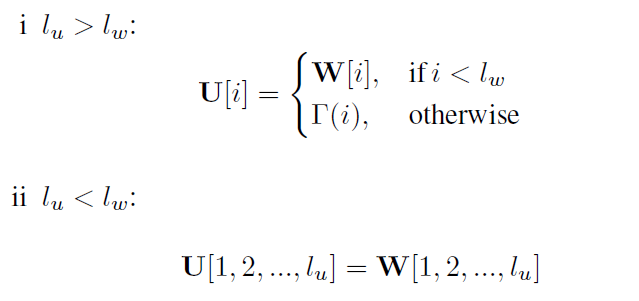
5 后代结构生成器
在完成了基础模型结构的搜索后,需要将基本结构迁移到大规模任务上。作者使用了后代结构生成器(Offspring Architecture Generator,OAG)从模型种群中生成新的模型种群,OAG会将基础模型作为新种群的初始化种子。同时,作者还定义了一个新的变换函数,通过添加一些扰动,使得输入框架可以更加轻量并同质化。算法3是该变换函数的详细过程:

在使用后代结构生成器产生新的种群后,再使用算法1中的进化算法进行最优化搜索,最终即可得到适用于大规模任务的模型结构。
实验结果
在CIFAR-10数据库上进行搜索
在CIFAR-10上的实验可以分为两步:结构搜索和结构进化。CIFAR-10包含5w张训练图像和1w张测试图像。作者对原始训练集进行2/8划分,分别作为验证集和训练集。CIFAR-10的测试集仅用来在完成最后的模型搜索后进行测试。实验过程中使用了标准的预处理和数据增强步骤。所有的图像都使用了通道均值与标准差进行白化。训练过程的详细参数可以参阅论文。
作者最终选择了前8个训练好的模型进行重训练,挑选其中精确度最高的作为基本结构。最终基本结构达到了96.42%的平均测试精度,模型参数大小仅为2.04M,平均精度的标准差为0.05。
迁移到ImageNet数据库
这里使用了上一步得到的基础模型作为ImageNet任务的种子来生成新的模型。搜索进程在整个ImageNet数据库上进行。作者使用OAG在基本结构的基础上产生了64个新的结构。CIFAR-10上得到的基本结构和迁移到ImageNet上网络结构如下图所示:
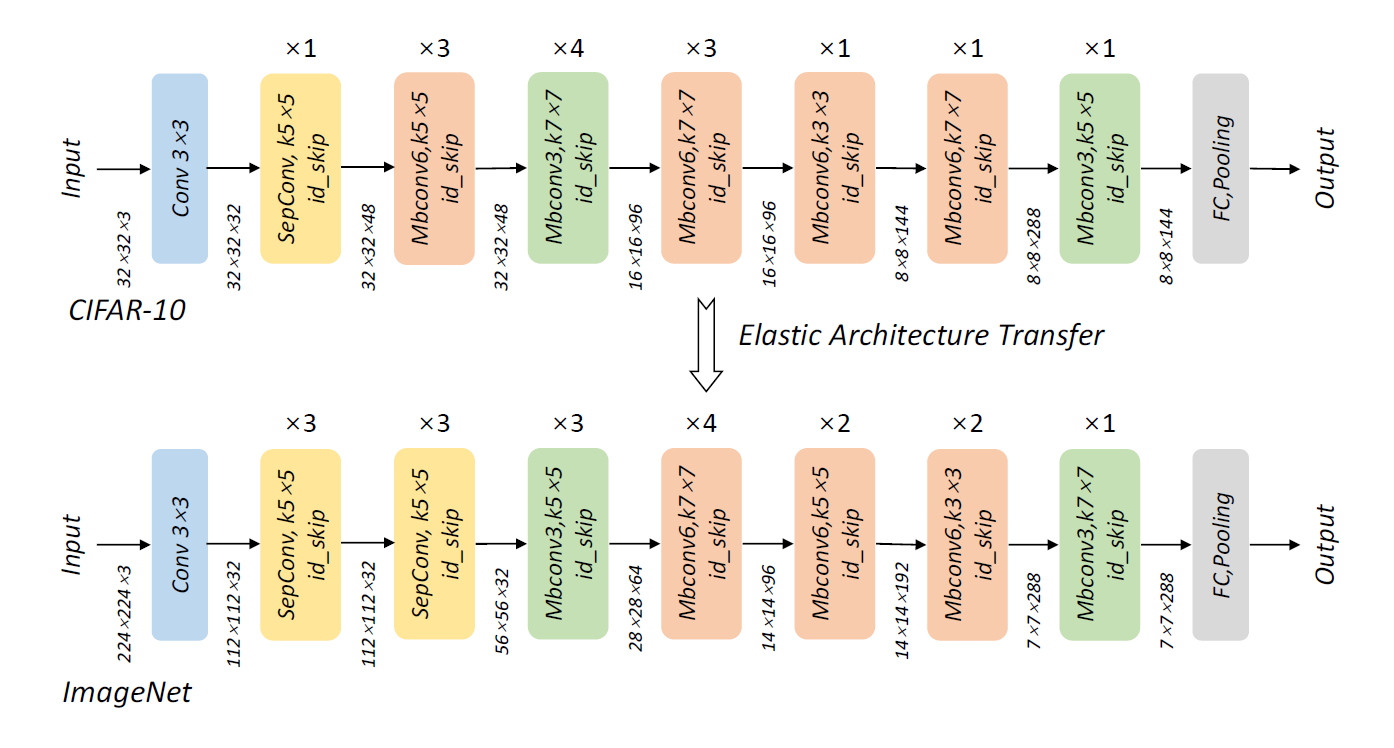
图 3 基本网络框架与经过弹性迁移后的框架
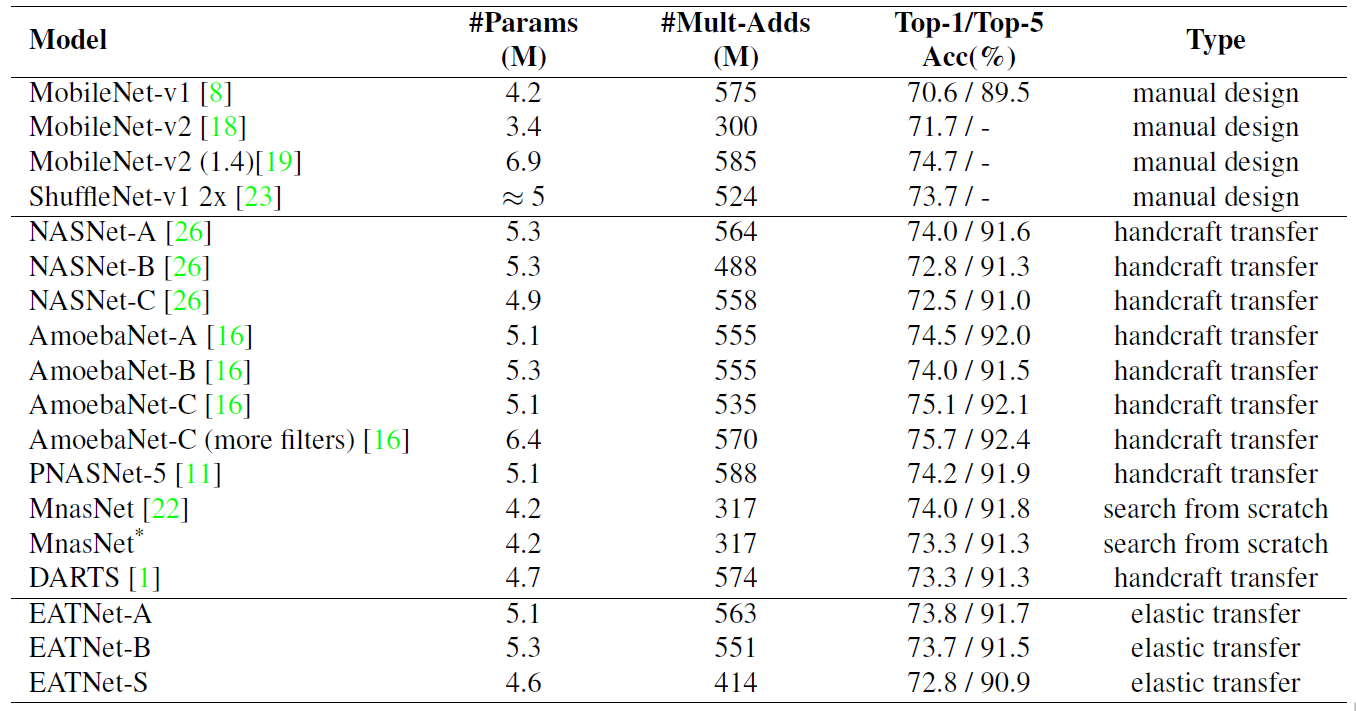
在ImageNet数据库上,整个进化过程经过100次突变循环即达到了收敛。也就是说,在基本模型的基础上,算上最开始的64个模型,仅采样了164个模型即找到了最优模型。而在类似的MnasNet中则需要采样约8k个模型才可达到最优,是EAT-NAS的50倍。最终的模型精度如下表所示,EATNet表示本文提出方法得到的模型。
总结
总的来说,EAT-NAS算法使用了一种很巧妙的设计,将模型在小规模数据库上学习到的信息用于大规模数据库上的模型搜索。作者将迁移学习的思想与进化算法相结合,在基本没有损失模型性能的基础上,极大地加速了整个优化进程。
论文原文链接:
EAT-NAS: Elastic Architecture Transfer for Accelerating Large-scale Neural Architecture Search
华中科大提出EAT-NAS方法:提升大规模神经模型搜索速度相关推荐
- 【AI周报】首款高容错通用量子计算机原型登上Nature;SIGIR 2022 | 快手联合武汉大学提出序列推荐的多粒度神经模型
01 # 行业大事件 首款高容错通用量子计算机原型登上Nature 理论上,量子计算机可以解决常规计算机在宇宙生命周期时间内也无法解决的问题.然而,我们需要大量的工程和技术才能将其「理论上」的能力兑现 ...
- ICCV 2021 | 腾讯、华中科大提出QueryInst,开启基于Query的实例分割新思路
©作者 | 机器之心编辑部 来源 | 机器之心 实例分割(Instance Segmentation)任务有着广阔的应用和发展前景.来自腾讯 PCG 应用研究中心 (ARC) 和华中科技大学的研究者们 ...
- win11如何加快搜索速度 Windows11更改文件索引加快搜索速度的设置方法
有时候当你急需寻找一份文件的时候,可能查找筛选需要很长时间,但是有什么方法可以加快寻找文件的搜索速度呢?今天小编就为大家带来更改文件索引加快搜索速度的教程.更多Windows11安装步骤可以参考小白一 ...
- 不用亲手搭建型了!华人博士提出few-shot NAS,效率提升10倍
[导读]你能找到最优的深度学习模型吗?还是说你会「堆积木」?最近,伍斯特理工学院华人博士在ICML 2021上发表了一篇文章,提出一个新模型few-shot NAS,效率提升10倍,准确率提升20%! ...
- Self-Attention真的是必要的吗?微软中科大提出Sparse MLP,降低计算量的同时提升性能!...
关注公众号,发现CV技术之美 ▊ 写在前面 Transformer由于其强大的建模能力,目前在计算机视觉领域占据了重要的地位.在这项工作中,作者探究了Transformer的自注意(Self-Atte ...
- ICCV 2019 | 厦大提出快速NAS检索方法,四小时搜索NN结构
点击我爱计算机视觉标星,更快获取CVML新技术 机器之心专栏 作者:郑侠武 ICCV 2019 将于 10.27-11.2 在韩国首尔召开,本次会议总共接受 1077 篇,总提交 4303 篇,接收率 ...
- 应用在大规模推荐系统,Facebook提出组合embedding方法 | KDD 2020
来源 | 深度传送门(ID: deep_deliver) Facebook团队考虑embedding的存储瓶颈,提出了一种新颖的方法,通过利用类别集合的互补分区为每个类别生成唯一的embedding向 ...
- 智慧校园怎么建?华中科大用“数”说话
智慧校园建设的一小步,可能是社会未来发展的一大步. 作为城市中重要的组成单元,高校看似不起眼,却犹如一个功能齐全的小型社会,承载着教学.科研等重要工作,其智慧校园的建设虽不像智慧城市那样宏伟和庞大,但 ...
- 旷视提出AutoML新方法,在ImageNet取得新突破 | 技术头条
点击上方↑↑↑蓝字关注我们~ 「2019 Python开发者日」,购票请扫码咨询 ↑↑↑ 来源 | 旷视研究院 近日,来自旷视研究院的郭梓超.张祥雨.穆皓远.孙剑等人发表一篇新论文"Sing ...
最新文章
- 快速构建Spring Cloud工程
- 你还在new对象吗?Java8通用Builder了解一下?
- java SAX 防xml注入,如何防止XML注入像XML Bomb和XXE攻击
- centos /dev/mapper/cl-root 100% 解决方法
- servlet、genericservlet、httpservlet之间的区别
- 服务中添加mysql服务_Windows平台下在服务中添加MySQL
- 微服务架构和SOA的区别
- Startup Error: Unable to detect graphics environment
- mybatis 依赖于jdbc_第1章 MyBatis快速入门
- [arduino]-序言:面向仅有C语言基础之人的单片机开发板
- 6.爬虫 requests库讲解 总结
- 从零基础入门Tensorflow2.0 ----三、9.tf.function
- VMThread占CPU高基本上是JVM在频繁GC导致,原因基本上是冰法下短时间内创建了大量对象堆积造成频繁GC。...
- typecast java_Delphi设置无效的Typecast
- 图像检索与识别(Bag-Of-Words Models)
- android手机内存不足使用sd卡,解决红米内存不足(内置SD卡与外置SD卡互换)
- Pt100铂电阻测温电路设计——
- 百度谷歌搜索引擎研究,如何做SEO优化?网站优化实操(程序员必看)
- 【泛函分析】巴拿赫空间
- 基于AMSR-E和AMSR2数据的全球长时序日尺度土壤水分数据集(2002-2022)