使用opencv实现实例分割,一学就会|附源码
无论是从酒店房间接听电话、在办公里楼工作,还是根本不想在家庭办公室等情况,电话会议模糊功能都可以让会议与会者专注于自己,这样的功能对于在家工作并希望保护其家庭成员隐私的人特别有用。
为了实现这样的功能,微软利用计算机视觉、深度学习以及实例分割技术实现。
在之前的博文中,介绍了如何利用YOLO以及OpenCV实现目标检测的功能,今天将采用Mask R-CNN来构建视频模糊功能。
使用OpenCV进行实例分割
https://youtu.be/puSN8Dg-bdI
在本教程的第一部分中,将简要介绍实例分割;之后将使用实例分割和OpenCV来实现:
- 从视频流中检测出用户并分割;
- 模糊背景;
- 将用户添加回流本身;
什么是实例分割?

图1:对象检测和实例分割之间的区别
如上图所示,对于对象检测(左图,Object Detection)而言,在各个对象周围绘制出一个框。 实例分割(右图,Instance Segmentation)而言,是需要尝试确定哪些像素属于对应的对象。通过上图,可以清楚地看到两者之间的差异。
执行对象检测时,是需要:
- 计算每个对象的边界框(x,y的)-坐标;
- 然后将类标签与每个边界框相关联;
从上可以看出,对象检测并没有告诉我们关于对象本身的形状,而只获得了一组边界框坐标。而另一方面,实例分割需要计算出一个逐像素掩模用于图像中的每个对象。
即使对象具有相同的类标签,例如上图中的两只狗,我们的实例分割算法仍然报告总共三个独特的对象:两只狗和一只猫。
使用实例分割,可以更加细致地理解图像中的对象——比如知道对象存在于哪个(x,y)坐标中。此外,通过使用实例分割,可以轻松地从背景中分割前景对象。
本文使用Mask R-CNN进行实例分割。
项目结构
项目树:
$ tree --dirsfirst
.
├── mask-rcnn-coco
│ ├── frozen_inference_graph.pb
│ ├── mask_rcnn_inception_v2_coco_2018_01_28.pbtxt
│ └── object_detection_classes_coco.txt
└── instance_segmentation.py1 directory, 4 files项目包括一个目录(由三个文件组成)和一个Python脚本:
mask-rcnn-coco/:Mask R-CNN模型目录包含三个文件:frozen_inference_graph .pb:Mask R-CNN模型的权重,这些权重是在COCO数据集上预先训练所得到的;mask_rcnn_inception_v2_coco_2018_01_28 .pbtxt:Mask R-CNN模型的配置文件,如果你想在自己的数据集上构建及训练自己的模型,可以参阅网上的一些资源更改该配置文件。object_detection_classes_coco.txt:此文本文件中列出了数据集中包含的90个类,每行表示一个类别。
instance_segmentation .py:背景模糊脚本,本文的核心内容, 将详细介绍该代码并评估其算法性能。
使用OpenCV实现实例分割
下面开始使用OpenCV实现实例分割。首先打开instance_segmentation .py文件并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
import os在开始编写脚本时,首先需要导入必要的包,并且需要配置好编译环境。本文使用的OpenCV版本为3.4.3。如果个人的计算机配置文件不同,需要对其进行更新。强烈建议将此软件放在隔离的虚拟环境中,推荐使用conda安装。
下面解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--mask-rcnn", required=True,help="base path to mask-rcnn directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,help="minimum threshold for pixel-wise mask segmentation")
ap.add_argument("-k", "--kernel", type=int, default=41,help="size of gaussian blur kernel")
args = vars(ap.parse_args())每个命令行参数的描述可以在下面找到:
mask-rcnn:Mask R-CNN目录的基本路径;confidence:滤除弱检测的最小概率,可以将此值的默认值设置为0.5,也可以通过命令行传递不同的值;threshold:像素掩码分割的最小阈值,默认设置为 0.3;kernel:高斯模糊内核的大小,默认设置41,这是通过实验得到的经验值;
下面加载数据集的标签和OpenCV实例分割模型:
# load the COCO class labels our Mask R-CNN was trained on
labelsPath = os.path.sep.join([args["mask_rcnn"],"object_detection_classes_coco.txt"])
LABELS = open(labelsPath).read().strip().split("\n")# derive the paths to the Mask R-CNN weights and model configuration
weightsPath = os.path.sep.join([args["mask_rcnn"],"frozen_inference_graph.pb"])
configPath = os.path.sep.join([args["mask_rcnn"],"mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"])# load our Mask R-CNN trained on the COCO dataset (90 classes)
# from disk
print("[INFO] loading Mask R-CNN from disk...")
net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath)标签文件位于mask-rcnn - coco目录,指定好路径后就可以加载标签文件了。同样地, weightsPath和configPath也执行类型的操作。
基于这两个路径,利用dnn模块初始化神经网络。在开始处理视频帧之前,需要将Mask R-CNN加载到内存中(只需要加载一次)。
下面构建模糊内核并启动网络摄像头视频流:
# construct the kernel for the Gaussian blur and initialize whether
# or not we are in "privacy mode"
K = (args["kernel"], args["kernel"])
privacy = False# initialize the video stream, then allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)模糊内核元组也通过行命令设定。此外,项目有两种模式:“正常模式”和“隐私模式”。因此, 布尔值privacy用于模式逻辑,上述代码将其初始化为False。
网络摄像头视频流用VideoStream(src=0).start(),首先暂停两秒钟以让传感器预热。
初始化了所有变量和对象后,就可以从网络摄像头开始处理帧了:
# loop over frames from the video file stream
while True:# grab the frame from the threaded video streamframe = vs.read()# resize the frame to have a width of 600 pixels (while# maintaining the aspect ratio), and then grab the image# dimensionsframe = imutils.resize(frame, width=600)(H, W) = frame.shape[:2]# construct a blob from the input image and then perform a# forward pass of the Mask R-CNN, giving us (1) the bounding# box coordinates of the objects in the image along with (2)# the pixel-wise segmentation for each specific objectblob = cv2.dnn.blobFromImage(frame, swapRB=True, crop=False)net.setInput(blob)(boxes, masks) = net.forward(["detection_out_final","detection_masks"])在每次迭代中,将抓取一帧并将其调整为设定的宽度,同时保持纵横比。此外,为了之后的缩放操作,继续并提取帧的尺寸。然后,构建一个blob并完成前向传播网络。
结果输出是boxes和masks,虽然需要用到掩码(mask),但还需要使用边界框(boxes)中包含的数据。
下面对索引进行排序并初始化变量:
# sort the indexes of the bounding boxes in by their corresponding# prediction probability (in descending order)idxs = np.argsort(boxes[0, 0, :, 2])[::-1]# initialize the mask, ROI, and coordinates of the person for the# current framemask = Noneroi = Nonecoords = None通过其对应的预测概率对边界框的索引进行排序,假设具有最大相应检测概率的人是我们的用户。然后初始化mask、roi以及边界框的坐标。
遍历索引并过滤结果:
# loop over the indexesfor i in idxs:# extract the class ID of the detection along with the# confidence (i.e., probability) associated with the# predictionclassID = int(boxes[0, 0, i, 1])confidence = boxes[0, 0, i, 2]# if the detection is not the 'person' class, ignore itif LABELS[classID] != "person":continue# filter out weak predictions by ensuring the detected# probability is greater than the minimum probabilityif confidence > args["confidence"]:# scale the bounding box coordinates back relative to the# size of the image and then compute the width and the# height of the bounding boxbox = boxes[0, 0, i, 3:7] * np.array([W, H, W, H])(startX, startY, endX, endY) = box.astype("int")coords = (startX, startY, endX, endY)boxW = endX - startXboxH = endY - startY从idxs开始循环,然后,使用框和当前索引提取classID和 置信度。随后,执行第一个过滤器—— “人”。如果遇到任何其他对象类,继续下一个索引。下一个过滤器确保预测的置信度超过通过命令行参数设置的阈值。
如果通过了该测试,那么将边界框坐标缩放回图像的相对尺寸,然后提取坐标和对象的宽度/高度。
计算掩膜并提取ROI:
# extract the pixel-wise segmentation for the object,# resize the mask such that it's the same dimensions of# the bounding box, and then finally threshold to create# a *binary* maskmask = masks[i, classID]mask = cv2.resize(mask, (boxW, boxH),interpolation=cv2.INTER_NEAREST)mask = (mask > args["threshold"])# extract the ROI and break from the loop (since we make# the assumption there is only *one* person in the frame# who is also the person with the highest prediction# confidence)roi = frame[startY:endY, startX:endX][mask]break上述代码首先提取掩码,并调整其大小,之后应用阈值来创建二进制掩码本身。示例如下图所示:
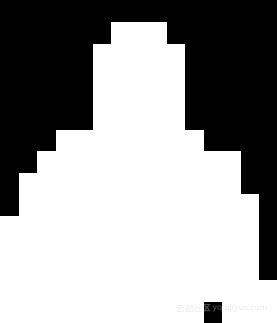
图2:使用OpenCV和实例分割在网络摄像头前通过实例分割计算的二进制掩码
从上图中可以看到,假设所有白色像素都是人(即前景),而所有黑色像素都是背景。使用掩码后,通过NumPy阵列切片计算roi。之后循环断开,这是因为你找到最大概率的人了。
如果处于“隐私模式”,需要进行初始化输出帧并计算模糊:
# initialize our output frameoutput = frame.copy()# if the mask is not None *and* we are in privacy mode, then we# know we can apply the mask and ROI to the output imageif mask is not None and privacy:# blur the output frameoutput = cv2.GaussianBlur(output, K, 0)# add the ROI to the output frame for only the masked region(startX, startY, endX, endY) = coordsoutput[startY:endY, startX:endX][mask] = roi其输出帧只是原始帧的副本。
如果我们俩都:
- 有一个非空的掩膜;
- 处于“ 隐私模式”;
- ... ...
然后将使用模糊背景并将掩码应用于输出帧。
下面显示输出以及图像处理按键:
# show the output framecv2.imshow("Video Call", output)key = cv2.waitKey(1) & 0xFF# if the `p` key was pressed, toggle privacy modeif key == ord("p"):privacy = not privacy# if the `q` key was pressed, break from the loopelif key == ord("q"):break# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()keypresses被获取其值,有两个值可供选择,但会导致不同的行为:
- “p”:按下此键时, 打开或关闭“ 隐私模式”;
- “q”:如果按下此键,将跳出循环并“退出”脚本;
每当退出时,上述代码就会关闭打开的窗口并停止视频流。
实例分割结果
现在已经实现了OpenCV实例分割算法,下面看看其实际应用!
打开一个终端并执行以下命令:
$ python instance_segmentation.py --mask-rcnn mask-rcnn-coco --kernel 41
[INFO] loading Mask R-CNN from disk...
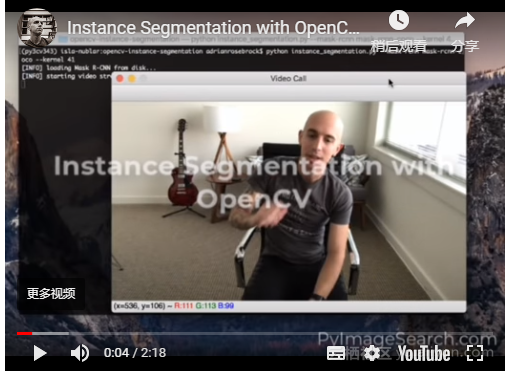
[INFO] starting video stream...图3:演示了一个用于网络聊天的“隐私过滤器”
通过启用“隐私模式”,可以:
- 使用OpenCV实例分割查找具有最大相应概率的人物检测(最可能是最接近相机的人);
- 模糊视频流的背景;
- 将分割的、非模糊的人重叠到视频流上;
下面列出一个视频演示(需外网):
https://youtu.be/puSN8Dg-bdI
看完视频会立即注意到,并没有获得真正的实时性能——每秒只处理几帧。为什么是这样?
要回答这些问题,请务必参考以下部分。
限制、缺点和潜在的改进
第一个限制是最明显的——OpenCV实例分割的实现太慢而无法实时运行。在CPU上运行,每秒只能处理几帧。为了获得真正的实时实例分割性能,需要利用到GPU。
但其中存在的问题是:
- OpenCV对其
dnn模块的GPU支持相当有限; - 目前,它主要支持英特尔GPU;
- NVIDIA CUDA GPU支持正在开发中,但目前尚未推出;
一旦OpenCV正式支持dnn模块的NVIDIA GPU版本, 就能够更轻松地构建实时(甚至超实时)的深度学习应用程序。但就目前而言,本文的实例分割教程只作为演示:
此外,也可以做出的另一项改进与分割的人重叠在模糊的背景上有关。当将本文的实现与Microsoft的Office 365视频模糊功能进行比较时,就会发现Microsoft会更加“流畅”。但也可以通过利用一些alpha混合来模仿这个功能。
对实例分割管道进行简单而有效的更新可能是:
- 使用形态学操作来增加蒙版的大小;
- 在掩膜本身涂抹少量高斯模糊,帮助平滑掩码;
- 将掩码值缩放到范围[0,1];
- 使用缩放蒙版创建alpha图层;
- 在模糊的背景上叠加平滑的掩膜+人;
或者,也可以计算掩膜本身的轮廓,然后应用掩膜近似来帮助创建“更平滑”的掩码。
总结
看完本篇文章,你应该学习了如何使用OpenCV、Deep Learning和Python实现实例分割了吧。实例分割大体过程如下:
- 检测图像中的每个对象;
- 计算每个对象的逐像素掩码;
注意,即使对象属于同一类,实例分割也应为每个对象返回唯一的掩码;
作者信息
Adrian Rosebrock ,机器学习,人工智能,图像处理
本文由阿里云云栖社区组织翻译。
文章原标题《Instance segmentation with OpenCV》,译者:海棠,审校:Uncle_LLD。
文章为简译,更为详细的内容,请查看原文。
使用opencv实现实例分割,一学就会|附源码相关推荐
- opencv判断 线夹角_python opencv实现直线检测并测出倾斜角度(附源码+注释)
由于学习需要,我想要检测出图片中的直线,并且得到这些直线的角度.于是我在网上搜了好多直线检测的代码,但是没有搜到附有计算直线倾斜角度的代码,所以我花了一点时间,自己写了一份直线检测并测出倾斜角度的代码 ...
- 基于 SpringMvc + OpenCV 实现的答题卡识别系统(附源码)
点击关注公众号,实用技术文章及时了解 java_opencv 项目介绍 OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,它提供了一系列图像处理和计算机视觉方面很多通用算法.是研究图像 ...
- 基于 SpringMvc+OpenCV 实现的答题卡识别系统(附源码)
java_opencv 项目介绍 OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,它提供了一系列图像处理和计算机视觉方面很多通用算法.是研究图像处理技术的一个很不错的工具.最初开始接 ...
- 【Android App】人脸识别中借助摄像头和OpenCV实时检测人脸讲解及实战(附源码和演示 超详细)
需要全部代码请点赞关注收藏后评论区留言私信~~~ 一.借助摄像头实时检测人脸 与Android自带的人脸检测器相比,OpenCV具备更强劲的人脸识别功能,它可以通过摄像头实时检测人脸,实时检测的预览空 ...
- Qt Quick 图像处理实例之美图秀秀(附源码下载)
在<Qt Quick 之 QML 与 C++ 混合编程详解>一文中我们讲解了 QML 与 C++ 混合编程的方方面面的内容,这次我们通过一个图像处理应用,再来看一下 QML 与 C++ 混 ...
- 【Android App】人脸识别中使用Opencv比较两张人脸相似程度实战(附源码和演示 超详细)
需要全部代码请点赞关注收藏后评论区留言私信~~~ 一.比较两张人脸的相似程度 直方图由一排纵向的竖条或者竖线组成,横轴代表数据类型,纵轴代表数据多少. 图像直方图经常应用于特征提取.图像匹配等方面. ...
- Python 毕业设计 - 基于 opencv 的人脸识别上课考勤系统,附源码
一.简介 这个人脸识别考勤签到系统是基于大佬的人脸识别陌生人报警系统二次开发的. 项目使用Python实现,基于OpenCV框架进行人脸识别和摄像头硬件调用,同时也用OpenCV工具包处理图片.交互界 ...
- 【Android App】实战项目之使用OpenCV人脸识别实现找人功能(附源码和演示 超详细)
需要全部代码请点赞关注收藏后评论区留言私信~~~ 人脸识别自古有之,每当官府要捉拿某人时,便在城墙贴出通缉告示并附上那人的肖像.只是该办法依赖人们的回忆与主观判断,指认结果多有出入,算不上什么先进. ...
- Python图像识别实战(三):基于OpenCV实现批量单图像超分辨重建(附源码和实现效果)
前面我介绍了可视化的一些方法以及机器学习在预测方面的应用,分为分类问题(预测值是离散型)和回归问题(预测值是连续型)(具体见之前的文章). 从本期开始,我将做一个关于图像识别的系列文章,让读者慢慢理解 ...
最新文章
- NodeJS和C++之间的类型转换
- 计算力即生产力,智算中心就是智慧时代的“发电厂” | MEET2021
- 【学习笔记】JS进阶语法一事件进阶
- centos7安装ddos-deflate
- CG CTF CRYPTO easy!
- 前端学习(2461):打包发布
- 浅谈Mysql 表设计规范
- YV12 and NV12异同,
- Jmeter - 服务器性能检测
- ubuntu系统4G卡上网操作图解
- 统计学权威盘点过去50年最重要的统计学思想,因果推理、bootstrap等上榜
- [noip2014]解方程 hash+秦九昭
- 计算机主机运行显示器没反应,启动电脑显示器没反应 启动电脑显示器没反应是什么原因...
- 气相色谱仪排除问题S级详情讲解【Chro】
- 【数据结构】两栈共享空间(双端栈)
- C语言编译器和amd兼容吗,Intel的“霸道”:深究编译器对CPU性能的影响
- [Mysql] SQL的书写顺序与执行顺序
- Windows 上帝模式「完全控制面板」的介绍和使用
- 微信小程序-购物车数字加减
- vivado约束BANK电平冲突