QCon演讲速递:异步处理在分布式系统中的优化作用
本文根据阿里巴巴技术保障研究员赵海平在2015年QCon全球软件开发大会(北京站)主题演讲整理而成。
\\
赵海平在Facebook工作8年期间,主要针对后端进行性能优化的工作,包括PHP的优化,memcache的优化,等等后端组件。偶然有机会跟阿里的朋友沟通他们遇到的问题,聊得比较深入,就发现虽然阿里是用Java的,但在大的系统优化方面遇到的问题,跟Facebook是很类似的,因此回国加入阿里,希望帮助阿里把整个系统优化得更好。计划第一步是先做整体的profiling系统,以找到性能的局部优化点;之后再进行一些大的架构优化,以及深入到JVM层面的优化。
\\
回国跟很多人沟通,感觉现在到了2015年,国内的朋友们基本上也都对分布式系统的架构相当了解了。今天的演讲就一个主题,就是分布式系统中异步处理的优化。
\\
单机时代的数据请求
\\
十五年前写软件是很简单的,一个Client对应一个DB Server,或者多个Client对应一个DB Server,每一个Client执行各自的服务。当时的讨论很多是说,这个东西要写在Client端还是写在DB Server端,流行的思路有两种:
\\
- 把DB Server写得很复杂,比如Oracle数据库,而Client端则写得很简单,只有调用返回\\t
- DB很简单,只有简单的表,而Client写得复杂。很多创业公司会这样做,因为他们对SQL不是很熟悉,但是很熟悉PHP。早期Facebook就是典型的代表\
大数据时代的数据请求
\\
单机时代随着两个趋势而逐渐成为历史。一个趋势是随着互联网的流行,越来越多的人开始上网使用Web服务,而且很多时候用户增长速度是非常快的,结果造成一台DB Server无法储存下所有用户的数据。第二个趋势是计算机能力越来越强,网络服务针对每一个用户要做的事情也变多了,比如Facebook不仅要保存一个用户的个人信息,还有他的关系链信息,他的使用习惯、点击习惯等,就造成一个用户的数据量也大大增加,仅仅访问一个DB Server就准备好一个页面变成了不可能的事情。
\\
这就带来了一个问题:针对多个DB Server的程序应该怎么写?
\\
针对这个问题也有两个思路:
\\
- 串行同步。先query DB1,返回res1,再使用res1做另一个DB的query,返回res2。这是在第二个Query依赖第一个Query结果的情况\\t
- 并行同步。针对DB1的query跟针对DB2的query同步进行。这是两个Query之间没有依赖关系的情况。Facebook早期专门写了一个并行处理的函数,用法是
ExecParallelQuery(conn1,Query1,conn2,Query2)\
这个时候的代码就比以前的代码更加复杂了,不过还是能实现需要实现的需求。但这时候带来了一个新的问题,就是等待。一个页面的加载可能需要调用不同的函数,而不同的函数可能是由不同的团队写的。比如获取朋友关系的函数getFriends把自己需要的数据用同步的方式获取了,但如果一个第三方开发者过来,则不仅要调用这个函数,还需要调用其他函数,这样其他函数的执行就需要等待前面这个getFriends函数返回了结果之后才能开始执行,就很慢了。
\\
要如何做到并行处理在代码层面很直观,在机器上的执行效率又好呢?
\\
异步的处理思路就是这么来的。
\\
所谓异步就是,我这个函数知道这里需要访问哪几个DB Server,但我先不着急去访问,而是先记录一下,等等看其他函数是不是也要访问这个DB,如果有的话,待会儿再一起去访问。异步处理的指令比如说是 conn.asyncExec(Query) ,这个可以立刻返回一个Future对象,意思就是“待会儿再去执行”。如果每个函数都返回这种Future对象,那么就可以根据这些Future对象来判断哪些请求没有依赖可以并行处理,哪些请求有依赖需要串行处理了。如此,不同的团队写出来的函数就不用一个等一个,而是可以在更高层面上互相合作。
\\
然而这又带来了一个问题,那就是异步处理的写法是具有传染性的。如果一个服务中有的函数写的异步,有的函数没写异步,就会造成有的函数返回了Future Object,有的函数返回了数值,导致无法执行。要实现异步,需要关联的所有函数都用异步的写法返回Future Object才可以。
\\
所以Facebook在转向异步处理的过程是非常痛苦的,一开始做了局部修改,再修改调用了局部修改过的函数的函数,所有调用的调用都要修改,最后全部改成了异步,只要有调用远程服务IO的操作都要改。每一个DB Query都拆分成两步,一个set request,一个receive response。这里的工作量很大,所以如果创业团队的话,最好是第一天就用正确的写法,就不会这么痛苦。
\\
所有函数改写后,每一个函数执行都会返回Future Object。那么异步处理的第一步,就是将这些Future Object形成一棵依赖树的结构,好像这样:
\\
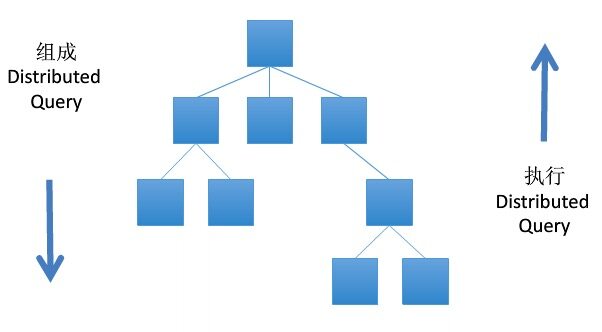
\\
这里每个节点都是一个Future对象,每一个Future对象有两种状态,一个是等待执行,一个是完成执行。同级的节点是没有依赖关系的,可以并行执行;上下节点是有依赖关系的,需要串行执行,先执行下层再执行上层。
\\
树结构形成后,从下到上执行,直到最上面的top parent节点被执行进入完成执行的状态,就是完成,比如一个页面加载完毕。
\\
所以异步处理之后有一个很有意思的情况,那就是PHP这个语言已经跟以前不同了,不再是一上来就是执行,而是一上来先lazy一下,看清楚所有的Query之后再执行。
\\
异步处理还需要解决的问题
\\
到目前为止,这样做异步处理似乎已经是足够好的优化,但实际上还有问题。看看下面这个例子。
\\
比如我们现在有两个查询需求。一个是查询你在淘宝上买过东西的朋友,另一个是查询你在淘宝上买过保时捷的朋友。常理来说,我们会先想到查询你在淘宝上的朋友,再进行另一个条件的查询,比如这样:
\\
\IdList friends = waitFor(getFriends(myId));\yield return getTaoBaoBuyers(friends);\
\\
但是对于保时捷这个查询而言,这是不对的,因为淘宝上买保时捷的人是很少的,可能就一两个,而淘宝上的好友数可能有上百。因此保时捷的查询应该是这个次序比较优化:
\\
\IdList buyers = waitFor(getPorscheBuyer());\yield return getFriends(buyers);\
\\
这个次序应该如何决定?实际上不应该在写程序的时候决定,因为写程序的时候是无法避免有先后顺序的——编辑器只能一行一行的写代码,但是机器执行却无需管这个。所以更好的方法应该是在执行代码之前再加入一个phase。
\\
其实传统数据库的cardinality(基数)功能已经解决了这个问题。你在DB query里面使用 INNER JOIN 这个指令,其实DB已经能够预判哪一个表给出的row会比较少,从而以更优化的次序去执行。但现在我们用的编程语言,无论是PHP,Java,Python还是C/C++,并没有考虑这个问题。有人会开很多线程来解决这个问题,但这不是最佳方案,因为在Linux系统里,你的线程数要是上了200-300,就会有很大的overhead。
\\
代码执行的次序,这是一个。另外最近几年还有一个流行的优化思路,就是上memcache。我们有时候会看到程序员把他自己的函数放进了memcache,相当于是依赖树的中间的一个节点,我就问他为什么要把他这个Class放入memcache,他可能会说,他觉得这个节点和这个节点的child被调用的次数多。我觉得这可能不是特别理想的。你今天觉得这个Class被调用的多,可以放进memcache,但明天是不是会有更重要的Class会更值得放进memcache,于是你又要把memcache的资源让给这个新的Class?如果你放入memcache的Class并不是最重要的,这就相当于真正优化的可能性被拿走了。
\\
如何让异步执行的更好?
\\
哪个query先执行,哪个query后执行,不应该是在编码阶段来做的。哪个Class该进memcache,哪个Class该出memcache,也不应该在编码阶段来做。应该有一个中间的阶段,专门进行这种调度工作,然而到目前为止,还没有公司能够做到,因为没有合适的语言。
\\
异步处理在分布式系统中怎样做有更好的优化作用,我们需要更多的思考。希望大家能够把计算机当作科学去思考,而不仅仅是工程应用。我们现在看十几年前,对单机是非常了解了,那么未来过了五年十年再回来看,可能对分布式系统也会了解的比现在更多很多,可能给分布式系统写程序也会变得跟给单机写程序一样简单。当然这就需要更合适的工具语言去给大家提供这种异步的便利。是不是会有Haskell那样lazy的方式从系统层面解决这个问题?希望跟大家一起思考探讨。
\\
讲师简介
\\
赵海平,阿里巴巴技术保障研究员,从小酷爱编程,多次获得中学生计算机竞赛的各种奖项,1987年以河北省高考状元的优异成绩进入北京大学生物系,又在美国纽约大学获得分子生物学硕士,其后放弃博士学位,进入普林斯顿获得计算机科学硕士,曾就职于微软公司。2007年加入只有不到50个软件工程师的Facebook,致力于软件性能和架构分析,在此期间创建了HipHop项目,重新编写和实现PHP语言,使其速度提高5到6倍,为公司节约数十亿美元。HipHop项目之后,致力于“用异步处理来优化分布式系统”的设计理念中,并为此做了多项分布式数据库的优化研究,在PHP语言中加入了yield和generator的新功能,来帮助日趋复杂的Facebook网页设计。2015年3月回国,加入阿里巴巴技术保障部,将重点攻克阿里在软件性能以及Java使用过程中遇到的技术问题。
\\
演讲slides下载地址
QCon演讲速递:异步处理在分布式系统中的优化作用相关推荐
- 异步处理在分布式系统中的优化作用
本文根据阿里巴巴技术保障研究员赵海平在2015年QCon全球软件开发大会(北京站)主题演讲整理而成. 赵海平在Facebook工作8年期间,主要针对后端进行性能优化的工作,包括PHP的优化,memca ...
- 《异步处理在分布式系统中的优化作用》学习笔记
原文地址:http://www.infoq.com/cn/presentations/optimization-of-asynchronous-processing-in-distributed-sy ...
- 英特尔台北信息技术峰会2008主题演讲速递 II
21日是台北英特尔信息技术峰会的第二天,今天主题演讲嘉宾有移动平台部门的总经理Mooly Eden,其中介绍了英特尔迅驰的下一代平台Calpella的一些细节,Calpella是基于45nm的base ...
- 中邮速递IPO初审 引爆电商物流大战
近日有消息爆出中国邮政速递通过IPO初审,今年有望登录上海证券交易所,成为国内第一家IPO的快递公司.这一消息引爆了物流行业与电商行业,近年来中国速递一直在民营与外资的夹击下艰难的生长,如果中有速递I ...
- QCon速递:Xen漏洞热补丁修复、异地双活、ODPS新功能与金融互联网
QCon速递:Xen漏洞热补丁修复.异地双活.ODPS新功能与金融互联网
- 【新书速递】重磅!混沌工程权威指南
编辑推荐 作为一名工程师,混沌工程是开始应对系统复杂性的既可行又有效的方法.混沌工程是对系统的容错设计进行验证,保障系统稳定性的新方法! 混沌工程这门学科既成熟得可以沉淀有价值的文献和常见的行业 ...
- mysql创建只读权限用户_新品速递 | Harbor 修复权限提升漏洞,MySQL Plus 支持密码强度校验以及审计功能...
为了更好的服务 QingCloud 用户,我们推出了『产品速递』栏目,帮助大家梳理青小云家最近上线的新功能和新产品,供大家从中快速选择,得以应用. 1 Harbor On QingCloud 升级至 ...
- arXiv每日推荐-5.16:语音/音频每日论文速递
同步公众号(arXiv每日学术速递) [1] Semi-supervised Neural Chord Estimation Based on a Variational Autoencoder wi ...
- 【新书速递】从原理、架构、案例三个维度深度剖析分布式数据库
分布式数据库是分布式计算与数据库结合的产物.分布式数据库的概念早就存在,但是直到最近才真正引起产业界的高度重视.这得益于互联网和云计算技术的高速发展与广泛应用. 以"国家政务服务平台&quo ...
最新文章
- AI一分钟 | 腾讯将成立机器人实验室;机器翻译重大突破:中英翻译已达人类水平
- 学懂分析,玩转大数据
- Netty堆外内存泄露排查与总结
- WinAPI: waveOutGetPlaybackRate - 获取输出设备当前的播放速度设置(默认速度值的倍数)...
- linux socket bind 内核详解,Socket与系统调用深度分析(示例代码)
- mysql5.6.36源码安装_CentOS 7下rpm安装MySQL 5.6.36
- 大数据发展火爆,云计算平台主打安全至上
- MySQL重要但容易被忽略_MySQL自定义函数存储过程
- Atitit gui界面ui技术发展史与未来趋势
- 电源管理IC临近爆发,详解四大市场趋势
- 借助 Finder 的Jitouch插件实现 Chrome 三指在 New Tab 中打开链接
- IDEA的Translation翻译插件失效
- 18种抗癌果蔬排行榜
- css 两个元素重叠,css元素如何重叠?
- Python入门基础-六、案例3 基础代谢率(BMR)计算器 #Python中常用的数值类型#字符串分割与格式化输出#异常处理机制
- 【读书笔记】《终身成长》——热爱挑战相信努力
- IRF堆叠(虚拟化)配置
- C# dll ushort*的处理方法
- 毕竟西湖六月中,风光不与四时同。接天莲叶无穷碧,映日荷花别样红
- Gradle-dependencies介绍