TensorFlow人工智能引擎入门教程之二 CNN卷积神经网络的基本定义理解。
首先 上面讲了神经元 Y=WX+B ,通过输入的参数X ===========》Y 深度学习 每一个batch来说 其实就是 多项公式

我们知道 在数学里面 求多项公式 其实 就是 矩阵 W 矩阵 乘与 X 加上 B 矩阵 = Y矩阵 ,矩阵 二元数组在tensorflow 也是一个tensor ndarray , 通常 我们知道 因为relu 收敛效果要比sigmod 与tanh 要好,所以在cnn中常用relu,所以 其实 对于输出o=relu(wx+b) ,
1.TensorFlow卷积
比如 下面 是tensorflow卷积定义 relu(W*X+B) W 矩阵 * X矩阵 + B矩阵 = W 权重variable变量 * X (placeholder占位符外部输入)variable变量 + B偏重变量,因为深度学习 会自动 不断地计算loss损失 BP 来调整 w b 所以 w b初始化 可以随便 全部都是0 都行 ,所以 其实 就是 X 以及 Y 对于 X来说其实我们知道 就是 我们图像数据 Y 是图像的标签,但是Y需要转为数学可以计算的值,所以采用one-hot 数组记录 标签的索引就行,比如 xx1 xx2 xx3 相应的y1=[1,0,0] y2=[0 1 0] y3=[0 0 1]
那么 其实 就是 X 图像的像素 通过外部输入 placeholder占位符 Y值 外部输入 通过 placeholder占位符
我们知道 W*X 矩阵 相乘 必须 符合 MXN NXM =MXM 也就是说W的 列 必须 与 X的行数目相同 这是要注意的,所以上一张shape来规范维度计算 ,下面是一个卷积层 定义 relu(wx+b) 下面是tensorflow来表示relu(wx+b)的公式
其中要注意参数 strides 是卷积滑动的步长 你可以配置更多的系数,
def conv2d(x, w, b):return tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME'),b))
上面我们理解了, 其实就是 W矩阵 * X矩阵 +B 矩阵 =Y矩阵
Y矩阵 好算 ,W矩阵 +B矩阵 已知 可以随意后面要bp调整。那么X矩阵 是图像 也就是说输入的X
x = tf.placeholder(tf.float32, [None, w*h]) #w*h 因为批次训练 数据可以任意所以第一个是None ,第二个图像是个w * h的图像 ,可以展开得到 w * h 的数组我们知道 卷积运算 其实是卷积的个数 M 展开的卷积核长宽维度 K * 卷积能够提取的数目 K * 提取图像的维度N =MXN
也就说可以通过 卷积核 让图像 W*H 转变成 一个 卷积的个数 的行 ,N 为提取图像卷积特征的每一行数据的的矩阵
还是遵循WX+B
我们定义好W
我们可以把整个网络看成wx+b 忽略掉那些relu 等等 其实 就是一个y=wx+b 我们知道输入 是上面的
x = tf.placeholder(tf.float32, [None, w*h])
y = tf.placeholder(tf.float32, [None, ysize])#y的数目个数 比如3个类 就是3那么 一个x 需 要 * W = y 计入batch为50 y为10 那么[50,224*224] * W= [50 ,10]
那么W 需要是一个[224*224,10] 的矩阵 ,也就是说 至少224*224*10*50 个连接

下面继续 讲X [None ,w*h] 对于每一个 w*h 是一个矩阵 每一层的w 也是一个矩阵 每一层的 b也是一个矩阵 ,每一层的输出y1 也是一个矩阵 y=[w*h]*w+b 为了减少系数,我们使用卷积,把它转换成MXN的值 ,这里就是跟全连接层的不同,使用了卷积转换成了一个MXN的卷积特征 而全连接层就是 y=wx+b (这里省略了那些relu(wx+b) tanh(wx+b))
所以我们现在来看看每一层的w 定义
因为卷积层的w是需要 与 w*h 提取的MXK来做矩阵相乘 所以 他是跟卷积核相关 以及 输入 输出 相关,对于每一张图像
输入为1 输出分解为多个输出用于 第二层运算
wc=tf.Variable(tf.random_normal([3, 3, 1, 64]) #3 3 分别为3x3大小的卷积核 1位输入数目 因为是第一层所以是1 输出我们配置的64
所以我们知道了 如果下一次卷积wc2=[5,5,64,256] //5x5 是我们配置的卷积核大小,第三位表示输入数目 我们通过上面知道 上面的输出 也就是下一层的输入 所以 就是64 了输出我们定义成256 这个随你喜好,关键要迭代看效果,一般都是某一个v*v的值这样我们知道了 wc*(卷积得到的x) + b =y1下一层输入,我们也能知道 一下层输入 mxnxo 分别为输出O个卷积核特征MXN 我们也能知道b 大小 那个肯定跟O一样,比如上面是64输出,所以
b1=tf.Variable(tf.random_normal([64]))
同样可以知道b2=[256]下面我们讲一讲池化层pool 池化层 不会减少输出,只会把MXNXO ,把卷积提取的特征 做进一步卷积 取MAX AVG MIN等 用局部代替整理进一步缩小特征值大小
下面是一个用kxk 的核做maxpooling的定义
def max_pool_kxk(x):return tf.nn.max_pool(x, ksize=[1, k, k, 1],strides=[1, k, k, 1], padding='SAME')这样我们可以定义一个简单的CNN了
c1 = tf.nn.relu(tf.nn.conv2d(X, w, [1, 1, 1, 1], 'SAME'))m1 = tf.nn.max_pool(l1a, ksize=[1, k, k, 1],strides=[1, k, k, 1], padding='SAME')d1 = tf.nn.dropout(l1, p_keep_conv)c2 = tf.nn.relu(tf.nn.conv2d(l1, w2, [1, 1, 1, 1], 'SAME'))m2 = tf.nn.max_pool(l2a, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')d2= tf.nn.dropout(l2, p_keep_conv)c3 = tf.nn.relu(tf.nn.conv2d(l2, w3, [1, 1, 1, 1], 'SAME'))m3 = tf.nn.max_pool(l3a, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')d3 = tf.nn.dropout(tf.reshape(l3, [-1, w4.get_shape().as_list()[0]]), p_keep_conv)#d3表示倒数第二层的输出 也就是倒数第一层一层的输入x 我们代入 y=wx+b 也就是w*x=w4*d3+b y = tf.nn.bias_add(tf.matmul(d3, w4),b4))#matmul 顾名思义mat矩阵mul相乘 matmul w*x上面的用图表示就是 X,Y ========>conv1======>relu======>drop梯度下降=======》conv2===>relu2===drop2====>conv3====>relu======>drop===full全连接 (y=wx+b)
官方给了 一个example 关于alexnet的 我贴一下代码 ,大家只要理解了上面讲的内容 就可以知道怎么稍微修改 就可以自己定义一个 CNN网络了
http://www.tensorfly.cn/tfdoc/tutorials/deep_cnn.html
http://www.tensorfly.cn/tfdoc/tutorials/mnist_pros.html
大家可以去执行一下,这个我执行多次了,下一章DNN ,DNN 就是CNN去掉卷积层 ,的深度学习网络 通过全连接层 梯度下降层构成的的DNN网络
大家有疑问就是后面训练完了怎么使用,其实训练完了 保存每一层的w b参数 起来就是一个网络模型model 然后使用model进行预测 分类了,这个后面要讲怎么保存并使用model
不知道怎么上传附件。麻烦 懒得放外联了 。其中input_data模块
地址为 https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/mnist/input_data.py
import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)import tensorflow as tf# Parameters
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units# tf Graph input
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32) #dropout (keep probability)# Create model
def conv2d(img, w, b):return tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(img, w, strides=[1, 1, 1, 1], padding='SAME'),b))def max_pool(img, k):return tf.nn.max_pool(img, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME')def conv_net(_X, _weights, _biases, _dropout):# Reshape input picture_X = tf.reshape(_X, shape=[-1, 28, 28, 1])# Convolution Layerconv1 = conv2d(_X, _weights['wc1'], _biases['bc1'])# Max Pooling (down-sampling)conv1 = max_pool(conv1, k=2)# Apply Dropoutconv1 = tf.nn.dropout(conv1, _dropout)# Convolution Layerconv2 = conv2d(conv1, _weights['wc2'], _biases['bc2'])# Max Pooling (down-sampling)conv2 = max_pool(conv2, k=2)# Apply Dropoutconv2 = tf.nn.dropout(conv2, _dropout)# Fully connected layerdense1 = tf.reshape(conv2, [-1, _weights['wd1'].get_shape().as_list()[0]]) # Reshape conv2 output to fit dense layer inputdense1 = tf.nn.relu(tf.add(tf.matmul(dense1, _weights['wd1']), _biases['bd1'])) # Relu activationdense1 = tf.nn.dropout(dense1, _dropout) # Apply Dropout# Output, class predictionout = tf.add(tf.matmul(dense1, _weights['out']), _biases['out'])return out# Store layers weight & bias
weights = {'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])), # 5x5 conv, 1 input, 32 outputs'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])), # 5x5 conv, 32 inputs, 64 outputs'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])), # fully connected, 7*7*64 inputs, 1024 outputs'out': tf.Variable(tf.random_normal([1024, n_classes])) # 1024 inputs, 10 outputs (class prediction)
}biases = {'bc1': tf.Variable(tf.random_normal([32])),'bc2': tf.Variable(tf.random_normal([64])),'bd1': tf.Variable(tf.random_normal([1024])),'out': tf.Variable(tf.random_normal([n_classes]))
}# Construct model
pred = conv_net(x, weights, biases, keep_prob)# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))# Initializing the variables
init = tf.initialize_all_variables()# Launch the graph
with tf.Session() as sess:sess.run(init)step = 1# Keep training until reach max iterationswhile step * batch_size < training_iters:batch_xs, batch_ys = mnist.train.next_batch(batch_size)# Fit training using batch datasess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys, keep_prob: dropout})if step % display_step == 0:# Calculate batch accuracyacc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})# Calculate batch lossloss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc)step += 1print "Optimization Finished!"# Calculate accuracy for 256 mnist test imagesprint "Testing Accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images[:256], y: mnist.test.labels[:256], keep_prob: 1.})运行截图========== accuracy为精度 loss为损失函数,有多种计算方式 这里是 交叉熵” 。下面看到 accuracy第三次为0.40625 通过多次迭代后 不断的提高,运行多次 最后保存精度最高的那个为模型就好了,这里因为alexnet本来就是一个很简单的模型,所以精度也不怎么高。 我服务器是1核1G的CPU服务器所以很慢。懒得等他运行完了




精度 在 增加。。。
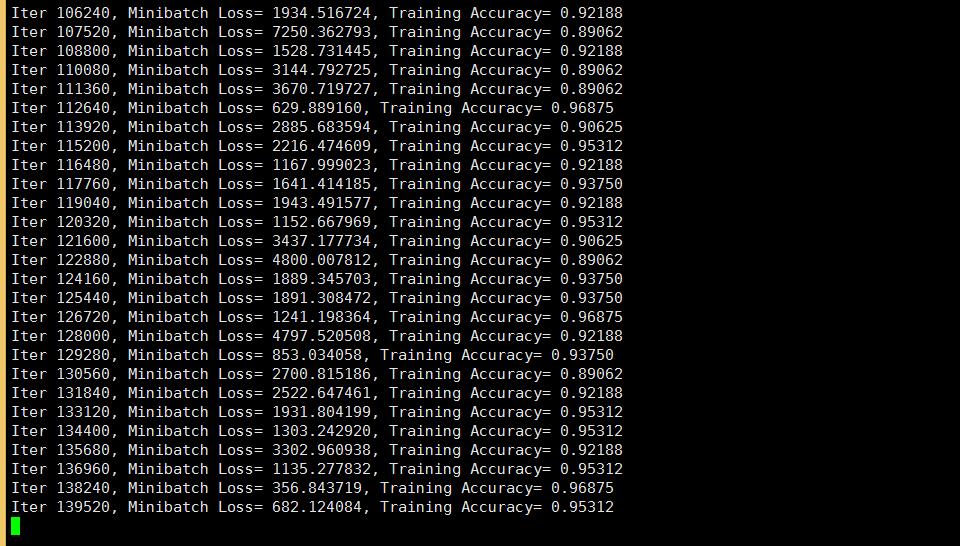
好像最后是99。2% 精确度 情况 ,手写识别 0-9 这里有98.4%了

好吧。这次运行 精度大概97.6左右 下一章节 我修改一下系数以及 加几层层网络试试效果 ,

TensorFlow人工智能引擎入门教程之二 CNN卷积神经网络的基本定义理解。相关推荐
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
摘要: 这一章节我们讲一下 RSNN深度残差网络 ,他准确率非常好,比CNN还要高.而且非常新 出现在2015 residual network http://blog.csdn.net/sunbai ...
- 无人驾驶汽车系统入门(十二)——卷积神经网络入门,基于深度学习的车辆实时检测
无人驾驶汽车系统入门(十二)--卷积神经网络入门,基于深度学习的车辆实时检测 上篇文章我们讲到能否尽可能利用上图像的二维特征来设计神经网络,以此来进一步提高识别的精度.在这篇博客中,我们学习一类专门用 ...
- 基于tensorflow、keras利用emnist数据集构建CNN卷积神经网络进行手写字母识别
EMNIST 数据集是一个包含手写字母,数字的数据集,它具有和MNIST相同的数据格式.The EMNIST Dataset | NIST 引用模块介绍: import tensorflow as t ...
- 【AI机器学习入门与实战】CNN卷积神经网络识别图片验证码案例
- python神经网络案例——CNN卷积神经网络实现mnist手写体识别
分享一个朋友的人工智能教程.零基础!通俗易懂!风趣幽默!还带黄段子!大家可以看看是否对自己有帮助:点击打开 全栈工程师开发手册 (作者:栾鹏) python教程全解 CNN卷积神经网络的理论教程参考 ...
- 日撸 Java 三百行(81-90天,CNN 卷积神经网络)
目录 总述 01-10天,基本语法 11-20天,线性数据结构 21-30天,树与二叉树 31-40天,图 41-50天,查找与排序 51-60天,kNN 与 NB 61-70天,决策树与集成学习 7 ...
- Node.js 官网入门教程(二) npm(安装、包版本、卸载、npx)、package.json(scripts、devDependencies)package-lock.json(语义版本规则符号
Node.js 官网入门教程(二) npm(包管理.安装.包版本.卸载.npx).package.json(scripts.devDependencies).package-lock.json(语义版 ...
- [TensorFlow深度学习入门]实战九·用CNN做科赛网TibetanMNIST藏文手写数字数据集准确率98%+
[TensorFlow深度学习入门]实战九·用CNN做科赛网TibetanMNIST藏文手写数字数据集准确率98.8%+ 我们在博文,使用CNN做Kaggle比赛手写数字识别准确率99%+,在此基础之 ...
- 这可能是最好的RxJava 2.x 入门教程(二)
这可能是最好的 RxJava 2.x 入门教程系列专栏 文章链接: 这可能是最好的 RxJava 2.x 入门教程(完结版)[推荐直接看这个] 这可能是最好的RxJava 2.x 入门教程(一) 这可 ...
最新文章
- 推荐一个生成后端模拟数据的懒人工具:lazy-mock
- Spring Cloud/Dubbo 应用无缝迁移到 Serverless 架构
- 计算机英语心得体会200字,英语读后感200字精选3篇
- Ubuntu14.04引导菜单修复
- junit测试设置不回滚_正确设置JUnit测试名称
- 大学只待成追忆,只是工作已半年,2016再见
- Bookdown平台分享了哪些书籍,如何使用Bookdown分享书籍
- 杭电2540遮挡判断
- 情侣在公交车上接吻遭乘客指责
- Windows 技术篇 - win10开机启动项设置方法,windows启动项里没有的程序设置开机启动方法
- 计算机二级常用口诀,2017计算机二级考试重点
- 产品冷思考:大而全or小而美如何选择?
- 【有感】成为一个不惑、不忧、不惧的人
- 证券基金经营机构信息技术管理办法
- Linuxnbsp;用命令行打开docnbsp;pdf…
- 计算机网络之——非常恶心但友善ip地址、子网掩码、网络地址、构造超网、最小地址和最大地址(理解篇)
- c++中按位取反运算
- HTML(二) -- 表格设计
- C#一元一次算法求解
- Linux(ubuntu)中删除除了一个文件之外的所有文件