MapReduce理解-深入理解MapReduce
前面的几篇博客主要介绍了Hadoop的存储HDFS,接下来几篇博客主要介绍Hadoop的计算框架MapReduce。本片博客主要讲解MapReduce框架的具体执行流程,以及shuffle过程,当然这方面的技术博客已经特别多而且都写得很优秀,我写本篇博客之前也有过相关阅读,受益匪浅。对一些博客和资料的参考都会才博客下方参考资料中列出。
MapReduce理解
- MapRedeuce,我们可以把它分开来理解:
- 映射(Mapping) :对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping(这里体现了移动计算而不是移动数据);
- 化简(Reducing):遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
计算框架
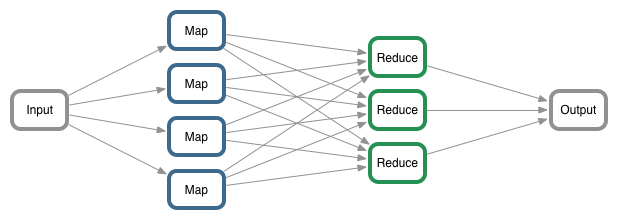 一个简单的MapReduce执行流程
一个简单的MapReduce执行流程
简单理解,MapReduce计算框架:把需要计算的东西放入到MapReduce中进行计算,然后返回一个我们期望的结果。所以首先我们需要一个来源(需要计算的东西)即输入(input),然后MapReduce操作这个输入(input),通过定义好的计算模型,最后得到一个(期望的结果)输出(output)。
计算模型
 Map和Reduce
Map和Reduce
在这里我们主要讨论的是MapReduce计算模型:在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
实例代码
- 以MapReduce统计单词次数为例(伪代码),主要四个模块来讲解,如上图计算框架:
Input,数据读入
1 2 3 4 5 6
// 设置数据输入来源 FileInputFormat.setInputPaths(job, args[0]); FileInputFormat.setInputDirRecursive(job, true); //递归 job.setInputFormatClass(TextInputFormat.class); //设置输入格式 //TextInputFormat,一种默认的文本输入格式,Mapper一次读取文本中的一行数据。
使用Mapper计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
//设置Job的Mapper计算类和K2、V2类型 job.setMapperClass(WordCountMapper.class); //1.设置Mapper类 job.setMapOutputKeyClass(Text.class); //设置Mapper输出Key的类型 job.setMapOutputValueClass(LongWritable.class);//设置Mapper输出Value的类型 //WordCountMapper类 /** * 自定义的Map 需要继承Mapper * K1 : 行序号 * V1 : 行信息 * K2 : 单词 * V2 : 次数 */ public static class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> { Text k2 = new Text() ; LongWritable v2 = new LongWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1. 获取行信息 String line = value.toString(); //2. 获取行的所用单词 String[] words = line.split("\t");//这里假设一行文本单词分隔符为"\t" for (String word : words) { k2.set(word.getBytes()) ; //设置键 v2.set(1); //设置值 context.write(k2,v2); } } }使用Reducer合并计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
//设置Job的Reducer计算类和K3、V3类型 job.setReducerClass(WordCountReducer.class); //自定义的Reducer类 job.setOutputKeyClass(Text.class); //输出Key类型 job.setOutputValueClass(LongWritable.class); //输出Value类型 //WordCountReducer 类 /** * 自定义的Reduce 需要继承Reducer * K2 : 字符串 * V3 : 次数(分组) * K3 : 字符串 * V3 : 次数(统计总的) */ public static class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable>{ LongWritable v3 = new LongWritable() ; int sum = 0 ; @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { sum = 0 ; for (LongWritable value : values) { sum +=value.get() ; } v3.set(sum); context.write( key , v3 ); } }Output,数据写出
1
FileOutputFormat.setOutputPath(job, new Path(args[1]));
运行机制
- 下面从两个角度来讲解MapReduce的运行机制:
- 各个角色实体;
- 运行的时间先后顺序。
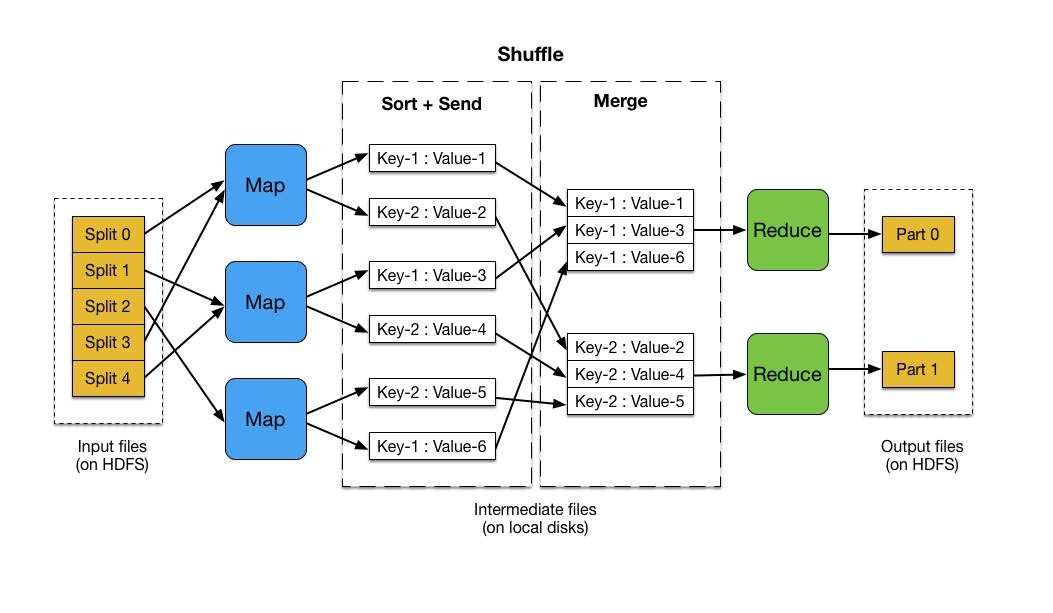 MapReduce计算模型的运行机制
MapReduce计算模型的运行机制
各个角色实体
程序运行时过程设计到的一个角色实体
1.1. Client:编写mapreduce程序,配置作业,提交作业的客户端 ;
1.2. ResourceManager:集群中的资源分配管理 ;
1.3. NodeManager:启动和监管各自节点上的计算资源 ;
1.4. ApplicationMaster:每个程序对应一个AM,负责程序的任务调度,本身也是运行在NM的Container中 ;
1.5. HDFS:分布式文件系统,保存作业的数据、配置信息等等。客户端提交Job
2.1. 客户端编写好Job后,调用Job实例的Submit()或者waitForCompletion()方法提交作业;
2.2. 客户端向ResourceManager请求分配一个Application ID,客户端会对程序的输出、输入路径进行检查,如果没有问题,进行作业输入分片的计算。Job提交到ResourceManager
3.1. 将作业运行所需要的资源拷贝到HDFS中(jar包、配置文件和计算出来的输入分片信息等);
3.2. 调用ResourceManager的submitApplication方法将作业提交到ResourceManager。给作业分配ApplicationMaster
4.1. ResourceManager收到submitApplication方法的调用之后会命令一个NodeManager启动一个Container ;
4.2. 在该NodeManager的Container上启动管理该作业的ApplicationMaster进程。ApplicationMaster初始化作业
5.1. ApplicationMaster对作业进行初始化操作;
5.2. ApplicationMaster从HDFS中获得输入分片信息(map、reduce任务数)任务分配
6.1. ApplicationMaster为其每个map和reduce任务向RM请求计算资源;
6.2. map任务优先于reduce任,map数据优先考虑本地化的数据。任务执行,在 Container 上启动任务(通过YarnChild进程来运行),执行map/reduce任务。
时间先后顺序
输入分片(input split)
每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为128M,可以设置)为一个分片。map输出的结果会暂且放在一个环形内存缓冲区中(默认mapreduce.task.io.sort.mb=100M),当该缓冲区快要溢出时(默认mapreduce.map.sort.spill.percent=0.8),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件;map阶段:由我们自己编写,最后调用 context.write(…);
partition分区阶段
3.1. 在map中调用 context.write(k2,v2)方法输出,该方法会立刻调用 Partitioner类对数据进行分区,一个分区对应一个 reduce task。
3.2. 默认的分区实现类是 HashPartitioner ,根据k2的哈希值 % numReduceTasks,可能出现“数据倾斜”现象。
3.3. 可以自定义 partition ,调用 job.setPartitioner(…)自己定义分区函数。combiner合并阶段:将属于同一个reduce处理的输出结果进行合并操作
4.1. 是可选的;
4.2. 目的有三个:1.减少Key-Value对;2.减少网络传输;3.减少Reduce的处理。shuffle阶段:即Map和Reduce中间的这个过程
5.1. 首先 map 在做输出时候会在内存里开启一个环形内存缓冲区,专门用来做输出,同时map还会启动一个守护线程;
5.2. 如缓冲区的内存达到了阈值的80%,守护线程就会把内容写到磁盘上,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的数据;
5.3. 写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作;
5.4. 写入磁盘时会有个排序操作,如果定义了combiner函数,那么排序前还会执行combiner操作;
5.5. 每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并这些输出文件,这个过程里还会有一个Partitioner操作(如上)
5.6. 最后 reduce 就是合并map输出文件,Partitioner会找到对应的map输出文件,然后进行复制操作,复制操作时reduce会开启几个复制线程,这些线程默认个数是5个(可修改),这个复制过程和map写入磁盘过程类似,也有阈值和内存大小,阈值一样可以在配置文件里配置,而内存大小是直接使用reduce的tasktracker的内存大小,复制时候reduce还会进行排序操作和合并文件操作,这些操作完了就会进行reduce计算了。reduce阶段:由我们自己编写,最终结果存储在hdfs上的。
http://www.cnblogs.com/sharpxiajun/p/3151395.html
http://blog.csdn.net/qq1010885678/article/details/51337323
http://blog.csdn.net/u014313009/article/details/38072269 (Shuffle阶段讲的很好)
MapReduce理解-深入理解MapReduce相关推荐
- MapReduce优劣,理解MapReduce与Hadoop
MapReduce是一种计算模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程 ...
- 大数据培训之核心知识点Hbase、Hive、Spark和MapReduce的概念理解、特点及机制等
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- mapreduce将key相同的value结合在一起_个人理解Hadoop中MapReduce
MapReduce 是什么? MapReduce是一种分布式离线计算框架 主要分为MapTask 和ReduceTask两部分 主要用于大规模的数据集(大于1T)的并行运算 首先我先讲解下MapRed ...
- 学习笔记Hadoop(十四)—— MapReduce开发入门(2)—— MapReduce API介绍、MapReduce实例
四.MapReduce API介绍 一般MapReduce都是由Mapper, Reducer 及main 函数组成. Mapper程序一般完成键值对映射操作; Reducer 程序一般完成键值对聚合 ...
- MapReduce学习1:MapReduce基本概念
1 MapReduce概述 1.1 MapReduce定义 1.2 MapReduce优缺点 1.2.1 MapReduce优缺点 1.2.2 MapReduce的缺点 3 MapReduce核心思想 ...
- 对ORBslam2前端ORBextractor点提取的理解(理解每行代码在干啥)
前言:受高博的启发,想自己写一个完整的slam,不知如何动手,想到将orbslam2拆分,按照自己的理解组装一个slam(先整出个视觉里程计吧),所以开始研究orbslam2前端的代码,在slam14 ...
- 理解逆矩阵 理解单位矩阵
目录 理解逆矩阵 理解单位矩阵 理解逆矩阵 a/b(当b不为0的时候有意义):同理你理解逆矩阵就是与矩阵成导数关系. 那么行列式的值不为0,就说明逆矩阵存在,这样就合情合理了. 首先,我们先来看看这个 ...
- MapReduce之OutputFormat理解
一 OutputFormat作用 1校验job中指定输出路径是否存在 2将结果写入输出文件 二 OutputFormat的实现 2.1DBOutputFormat: 发送Reduce结果到SQL表中 ...
- MapReduce之InputFormat理解
一 InputFormat主要作用: #验证job的输入规范 #对输入的文件进行切分,形成多个InputSplit文件,每一个InputSplit对应着一个map任务 #创建RecordReader, ...
最新文章
- 7.Odoo产品分析 (二) – 商业板块(3) –CRM(1)
- linux使用X11捕捉鼠标,如何在Linux下合法地以编程方式捕获第二个鼠标或轨迹球,X?...
- the largest issue in management
- GO语言eclipse开发环境搭建
- JavaScript入门(part3)--变量
- 互联网日报 | 3月22日 星期一 | 苹果iMac Pro全球下架;知乎更新上市招股书;字节跳动成立朝夕光年奇想基金...
- Windows服务器管理(3)——IIS服务器误删了Default Web Site 网站 解决方法
- Adwonder笔记
- hackmyvm之warez
- 斐讯N1纯净精简/夏杰语音/支持投屏-线刷固件及教程202208
- 计算机硬件认识与了解,计算机硬件认识实习报告参考
- IAR 点击下载调试按钮 软件崩溃
- 老牛知点所以然-Qt安装后一行命令解决:libxcb-util.so.1 => not found
- Oracle 变量绑定与变量窥视合集系列五
- 飞浆领航团AI达人创造营第01课|让人拍案叫绝的创意都是如何诞生的?
- JavaScript图片轮播图
- 一文总结深度学习的12张思维导图
- 查看网站历史记录的2种办法,怎样查看网站历史记录?
- 16个很好的在线教育网站
- rg1 蓝光危害rg0_LED蓝光危害评估的最新标准IEC/TR 62778:2014