Transformer、Bert、GPT简介
Transformer
首先看一下trasformer结构
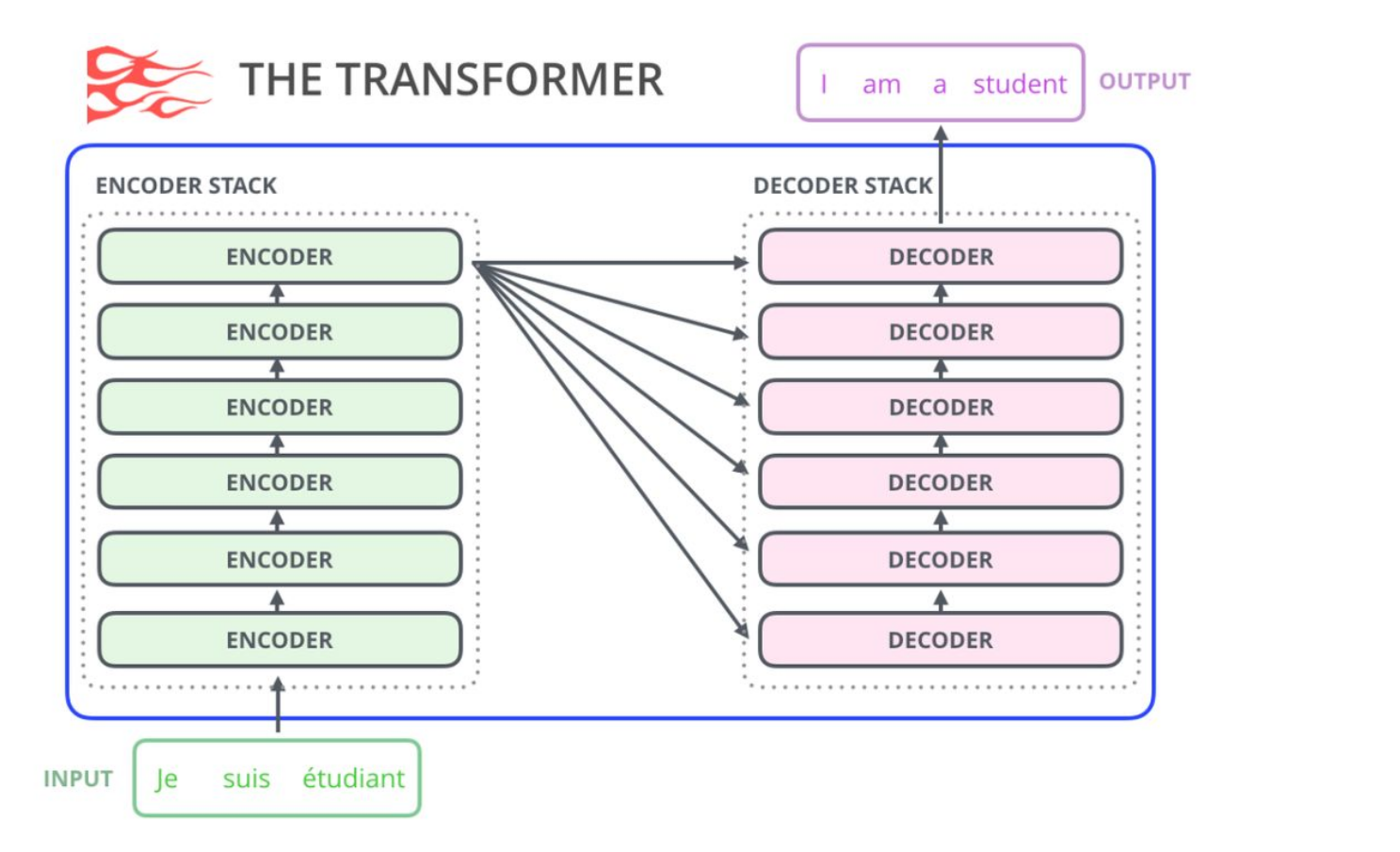
简单回顾一下,encoder将token编码处理,得到embedding.然后送入decoder。decoder的input是前一个时间点产生的output。
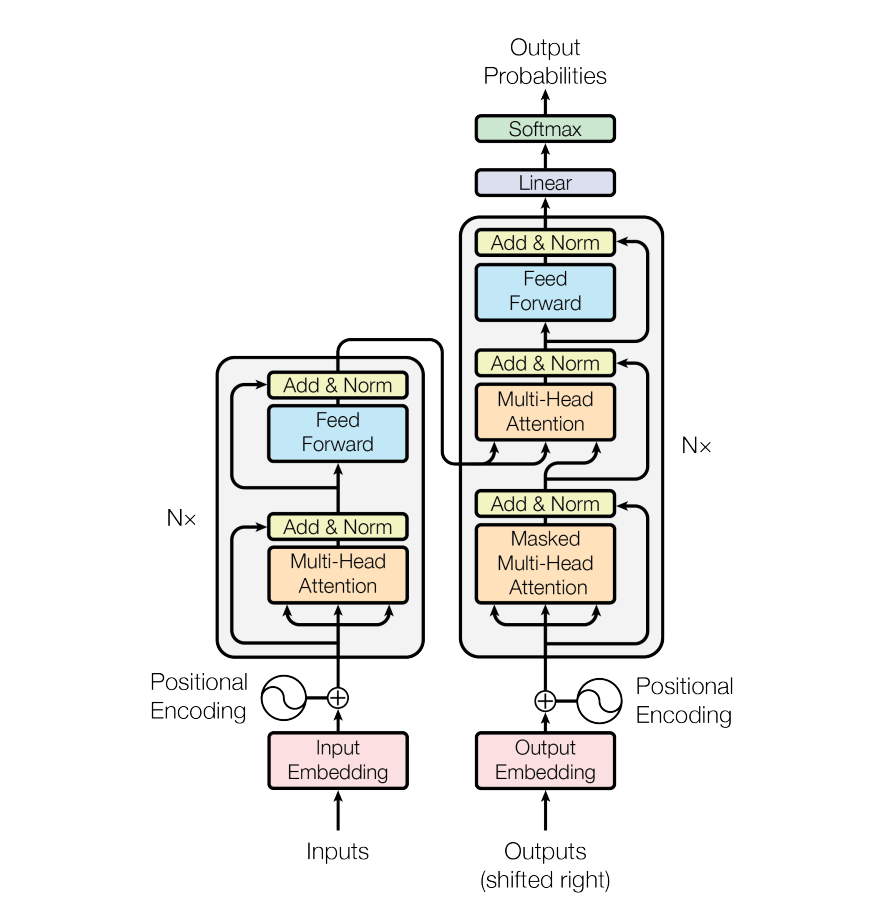
Masked Multi-Head Attention,Masked的意思是,在做self-attention的时候,这个decoder只会attend到已经产生的sequence(这个sequence长度和encoder的输出长度不一样),因为没有产生的部分无法做attention
一个有趣的动画:
![]()
Encode:所有word两两之间做attention,有三个attention layer
Decode:不只 attend input 也会attend 之前已经输出的部分
损失函数:
Q&A
q1:decoder的输入长度为什么和encoder的不一样,decoder的输入是什么?
训练时是GT+Positional Embedding。没有Positional Embedding的Attention mask只能做到看到当前位置之前的所有信息,而做不到有序
预测时是(1)起始符以及后续。
以问答为例,训练阶段我是知道decoder最终输出是“I am fine”,所以decoder的【输入】在训练阶段分别为(1)起始符(2)起始符+I(3)起始符+I+am(4)起始符+I+am+fine,因为我们知道正确的最终输出是什么,所以这4个阶段是可以并行执行的.
但是预测阶段,我们是不知道decoder的输出的,所以我们只能decoder的输入只能逐步进行(1)起始符(2)起始符+decoder预测单词1(3)起始符+decoder预测单词1+decoder预测单词2…,这样
BERT
结构:
BERT只使用了transformer的encoder部分.
input: token embedding +segment embedding + position embedding
会将输入的自然语言句子通过WordPiece embeddings来转化为token序列。之所以会有segment embedding是因为bert会做NSP(next sentense prediction)任务,判断两个句子间的关系,需要sentense级别的信息
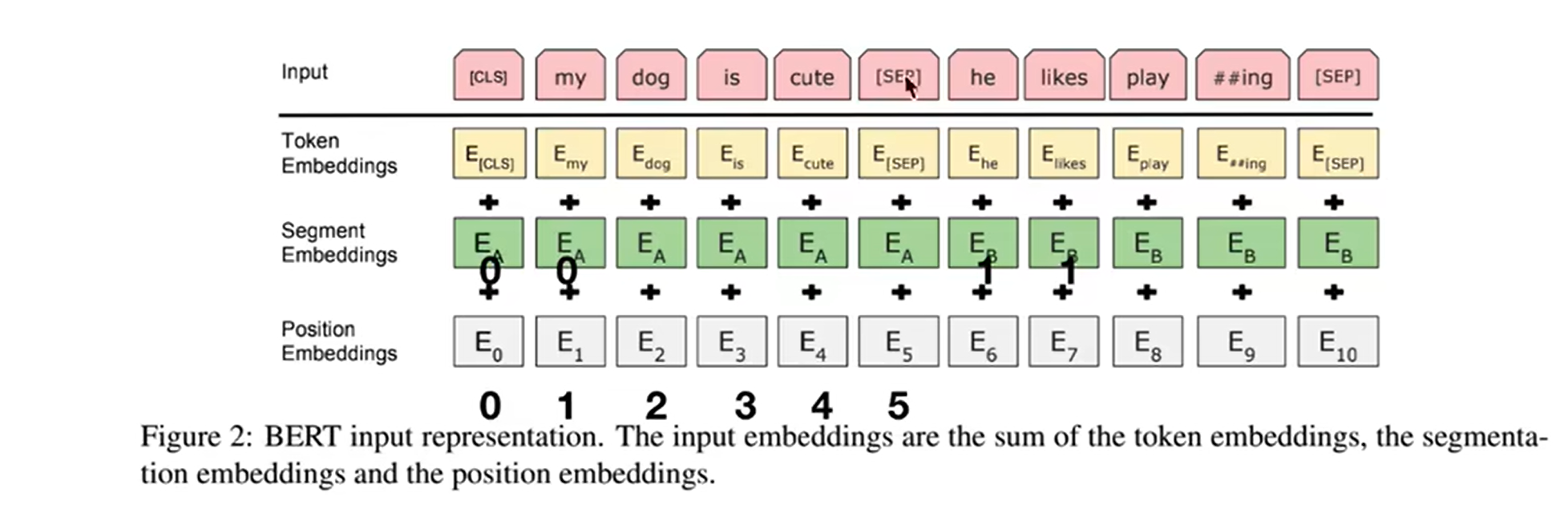
output:为预测这些被遮盖掉的token,被mask掉的词将会被输入到一个softmax分类器中,分类器输出的维度对应词典的大小。
方法:
AE:auto encoder

损失函数为:负对数似然函数 + 二分类损失函数
具体的损失函数参看BERT损失函数
Q&A
q1:BERT怎么实现双向的:
对比GPT,BERT使用了双向self-attention架构,而GPT使用的是受限的self-attention, 即限制每个token只能attend到其左边的token。
为了能够双向地训练语言模型,BERT的做法是简单地随机mask掉一定比例的输入token(这些token被替换成[MASK]这个特殊token),然后
GPT
GPT 预训练的方式和传统的语言模型一样,通过上文,预测下一个单词;GPT 预训练的方式是使用 Mask LM。
例如给定一个句子 [u1, u2, …, un],GPT 在预测单词 ui 的时候只会利用 [u1, u2, …, u(i-1)] 的信息,而 BERT 会同时利用 [u1, u2, …, u(i-1), u(i+1), …, un] 的信息
结构
GPT只使用了transformer的decoder部分,并去掉了第二个multi self attention layer
方法:
AR:auto regressive

损失函数为:给定一个无标签的序列 u = { u 1 , u 2 , ⋯ u i } u= \{u_1, u_2 , \cdots u_i \} u={u1,u2,⋯ui},语言模型的优化目标是最大化下面的似然值:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) L1(U)=i∑logP(ui∣ui−k,…,ui−1;Θ)
Q&A
q1:GPT是一个单词一个单词的预测概率嘛?
是的。
Transformer、Bert、GPT简介相关推荐
- transformer bert GPT(未完)
原文标题:⼤规模⽆监督预训练语⾔模型与应⽤(中) 文章目录 1 transformer 1.1 encoder部分 1.1.1 Attention定义 1.1.2 Multi-head Attenti ...
- 快速串联 RNN / LSTM / Attention / transformer / BERT / GPT
参考: 李宏毅2021/2022春机器学习课程 王树森 RNN & Transformer 教程 Transformer 详解 文章目录 0. 背景:序列数据及相关任务 1. 早期序列模型 1 ...
- 【莫烦Python】机器要说话 NLP 自然语言处理教程 W2V Transformer BERT Seq2Seq GPT 笔记
[莫烦Python]机器要说话 NLP 自然语言处理教程 W2V Transformer BERT Seq2Seq GPT 笔记 教程与代码地址 P1 NLP行业大佬采访 P2 NLP简介 P3 1. ...
- 让chatGPT使用Tensor flow Keras组装Bert,GPT,Transformer
让chatGPT使用Tensor flow Keras组装Bert,GPT,Transformer implement Transformer Model by Tensor flow Keras i ...
- 热门的模型跨界,Transformer、GPT做CV任务一文大盘点
作者|陈萍 来源|机器之心 可能大家心里都有一种错误认知,做自然语言处理任务的模型不能够用来进行计算机视觉任务.其实不然,现阶段已出现好多研究,它们通过算法的改进,将在 NLP 领域表现良好的模型,如 ...
- bert模型简介、transformers中bert模型源码阅读、分类任务实战和难点总结
bert模型简介.transformers中bert模型源码阅读.分类任务实战和难点总结:https://blog.csdn.net/HUSTHY/article/details/105882989 ...
- 【李宏毅2020 ML/DL】P25 ELMO, BERT, GPT
我已经有两年 ML 经历,这系列课主要用来查缺补漏,会记录一些细节的.自己不知道的东西. 已经有人记了笔记(很用心,强烈推荐):https://github.com/Sakura-gh/ML-note ...
- 【自然语言处理】BERT GPT
BERT & GPT 近年来,随着大规模预训练语言模型的发展,自然语言处理领域发生了巨大变革.BERT 和 GPT 是其中最流行且最有影响力的两种模型.在本篇博客中,我们将讨论 BERT 和 ...
- 文本表示(一)—— word2vec(skip-gram CBOW) glove, transformer, BERT
文本离散表示 1. one-hot 简单说,就是用一个词典维度的向量来表示词语,当前词语位置为1,其余位置为0. 例如 vocabulary = ['胡萝卜' , '兔子', '猕猴桃'], 采用三维 ...
- 深度学习机器学习面试题——自然语言处理NLP,transformer,BERT,RNN,LSTM
深度学习机器学习面试题--自然语言处理NLP,transformer,BERT,RNN,LSTM 提示:互联网大厂常考的深度学习基础知识 LSTM与Transformer的区别 讲一下Bert原理,B ...
最新文章
- 双十一风险暗藏危机 网络狂欢需谨慎
- maven-eclipse 中index.html页面乱码
- SQL server 2012 如何取上个月的最后一天
- sdk编程改变static控件字体和颜色
- 牛客题霸 [最长公共子序列] C++题解/答案
- 重装Nodejs后,webstorm代码报错问题
- Python 运算符重载
- Fegin拦截器解决各微服务之间数据下沉
- linux free 物理内存,Linux free显示系统内存使用
- Spring AOP动态代理的两种实现方式
- 51单片机英文缩写全称
- 运维团队(OPS)与技术团队有效沟通配合探讨
- 编译原理(龙书第二版)--怎么求FOLLOW集
- linux symlink 函数,详解C语言中symlink()函数和readlink()函数的使用
- js写的 几款时间轴
- windos下 elasticksearch7.13安装踩坑记
- 隐马尔可夫模型HMM学习笔记
- fiddler-2-5分钟学会手机端抓包
- 模型放到gpu上训练
- 魔兽争霸地图修改(三国列传,又名:三国列传之真策略无双3.0 A)