《Greenplum企业应用实战》一2.3 畅游Greenplum
本节书摘来自华章出版社《Greenplum企业应用实战》一书中的第2章,第2.3节,作者 何勇 陈晓峰,更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.3 畅游Greenplum
本节只介绍一些常用的命令,重点是Greenplum特有的一些命令,而对于一般数据库都具备的特性及SQL标准语法,本节提到的比较少,因此要求读者在阅读本节具备一定的SQL基础。
2.3.1 如何访问Greenplum
- psql
psql是Greenplum/PostgreSQL默认的客户端,前面初始化数据库的时候已经使用过了,下面介绍一些详细的用法。
[gpadmin@dw-greenplum-1 ~]$ psql --help
This is psql 8.2.15, the PostgreSQL interactive terminal (Greenplum version).
Usage:psql [OPTION]... [DBNAME [USERNAME]]General options:-c, --command=COMMAND run only single command (SQL or internal) and exit-d, --dbname=DBNAME database name to connect to (default: "testDB")
…Connection options:-h, --host=HOSTNAME database server host or socket directory (default: "local socket")-p, --port=PORT database server port (default: "2345")-U, --username=USERNAME database user name (default: "gpadmin")
我们可以在其他机器上使用psql连接到数据库中,例如:
admin@test1:/home/admin>psql -h 10.20.151.7 -p 2345 -d testDB -U gpadmin
psql: FATAL: no pg_hba.conf entry for host "10.20.151.1", user "gpadmin", database "testDB", SSL off
之所以报错,是因为Greenplum有权限控制,并不是所有的机器都可以连接到数据库上。关于如何配置权限控制,会在“第9章数据库管理”的前两节详细介绍。如果有其他计算机要登录Greenplum,先为数据库用户gpadmin创建一个密码,然后在pg_hba.conf文件中增加客户端机器的权限配置,这样就可以成功登录了。
testDB=# alter role gpadmin with password 'gpadmin';
ALTER ROLE
接着在$MASTER_DATA_DIRECTORY/pg_hba.conf文件中增加:
host testDB gpadmin 10.20.151.1/32 md5
之后通过gpstop -u 命令使配置生效,如图2-14所示。

这样我们就可以在其他机器上登录数据库了。
admin@test1:/home/admin>psql -h 10.20.151.7 -p 2345 -d testDB -U gpadmin -W
Password for user gpadmin:
psql (8.2.13, server 8.2.15)
Type "help" for help.
testDB=#
- pgAdmin
当然,除了采用psql的登录方法之外,还可以利用图形界面的GUI,就是pgAdmin这款软件。我们可以从http://www.pgadmin.org/download/这个网址上下载pgAdmin。
这里以Windows为例,介绍下pgAdmin软件的安装及使用。
首先,下载pgadmin3-1.14.1.zip后将其解压并进行安装。
然后,启动pgAdmin,自动弹出“新增服务器登记”界面,如图2-15所示。
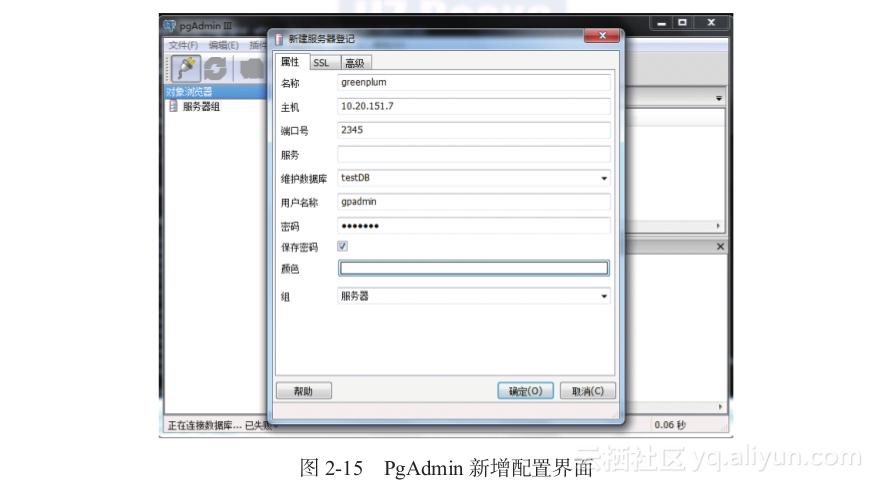
接下来单击“确认”按钮创建连接,登录到Greenplum数据库中(需要在pg_hba.conf中将本机的IP加入认证)。
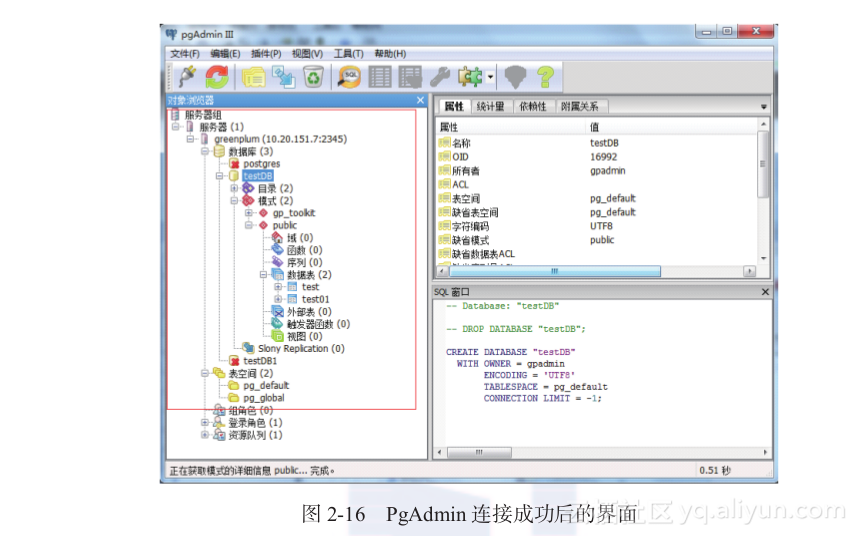
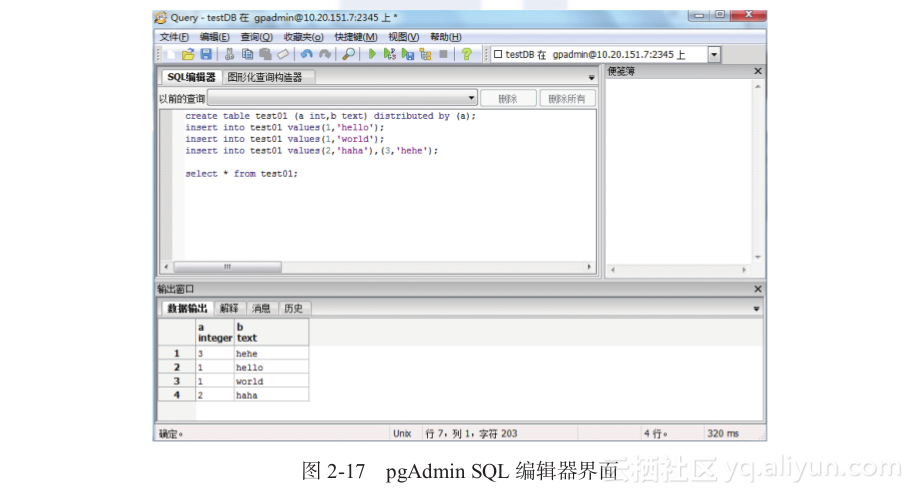
单击图2-16中的,弹出如图2-17所示的pgAdmin SQL编辑器界面,我们就可以在其中编写SQL查询语句了。
2.3.2 数据库整体概况
本小节稍微介绍一下Greenplum的数据分布,以方便读者理解Greenplum的一些操作。
- Greenplum基于PostgreSQL开发
Greenplum是基于开源数据库软件PostgreSQL 8.2开发的,其大部分语法和数据字典都与PostgreSQL一样,很多工具使用的规范也基本跟PostgreSQL一样。因此,在学习的过程中,可以参考网上的一些PostgreSQL的资料。强烈建议参考PostgreSQL 8.2的官方中文文档,其中大部分内容都适用于Greenplum。 - Greenplum的数据分布
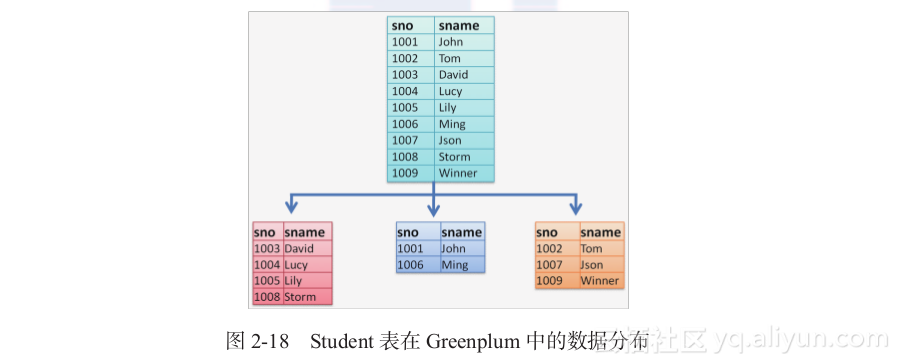
可以说Greenplum将PostgreSQL改造成一个分布式数据库。其中,Segment节点都是一个单独的PostgreSQL数据库,Master本身也是一个PostgreSQL数据库。
Master本身不储存数据,所有数据拆分保存到每一个节点上。在指定分布键的时候,数据按照分布键的Hash值来分布数据,称为哈希分布。还有一种分布不用指定分布键,数据随机分布到每一个节点上,称作随机分布(也叫平均分布)。
以一张Student表为例,它在Greenplum中的数据分布如图2-18所示。
2.3.3 基本语法介绍
Greenplum是一个很全面的数据库,提供了很多的功能。如果将所有语法都讲一遍,篇幅会很大,所以这里只将一些基本的语法简单罗列一下。
- 获取语法介绍
可以使用h查看Greenplum支持的所有语法,如图2-19所示。
在psql中使用h command可以获取具体命令的语法:
testDB=# \h create view
Command: CREATE VIEW
Description: define a new view
Syntax:
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] VIEW name [ ( column_name [, ...] ) ]AS query

- CREATE TABLE
Greenplum中的建表语句跟普通数据库的建表语句区别不大,仅有几个地方与其他数据库不同。
在Greenplum中建表时需要指定表的分布键。
如果表需要用某个字段分区,可以通过partition by将表建成分区表。
可以使用like操作创建与like的表一样结构的表,功能类似create table t1 as select * from t2 limit 0。
可以使用inherits实现表的继承,具体的实现可以参考postgreSQL文档。
在Greenplum中,建表语句的语法大致如下:
Command: CREATE TABLE
Description: define a new table
Syntax:
CREATE [[GLOBAL | LOCAL] {TEMPORARY | TEMP}] TABLE table_name ( [ { column_name data_type [DEFAULT default_expr] [column_constraint [ ... ]]| table_constraint| LIKE other_table [{INCLUDING | EXCLUDING} {DEFAULTS | CONSTRAINTS}] ...}[, ... ] ] )[ INHERITS ( parent_table [, ... ] ) ][ WITH ( storage_parameter=value [, ... ] )[ ON COMMIT {PRESERVE ROWS | DELETE ROWS | DROP} ][ TABLESPACE tablespace ][ DISTRIBUTED BY (column, [ ... ] ) | DISTRIBUTED RANDOMLY ][ PARTITION BY partition_type (column)[ SUBPARTITION BY partition_type (column) ] [ SUBPARTITION TEMPLATE ( template_spec ) ][...]( partition_spec ) | [ SUBPARTITION BY partition_type (column) ][...]( partition_spec [ ( subpartition_spec [(...)] ) ] )
由于Greenplum是一个分布式数据库,数据肯定是分布在每一个节点上的。在Greenplum中有两种数据分布策略:
1)Hash分布。指定一个或多个分布键,计算hash值,并且通过hash值路由到特定的Segment节点上,语法为Distributed by(..)。如果不指定分布键,默认将第一个字段作为分布键。
2)随机分布,也叫平均分布。数据随机分散在每一个节点中,这样无论数据是什么内容,都可以平均分布在每个节点上,但是在执行SQL的过程中,关联等操作都需要将数据重分布,性能较差。语法为在表字段定义的后面加上Distributed randomly。
下面两个建表语句的执行结果一样,都是以id作为分布键:
testDB=# create table test001(id int ,name varchar(128));
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLEtestDB=# create table test002(id int ,name varchar(128)) distributed by(id);
CREATE TABLE
在下面的建表语句中指定了多个分布键:
testDB=# create table test003(id int ,name varchar(128)) distributed by(id,name);
CREATE TABLE
在下面的建表语句中采用了随机分布:
testDB=# create table test004(id int ,name varchar(128)) distributed randomly;
CREATE TABLE
采用随机分布策略的表默认将主键或唯一键作为分布键,因为每一个Segment都是一个单一的数据库,单个的数据库可以保证唯一性,多个数据库节点就无法保证全局的跨库唯一性,故只能按照唯一键分布,同一个值的数据都在一个节点上,以此来保证唯一性。
testDB=# create table test005(id int primary key,name varchar(128));
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "test005_pkey" for table "test005"
CREATE TABLE
testDB=# create table test006(id int unique,name varchar(128));
NOTICE: CREATE TABLE / UNIQUE will create implicit index "test006_id_key" for table "test006"
CREATE TABLE
如果指定的分布键与主键不一样,那么分布键会被更改为主键:
testDB=# create table test007(id int unique,name varchar(128)) distributed by(id,name);
NOTICE: updating distribution policy to match new unique index
NOTICE: CREATE TABLE / UNIQUE will create implicit index "test007_id_key" for table "test007"
CREATE TABLE
testDB=# \d test007Table "public.test007"Column | Type | Modifiers
--------+------------------------+-----------id | integer | name | character varying(128) |
Indexes:"test007_id_key" UNIQUE, btree (id)
Distributed by: (id)
在创建表的时候,如果要建一张表结构一模一样的表,可以利用create table like命令:
testDB=# create table test001_like (like test001);
NOTICE: Table doesn't have 'distributed by' clause, defaulting to distribution columns from LIKE table
CREATE TABLE
使用like创建的表,只是表结构会与原表一模一样,表的一些特殊属性并不会一样,例如压缩、只增(appendonly)等属性。如果不指定分布键,则默认分布键与原表一样。
- SELECT
Greenplum中的SELECT操作基本上与普通关系型数据库中的SELECT操作没有太大的区别。要了解SQL的执行计划,对于Greenplum而言,重点要了解分布式执行计划,这个具体会在“第5章执行计划详解”中详细介绍。
下面介绍SELECT语句的语法。SELECT语句的基本语法跟其他数据库类似,也有自己的一些特性,例如分页采用offset加limit操作:
Command: SELECT
Description: retrieve rows from a table or view
Syntax:
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]* | expression [ [AS] output_name ] [, ...][ FROM from_item [, ...] ][ WHERE condition ][ GROUP BY grouping_element [, ...] ][ HAVING condition [, ...] ][ WINDOW window_name AS (window_specification) ][ { UNION | INTERSECT | EXCEPT } [ ALL ] select ][ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ][ LIMIT { count | ALL } ][ OFFSET start ][ FOR { UPDATE | SHARE } [ OF table_name [, ...] ] [ NOWAIT ] [...] ]
一个简单的示例如下:
testDB=# select id,name from test001 order by id;id | name
-----+-------100 | jack101 | david102 | tom103 | lily
(4 rows)
SELECT可以不用指定From子句,如执行函数:
testDB=# select greatest(1,2);greatest
----------2
(1 row)
进行一些简单的科学计算等:
testDB=# select 2^3+3+9*(8+1);?column?
----------92
(1 row)
需要注意的是,Greenplum的数据切分放在所有的Segment上。当从一个表查询数据的时候,Master的数据展现顺序是以Master先接收到的数据的顺序,每个Segment的数据到达Master的顺序是随机的,不是固定的,所以执行SELECT的结果的顺序是随机的,即使表中数据一点变化都没有。这一点跟其他数据库是不一样的,下面是两次执行SELECT的结果,从中明显可以看出数据的顺序是不一样的。如果要求多次查询的结果一样,必须显式地加一个order by语句,强制输出的结果排序。
下面是连续两次对同一个表执行查询操作的结果(中间数据没有发生过任何变更),可以看出,如果不加order by子句,在查询的结果中,数据的顺序是不能够保证的。
testDB=# select * from test001; testDB=# select * from test001;id | name id | name
-----+------- -----+-------101 | david 101 | david103 | lily 100 | jack100 | jack 102 | tom102 | tom 103 | lily
(4 rows) (4 rows)
- create table as与select into
- table as与select into有一样的功能,都可以使表根据直接执行SELECT的结果创建出一个新的表,这个在临时分析数据的时候十分方便。例如,在创建一个表的时候如果默认不指定分布键,那么Greenplum根据执行SELECT得到的结果集来选择,不用再次重分布数据的字段作为表的分布键:
testDB=# create table test2 as select * from test1;
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column(s) named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
SELECT 10000
当然,也可以手工加入distributed 关键字,指定分布键,这样数据就会根据指定分布键再建表:
testDB=# create table test3 as select * from test1 distributed by(id);
SELECT 10000
select into的语法比create table as更简单,虽然功能一样,但是执行select into不能指定分布键,只能使用默认的分布键,例如:
testDB=# select * into test4 from test1;
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column(s) named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
SELECT 10000
- explain
explain用于查询一个表的执行计划,它在SQL优化的时候经常要用到,详细的执行计划解释请参考“第5章执行计划详解”。
下面代码演示了简单的执行计划的查看方法:
testDB=# explain select * from test1 x,test2 y where x.id=y.id;QUERY PLAN
------------------------------------------------------------------------------Gather Motion 6:1 (slice1; segments: 6) (cost=243.00..511.00 rows=1667 width=30)-> Hash Join (cost=243.00..511.00 rows=1667 width=30)Hash Cond: x.id = y.id-> Seq Scan on test1 x (cost=0.00..118.00 rows=1667 width=15)-> Hash (cost=118.00..118.00 rows=1667 width=15)-> Seq Scan on test2 y (cost=0.00..118.00 rows=1667 width=15)
(6 rows)
可以看出,上面代码查看的是一个简单的关联生成的执行计划,该执行计划是一个层次关系,先从最右边开始查看。
第一步,数据库先顺序扫描test2表,扫描大概有118单位的消耗,有1667行数据,平均长度为15字节。其中,1667行数据是一个估计值,是一个Segment的数据量,如果数据分布均匀,大概是总数据量除以Segment的个数。由于这个Greenplum集群有6个Segment节点,因此可以推断test2表大概有1万行数据。
第二步,扫描出test2表,并且计算hash值,将其保存在内存中。
第三步,顺序扫描test1表。
第四步,在扫描test1表的过程中,与test2表进行hash后的结果关联(hash join),关联的条件是两表的id字段相同。
第五步,将数据汇总到Master上。Master将数据结果进行汇总并展现。
- insert、update和delete
这3个操作是数据库最基本的操作,基本语法就不介绍了,只讲几点数据切片带来的问题。
1)insert:在执行insert语句的时候,要留意分布键不要为空,否则分布键默认会变成null,数据都被保存在一个节点上,造成数据分布不均。
insert可以批量操作,语法如下:
testDB=# insert into test001 values(100,'tom'),(101,'lily'),(102,'jack');
INSERT 0 3
2)update:不能批量对分布键执行update,因为对分布键执行update需要将数据重分布,而Greenplum暂时不支持这个功能。
testDB=# \d test001Table "public.test001"Column | Type | Modifiers
--------+---------+-----------id | integer | name | text |
Indexes:"test001_idx" btree (id)
Distributed by: (id)testDB=# update test001 set id=5 where id=6;
ERROR: Cannot parallelize an UPDATE statement that updates the distribution columns
3)delete:在Greenplum 3.x的版本中,如果Delete操作涉及子查询,并且子查询的结果还会涉及数据重分布,这样的删除语句会报错,如下所示(在Greenplum 4.x中支持该操作):
testDB=# delete from test001 where name in (select name from test002);
ERROR: Cannot parallelize that DELETE yet
DETAIL: Passage of data from one segment to another is not yet supported during DELETE operations.
HINT: The WHERE condition must specify equality between corresponding DISTRIBUTED BY columns of the target table and all joined tables.
如果对整张表执行Delete会比较慢,建议使用TRUNCATE。
- TRUNCATE
与在Oracle中一样,执行TRUNCATE直接删除表的物理文件,然后创建新的数据文件。TRUNCATE操作比Delete操作在性能上有非常大的提升,当前如果有SQL正在操作这张表,那么TRUNCATE操作会被锁住,直到表上面的所有锁被释放。
testDB=# truncate test001;
TRUNCATE TABLE
2.3.4 常用数据类型
Greenplum的数据类型基本跟PostgreSQL的一样,类型十分丰富,下面介绍几种最常见的数据类型。对于Greenplum支持的其他数据类型,读者可以参考PostgreSQL文档。
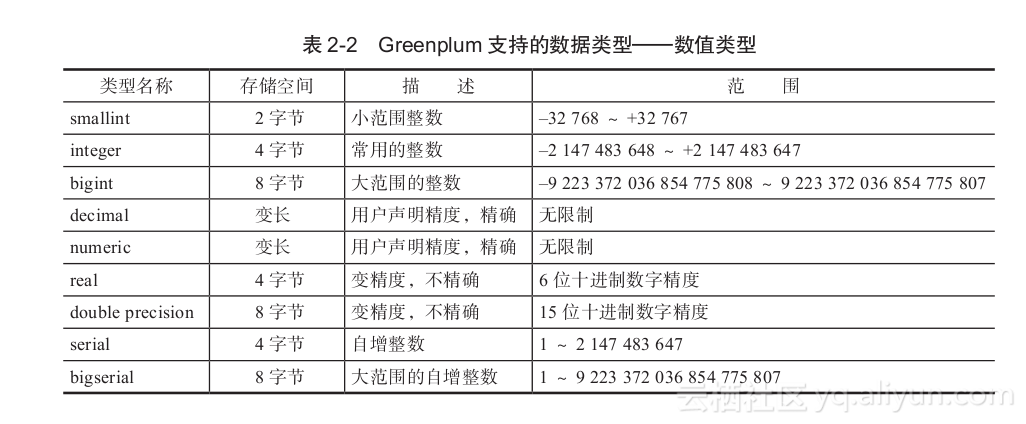
- 数值类型
Greenplum支持的数值类型数据如表2-2所示。
- 字符类型
Greenplum支持的字符类型数据如表2-3所示。

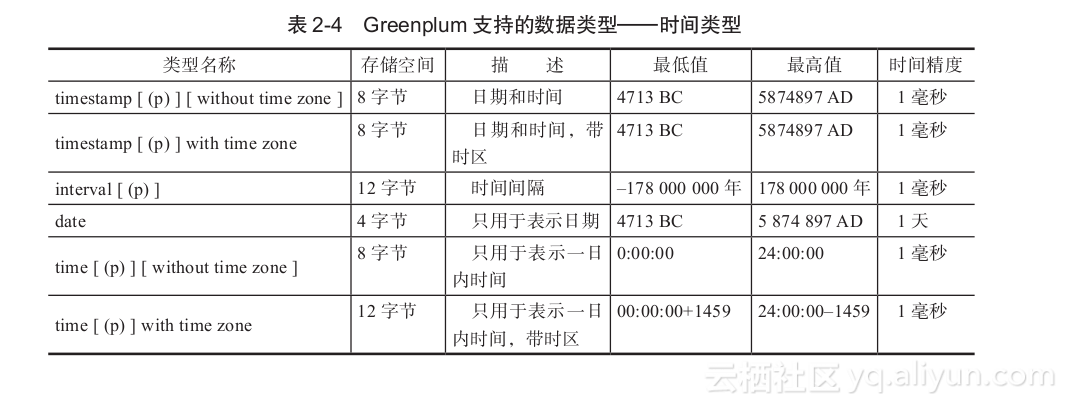
- 时间类型
Greenplum支持的时间类型数据如表2-4所示。
2.3.5 常用函数
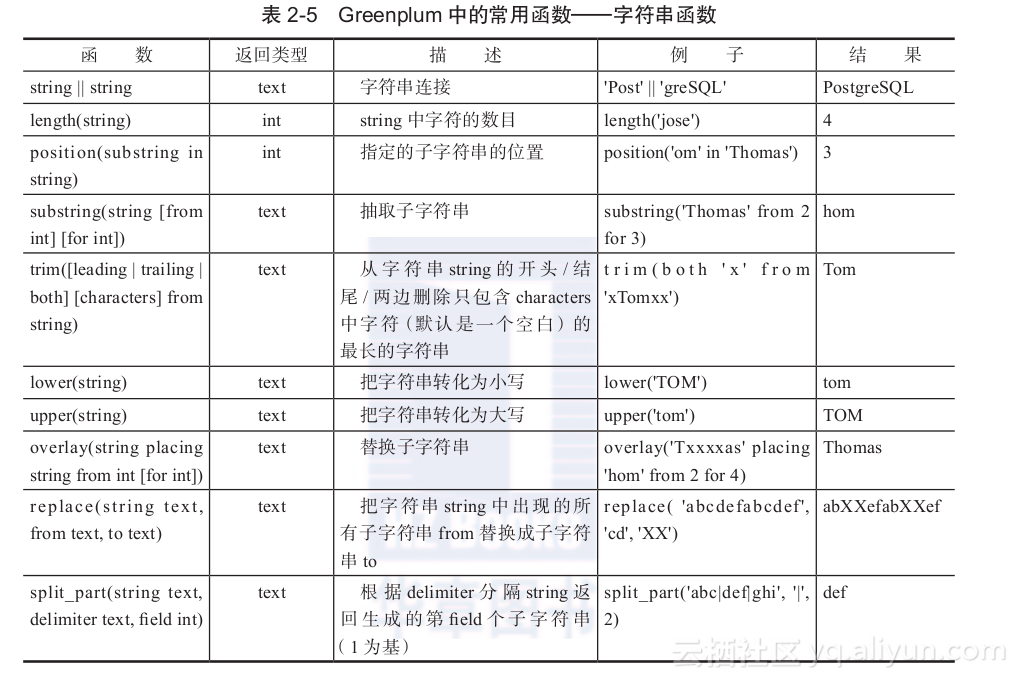
- 字符串函数
Greenplum中的字符串函数如表2-5所示。
下面是一个字符串拼接的示例:
testDB=# select 'green'||'plum' as dbname;dbname
-----------greenplum
(1 row)
下面以|为分隔符,将字符串分割:
testDB=# select split_part(col,'|',1)
testDB-# ,split_part(col,'|',2)
testDB-# from (values ('hello|wolrd!'),('greenplum|database'))
testDB-# t(col) ;split_part | split_part
------------+------------hello | wolrd!greenplum | database
(2 rows)
其中Values是Greenplum特有的语法,在这里可以将其看成一张表,表中有两行数据,表名为t,字段名为col,Values的用法如下:
testDB=# values ('hello|wolrd!'),('greenplum|database');column1
--------------------hello|wolrd!greenplum|database
(2 rows)
获取字符串的第2个字符之后的3个字符:
testDB=# select substr('hello world!',2,3);substr
--------ell
(1 row)
获取子串在字符串中的位置:
testDB=# select position('world' in 'hello world!');
position
----------7
(1 row)
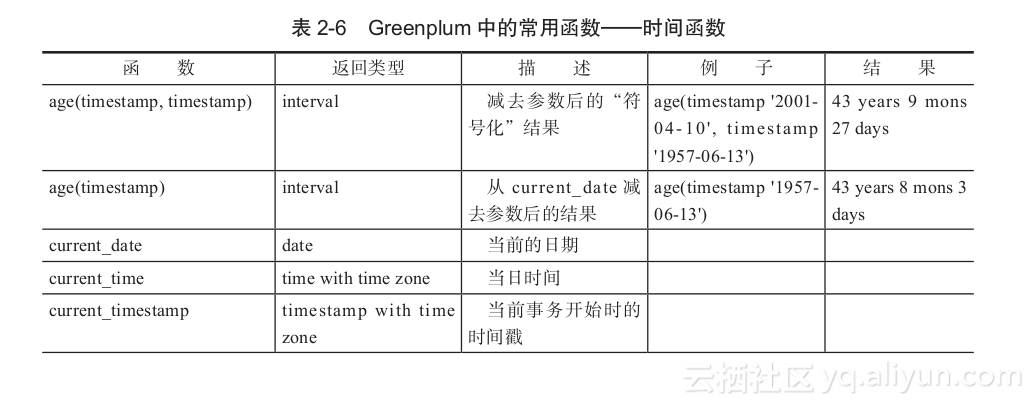
- 时间函数
本节内容可参考PostgreSQL8.2文档“9.9.时间/日期函数和操作符”。Greenplum支持的时间函数如表2-6所示。
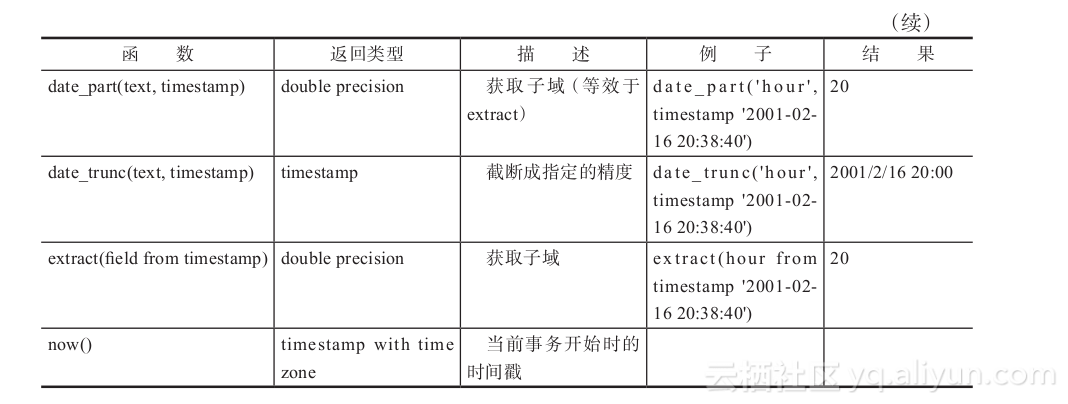
时间加减:
testDB=# select '2011-10-01 10:0:0'::timestamp + interval '10 days 2 hours 10 seconds';?column?
---------------------2011-10-11 12:00:10
(1 row)
Interval是一种表示时间间隔的一种数据类型。利用interval这种数据类型可以实现时间的加减,两个时间的时间差就是一个Interval类型。
获取当前时间:
testDB=# select now(), current_date, current_time , current_timestamp;now | date | timetz | now
------------------------------+------------+-------------------+------------------------------2012-01-15 16:04:52.15361+08 | 2012-01-15 | 16:04:52.15361+08 | 2012-01-15 16:04:52.15361+08
(1 row)
获取当月的第一天:
aligputf8=# select date_trunc('months',now())::date;date_trunc
------------2012-01-01
(1 row)
aligputf8=# select date_trunc('months',now())::date;date_trunc
------------2012-01-01
(1 row)
获取当前时间距离2011-10-10 10:10:10过了多少秒:
testDB=# SELECT EXTRACT(EPOCH FROM now() - '2011-10-10 10:10:10');date_part
----------------8403301.725044
(1 row)
除了这些函数以外,Greenplum还支持SQL的OVERLAPS操作符:
(start1, end1) OVERLAPS (start2, end2)
(start1, length1) OVERLAPS (start2, length2)
这个表达式在两个时间域(用它们的终点定义)重叠的时候生成真值。终点可以用一对日期、时间或时间戳来声明,或者在后面跟一个时间间隔的日期、时间或时间戳。
testDB=# SELECT (DATE '2011-02-16', DATE '2011-12-21') OVERLAPS
testDB-# (DATE '2011-10-30', DATE '2012-1-15');overlaps
----------t
(1 row)
testDB=# SELECT (DATE '2011-02-16', INTERVAL '100 days') OVERLAPS
testDB-# (DATE '2011-10-30', DATE '2012-10-30');overlaps
----------f
(1 row)
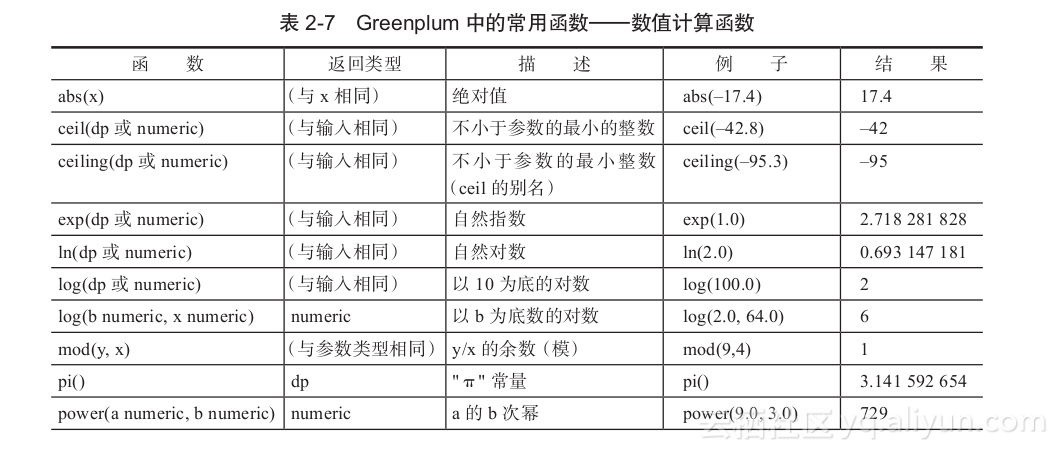
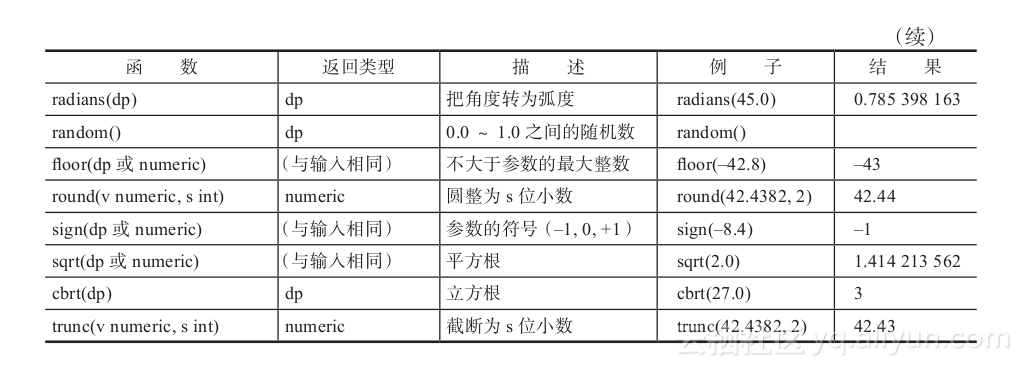
- 数值计算函数
Greenplum中的数值计算函数如表2-7所示。
- 其他常用函数
(1)序列号生成函数—generate_series
该函数生成多行数据,从一个数字(start)到另外一个数字(end)按照一定的间隔,默认是1,生成一个结果集,具体的使用方法如下:
testDB=# select * from generate_series(6,10);generate_series
-----------------678910
(5 rows)
我们可以很方便地使用这个函数来创建一些测试表的数据:
testDB=# create table test_gen as select generate_series(1,10000) as id,'hello'::text as name distributed by (id);
SELECT 10000
我们还可以用generate_series来做一些数值计算,比如,计算1~2000之间所有的奇数之和:
testDB=# select sum(num) from generate_series(1,2000,2) num;sum
---------1000000
(1 row)
(2)字符串列转行函数—string_agg
有时候我们需要将一个列的字符串按照某个分割符将其拼接起来:
testDB=# select * from test_string;id | str
----+-----------1 | hello1 | world2 | greenplum2 | database2 | system
(5 rows)
要按照id字段将字符串拼接起来,可以像下面这样使用string_agg来实现。
testDB=# select id,string_agg(str,'|') from test_string group by id;id | string_agg
----+---------------------------2 | greenplum|database|system1 | hello|world
(2 rows)
我们还可以先按照某一个字段做排序,再做拼接:
testDB=# select id,string_agg(str,'|' order by str) from test_string group by id;id | string_agg
----+---------------------------2 | database|greenplum|system1 | hello|world
(2 rows)
这个函数是Greeplum 4.0之后加入的新功能,要在Greeplum 3.x中实现同样的功能,需要自己自定义一个聚合函数,第6章将介绍如何编写自定义函数。
(3)字符串行转列—regexp_split_to_table
上面介绍进行字符串拼接的函数,那么反过来怎么把拼接好的字符串重新拆分,变成多个字段呢?
我们可以使用regexp_split_to_table函数来实现这个功能。这次对上面例子的结果进行操作。
testDB=# select * from test_string2;id | str
----+---------------------------1 | hello|world2 | database|greenplum|system
(2 rows)testDB=# select id,regexp_split_to_table(str,E'\\|') str from test_string2;id | str
----+-----------1 | hello1 | world2 | database2 | greenplum2 | system
(5 rows)
由于|字符被转义了,因此想正确表达,必须对其进行转义。
(4)hash函数—md5, hashbpchar
Greenplum中内置了很多hash函数,下面以其中两个为例进行介绍,其他的大同小异,只是按照不同的数据类型来执行hash函数。
md5的hash算法的精确度是128位,返回值是一个字符串。
testDB=# select md5('helloworld');md5
----------------------------------fc5e038d38a57032085441e7fe7010b0
(1 row)
Hashbpchar的精确度是32位的,返回值是一个integer类型。
testDB=# select hashbpchar('helloworld');hashbpchar
------------252807993
(1 row)
2.3.6 分析函数
学习过Oracle的读者应该知道,Oracle中的分析函数功能十分强大, Greenplum中也内置了这些函数,对于数据仓库应用来说,在对大量数据进行分析的时候,这些函数可以为实现一些复杂逻辑节省很多的时间。
- 开窗函数
使用数据库进行数据分析的时候经常用聚合函数来做一些不同维度的统计分析,但是聚合函数统计出的是汇总后的结果,没有明细数据,如果既要统计结果又要明细数据,那么用普通的SQL将会很复杂。如果利用开窗函数,这一切就会变得很简单。简言之,聚合函数返回各个分组的结果,开窗函数则为每一行返回结果。下面将结合PostgreSQL8.4英文文档中的例子来简单介绍下开窗函数的使用。
原表的数据为:
testDB=# select * from empsalary order by depname;depname | empno | salary
-----------+-------+--------develop | 9 | 4500develop | 11 | 5200develop | 7 | 4200develop | 10 | 5200develop | 8 | 6000personnel | 5 | 3500personnel | 2 | 3900sales | 3 | 4800sales | 1 | 5000sales | 4 | 4800
(10 rows)
每个部门的人,在部门内工资的排名:
testDB=# SELECT depname, empno, salary
testDB-# ,rank() OVER (PARTITION BY depname ORDER BY salary DESC)
testDB-# ,row_number() OVER (PARTITION BY depname ORDER BY salary DESC)
testDB-# FROM empsalary;depname | empno | salary | rank | row_number
-----------+-------+--------+------+------------personnel | 2 | 3900 | 1 | 1personnel | 5 | 3500 | 2 | 2develop | 8 | 6000 | 1 | 1develop | 11 | 5200 | 2 | 2develop | 10 | 5200 | 2 | 3develop | 9 | 4500 | 4 | 4develop | 7 | 4200 | 5 | 5sales | 1 | 5000 | 1 | 1sales | 3 | 4800 | 2 | 2sales | 4 | 4800 | 2 | 3
(10 rows)
执行rank函数,同样工资的排名会是一样,执行row_number函数,则同一个数值,都会有先后顺序的,比如develop部门的empno为10、11的两个员工的工资都是5200元,使用rank,则排名都是2,如果使用row_number,则10的排名是2,11的排名是3。
在执行sum、count和avg这一类的聚集函数时,加不加order by是不相同的。不加order by所有的结果都是一样的,都是根据partition by的字段将所有的值聚合,加了order by则是根据排序的字段递增的。例如下面这个SQL:
testDB=# SELECT *
testDB-# ,sum(salary) OVER () sum1
testDB-# ,sum(salary) OVER (ORDER BY salary) sum2
testDB-# ,sum(salary) OVER (partition by depname) sum3
testDB-# ,sum(salary) OVER (partition by depname order by salary) sum4
testDB-# FROM empsalary;depname | empno | salary | sum1 | sum2 | sum3 | sum4
-----------+-------+--------+-------+-------+-------+-------personnel | 5 | 3500 | 47100 | 3500 | 7400 | 3500personnel | 2 | 3900 | 47100 | 7400 | 7400 | 7400develop | 7 | 4200 | 47100 | 11600 | 25100 | 4200develop | 9 | 4500 | 47100 | 16100 | 25100 | 8700sales | 3 | 4800 | 47100 | 25700 | 14600 | 9600sales | 4 | 4800 | 47100 | 25700 | 14600 | 9600sales | 1 | 5000 | 47100 | 30700 | 14600 | 14600develop | 10 | 5200 | 47100 | 41100 | 25100 | 19100develop | 11 | 5200 | 47100 | 41100 | 25100 | 19100develop | 8 | 6000 | 47100 | 47100 | 25100 | 25100
(10 rows)
字段sum1是所有雇员工资总和的大小,sum2则是全局根据工资排序后的递增结果,sum3是每个部门内雇员工资的总和,sum4是部门内按照工资排序后的递增结果。
- grouping sets
如果需要对几个字段的组合进行group by,就需要用到Grouping Sets的功能了。 为了方便读者理解,下面介绍一些等价的定义,如表2-8所示。
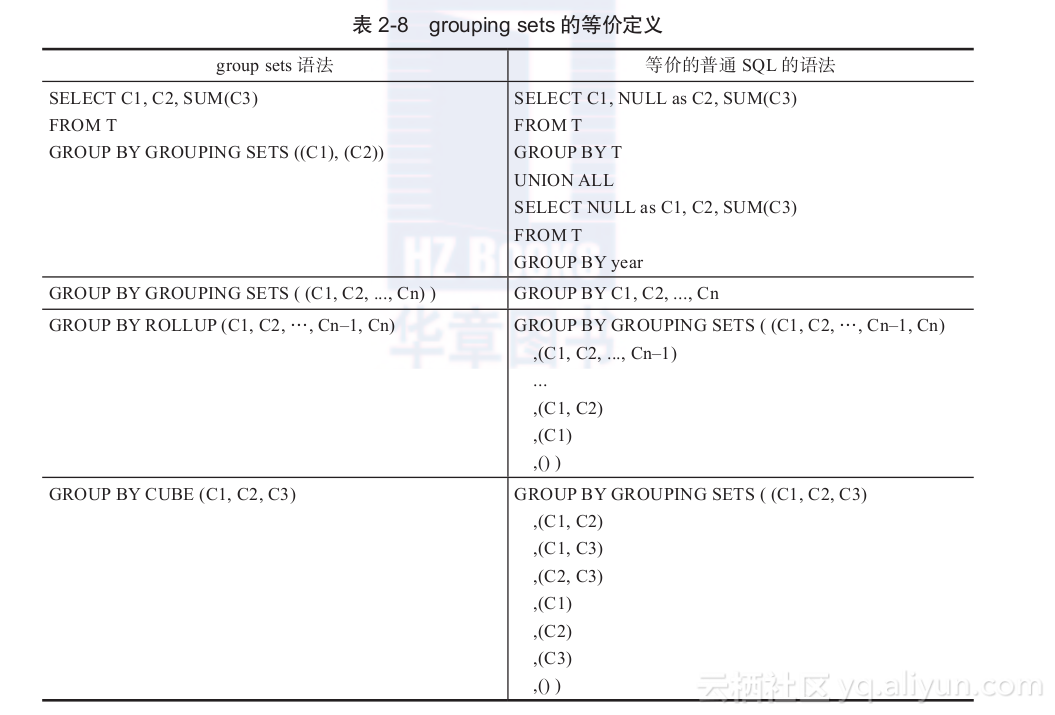
假设我们要统计大部门的人数,也要统计大部门中每个小组的人数,如下:
testDB=# select depname,depname2,count(1)
testDB-# from empsalary2
testDB-# group by grouping sets(depname,(depname,depname2))
testDB-# order by depname2;depname | depname2 | count
-----------+----------+-------develop | dev1 | 2develop | dev2 | 3personnel | per1 | 1personnel | per2 | 1sales | sal1 | 2sales | sal2 | 1develop | | 5sales | | 3personnel | | 2
(9 rows)
2.3.7 分区表
Greenplum支持分区表,具体的实现原理可查看“第4章数据字典详解”。
在创建表时,关于partition的语法如下:
[ PARTITION BY partition_type (column)[ SUBPARTITION BY partition_type (column) ] [ SUBPARTITION TEMPLATE ( template_spec ) ][...]( partition_spec ) | [ SUBPARTITION BY partition_type (column) ][...]( partition_spec [ ( subpartition_spec [(...)] ) ]
and partition_element is:DEFAULT PARTITION name| [PARTITION name] VALUES (list_value [,...] )| [PARTITION name] START ([datatype] 'start_value') [INCLUSIVE | EXCLUSIVE][ END ([datatype] 'end_value') [INCLUSIVE | EXCLUSIVE] ][ EVERY ([datatype] [number | INTERVAL] 'interval_value') ]| [PARTITION name] END ([datatype] 'end_value') [INCLUSIVE | EXCLUSIVE][ EVERY ([datatype] [number | INTERVAL] 'interval_value') ]
[ WITH ( partition_storage_parameter=value [, ... ] ) ]
[ TABLESPACE tablespace ]
按照时间分区,创建20111230~20120104号的分区:
create table public.test_partition_range(id numeric,name character varying(32),dw_end_date date)Distributed by (id)PARTITION BY range(dw_end_date)(PARTITION p20111230 START ('2011-12-30'::date) END ('2011-12-31'::date), PARTITION p20111231 START ('2011-12-31'::date) END ('2012-01-01'::date), PARTITION p20120101 START ('2012-01-01'::date) END ('2012-01-02'::date), PARTITION p20120102 START ('2012-01-02'::date) END ('2012-01-03'::date), PARTITION p20120103 START ('2012-01-03'::date) END ('2012-01-04'::date), PARTITION p20120104 START ('2012-01-04'::date) END ('2012-01-05'::date) );
使用Every,创建20111201~20111231的分区:
create table public.test_partition_every(id numeric,name character varying(32),dw_end_date date)Distributed by (id)PARTITION BY range(dw_end_date)(PARTITION p201112 START ('2011-12-1'::date) END ('2011-12-31'::date) every ('1 days'::interval));
创建list分区:
create table public.test_partition_list(member_id numeric,city character varying(32))Distributed by (member_id)PARTITION BY list(city)(partition guangzhou values('guangzhou'),partition hangzhou values('hangzhou'),partition shanghai values('shanghai'),partition beijing values('beijing'),DEFAULT PARTITION other_city);
下面是alter table对分区表特有的一些操作的语法:
where partition_action is one of:ALTER DEFAULT PARTITIONDROP DEFAULT PARTITION [IF EXISTS]DROP PARTITION [IF EXISTS] { partition_name | FOR (RANK(number)) | FOR (value) } [CASCADE]TRUNCATE DEFAULT PARTITIONTRUNCATE PARTITION { partition_name | FOR (RANK(number)) | FOR (value) }RENAME DEFAULT PARTITION TO new_partition_nameRENAME PARTITION { partition_name | FOR (RANK(number)) | FOR (value) } TO new_partition_nameADD DEFAULT PARTITION name [ ( subpartition_spec ) ]ADD PARTITION [name] partition_element[ ( subpartition_spec ) ]EXCHANGE PARTITION { partition_name | FOR (RANK(number)) | FOR (value) } WITH TABLE table_name [ WITH | WITHOUT VALIDATION ]EXCHANGE DEFAULT PARTITION WITH TABLE table_name[ WITH | WITHOUT VALIDATION ]SET SUBPARTITION TEMPLATE (subpartition_spec)SPLIT DEFAULT PARTITION { AT (list_value)| START([datatype] range_value) [INCLUSIVE | EXCLUSIVE] END([datatype] range_value) [INCLUSIVE | EXCLUSIVE] }[ INTO ( PARTITION new_partition_name, PARTITION default_partition_name ) ]SPLIT PARTITION { partition_name | FOR (RANK(number)) | FOR (value) } AT (value) [ INTO (PARTITION partition_name, PARTITION partition_name)]
接下来介绍对分区表进行的一些常用操作。
(1)新增分区
testDB=# alter table public. test_partition_every add partition p20120105_6 START ('2012-01-05'::date) END ('2012-01-07'::date);
NOTICE: CREATE TABLE will create partition "test_partition_1_1_prt_p20120105_6" for table "test_partition_1"
ALTER TABLE
(2)drop/truncate分区
删除p20120104分区:
alter table public. test_partition_every drop partition p20120105_6;
truncate p20120103分区:
alter table public. test_partition_every truncate partition p20120105_6;
(3)拆分分区
alter table public. test_partition_every split partition p20120105_6
at(('2012-01-06'::date)) into (PARTITION p20120105,PARTITION p20120106);
(4)交换分区
alter table public. test_partition_every exchange partition p20120102 with table public.test_one_partition;
2.3.8 外部表
Greenplum在数据加载上有一个明显的优势,就是支持数据并发加载,gpfdist就是并发加载的工具,在数据库中对应的就是外部表。
gpfdist的实现架构图如图2-20所示。
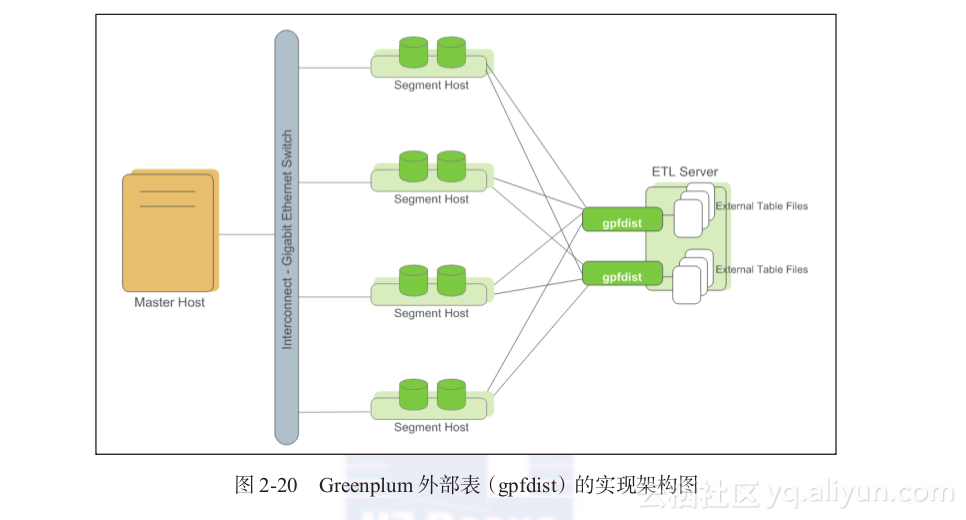
外部表,顾名思义就是一张表的数据是指向数据库之外的数据文件的。在Greenplum中,我们可以对一个外部表执行正常的DML操作,当读取数据的时候,数据库就从数据文件中加载数据。外部表支持在Segment上并发地高速从gpfdist导入数据,由于是直接从Segment上导入数据,所以效率非常的高。
创建外部表语法:
CREATE [READABLE] EXTERNAL TABLE table_name ( column_name data_type [, ...] | LIKE other_table )LOCATION ('file://seghost[:port]/path/file' [, ...])| ('gpfdist://filehost[:port]/file_pattern' [, ...])| ('gphdfs://hdfs_host[:port]/path/file')FORMAT 'TEXT' [( [HEADER][DELIMITER [AS] 'delimiter' | 'OFF'][NULL [AS] 'null string'][ESCAPE [AS] 'escape' | 'OFF'][NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'][FILL MISSING FIELDS] )]| 'CSV'[( [HEADER][QUOTE [AS] 'quote'] [DELIMITER [AS] 'delimiter'][NULL [AS] 'null string'][FORCE NOT NULL column [, ...]][ESCAPE [AS] 'escape'][NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'][FILL MISSING FIELDS] )][ ENCODING 'encoding' ][ [LOG ERRORS INTO error_table] SEGMENT REJECT LIMIT count [ROWS | PERCENT] ]
外部表需要指定gpfdist的IP和端口,还要有详细的目录地址,其中文件名支持通配符匹配。可以编写多个gpfdist的地址,但是不能超过总的Segment数,否则会报错。在创建外部表的时候可以指定分隔符、err表、指定允许出错的数据条数,以及源文件的字符编码等信息。
外部表还支持本地文本文件的导入,不过效率较低,不建议使用。外部表还支持HDFS的文件操作,这一部分将在6.3.3节介绍。
启动gpfdist及创建外部表的实际步骤如下:
1)首先在文件服务器(这里假设是10.20.151.11)上启动gpfdist的服务,指定文件目录及端口。
nohup $GPHOME/bin/gpfdist -d /home/admin -p 8888 > /tmp/gpfdist.log 2>&1 &
启动gpfdist后,在log中可以看到:
Serving HTTP on port 8888, directory /home/admin
说明程序已经成功启动了,端口是8888,这个服务只需要启动一次以后就不用启动了。nohup保证程序在Server端执行,当前会话关闭后,程序仍然正常运行。
nohup是UNIX/Linux中的一个命令,普通进程通过&符号放到后台运行,如果启动该程序的控制台退出,则该进程随即终止。nohup命令启动程序,则在控制台退出后,进程仍然继续运行,起到守护进程的作用。
2)准备好需要加载的数据文件,将其放在10.20.151.11机器的/home/admin/目录或该目录的子目录下,在Greenplum中创建对应的外部表:
create external table public.test001_ext(
id integer,
name varchar(128)
)
Location (
'gpfdist://10.20.151.11:8888/gpextdata/test001.txt'
)
Format 'TEXT' (delimiter as E'|' null as '' escape 'OFF')
Encoding 'GB18030' Log errors into public.test001_err segment reject limit 10 rows;
3)外部表查询及数据加载:
testDB=# select * from public.test001_ext;id | name
-----+-------100 | jack102 | tom103 | lily101 | david
(4 rows)testDB=# insert into test001 select * from test001_ext;
INSERT 0 4
Time: 345.514 ms
4)如果加载报错,报错的数据会被插入到err表中,并显示报错的详细信息:
testDB=# select * from public.test001_err;
-[ RECORD 1 ]-----------------------------------------------
cmdtime | 2012-01-11 23:42:35.242877+08
relname | test001_ext
filename | gpfdist://10.20.151.11:8888/gpextdata/test001.txt [/home/admin/gpextdata/test001.txt]
linenum | 5
bytenum |
errmsg | extra data after last expected column
rawdata | sdfdsf|sdfdsfdsf|sfd
rawbytes |
2.3.9 COPY命令
使用COPY命令可以实现将文件导出和导入,只不过要通过Master,效率没有外部表高,但是在数据量比较小的情况下,COPY命令比外部表要方便很多。
使用COPY命令的语法如下:
Command: COPY
Description: copy data between a file and a table
Syntax:
COPY table [(column [, ...])] FROM {'file' | STDIN}[ [WITH] [OIDS][HEADER][DELIMITER [ AS ] 'delimiter'][NULL [ AS ] 'null string'][ESCAPE [ AS ] 'escape' | 'OFF'][NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'][CSV [QUOTE [ AS ] 'quote'] [FORCE NOT NULL column [, ...]][FILL MISSING FIELDS][ [LOG ERRORS INTO error_table] [KEEP] SEGMENT REJECT LIMIT count [ROWS | PERCENT] ]COPY {table [(column [, ...])] | (query)} TO {'file' | STDOUT}[ [WITH] [OIDS][HEADER][DELIMITER [ AS ] 'delimiter'][NULL [ AS ] 'null string'][ESCAPE [ AS ] 'escape' | 'OFF'][CSV [QUOTE [ AS ] 'quote'] [FORCE QUOTE column [, ...]] ]
Greeplum 4.x中引入了可写外部表,在导出数据的时候可以用可写外部表并发导出,性能很好,但是在Greeplum 3.x版本中,导出数据只能通过COPY命令实现,数据在Master上汇总导出。
如果需要将数据远程导出到其他机器上,可以使用copy to stdout,远程执行psql连接到数据库上,然后通过管道将数据重定向成文件。
《Greenplum企业应用实战》一2.3 畅游Greenplum相关推荐
- 《Greenplum企业应用实战》一导读
前 言 为什么写作本书 阿里巴巴是国内最早使用Greenplum作为数据仓库计算中心的公司.从2009年到2012年Greenplum都是阿里巴巴B2B最重要的数据计算中心,它替换掉了之前的Oracl ...
- 读书笔记-Greenplum企业应用实战:简介
Greenplum是一家总部位于美国加利福尼亚,为全球大型企业用户提供新型企业级数据仓库(EDW).企业级数据云(EDC)和商务智能(BI)提供解决方案和咨询服务的公司. 重吞吐.高并发OLTP和重计 ...
- 读书笔记-Greenplum企业应用实战:Greenplum架构
Master和Segment其实都是一个单独的PostgreSQL数据库.每一个都有自己单独的一套元数据字典.Master节点一般叫主节点,Segment叫数据节点.Segment节点和Master节 ...
- 手把手搭建企业IT实战环境第三季:快速搭建SCCM1902服务器
手把手搭建企业IT实战环境第三季:快速搭建SCCM1902服务器 ©Lander Zhang 专注外企按需IT基础架构运维服务,IT Helpdesk 实战培训践行者 博客:https://blog. ...
- 企业Shell实战-MySQL分库分表备份脚本
本文来自 http://www.xuliangwei.com/xubusi/252.html 免费视频讲解见 http://edu.51cto.com/course/course_id-5064.ht ...
- Java EE企业应用实战
前 言 目前Java EE应用的开发方式大致可分为两种:一种以Spring.Hibernate等开源框架为基础,这就是通常所说的轻量级Java EE应用:另一种则以EJB 3+JPA为基础,也就是本书 ...
- 基于大数据技术之电视收视率企业项目实战(hadoop+Spark)
基于大数据技术之电视收视率企业项目实战(hadoop+Spark) 网盘地址:https://pan.baidu.com/s/1bEeSB1Y9nmjzctnbJMcBkg 密码:dohg 备用地址( ...
- Django企业开发实战--by胡阳,学习记录1127
标题2.2.3 多线程版的 Web Server 1.书中讲解了引入新的参数"import time以及time.sleep()"的例子,实际应用性并不强,除非有特定的处理界面需要 ...
- pythondjangoweb典型模块开发实战 pdf下载_胡阳《Django企业开发实战高效Python Web框架指南》PDF及代码...
Python社区中的框架Django 的定位是企业级开发框架,全功能 Web开发框架,少代码快速开发 Web应用.从开发速度还是上线后新功能的迭代,Django 都能很好地满足需求. 学完 Pytho ...
最新文章
- 复盘一次服务安装失败问题
- 判断h5是不是在小程序中
- java中位与运算符_Java中位运算符和的区别
- Spark学习之路(二)
- Oracle基于Linux平台的虚拟化与云计算战略
- 开源的javascript实现页面打印功能,兼容所有的浏览器(情况属实)
- Windows XP 服务说明
- 修理机器人基维斯_魔兽世界修理机器人沃尔特和移动邮箱怎么做
- 【解决办法】No module named 'ahocorasick'
- 算法学习-莫比乌斯反演
- SharePoint2013 2019性能及限制
- DLA实现跨地域、跨实例的多AnalyticDB读写访问 1
- [LeetCode] Best Time to Buy and Sell Stock 买卖股票的最佳时间
- linux top功能,[每日一题]说说Linux top命令的功能和用法
- pytorch---之指定GPU
- LoadRunner监控SQLServer
- send tcp char far_wemos D1 arduino项目实战1-TCP协议连接Tlink平台③
- Atitit 个人 企业 政府 等组织 财政收入分类与提升途径attilax总结 1.1. 国家财政收入分类 1 1.2. 企业收入分类 1 1.3. 个人收入分类 1 1.1.国家财政收入分类
- Linux添加keytool环境变量,linux keytool命令
- 什么是点对点?什么去中心化?