Oracle 数据库萌新经验小结
刚出道的时候,学的就是oracle数据库,后期兴趣所向,转行java,
翻出以前的总结笔记,拿来分享给大家有点小多,想直接看文档的小伙伴可以去网盘下载(文档里有格式和目录,好看点):
链接:https://pan.baidu.com/s/1t_ybXIbRCCJFZAmqQ6lx-Q
提取码:o18i
常用查询及操作
复制表结构和数据
- 复制表结构及数据到新表:CREATE TABLE 新表 SELECT * FROM 旧表
- 只复制表结构到新表:CREATE TABLE 新表 SELECT * FROM 旧表 WHERE 1=2
即:让WHERE条件不成立.
方法二:CREATE TABLE 新表 LIKE 旧表
3.复制旧表的数据到新表(假设两个表结构一样):
INSERT INTO 新表 SELECT * FROM 旧表
4.复制旧表的数据到新表(假设两个表结构不一样)
INSERT INTO 新表(字段1,字段2,.......) SELECT 字段1,字段2,...... FROM 旧表
insert into b(a, b, c) select d,e,f from b;
说明:复制表(只复制结构,源表名:a 新表名:b)
SQL: select * into b from a where 1<>1
说明:拷贝表(拷贝数据,源表名:a 目标表名:b)
SQL: insert into b(a, b, c) select d,e,f from b;
说明:显示文章、提交人和最后回复时间
SQL: select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
说明:外连接查询(表名1:a 表名2:b)
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
说明:日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f开始时间,getdate())>5
说明:两张关联表,删除主表中已经在副表中没有的信息
SQL:delete from info where not exists ( select * from infobz where info.infid=infobz.infid )
常用嵌套查询
- 每个部门前几名提取出来
select e.department,e.salary from (select department, salary,row_number() over (partition by department order by salary desc) rn from employee) e where e.rn<=3;
- 部门表和员工表,获取各个部门的最大工资?
Select deptno, max(sal) from 员工表 left outer join 部门表 on 员工表.deptno=部门表.deptno group by 部门表.deptno;
Select emp.deptno, Max(sal) From emp Left Join dept On dept.deptno=emp.deptno Group By emp.deptno
- 如何查找和删除表中重复数据:
Select * from A not exists(select B.id from B where A.id=B.id);
- 请写一段SQL,找出在2011年1月1日,客户地址发生变更的客户,并将这些客户2011.1.1的地址和电话显示出来,显示如下(8分)
|
客户编号 |
更新日期 |
家庭地址 |
家庭电话 |
|
3109026058996 |
XXXXXXXX |
XXXXXX |
XXXXX |
Select Party_Id 客户编号
,'2011-01-01' 更新日期
, max(case when Addr_Type2_Cd='02' then Addr_Line1 end) 家庭地址//取到最后更新的那一条记录
, max(case when Addr_Type_Cd='01' then Addr_Line1 end) 家庭电话
From T06_ADDRESS
Where St_Dt<=date'2011-01-01'
and End_Dt>date'2011-01-01'//找出现在正常使用的客户,即2011.1.1号这个时间点上的信息
and Party_Id in (select Party_Id
From T06_ADDRESS
Where Addr_Type_Cd='02'
And St_Dt=date'2011-01-01')
group by Party_Id;
(1)从T06_ADDRESS表中筛选出在2011年1月1日客户地址发生变更的客户编号
select Party_Id
From T06_ADDRESS
Where Addr_Type_Cd='02'
And St_Dt=date('2011-01-01')
(2)再从T06_ADDRESS表中查出客户编号为(1)的客户的地址和电话(当地址类型为‘02’时显示家庭地址,当地址类型为‘01’时显示家庭电话),并且结果中把客户编号和更新日期也显示出来
经典操作
- 用户管理
新建用户
Create User [usrename] Identyfied by [userpassword] [Default tablespace] [tempory tablespace]
授予权限
Grant connect to [username/rolename] [options]
更改用户
Alter [user]
- 向表中加入字段
通用式: alter table [表名] add [字段名] 字段属性 default 缺省值 default 是可选参数
例如: ALTER TABLE employee ADD post varchar(20)
增加字段: alter table [表名] add 字段名 smallint default 0 增加数字字段,整型,缺省值为0
alter table [表名] add 字段名 int default 0 增加数字字段,长整型,缺省值为0
alter table [表名] add 字段名 single default 0 增加数字字段,单精度型,缺省值为0
alter table [表名] add 字段名 double default 0 增加数字字段,双精度型,缺省值为0
alter table [表名] add 字段名 Tinyint default 0 增加数字字段,字节型,缺省值为0
alter table [表名] add 字段名 text [null] 增加备注型字段,[null]可选参数
alter table [表名] add 字段名 memo [null] 增加备注型字段,[null]可选参数
alter table [表名] add 字段名 varchar(N) [null] 增加变长文本型字段大小为N(1~255)
alter table [表名] add 字段名 char [null] 增加定长文本型字段大小固定为255
alter table [表名] add 字段名 Datetime default 函数增加日期型字段,其中函数可以是 now(),date()等,表示缺省值
(上面都是最常用的,还有其他的属性,可以参考下面的数据类型描述)
删除字段: alter table [表名] drop 字段名
修改变长文本型字段的大小:alter table [表名] alter 字段名 varchar(N)
删除表: drop table [表名]
创建表:
sql="CREATE TABLE [表名] ([字段1,并设置为主键] int IDENTITY (1, 1) NOT NULL CONSTRAINT PrimaryKey PRIMARY KEY,"&
"[字段2] varchar(50),"&
"[字段3] single default 0,"&
"[字段4] varchar(100) null,"&
"[字段5] smallint default 0,"&
"[字段6] int default 0,"&
"[字段7] date default date(),"&
"[字段8] int default 1)"
conn.execute sql
有null 的表示字段允许零长
- 表关联
if exists(select 1 from sys.sysforeignkey where role='FK_对公贷款账户信息_REFERENCE_对公账户') then
alter table 对公贷款账户信息表
delete foreign key FK_对公贷款账户信息_REFERENCE_对公账户
end if;
if exists(select 1 from sys.sysforeignkey where role='FK_对公贷款账户信息_REFERENCE_对公贷款账户余额') then
alter table 对公贷款账户信息表
delete foreign key FK_对公贷款账户信息_REFERENCE_对公贷款账户余额
end if;
drop table if exists 对公贷款账户信息表;
/*==============================================================*/
/* Table: 对公贷款账户信息表 */
/*==============================================================*/
create table 对公贷款账户信息表
(
ACCT_NO varchar2 null,
LOAN_NO U_LOAN_NO not null,
AREA_NO U_AREA_NO not null,
ITEM_NO U_ITEM_NO null,
ORG_NO U_ORG_NO null,
CURRENCY U_CURRENCY null,
TERM_NO U_LOAN_TERM null,
LOAN_DATE DATE null,
MATURE_DATE DATE null,
PRODUCT_NO U_PRODUCT_NO null,
INDUSTRY_NO U_INDUSTRY null,
ASSURE_MODE U_ASSURE_MODE null,
LEVEL_FOUR U_LEVEL_FOUR null,
LEVEL_RISK U_LEVEL_RISK null,
CARD_NO U_CARD_NO null,
INTEREST_RATE U_HIGH_PRECIS_RATE null,
OVERDUE_DAYS INTEGER null,
NONPERFORMING_FLAG U_NONPERFORM_FLAG null,
DEDUCT_ACCT_NO U_ACCT_NO null,
INTEREST_OWED U_MONEY null,
INTEREST_OWED_OUT U_MONEY null,
INTEREST_RATE_DATE DATE null,
LOAN_AMT U_MONEY null,
BAL U_MONEY null,
MORTGAGE_FLAG U_BOOLEAN null,
CUST_LEVEL U_CUST_LEVEL null,
LOAN_VARIETY U_LOAN_VARIETY null,
LOAN_TYPE U_LOAN_TYPE_U null,
COLLATERAL_VALUE U_MONEY null,
PLEDGED_CURRENCY U_CURRENCY null,
PLEDGED_AMT U_MONEY null,
EAD_RATE U_HIGH_PRECIS_RATE null,
FLOAT_TYPE U_FLOAT_TYPE null,
FLOAT_RATE U_HIGH_PRECIS_RATE null,
DAY_REMAIN INTEGER null
constraint CKC_DAY_REMAIN_对公贷款账户信息 check (DAY_REMAIN is null or (DAY_REMAIN in (0,1))),
STATUS U_STATUS null,
BAIL_ACCT U_ACCT_NO null,
BAIL U_MONEY null,
BAIL_CURRENCY U_CURRENCY null,
FIRM_SIZE U_FIRM_SIZE null,
TRUST_PAY_AMT U_MONEY null,
RPDATE DATE null
);
alter table 对公贷款账户信息表
add constraint FK_对公贷款账户信息_REFERENCE_对公账户 foreign key (ACCT_NO)
references 对公账户 (ACCT_NO)
on update restrict
//外键约束,如果存在从数据就不能更新主数据
on delete restrict;
//外键约束,如果存在从数据就不能删除主数据
alter table 对公贷款账户信息表
add constraint FK_对公贷款账户信息_REFERENCE_对公贷款账户余额 foreign key ()
references 对公贷款账户余额表
on update restrict
on delete restrict;
- 更改表中字段的长度
ALTER TABLE [table_name] MODIFY [column_name] [new type]
- 将一张表中的数据放到另一张表里
ALTER TABLE ODS_NBS_MCJNL
RENAME TO ODS_NBS_MCJNL_1
CREATE TABLE ODS_NBS_MCJNL
TABLESPACE ETL_SYS
AS
SELECT * FROM ODS_NBS_MCJNL_1 WHERE 1=0;
INSERT INTO ODS_NBS_MCJNL
SELECT * FROM ODS_NBS_MCJNL_1
SELECT COUNT(*) FROM ODS_NBS_MCJNL_1
DROP TABLE ODS_NBS_MCJNL_1
- DBlink
不同数据库之间的连接
CREATE PUBLIC DATABASE LINK <DBLINK 名称> CONNECT TO <被连接的用户名> IDENTIFIED BY <被连接库的密码> USING '<ORACLE 客户端工具建立的指向被连接库服务名>'
在xxx.ORA里配置好 或直接配置好
'(DESCRIPTION=
(ADDRESS= (PROTOCOL=TCP)(HOST=10.53.3.210)(PORT=1521))
(CONNECT_DATA=
(SERVER=dedicated)
(SERVICE_NAME=GZPEMSDB)
)
)'
系统表
- 系统表列表
dba_开头.....
dba_users 数据库用户信息dba_segments 表段信息dba_extents 数据区信息
dba_objects 数据库对象信息dba_tablespaces 数据库表空间信息
dba_data_files 数据文件设置信息dba_temp_files 临时数据文件信息
dba_rollback_segs 回滚段信息dba_ts_quotas 用户表空间配额信息
dba_free_space数据库空闲空间信息dba_profiles 数据库用户资源限制信息
dba_sys_privs 用户的系统权限信息dba_tab_privs用户具有的对象权限信息
dba_col_privs用户具有的列对象权限信息dba_role_privs用户具有的角色信息
dba_audit_trail审计跟踪记录信息dba_stmt_audit_opts审计设置信息
dba_audit_object 对象审计结果信息dba_audit_session会话审计结果信息
dba_indexes用户模式的索引信息
user_开头
user_objects 用户对象信息user_source 数据库用户的所有资源对象信息
user_segments 用户的表段信息user_tables 用户的表对象信息
user_tab_columns 用户的表列信息user_constraints 用户的对象约束信息
user_sys_privs 当前用户的系统权限信息user_tab_privs 当前用户的对象权限信息
user_col_privs 当前用户的表列权限信息user_role_privs 当前用户的角色权限信息
user_indexes 用户的索引信息user_ind_columns用户的索引对应的表列信息
user_cons_columns 用户的约束对应的表列信息user_clusters 用户的所有簇信息
user_clu_columns 用户的簇所包含的内容信息
user_cluster_hash_expressions 散列簇的信息
v$开头
v$database 数据库信息v$datafile 数据文件信息v$controlfile控制文件信息
v$logfile 重做日志信息v$instance 数据库实例信息v$log 日志组信息
v$loghist 日志历史信息v$sga 数据库SGA信息v$parameter 初始化参数信息
v$process 数据库服务器进程信息v$bgprocess 数据库后台进程信息
v$controlfile_record_section 控制文件记载的各部分信息v$thread 线程信息
v$datafile_header 数据文件头所记载的信息v$archived_log归档日志信息
v$archive_dest 归档日志的设置信息
v$logmnr_contents 归档日志分析的DML DDL结果信息
v$logmnr_dictionary 日志分析的字典文件信息v$logmnr_logs 日志分析的日志列表信息
v$tablespace 表空间信息v$tempfile 临时文件信息v$filestat 数据文件的I/O统计信息
v$undostat Undo数据信息v$rollname 在线回滚段信息v$session 会话信息
v$transaction 事务信息v$rollstat 回滚段统计信息v$pwfile_users 特权用户信息
v$sqlarea 当前查询过的sql语句访问过的资源及相关的信息
v$sql 与v$sqlarea基本相同的相关信息v$sysstat 数据库系统状态信息
all_开头
all_users 数据库所有用户的信息all_objects 数据库所有的对象的信息
all_def_audit_opts 所有默认的审计设置信息all_tables 所有的表对象信息
all_indexes所有的数据库对象索引的信息
session_开头
session_roles 会话的角色信息session_privs 会话的权限信息
index_开头
index_stats 索引的设置和存储信息
伪表
dual 系统伪列表信息
1.系统表 ORACLE数据库的系统参数都存储在数据库中,可以通过SQLPLUS,以用户SYSYTEM进行查询。几个重要的表或者视图如下:
v$controlfile:控制文件的信息;
v$datafile:数据文件的信息;
v$log:日志文件的信息;
v$process:处理器的信息;
v$session:会话信息;
v$transaction:事务信息;
v$resource:资源信息;
v$sga:系统全局区的信息。
上面的视图名中的‘v$’,只是视图名字中的字符。类似于上面的视图或表还有很多,位于: $ORACLE_HOME/RDBMS/ADMIN/CATALOG.SQL文件中。 这些视图或表可以在SQLPLUS中用SELECT语句进行查询。
2.数据字典视图
表和列 DBA_TABLES、ALL_TABLES和USER_TABLES显示了有关数据库表的一般信息。 DBA_TAB_COLUMNS、ALL_TAB_COLUMNS和USE..
- 查询数据库中的表
Select * from cat;
--某个用户的表有哪些
Select table_name from all_tables where owner=’scott’;
--查找该表所属用户有哪些
Select * from all_tab_comments where table_name in('[表名]', '[表名]', '[表名]'……);
--查找同义词下的用户有哪些
Select * from all_synoyms where table_name in ('[表名]', '[表名]', '[表名]'……);
--查看plsql或oracle编码
Select * from v$nls_paramenters t where t.parament='NLS_CHARACTERSET';
Sql优化
查询的逻辑执行顺序
(1) FROM left_table
(3) join_type JOIN right_table
(2) ON join_condition
(4) WHERE where_condition
(5) GROUP BY group_by_list
(6) WITH {cube | rollup}
(7) HAVING having_condition
(8) SELECT
(9) DISTINCT
(10) ORDER BY order_by_list
(11) top_specification select_list
标准的 SQL 的解析顺序为:
(1) FROM 子句 组装来自不同数据源的数据
(2) WHERE 子句 基于指定的条件对记录进行筛选
(3) GROUP BY 子句 将数据划分为多个分组
(4) 使用聚合函数进行计算
(5) 使用HAVING子句筛选分组
(6) 计算所有的表达式
(7) 使用ORDER BY对结果集进行排序
二、执行顺序
1. FROM:对FROM子句中前两个表执行笛卡尔积生成虚拟表vt1
2. ON: 对vt1表应用ON筛选器只有满足 join_condition 为真的行才被插入vt2
3. OUTER(join):如果指定了 OUTER JOIN保留表(preserved table)中未找到的行将行作为外部行添加到vt2,生成t3,如果from包含两个以上表,则对上一个联结生成的结果表和下一个表重复执行步骤和步骤直接结束。
4. WHERE:对vt3应用 WHERE 筛选器只有使 where_condition 为true的行才被插入vt4
5. GROUP BY:按GROUP BY子句中的列列表对vt4中的行分组生成vt5
6. CUBE|ROLLUP:把超组(supergroups)插入vt6,生成vt6
7. HAVING:对vt6应用HAVING筛选器只有使 having_condition 为true的组才插入vt7
8. SELECT:处理select列表产生vt8
9. DISTINCT:将重复的行从vt8中去除产生vt9
10. ORDER BY:将vt9的行按order by子句中的列列表排序生成一个游标vc10
11. TOP:从vc10的开始处选择指定数量或比例的行生成vt11 并返回调用者
看到这里,那么用过Linq to SQL的语法有点相似啊?如果我们我们了解了SQL Server执行顺序,那么我们就接下来进一步养成日常SQL的好习惯,也就是在实现功能的同时有考虑性能的思想,数据库是能进行集合运算的工具,我们应该尽量的利用这个工具,所谓集合运算实际就是批量运算,就是尽量减少在客户端进行大数据量的循环操作,而用SQL语句或者存储过程代替。
执行计划、语句的写法注意事项、临时表、绑定变量
1、 首先要搞明白什么叫执行计划?
执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的,比如一条SQL语句如果用来从一个 10万条记录的表中查1条记录,那查询优化器会选择“索引查找”方式,如果该表进行了归档,当前只剩下5000条记录了,那查询优化器就会改变方案,采用 “全表扫描”方式。
可见,执行计划并不是固定的,它是“个性化的”。产生一个正确的“执行计划”有两点很重要:
(1) SQL语句是否清晰地告诉查询优化器它想干什么?
(2) 查询优化器得到的数据库统计信息是否是最新的、正确的?
2、 统一SQL语句的写法
对于以下两句SQL语句,程序员认为是相同的,数据库查询优化器认为是不同的。
select*from dual
select*From dual
(缓冲池中滴,最好使用同样的格式)
其实就是大小写不同,查询分析器就认为是两句不同的SQL语句,必须进行两次解析。生成2个执行计划。所以作为程序员,应该保证相同的查询语句在任何地方都一致,多一个空格都不行!
3、 不要把SQL语句写得太复杂
一般,将一个Select语句的结果作为子集,然后从该子集中再进行查询,这种一层嵌套语句还是比较常见的,但是根据经验,超过3层嵌套,查询优化器就很容易给出错误的执行计划。因为它被绕晕了。像这种类似人工智能的东西,终究比人的分辨力要差些,如果人都看晕了,我可以保证数据库也会晕的。
另外,执行计划是可以被重用的,越简单的SQL语句被重用的可能性越高。而复杂的SQL语句只要有一个字符发生变化就必须重新解析,然后再把这一大堆垃圾塞在内存里。可想而知,数据库的效率会何等低下。
4、 使用“临时表”暂存中间结果
简化SQL语句的重要方法就是采用临时表暂存中间结果,但是,临时表的好处远远不止这些,将临时结果暂存在临时表,后面的查询就在tempdb中了,这可以避免程序中多次扫描主表,也大大减少了程序执行中“共享锁”阻塞“更新锁”,减少了阻塞,提高了并发性能。
5、 OLTP系统SQL语句必须采用绑定变量
select*from orderheader where changetime >'2010-10-20 00:00:01'
select*from orderheader where changetime >'2010-09-22 00:00:01'
以上两句语句,查询优化器认为是不同的SQL语句,需要解析两次。如果采用绑定变量
select*from orderheader where changetime >@chgtime
@chgtime变量可以传入任何值,这样大量的类似查询可以重用该执行计划了,这可以大大降低数据库解析SQL语句的负担。一次解析,多次重用,是提高数据库效率的原则。
6、 绑定变量窥测
事物都存在两面性,绑定变量对大多数OLTP处理是适用的,但是也有例外。比如在where条件中的字段是“倾斜字段”的时候。
“倾斜字段”指该列中的绝大多数的值都是相同的,比如一张人口调查表,其中“民族”这列,90%以上都是汉族。那么如果一个SQL语句要查询30岁的汉族人口有多少,那“民族”这列必然要被放在where条件中。这个时候如果采用绑定变量@nation会存在很大问题。
试想如果@nation传入的第一个值是“汉族”,那整个执行计划必然会选择表扫描。然后,第二个值传入的是“布依族”,按理说“布依族”占的比例可能只有万分之一,应该采用索引查找。但是,由于重用了第一次解析的“汉族”的那个执行计划,那么第二次也将采用表扫描方式。这个问题就是著名的“绑定变量窥测”,建议对于“倾斜字段”不要采用绑定变量。
少用系列
- From子句中写在最后的表(driving table基础表(就是谁写在前面))将被最先处理,所以选个记录条数最少的表作为基础表。
Eg: tab1有N条数据
tab2有10条数据
select count(*) from tab1,tab2 ………….//不佳
select count(*) from tab2,tab1 …………//最佳
- 不要把交叉表放后面。交叉表放前面,即from的第一个表最好是交叉表
- Where条件中不要把表间的连接放后面
表之间的连接必须写在其他where条件之前。
可以过滤掉最大数据记录的条件必须写在where子句的末尾
- 如果表A和B存在 多对一 或者 一对一 的关系如下:
//高效
Select A.* from A,B where A.city=B.city
//低效
Select * from A where A.city in (select B.city from B)
- 全表删除用truncate代替delete
- 不用*代替所有列名,因为oracle中会查询数据字典把*转变为表的所有列名
- 少用动态语句、like、commit、order by、视图嵌套(理论上可嵌套16层,但是3层就会使性能下降的非常严重)
- 定义trunc(sysdate)时尽量在声明的时候用,同时不推荐使用sysdate
- Mod的开销很大
- 使用不等于操作符(<> 、 != )
下面的查询即使在cust_rating 列有一个索引,查询语句仍然执行一次全表扫描。
select cust_Id,cust_name from customers where cust_rating <> 'aa';
把上面的语句改成如下的查询语句,这样,在采用基于规则的优化器而不是基于代价的优化器(更智能)时,将会使用索引。
select cust_Id,cust_name from customers where cust_rating < 'aa' or cust_rating > 'aa';
特别注意:通过把不等于操作符改成 OR 条件,就可以使用索引,以避免全表扫描。
- 使用 IS NULL 或 IS NOT NULL
使用 IS NULL 或 IS NOT NULL 同样会限制索引的使用 。因为 NULL 值并没有被定义。在 SQL 语句中使用 NULL 会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成 NOT NULL 。如果被索引的列在某些行中存在 NULL 值,就不会使用这个索引(除非索引是一个位图索引,关于位图索引在稍后在详细讨论)。
- 使用函数
如果不使用基于函数的索引,那么在SQL 语句的 WHERE 子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。
下面的查询不会使用索引(只要它不是基于函数的索引)
select empno,ename,deptno from emp where trunc(hiredate)='01-MAY-81';
把上面的语句改成下面的语句,这样就可以通过索引进行查找。
select empno,ename,deptno from emp where hiredate<(to_date('01-MAY-81')+0.9999);
- 比较不匹配的数据类型
注意下面查询的例子,account_number 是一个 VARCHAR2 类型 , 在 account_number 字段上有索引。
下面的语句将执行全表扫描 :
select bank_name,address,city,state,zip from banks where account_number = 990354;
Oracle可以自动把 where 子句变成 to_number(account_number)=990354 ,这样就限制了索引 的使用 , 改成下面的查询就可以使用索引:
select bank_name,address,city,state,zip from banks where account_number ='990354';
特别注意:不匹配的数据类型之间比较会让Oracle 自动限制索引的使用 , 即便对这个查询执行 Explain Plan 也不能让您明白为什么做了一次 “ 全表扫描 ” 。
- union操作符
union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表union。如:
select * from gc_dfys
union
select * from ls_jg_dfys
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
推荐方案:采用union ALL操作符替代union,因为union ALL操作只是简单的将两个结果合并后就返回。
select * from gc_dfys
union all
select * from ls_jg_dfys
- 采用函数处理的字段不能利用索引,如:
substr(hbs_bh,1,4)=’5400’,优化处理:hbs_bh like ‘5400%’
trunc(sk_rq)=trunc(sysdate),优化处理:sk_rq>=trunc(sysdate) and sk_rq<trunc(sysdate+1)
进行了显式或隐式的运算的字段不能进行索引,如:
ss_df+20>50,优化处理:ss_df>30
‘X’||hbs_bh>’X5400021452’,优化处理:hbs_bh>’5400021542’
sk_rq+5=sysdate,优化处理:sk_rq=sysdate-5
hbs_bh=5401002554,优化处理:hbs_bh=’ 5401002554’,注:此条件对hbs_bh 进行隐式的
to_number转换,因为hbs_bh字段是字符型。
条件内包括了多个本表的字段运算时不能进行索引,如:
ys_df>cx_df,无法进行优化
qc_bh||kh_bh=’5400250000’,优化处理:qc_bh=’5400’ and kh_bh=’250000’
推荐使用
- 推荐使用decode函数,oracle所有版本都支持,同时decode比if和then高效
Eg:select DECODE(command, 0, ‘none’, 2, ‘insert’, 3, ‘select’, 6, ‘update’, 7, ‘delete’, 8, ‘drop’, ‘other’)command from …………………..
- Oracle里的rowid可立即确定行当位置, ROWID为该表行的唯一标识,是一个伪列,可以用在SELECT中,但不可以用INSERT, UPDATE来修改该值。如Rowid可以作为判断条件与用户id相等
- 避免定义的变量类型与表中列的类型不一样,造成转换问题。同时不要定义了变量又不去使用。新变量类型:用BINARY_DOUBLE/BINARY_FLOAT代替Number型
- 自制临时表。可能因为关联表的数据分散冗杂致使效率低下,所以将关联的东东创建到一个新的表中存储在新表空间里,用这个临时表进行关联查询。
- 中间结果中会话中使用时,不要采用永久表,自己搞个临时表就行了
- 推荐结果不大的时候,用exits而不用in,in返回的是结果集,而exists返回的是布尔值。
- 当子查询结果较大时,用minus代替not in/ NOT exists
//见笔记(点击打开)
- 用instr代替like Eg: instr(字段名/列名, ‘查找字段’)
有的时候会需要进行一些模糊查询比如
select*from contact where username like ‘%yue%’
关键词%yue%,由于yue前面用到了“%”,因此该查询必然走全表扫描,除非必要否则不要在关键词前加%
Eg: Select * From employee Where instr(last_name,'linton')>0;
- 在进行多表关联时,多用 Where 语句把单个表的结果集最小化,多用聚合函数汇总结果集后再与其它表做关联,以使结果集数据量最小化
- 在两张表进行关联时,应考虑可否使用左/右连接。以提高查询速度
- 使用 where 而不是 having ,where是用于过滤行的,而having是用来过滤组的,因为行被分组后,having 才能过滤组,所以尽量用户 WHERE 过滤
Pl/sql块积累
u 基本语法
Declare
Begin
Commit;
End;
以下用testtable作为例子:
―――――――――――――――――――――――――――――――――
创建表testtable
create table testtable
(recordnumber number(4) not null,
currentdate date not null) ;
―――――――――――――――――――――――――――――――――
向表testtable中输入100条记录
set serveroutput on
declare
maxrecords constant int:=100;
i int :=1;
begin
for i in 1..maxrecords loop
insert into testtable(recordnumber,currentdate)
values(i,sysdate);
end loop;
dbms_output.put_line('成功录入数据!');
commit;
end;
- %type定义变量
为了让PL/SQL中变量的类型和数据表中的字段的数据类型一致,Oracle 9i提供了%type定义方法.这样当数据表的字段类型修改后,PL/SQL程序中相应变量的类型也自动修改.
declare
mydate [表名].[字段名]%type; ‘这里定义的mydate的类型和表中字段的类型一样
begin
commit;
end;
- 定义 记录类型变量
PL/SQL中,也支持将多个基本数据类型捆绑在一起的记录数据类型.
下面的程序代码定义了名为myrecord的记录类型,该记录类型由整数型的myrecordnumber和日期型的mycurrentdate基本类型变量组成,srecord是该类型的变量,引用记录型变量的方法是"记录变量名.基本类型变量名". 程序的执行部分从testtable数据表中提取recordnumber字段为68的记录的内容,存放在srecord复合变量里,然后输出srecord.mycurrentdate的值,实际上就是数据表中相应记录的currentdate的值.
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
type myrecord is record(
myrecordnumber int,
mycurrentdate date);
srecord myrecord;
begin
select * into srecord from testtable where recordnumber=68;
dbms_output.put_line(srecord.mycurrentdate);
end;
―――――――――――――――――――――――――――――――――――――
在PL/SQL程序中,select语句总是和into配合使用,into子句后面就是要被赋值的变量.
- %rowtype定义变量
使用%type可以使变量获得字段的数据类型,使用%rowtype可以使变量获得整个记录的数据类型.
比较两者定义的不同:
变量名 数据表.列名%type //定义普通变量,类型和某列一致
变量名 数据表%rowtype //定义复合类型变量,类型与表结构相同
下列PL/SQL程序定义了名为mytable的复合类型变量,与testtable数据表结构相同―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
mytable testtable%rowtype;
begin
select * into mytable from testtable where recordnumber=88;
dbms_output.put_line(mytable.currentdate);
end;
- 定义一维表类型变量(一维数组)
表类型变量和数据表是有区别的,定义表类型变量的语法如下:
―――――――――――――――――――――――――――――――――――――
type 表类型 is table of 类型 index by binary_integer;
表变量名 表类型;
―――――――――――――――――――――――――――――――――――――
类型可以是前面的类型定义,index by binary_integer子句代表以符号整数为索引,这样访问表类型变量中的数据方法就是"表变量名(索引符号整数)".
下列PL/SQL程序定义了名为tabletype1和tabletype2的两个一维表类型,相当于一维数组.
table1和table2分别是两种表类型变量.
"||"是连接字符串的运算符. ―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
type tabletype1 is table of varchar2(4) index by binary_integer;
type tabletype2 is table of testtable.recordnumber%type index by binary_integer;
table1 tabletype1;
table2 tabletype2;
begin
table1(1):='大学';
table1(2):='大专';
table2(1):=88;
table2(2):=55;
dbms_output.put_line(table1(1)||table2(1));
dbms_output.put_line(table1(2)||table2(2));
end;
―――――――――――――――――――――――――――――――――――――
- 定义多维表类型变量(多维数组)
下列PL/SQL程序定义了名为tabletype1的多维表类型,相当于多维数组,table1是多维表类型变量,将数据表testtable中recordnumber为60的记录提取出来存放在table1中并显示.
――――――――――――――――――――――――――――――
set serveroutput on
declare
type tabletype1 is table of testtable%rowtype index by binary_integer;
table1 tabletype1;
begin
select * into table1(60)
from testtable
where recordnumber=60;
dbms_output.put_line(table1(60).recordnumber||table1(60).currentdate);
end;
――――――――――――――――――――――――――――――
在定义好的表类型变量里,可以使用count,delete,first,last,next,exists和prior等属性进行操作,使用方法为"表变量名.属性",返回的是数字.
下列PL/SQL程序,该程序定义了名为tabletype1的一维表类型,table1是一维表类型变量,变量中插入3个数据,综合使用了表变量属性.
set serveroutput on
declare
type tabletype1 is table of varchar2(9) index by binary_integer;
table1 tabletype1;
begin
table1(1):='成都市';
table1(2):='北京市';
table1(3):='青岛市';
dbms_output.put_line('总记录数:'||to_char(table1.count));
dbms_output.put_line('第一条记录:'||table1.first);
dbms_output.put_line('最后条记录:'||table1.last);
dbms_output.put_line('第二条的前一条记录:'||table1.prior(2));
dbms_output.put_line('第二条的后一条记录:'||table1.next(2));
if(table1.exists(2)) then dbms_output.put_line('第二条记录存在!');
else dbms_output.put_line('第二条记录不存在!');
end if;
table1.delete(2);
dbms_output.put_line('=====================');
dbms_output.put_line('总记录数:'||to_char(table1.count));
dbms_output.put_line('第一条记录:'||table1.first);
dbms_output.put_line('最后条记录:'||table1.last);
dbms_output.put_line('第二条的前一条记录:'||table1.prior(2));
dbms_output.put_line('第二条的后一条记录:'||table1.next(2));
if(table1.exists(2)) then dbms_output.put_line('第二条记录存在!');
else dbms_output.put_line('第二条记录不存在!');
end if;
end;
- 表达式
(1)数值表达式
PL/SQL程序中的数值表达式是由数值型常数,变量,函数和算术运算符组成的,可以
使用的算术运算符包括+(加法),-(减法),*(乘法),/(除法)和**(乘方)等.
――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
result integer;
begin
result:=10+3*4-20+5**2;
dbms_output.put_line('运算结果是:'||to_char(result));
end;
――――――――――――――――――――――――――――――――――――dbms_output.put_line函数输出只能是字符串,因此利用to_char函数将数值型结果转换为字符型.
(2)字符表达式
字符表达式由字符型常数,变量,函数和字符运算符组成,唯一可以使用的字符运算符
就是连接运算符"||".
(3)关系表达式
关系表达式由字符表达式或数值表达式与关系运算符组成,可以使用的关系运算符包括以下9种.
<小于
>大于
= 等于(不是赋值运算符:=)
like 类似于
in 在……之中
<= 小于等于
= 大于等于
!= 不等于
between 在……之间
关系型表达式运算符两边的表达式的数据类型必须一致.
(4)逻辑表达式
逻辑表达式由逻辑常数,变量,函数和逻辑运算符组成,常见的逻辑运算符包括以下3种.
NOT:逻辑非
OR:逻辑或
AND:逻辑与
运算的优先次序为NOT,AND和OR.
- TO_[] 函数
PL/SQL程序中提供了很多函数供扩展功能,除了标准SQL语言的函数可以使用外,最常见的数据类型转换函数有以下3个.
To_char:将其他类型数据转换为字符型.
To_date:将其他类型数据转换为日期型.
To_number:将其他类型数据转换为数值型.
――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
inum integer;
cd date;
cchar varchar2(5);
begin
inum := to_number('30');
cd:=to_date('2007-4-4','yyyy-mm-dd'); //TO_DATE('','YYYYMMDD HH24:MI:SS')
cchar :=to_char(30);
dbms_output.put_line(inum);
dbms_output.put_line(cd);
dbms_output.put_line(cchar);
end;
――――――――――――――――――――――――――――――――――――
- 事务处理
事务是Oracle 9i中进行数据库操作的基本单位,在PL/SQL程序中,可以使用3个事务处理控制命令:commit, rollback, savepoint
(1)commit命令
为了保证数据的一致性,在内存中将为每个客户机建立工作区,客户机对数据库进行操作处理的事务都在工作区内完成,只有在输入commit命令后,工作区内的修改内容才写入到数据库上,称为物理写入,这样可以保证在任意的客户机没有物理提交修改以前,别的客户机读取的后台数据库中的数据是完整的,一致的 。
每次执行PL/SQL程序都会自动进行事务提交 。
set auto on;
取消自动提交功能的PL/SQL程序如下。
set auto off;
(2)rollback
事务回滚命令,在尚未提交commit命令之前,如果发现delete,insert和update等操作需要恢复的话,可以使用rollback命令回滚到上次commit时的状态.
下面可以回滚到保存点
(3)savepoint
保存点命令.事务通常由数条命令组成,可以将每个事务划分成若干个部分进行保存,这样每次可以回滚每个保存点,而不必回滚整个事务.语法格式如下.
创建保存点:savepoint 保存点名;
回滚保存点:rollback to 保存点名;
- 游标
游标是从数据表中提取出来的数据,以临时表的形式存放在内存中,在游标中有一个数据指针,在初始状态下指向的是首记录,利用fetch语句可以移动该指针,从而对游标中的数据进行各种操作,然后将操作结果写回数据表中.
游标作为一种数据类型,首先必须进行定义,其语法如下.
cursor 游标名 is select 语句;
cursor是定义游标的关键词,select是建立游标的数据表查询命令.
使用创建好的游标,接下来要打开游标,语法结构如下:
open 游标名;
打开游标的过程有以下两个步骤:
(1)将符合条件的记录送入内存.
(2)将指针指向第一条记录.
要提取游标中的数据,使用fetch命令,语法形式如下.
fetch 游标名 into 变量名1, 变量名2,……;
或
fetch 游标名 into 记录型变量名;
定义cursorrecord变量是游标mycursor的记录行变量,在游标mycursor的结果中找到sal字段大于800的第一个记录,显示deptno字段的内容.
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
tempsal emp.sal%type;
cursor mycursor is select * from emp where sal>tempsal; ##游标实现的功能
cursorrecord mycursor%rowtype; ##表结构
begin
tempsal:=800;
open mycursor;
fetch mycursor into cursorrecord;
dbms_output.put_line(to_char(cursorrecord.deptno)); ##对数字类型的用to_char转换
end;
―――――――――――――――――――――――――――――――――――――
使用完游标后,要关闭游标,使用close命令,语法形式如下:
close 游标名;
游标提供的一些属性可以帮助编写PL/SQL程序,游标属性的使用方法为:
游标名[属性],
例如:mycursor%isopen
- 游标属性
(1)%isopen
该属性功能是测试游标是否打开,如果没有打开游标,使用fetch语句将提示错误.
判断游标是否打开 :
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
tempsal emp.sal%type;
cursor mycursor is select * from scott.emp where sal>tempsal; ##游标实现的功能
cursorrecord mycursor%rowtype; ##表结构
begin
tempsal:=800;
if mycursor%isopen then
fetch mycursor into cursorrecord;
dbms_output.put_line(to_char(cursorrecord.deptno));
else
dbms_output.put_line('游标没有打开!');
end if;
end;
―――――――――――――――――――――――――――――――――――――
(2)%found
该属性功能是测试前一个fetch语句是否有值,有值将返回true,否则为false.
判断游标是否有数据:
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
tempsal emp.sal%type;
cursor mycursor is select * from emp where sal>tempsal;
cursorrecord mycursor%rowtype;
begin
tempsal:=800;
open mycursor;
fetch mycursor into cursorrecord;
if mycursor%found then
dbms_output.put_line(to_char(cursorrecord.deptno));
else
dbms_output.put_line('没有数据!');
end if;
end;
―――――――――――――――――――――――――――――――――――――
(3)%notfound
该属性是%found属性的反逻辑,常被用于退出循环.
判断游标是否没数据:
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
tempsal emp.sal%type;
cursor mycursor is select * from emp where sal>tempsal;
cursorrecord mycursor%rowtype;
begin
tempsal:=800;
open mycursor;
fetch mycursor into cursorrecord;
if mycursor%notfound then
dbms_output.put_line(to_char(cursorrecord.deptno));
else
dbms_output.put_line('发现数据!');
end if;
end;
―――――――――――――――――――――――――――――――――――――
(4)%rowcount
该属性用于返回游标的数据行数.
判断游标数据行数:
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
tempsal emp.sal%type;
cursor mycursor is select * from emp where sal>tempsal;
cursorrecord mycursor%rowtype;
begin
tempsal:=800;
open mycursor;
fetch mycursor into cursorrecord;
dbms_output.put_line(to_char(mycursor%rowcount));
end;
―――――――――――――――――――――――――――――――――――――
若返回值为0,表明游标已经打开,但没有提取出数据.
u 过程
将一些内部联系的命令组成一个个过程,通过参数在过程之间传递数据
完整的过程结构如下:
create or replace procedure [过程名] as
声明语句段;
begin
执行语句段;
exception
异常处理语句段;
end;
过程是有名称的程序块,as关键词代替了无名块的declare.
创建名为tempprocedure的过程,create是创建过程的标识符,replace表示若同名过程存在将覆盖原过程.该过程定义了一个变量,其类型和testtable数据表中的currentdate字段类型相同,都是日期型,将数据表中的recordnumber字段为88的currentdate字段内容送入变量中,然后输出结果.
―――――――――――――――――――――――――――――――――――――
set serveroutput on
create or replace procedure tempprocedure as
tempdate testtable.currentdate%type;
begin
select currentdate into tempdate from testtable where recordnumber=88;
dbms_output.put_line(to_char(tempdate));
end;
―――――――――――――――――――――――――――――――――――――
创建过程并不会直接输出结果,只是和创建其他数据库对象一样,是一个数据定义命令.
要执行创建的过程,必须通过主程序来调用过程.
――――――――――――――――――――――――
set serveroutput on
begin
tempprocedure; ##有的地方是exce tempprocedure
end;
―――――――――――――――――――――――
在Oracle中,创建好的过程可以被任何程序调用.
- 过程的三种类型的参数
在PL/SQL过程中,可以有3种类型的参数:in, out, in out
in参数:读入参数,主程序向过程传递参数值.
out参数:读出参数,过程向主程序传递参数值.
in out 参数:双向参数,过程与主程序双向交流数据.
例如:
创建带参数的过程:
―――――――――――――――――――――――――――――――――――――
set serveroutput on
create or replace procedure tempprocedure(
tempdeptno in dept.deptno%type,
tempdname out dept.dname%type,
temploc in out dept.loc%type
)
as
loc1 dept.loc%type;
dname1 dept.dname%type;
begin
select loc into loc1 from dept where deptno=tempdeptno;
select dname into dname1 from dept where deptno=tempdeptno;
temploc:='地址:'||loc1;
tempdname:='姓名:'||dname1;
end;
―――――――――――――――――――――――――――――――――――――
调用带参数的过程tempprocedure,实际参数为(10, 'SALES ', 'CHICAGO').
――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
myno dept.deptno%type;
mydname dept.dname%type;
myloc dept.loc%type;
begin
myno:=30;
mydname:= 'SALES';
myloc:='CHICAGO';
tempprocedure(myno,mydname,myloc);
dbms_output.put_line(myno);
dbms_output.put_line(mydname);
dbms_output.put_line(myloc);
end;
――――――――――――――――――――――――――――――――――――
- 序列
序列是Oracle 9i提供的用于按照设定的规则自动产生数据的方案对象.在某些数据表的
构中,有些字段需要这种特性.比如,对于某个学生数据表的学号关键字段,用户可以希望在录入数据时,能够自动在上一个记录的学号字段上自动加1等.由于Oracle 9i提供的16种基本数据类型并没有这样的功能,可以通过序列方案对象来实现.
创建各项参数均为默认值的序列:
―――――――――――――――――――――――――――――――――
create sequence tempsequence;
―――――――――――――――――――――――――――――――――
创建指定参数的序列:
―――――――――――――――――――――――――――――――――
create sequence tempsequence
INCREMENT BY 1 ##递增/递减的间隔数值
START WITH 1 ##序列的起始值
MAXVALUE 1000 ##序列允许的最大值
MINVALUE 1 ##序列允许的最小值
NOCYCLE ##达到最小值或最大值后停止生成任何值,此为默认值
CACHE 20 ##数据库预分配并存储的值的数目,默认值为20
NOORDER; ##序列号不按请求次序生成
―――――――――――――――――――――――――――――――――
INCREMENT BY :递增序列递增的间隔数值(升序序列)或递减序列递减的间隔数值(降序序列). 默认为1.
START WITH :设置序列的起始值.
MAXVALUE :序列允许的最大值.
NOMAXVALUE :.对升序序列使用默认值 10的27次方,而对降序序列使用默认值-1.
MINVALUE :设置序列允许的最小值.
NOMINVALUE :对升序序列使用默认值 1,而对降序序列使用默认值-10的26次方.
CYCLE :在达到序列最小值或最大值之后,序列应继续生成值.对升序序列来说,在达到最大值后将生成最小值.对降序序列来说,在达到最小值后将生成最大值.
NOCYCLE :在达到最小值或最大值后停止生成任何值,此为默认值.
CACHE :由数据库预分配并存储的值的数目,默认值为20.
NOCACHE :不预分配序列值 .
ORDER :序列号要按请求次序生成
NOORDER :序列号不按请求次序生成
——————————————————————————————————
向数据表中插入数据时如何使用序列 :
(1)创建表SEQUENCE_TABLE
――――――――――――――――――――――――――――――――――――———————
CREATE TABLE SEQUENCE_TABLE (NO NUMBER(10) NOT NULL);
―――――――――――――――――――――――――――――――――――————————
(2)在插入新的记录时,使用刚创建的“TEMPSEQUENCE”序列来自动产生“NO”数据列的值
――――――――――――――――――――――――――――――――――――———————
INSERT INTO SEQUENCE_TABLE (NO) VALUES(TEMPSEQUENCE.NEXTVAL)
――――――――――――――――――――――――――――――――――――———————
(3)查询数据表SEQUENCE_TABLE
―――――――――――――――――――――――――――――――――――――
select * from sequence_table;
―――――――――――――――――――――――――――――――――――――
删除序列可以使用下列命令:
drop sequence 序列名;
- 异常处理
Oracle 9i中的异常处理分为系统预定义异常处理和自定义异常处理两部分
系统预定义异常处理是针对PL/SQL程序编译,执行过程中发生的问题进行处理的程序. 下列代码为正确代码,在sql pluls中能够顺利执行.
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
tempno integer:=100;
begin
tempno:=tempno+1;
end;
―――――――――――――――――――――――――――――――――――――
下列代码为错误代码,在sql pluls中的执行会出现异常.
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
tempno integer:=100;
tempno=tempno+1;
end;
―――――――――――――――――――――――――――――――――――――
每个预定义例外都对应一个oracle系统错误。
ACCESS_INFO_NULL(ora-06530):当访问没有初始化的对象时触发。
CASE_NOT_FOUND(ora-06592):在CASE过程中WHEN后没有包含必要的条件分支并且没有ELSE子句,则会触发本异常。
COLLECTION_IS_NULL(06531):访问未初始化的集合元素(嵌套表或者varray)。
CURSOR_ALREADY_OPEN(ora-06511):重新打开已经打开的游标。
DUP_VAL_ON_INDEX(ora-00001):当中唯一索引所对应的列上键入重复值时。
INVALID_CURSOR(ora-01001):试图在不合法的游标上执行操作时,譬如没打开游标就提取内容。
INVALID_NUMBER(ora-01722):当试图将非法的字符串转换成数字类型时。
NO_DATA_FOUND(ora-01403):执行SELECT INTO返回行,或者引用了索引表未初始化的元素时。
TOO_MANY_ROWS(ora-01422):执行SELECT INTO返回超过一行数据时。
ZERO_DIVIDE(ora-01476):0作为被除数时。
SUBSCRIPT_BEYOND_COUNT(ora-06533):使用嵌套表或者VARRAY集合时,如果引用下标超过last。
SUBSCRIPT_OUTSIDE_LIMIT(ora-06532):使用嵌套表或者VARRAY集合时,如果引用下标小于first。
VALUE_ERROR(ora-06522):在执行赋值操作时,如果变量长度不足以容纳实际数据。
LOGIN_DENIED(ora-01017):连接数据库时,如果变量长度不足以容纳实际数据。
NOT_LOGGED_ON(ora-01012):在程序没有连接到oracle数据库执行plsql代码则会触发。
PROGRAM_ERROR(ora-06501):plsql内部问题。
ROWTYPE_MISMATCH(ora-06504):执行赋值操作时,如果宿主游标变量和PLSQL游标变量返回类型不兼容时。
SELF_IS_NULL(ora-30625):使用对象类型时,如果在NULL实例上调用成员方法。
STORAGE_ERROR(ora-06500):超出内存空间或者内存被破坏。
SYS_INVALID_ROWID(ora-01410):无效字符串企图转换为ROWID类型时。
TIMEOUT_ON_RESOURCE(ora-00051):等待资源时出现超时错误。
自定义异常处理
1. 定义异常处理
定义异常处理的语法如下:
declare
异常名 exception;
2. 触发异常处理
触发异常处理的语法如下:
raise 异常名;
3. 处理异常
触发异常处理后,可以定义异常处理部分,语法如下:
Exception
When 异常名1 then
异常处理语句段1;
When 异常名2 then
异常处理语句段2;
下面的PL/SQL程序包含了完整的异常处理定义,触发,处理的过程.定义名为salaryerror的异常,在emp数据表中查找empno=7566的记录,将其值放入变量tempsal中,判断tempsal值若不在900和2600之间,说明该员工的薪水有问题,将激活异常处理,提示信息.
―――――――――――――――――――――――――――――――――――――
set serveroutput on
declare
salaryerror exception;
tempsal emp.sal%type;
begin
select sal into tempsal
from emp
where empno=7566;
if tempsal>2600 then
raise salaryerror;
end if;
exception
when salaryerror then
dbms_output.put_line('薪水超出范围');
end;
- 银行存储过程案例
对公账户:
prompt 这个是已经建好的
prompt Creating table OM_ORGANIZATION
prompt ==============================
prompt
create table OM_ORGANIZATION
(
ORGID NUMBER(10) not null,
ORGCODE VARCHAR2(32) not null,
ORGNAME VARCHAR2(64),
ORGLEVEL NUMBER(2) default 1/*机构层次*/,
ORGDEGREE VARCHAR2(255),
PARENTORGID NUMBER(10),
ORGSEQ VARCHAR2(512),
ORGTYPE VARCHAR2(12),
ORGADDR VARCHAR2(256),
ZIPCODE VARCHAR2(10),
MANAPOSITION NUMBER(10),
MANAGERID NUMBER(10),
ORGMANAGER VARCHAR2(128),
LINKMAN VARCHAR2(30),
LINKTEL VARCHAR2(20),
EMAIL VARCHAR2(128),
WEBURL VARCHAR2(512),
STARTDATE DATE,
ENDDATE DATE,
STATUS VARCHAR2(255),
AREA VARCHAR2(30),
CREATETIME TIMESTAMP(6),
LASTUPDATE DATE,
UPDATOR NUMBER(10),
SORTNO INTEGER,
ISLEAF CHAR(1),
SUBCOUNT NUMBER(10),
REMARK VARCHAR2(512)
)
tablespace TBS_SMT
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
minextents 1
maxextents unlimited
);
comment on table OM_ORGANIZATION
is '机构部门表
允许定义多个平行机构';
comment on column OM_ORGANIZATION.ORGDEGREE
is '总行,分行,海外分行...';
comment on column OM_ORGANIZATION.ORGTYPE
is '总公司/总部部门/分公司/分公司部门...';
comment on column OM_ORGANIZATION.ORGMANAGER
is '机构管理员能够给本机构的人员进行授权,多个机构管理员之间用,分隔';
alter table OM_ORGANIZATION
add constraint P_ORGNIZATION primary key (ORGID)
using index
tablespace TBS_SMT
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
minextents 1
maxextents unlimited
);
create unique index IDX_OM_ORGANIZATION_ORGCODE on OM_ORGANIZATION (ORGCODE)
tablespace TBS_SMT
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
minextents 1
maxextents unlimited
);
prompt 这个是日志表,通过存储过程SP_WRITE_LOG 调用
prompt Creating table CA_CTL_LOG
prompt =========================
prompt
create table CA_CTL_LOG
(
DATA_DATE DATE,
LOG_TIME TIMESTAMP(6),
PROGRAM_NAME VARCHAR2(100),
LOG_LEVEL CHAR(1),
LOG_CODE VARCHAR2(10),
LOG_DETAIL VARCHAR2(4000)
)
tablespace TBS_DAT0
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
minextents 1
maxextents unlimited
);
prompt
prompt Creating procedure SP_WRITE_LOG
prompt ===============================
prompt
CREATE OR REPLACE PROCEDURE SP_WRITE_LOG
(
I_DATA_DATE IN DATE, /*批处理日期*/
I_PROGRAM_NAME IN VARCHAR2, /*执行程序*/
I_LOG_LEVEL IN CHAR, /*日志类型*/
I_LOG_CODE IN VARCHAR2, /*日志代码*/
I_LOG_DETAIL IN VARCHAR2 /*日志信息*/
) AS
BEGIN
IF I_LOG_LEVEL<>'1' THEN
INSERT INTO CA_CTL_LOG(DATA_DATE,LOG_TIME,PROGRAM_NAME,LOG_LEVEL,LOG_CODE,LOG_DETAIL)
VALUES(I_DATA_DATE,CURRENT_TIMESTAMP,UPPER(NVL(I_PROGRAM_NAME,'SP_WRITE_LOG')),I_LOG_LEVEL,I_LOG_CODE,I_LOG_DETAIL);
COMMIT;
END IF;
END SP_WRITE_LOG;
/
prompt 存储过程SP_PMM_CACCT_BASE_INFO
prompt Creating procedure SP_PMM_CACCT_BASE_INFO
prompt ===============================
prompt
CREATE OR REPLACE PROCEDURE SP_PMM_CACCT_BASE_INFO /*对公账户 */
(
I_DATA_DATE IN DATE, /*批处理日期*/
O_RETURN_MSG OUT VARCHAR2 /*返回信息*/
) AS
/*常用变量定义*/
V_PROGRAM_NAME VARCHAR2(50) DEFAULT 'SP_PMM_CACCT_BASE_INFO'; /*处理程序名称*/
V_LOG_CODE VARCHAR2(10); /*日志代码*/
V_LOG_DETAIL VARCHAR2(4000); /*日志详情*/
/*异常定义*/
V_RETURN_MSG VARCHAR2(4000); /*返回信息*/
ERR_EXCEPTION EXCEPTION; /*异常内容*/
V_EXESQL VARCHAR2(8000); /**/
V_NUMBER INT; /*查询是否需要更新*/
V_TEMP_TABLE VARCHAR(50);
V_TEMP_COLUMN VARCHAR(2000);
BEGIN
V_LOG_CODE := '';
V_LOG_DETAIL := '开始插入对公存款接口表数据:SP_PMM_CACCT_BASE_INFO';
SP_WRITE_LOG(I_DATA_DATE,V_PROGRAM_NAME,'2',V_LOG_CODE,V_LOG_DETAIL);
BEGIN
DELETE
FROM PMM_CACCT_BASE_INFO;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
V_LOG_CODE := '';
V_LOG_DETAIL := 'Error:删除零售存款信息'||'SP_PMM_CACCT_BASE_INFO'||'出错:'|| SQLCODE || SQLERRM;
RAISE ERR_EXCEPTION;
END;
BEGIN
INSERT INTO PMM_CACCT_BASE_INFO(
DATA_DATE, /*数据日期 */
ACCT_NO, /*账号 */
AREA_NO, /*区域编码 */
ITEM_NO, /*科目号 */
ORG_NO, /*机构号 */
CURRENCY, /*币种 */
TERM_NO, /*期限 */
OPEN_DATE, /*开户日期 */
CLOSE_DATE, /*销户日期 */
MATURE_DATE, /*到期日期 */
CUST_NO, /*客户号 */
CUST_TYPE, /*客户类型 */
CUST_NAME, /*客户名称 */
PRODUCT_NO, /*产品编号 */
--MAIN_ACCT_NO, /*主账号 */
--CARD_NO, /*卡号 */
--ACCT_TYPE, /*账户类型 */
ACCT_ATTRIBUTE, /*账户属性 */
--BELONG_MARK, /*归属标志 */
OPEN_TELLER, /*开户柜员 */
CLOSE_TELLER, /*销户柜员 */
LAST_TRAN_DATE, /*最后交易日期 */
STATUS, /*账户状态 */
RELATION_LOAN_FLAG, /*贷款关联标志 */
--DEDUCT_ACCT_FLAG, /*贷款扣款账户标志*/
--INTEREST_RATE, /*利率 */
BAL, /*余额 */
--BAL_SUM_M, /*余额累积(月) */
--BAL_SUM_Q, /*余额累积(季) */
--BAL_SUM_Y, /*余额累积(年) */
--BAL_AVG_M, /*日均(月) */
--BAL_AVG_Q, /*日均(季) */
--BAL_AVG_Y, /*日均(年) */
--REAL_INTEREST_D, /*实际利息(日) */
--REAL_INTEREST_M, /*实际利息(月) */
-- REAL_INTEREST_Q, /*实际利息(季) */
-- REAL_INTEREST_Y, /*实际利息(年) */
D_AMT_D, /*借方发生额(日) */
--D_AMT_M, /*借方发生额(月) */
--D_AMT_Q, /*借方发生额(季) */
--D_AMT_Y, /*借方发生额(年) */
C_AMT_D, /*贷方发生额(日) */
--C_AMT_M, /*贷方发生额(月) */
--C_AMT_Q, /*贷方发生额(季) */
--C_AMT_Y, /*贷方发生额(年) */
D_TRAN_NUM_D, /*借方交易笔数(日)*/
--D_TRAN_NUM_M, /*借方交易笔数(月)*/
--D_TRAN_NUM_Q, /*借方交易笔数(季)*/
--D_TRAN_NUM_Y, /*借方交易笔数(年)*/
C_TRAN_NUM_D, /*贷方交易笔数(日)*/
--C_TRAN_NUM_M, /*贷方交易笔数(月)*/
--C_TRAN_NUM_Q, /*贷方交易笔数(季)*/
--C_TRAN_NUM_Y, /*贷方交易笔数(年)*/
--AGREE_FLAG, /*协定标志 */
DEPOSIT_TYPE , /*存款类型 */
CUACNO
--PLEDGED_FLAG, /*质押标志 */
--RESIDENT_FLAG, /*居民标识 */
--IS_PACU, /*三方存管标志 */
--IS_REPWAGE, /*代发工资标志 */
--FTP_CP /*创利 */
)
SELECT I_DATA_DATE AS DATA_DATE,
A.DPACNO AS ACCT_NO,
NVL(B.AREA, '0001') AS AREA_NO,
C.KMUHAO AS ITEM_NO,
A.ACOPBR AS ORG_NO,
'CNY'/*A.ACCCUR*/ AS CURRENCY,
A.ACTERM AS TERM_NO,
TO_DATE(A.ACOPDT, 'YYYYMMDD') AS OPEN_DATE,
TO_DATE(A.ACCLDT, 'YYYYMMDD') AS CLOSE_DATE,
TO_DATE(A.ACMADT, 'YYYYMMDD') AS MATURE_DATE,
A.CUSNUM AS CUST_NO,
CASE WHEN A.PRCLS1=2 THEN '2' ELSE '3' END
AS CUST_TYPE,
A.ACTNAM AS CUST_NAME,
A.PRODCD AS PRODUCT_NO,
--A.CUNKZL AS ACCT_TYPE,
A.ACTCD1 AS ACCT_ATTRIBUTE,
A.ACOPTL AS OPEN_TELLER,
A.ACCLTL AS CLOSE_TELLER,
TO_DATE(A.SCYWRQ, 'YYYYMMDD') AS LAST_TRAN_DATE,
A.DPZHZT AS STATUS,
A.SFXHDK AS RELATION_LOAN_FLAG,
--J.ACTINR AS INTEREST_RATE,
CASE WHEN to_date(A.NUPDAT,'yyyymmdd') > I_DATA_DATE then NVL(A.LDAYBL, 0) ELSE NVL(A.CURBAL, 0) END
AS BAL,
NVL(G.D_AMT_D, 0) AS D_AMT_D,
NVL(G.C_AMT_D, 0) AS C_AMT_D,
NVL(G.D_TRAN_NUM_D, 0) AS D_TRAN_NUM_D,
NVL(G.C_TRAN_NUM_D, 0) AS C_TRAN_NUM_D,
A.CUNKZL AS DEPOSIT_TYPE,
A.CUACNO AS CUACNO
FROM ODS_CBS_DEPOSIT_ADPXX A
LEFT JOIN OM_ORGANIZATION B ON A.ACOPBR=B.ORGCODE
LEFT JOIN ODS_CBS_ACCOUT_PYWDH C ON A.YEWUDH=C.YEWUDH /*核心-业务代号参数表 */
LEFT JOIN (SELECT FAREDM,DPACNO,
SUM(C_AMT_D) AS C_AMT_D,
SUM(C_TRAN_NUM_D) AS C_TRAN_NUM_D,
SUM(D_AMT_D) AS D_AMT_D,
SUM(D_TRAN_NUM_D) AS D_TRAN_NUM_D
FROM(
SELECT FAREDM,DPACNO,
CASE WHEN JIEDBZ = '1' THEN TRAAMT ELSE 0 END AS C_AMT_D,
CASE WHEN JIEDBZ = '1' THEN 1 ELSE 0 END AS C_TRAN_NUM_D,
CASE WHEN JIEDBZ = '0' THEN TRAAMT ELSE 0 END AS D_AMT_D,
CASE WHEN JIEDBZ = '0' THEN 1 ELSE 0 END AS D_TRAN_NUM_D
FROM ODS_CBS_DEPOSIT_BDPAL /*核心-账户余额发生明细*/
WHERE TO_DATE(JIOYRQ,'yyyymmdd') = I_DATA_DATE
) GROUP BY FAREDM,DPACNO
) G
ON A.FAREDM = G.FAREDM
AND A.DPACNO = G.DPACNO
WHERE (A.PRCLS1=2 OR A.PRCLS1=3) AND A.YETBBZ='1' -- AND A.RECSTA = '0'
AND INSTR(C.KMUHAO,'2013')=0
AND INSTR(C.KMUHAO,'201601')=0;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
V_LOG_CODE := '';
V_LOG_DETAIL := 'ERROR: 插入对公存款接口表SP_PMM_CACCT_BASE_INFO出错:'|| SQLCODE || SQLERRM;
RAISE ERR_EXCEPTION;
END;
---开始插入结构性存款和应解汇款余额----------------------------
BEGIN
INSERT INTO PMM_CACCT_BASE_INFO(
DATA_DATE , /*数据日期 */
ACCT_NO , /*账号 */
AREA_NO , /*区域编码 */
ITEM_NO , /*科目号 */
ORG_NO , /*机构号 */
CURRENCY , /*币种 */
--TERM_NO /*期限 */
--OPEN_DATE /*开户日期 */
--CLOSE_DATE /*销户日期 */
--MATURE_DATE /*到期日期 */
--CUST_NO /*客户号 */
CUST_TYPE , /*客户类型 */
CUST_NAME , /*客户名称 */
--PRODUCT_NO /*产品编号 */
----MAIN_ACCT_NO /*主账号 */
--CARD_NO /*卡号 */
--ACCT_TYPE /*账户类型 */
--ACCT_ATTRIBUTE /*账户属性 */
--BELONG_MARK /*归属标志 */
--OPEN_TELLER /*开户柜员 */
--CLOSE_TELLER /*销户柜员 */
--LAST_TRAN_DATE /*最后交易日期 */
--STATUS /*账户状态 */
--RELATION_LOAN_FLAG /*贷款关联标志 */
--DEDUCT_ACCT_FLAG /*贷款扣款账户标志*/
--INTEREST_RATE /*利率 */
-- CUACNO,
BAL /*余额 */
--BAL_SUM_M /*余额累积(月) */
--BAL_SUM_Q /*余额累积(季) */
--BAL_SUM_Y /*余额累积(年) */
--BAL_AVG_M /*日均(月) */
--BAL_AVG_Q /*日均(季) */
--BAL_AVG_Y /*日均(年) */
--REAL_INTEREST_D /*实际利息(日) */
--REAL_INTEREST_M /*实际利息(月) */
-- REAL_INTEREST_Q /*实际利息(季) */
-- REAL_INTEREST_Y /*实际利息(年) */
--D_AMT_D /*借方发生额(日) */
--D_AMT_M /*借方发生额(月) */
--D_AMT_Q /*借方发生额(季) */
--D_AMT_Y /*借方发生额(年) */
--C_AMT_D /*贷方发生额(日) */
--C_AMT_M /*贷方发生额(月) */
--C_AMT_Q /*贷方发生额(季) */
--C_AMT_Y /*贷方发生额(年) */
--D_TRAN_NUM_D /*借方交易笔数(日)*/
--D_TRAN_NUM_M /*借方交易笔数(月)*/
--D_TRAN_NUM_Q /*借方交易笔数(季)*/
--D_TRAN_NUM_Y /*借方交易笔数(年)*/
--C_TRAN_NUM_D /*贷方交易笔数(日)*/
--C_TRAN_NUM_M /*贷方交易笔数(月)*/
--C_TRAN_NUM_Q /*贷方交易笔数(季)*/
--C_TRAN_NUM_Y /*贷方交易笔数(年)*/
--AGREE_FLAG /*协定标志 */
--DEPOSIT_TYPE /*存款类型 */
--PLEDGED_FLAG /*质押标志 */
--RESIDENT_FLAG /*居民标识 */
--IS_PACU /*三方存管标志 */
--IS_REPWAGE /*代发工资标志 */
--FTP_CP /*创利 */
)
SELECT I_DATA_DATE AS DATA_DATE,
A.KMUHAO||A.JIGOUH AS ACCT_NO,
'0001' AS AREA_NO,
A.KMUHAO AS ITEM_NO,
/*A.JIGOUH */
DECODE(A.JIGOUH,
'0199','0198',
'0299','0298',
'0399','0398',
'0499','0498',
'0599','0598',
'0699','0698',
'0799','0798',
'0899','0898',
'0999','0998') AS ORG_NO,
/*DECODE(HUOBDH,
'01 ','CNY','12 ','GBP','13 ','HKD','14 ','USD',
'18 ','18' ,'27 ','JPY','28 ','CAD','29 ','AUD',
'38 ','EUR','64 ','64' ,'CHF','CHF','CN ','CN ',
'DKK','DKK','FC ','FC ','MOP','MOP','RUR','RUR',
'SEK','SEK','US ','US ') */
'CNY' AS CURRENCY,
--A.ACTERM AS TERM_NO
--TO_DATE(A.ACOPDT 'YYYYMMDD') AS OPEN_DATE
--TO_DATE(A.ACCLDT 'YYYYMMDD') AS CLOSE_DATE
--TO_DATE(A.ACMADT 'YYYYMMDD') AS MATURE_DATE
--A.CUSNUM AS CUST_NO
--CASE WHEN A.PRCLS1=2 THEN '2' ELSE '3' END
'2'AS CUST_TYPE,
kemumc as cust_name,
--A.ACTNAM AS CUST_NAME
--A.PRODCD AS PRODUCT_NO
----A.CUNKZL AS ACCT_TYPE
--A.ACTCD1 AS ACCT_ATTRIBUTE
--A.ACOPTL AS OPEN_TELLER
--A.ACCLTL AS CLOSE_TELLER
--TO_DATE(A.SCYWRQ 'YYYYMMDD') AS LAST_TRAN_DATE
--A.DPZHZT AS STATUS
--A.SFXHDK AS RELATION_LOAN_FLAG
----J.ACTINR AS INTEREST_RATE*/
-- CASE WHEN to_date(A.NUPDAT,'yyyymmdd') > I_DATA_DATE then NVL(A.LDAYBL,0) ELSE NVL(A.CURBAL,0) END ,
nvl(DAIFYE,0) as BAL
--NVL(G.D_AMT_D 0) AS D_AMT_D
--NVL(G.C_AMT_D 0) AS C_AMT_D
--NVL(G.D_TRAN_NUM_D 0) AS D_TRAN_NUM_D
--NVL(G.C_TRAN_NUM_D 0) AS C_TRAN_NUM_D
--A.CUNKZL AS DEPOSIT_TYPE
FROM ODS_CBS_ACCOUT_AKMZZ A
WHERE A.KMUHAO IN ( '2013', '201601')
AND to_date(JIOYRQ,'yyyy-mm-dd')=I_DATA_DATE
AND A.ZNGZQJ = '0'
AND A.HUOBDH = '01'
AND A.JIGOUH IN ('0899',
'0999',
'0199',
'0299',
'0399',
'0499',
'0599',
'0699',
'0799')
;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
V_LOG_CODE := '';
V_LOG_DETAIL := 'ERROR: 插入对公存款接口表PMM_CACCT_BASE_INFO(来源ODS_CBS_ACCOUT_AKMZZ):'|| SQLCODE || SQLERRM;
RAISE ERR_EXCEPTION;
END ;
EXCEPTION
WHEN ERR_EXCEPTION THEN
SP_WRITE_LOG(I_DATA_DATE,V_PROGRAM_NAME,'4',V_LOG_CODE,V_LOG_DETAIL);
COMMIT;
O_RETURN_MSG := V_LOG_DETAIL;
END SP_PMM_CACCT_BASE_INFO;
/
prompt 存储过程调用
prompt Creating procedure SP_PMM_CACCT_BASE_INFO
prompt ===============================
prompt
DECLARE
O_RETURN_MSG VARCHAR(100);
BEGIN
IN_PMM_CACCT_BASE_INFO (SYSDATE,O_RETURN_MSG);
dbms_output.put_line(O_RETURN_MSG);
END;
函数用法积累
u MINUS(减去),INTERSECT(交集)和UNION ALL(并集);
关于集合的概念,中学都应该学过,就不多说了.这三个关键字主要是对数据库的查询结果进行操作,正如其中文含义一样:两个查询,MINUS是从第一个查询结果减去第二个查询结果,如果有相交部分就减去相交部分;否则和第一个查询结果没有区别. INTERSECT是两个查询结果的交集,UNION ALL是两个查询的并集;
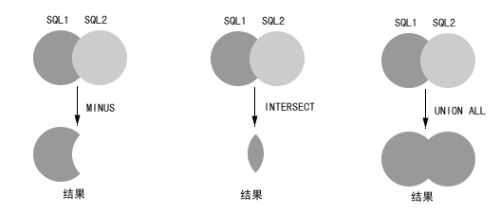
虽然同样的功能可以用简单SQL语句来实现,但是性能差别非常大,有人做过实验:made_order共23万笔记录,charge_detail共17万笔记录:
SELECT order_id FROM made_order
MINUS
SELECT order_id FROM charge_detail
耗时:1.14 sec
SELECT a.order_id FROM made_order a
WHERE a.order_id NOT exists (
SELECT order_id
FROM charge_detail
WHERE order_id = a.order_id
)
耗时:18.19 sec
性能相差15.956倍!因此在遇到这种问题的时候,还是用MINUS,INTERSECT和UNION ALL来解决问题,否则面对业务中随处可见的上百万数据量的查询,数据库服务器还不被咱玩的死翘翘?
PS:应用两个集合的相减,相交和相加时,是有严格要求的:1.两个集合的字段必须明确(用*就不行,报错);2.字段类型和顺序相同(名称可以不同),如:集合1的字段1是NUMBER,字段2是VARCHAR,那么集合2的字段1必须也是NUMBER,字段2必须是VARCHAR;3.不能排序,如果要对结果排序,可以在集合运算后,外面再套一个查询,然后排序,如前面的例子可以改成:
SELECT * FROM (SELECT order_id FROM made_order
MINUS
SELECT order_id FROM charge_detail) ORDER BY ORDER_ID ASC
u IN和EXISTS NOT IN 和NOT EXISTS
- in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
- 如果查询的两个表大小相当,那么用in和exists差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
- 例如:表A(小表),表B(大表)1:select * from A where cc in (select cc from B)
- 效率低,用到了A表上cc列的索引;select * from A where exists(select cc from B where cc=A.cc)
- 效率高,用到了B表上cc列的索引。
- 相反的2:select * from B where cc in (select cc from A)
- 效率高,用到了B表上cc列的索引;select * from B where exists(select cc from A where cc=B.cc)
- 效率低,用到了A表上cc列的索引。
- not in 和not exists
- 如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not exists 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
- not in 逻辑上不完全等同于not exists,如果你误用了not in,小心你的程序存在致命的BUG:
- 请看下面的例子:
- create table t1 (c1 number,c2 number);
- create table t2 (c1 number,c2 number);
- insert into t1 values (1,2);
- insert into t1 values (1,3);
- insert into t2 values (1,2);
- insert into t2 values (1,null);
- select * from t1 where c2 not in (select c2 from t2);
- no rows found
- select * from t1 where not exists (select 1 from t2 where t1.c2=t2.c2);
- c1 c2
- 1 3
- 正如所看到的,not in 出现了不期望的结果集,存在逻辑错误。如果看一下上述两个select语句的执行计划,也会不同。后者使用了hash_aj。
- 因此,请尽量不要使用not in(它会调用子查询),而尽量使用not exists(它会调用关联子查询)。如果子查询中返回的任意一条记录含有空值,则查询将不返回任何记录,正如上面例子所示。
- 除非子查询字段有非空限制,这时可以使用not in ,并且也可以通过提示让它使用hasg_aj或merge_aj连接
u ADD_MONTHS(d,n)
日期运算函数
ADD_MONTHS(d,n)--时间点d再加上n个月
例子:
select sysdate, add_months(sysdate,2) aa from dual;
SYSDATE AA
21-SEP-07 21-NOV-07
u INSTR代替LIKE
t表中将近有1100万数据,很多时候,我们要进行字符串匹配,在语句中,我们通常使用来达到我们搜索的目标。但经过实际发现,like的效率与函数差别相当大。下面是一些测试结果:
SQL> set timing on
SQL> select count(*) from t where instr(title,’手册’)>0;
COUNT(*)
———-
65881
Elapsed: 00:00:11.04
SQL> select count(*) from t where title like ‘%手册%’;
COUNT(*)
———-
65881
Elapsed: 00:00:31.47
SQL> select count(*) from t where instr(title,’手册’)=0;
COUNT(*)
———-
11554580
Elapsed: 00:00:11.31
SQL> select count(*) from t where title not like ‘%手册%’;
COUNT(*)
———-
11554580
另外,我在另外一个2亿多的表,使用8个并行,使用like查询很久都不出来结果,但使用instr,4分钟即完成查找,性能是相当的好。这些小技巧用好,工作效率提高不少。通过上面的测试说明,ORACLE内建的一些函数,是经过相当程度的优化的。
u LIKE和ESCAPE
% 表示零或多个字符 _ 表示一个字符 对于特殊符号可使用 ESCAPE 标识符来查找
select * from emp where ename like '%*_%' escape '*'
上面的 escape 表示*后面的那个符号不当成特殊字符处理,就是查找普通的_符号
u Left join与where的区别
其实以上结果的关键原因就是left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。 而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
在使用left jion时,on和where条件的区别如下:
1、on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
u CONVERT()格式化日期和数值
CONVERT()函数和CAST()函数的功能相同,只是语法不同。CAST()函数一般更容易使用,其功能也更简单。CONVERT()函数的优点是可以格式化日期和数值,它需要两个参数:第1个是目标数据类型,第2个是源数据。以下的两个例子和上一节的例子类似:
SELECT CONVERT(int, '123')
SELECT CONVERT(decimal(9,2), '123.4')
在oracle中,convert函数是用来转字符集转换的。
语法:CONVERT( char, dest_char_set [ ,source_char_set] );
char的参数是要转换的值。它可以是任何的数据类型CHAR , VARCHAR2 , NCHAR , NVARCHAR2 , CLOB或NCLOB 。
dest_char_set参数是char转换的字符集的名称。
source_char_set参数是char是存储在数据库中的字符集,其中的名称。.默认值是数据库的字符集。
Eg: convert(char,'ZHS16GBK','UTF8')
SQL code
SQL> select CONVERT(datatype, 'US7ASCII' ) from BSTH_SYS_FIELD_ALIAS;
--------------------------------------------------------------------------------
gfdfghdf
??
SQL> select CONVERT(datatype, 'ZHS16GBK' ) from BSTH_SYS_FIELD_ALIAS;
--------------------------------------------------------------------------------
gfdfghdf
中文
对日期进行转换:
CONVERT (data_type[(length)], expression [, style])
data_type 目标系统所提供的数据类型,包括 bigint 和 Sql_variant。不能使用用户定义的数据类型。
length :nchar、nvarchar、char、varchar、binary 或 varbinary 数据类型的可选参数。
style:日期格式样式,借以将 datetime 或 smalldatetime 数据转换为字符数据(nchar、nvarchar、char、varchar、nchar 或 nvarchar 数据类型);或者字符串格式样式,借以将 float、real、money 或 smallmoney 数据转换为字符数据(nchar、nvarchar、char、varchar、nchar 或 nvarchar 数据类型)。
u ASCII
返回与指定的字符对应的十进制数;
SQL> select ascii(A) A,ascii(a) a,ascii(0) zero,ascii( ) space from dual;
A A ZERO SPACE
--------- --------- --------- ---------
65 97 48 32
u CHR
给出整数,返回对应的字符;
SQL> select chr(54740) zhao,chr(65) chr65 from dual;
ZH C
-- -
赵 A
u DateDiff()
首先在oracle中没有datediff()函数
可以用以下方法在oracle中实现该函数的功能:
1.利用日期间的加减运算
天:
ROUND(TO_NUMBER(END_DATE - START_DATE))
小时:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24)
分钟:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24 * 60)
秒:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24 * 60 * 60)
毫秒:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24 * 60 * 60 * 60)
计算2个日期之间的时间间隔数目函数:可以使用 DateDiff 计算两个日期相差的天数,或者当天到当年最后一天之间的星期数。
DateDiff(interval, date1, date2, [firstdayofweek], [firstweekofyear])
Firstdayofweek 可选。指定一个星期的第一天的常数。如果未予指定,则以星期日为第一天。
firstweekofyear 可选。指定一年的第一周的常数。如果未予指定,则以包含 1 月 1 日的星期为第一周
如果 date1 晚于 date2,则 DateDiff 函数返回负数。
interval 参数值:yyyy (年) 、q(季)、 m (月)、 y( 一年的日数)、 d (日)、 w (一周的日数)、 ww (周)、 h( 时)、 n (分钟)、 s (秒)
firstdayofweek 参数的设定值如下:
0 使用 NLS API 设置
1 星期日(缺省值)
2 星期一
3 星期二
4 星期三
5 星期四
6 星期五
7 星期六
firstweekofyear 参数的设定值如下:
0 用 NLS API 设置。
1 从包含 1 月 1 日的星期开始(缺省值)。
2 从第一个其大半个星期在新的一年的一周开始
u Decode():
DECODE(value, if1, then1, if2,then2, if3,then3, . . . else )
Value 代表某个表的任何类型的任意列或一个通过计算所得的任何结果。当每个value值被测试,如果value的值为if1,Decode 函数的结果是then1;如果value等于if2,Decode函数结果是then2;等等。事实上,可以给出多个if/then 配对。如果value结果不等于给出的任何配对时,Decode 结果就返回else 。
需要注意的是,这里的if、then及else 都可以是函数或计算表达式。
Eg1:
select sid,serial#,username,
DECODE(command,
0,’None’,
2,’Insert’,
3,’Select’,
6,’Update’,
7,’Delete’,
8,’Drop’,
‘Other’) command
from v$session where username is not null;
例子2:
DECODE(VALUE,'0','1','2')
若value为0,则为1,否则为2
Eg2:Select decode(columnname,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)From talbename Where …
其中columnname为要选择的table中所定义的column,
·含义解释:
decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)的理解如下:
if (条件==值1) then return(翻译值1)
elsif (条件==值2)then return(翻译值2)
......
elsif (条件==值n) then return(翻译值n)
else return(缺省值)
end if
注:其中缺省值可以是你要选择的column name 本身,也可以是你想定义的其他值,比如Other等;
Eg3: 数据为
1 1 一班 NUM_1
2 2 二班 NUM_2
3 3 三班 NUM_3
4 4 四班 NUM_4
select t.* from classes t order by decode(t.classnum,'NUM_1',4,'NUM_2',3,'NUM_3',1);
1 3 三班 NUM_3
2 2 二班 NUM_2
3 1 一班 NUM_1
4 4 四班 NUM_4
u 行转列wm_concat(column)函数的使用
此函数实现字段合并,可以把列值以","号或其他分隔起来并显示成一行,实现行转列的效果。
eg1:shopping:
-----------------------------------------
u_id goods num
------------------------------------------
1 苹果 2
2 梨子 5
1 西瓜 4
3 葡萄 1
3 香蕉 1
1 橘子 3
=======================
想要的结果为:
--------------------------------
u_id goods_sum
____________________
1 苹果,西瓜,橘子
2 梨子
3 葡萄,香蕉
---------------------------------
- select u_id, wmsys.wm_concat(goods) goods_sum
- from shopping
- group by u_id
想要的结果2:
--------------------------------
u_id goods_sum
____________________
1 苹果(2斤),西瓜(4斤),橘子(3斤)
2 梨子(5斤)
3 葡萄(1斤),香蕉(1斤)
---------------------------------
使用oracle wm_concat(column)函数实现:
- select u_id, wmsys.wm_concat(goods || '(' || num || '斤)' ) goods_sum
- from shopping
- group by u_id
wmsys.wm_concat、sys_connect_by_path、自定义行数实现行列转换:
CREATE TABLE tab_name(ID INTEGER NOT NULL PRIMARY KEY,cName VARCHAR2(20));
CREATE TABLE tab_name2(ID INTEGER NOT NULL,pName VARCHAR2(20));
INSERT INTO tab_name(ID,cName) VALUES (1,'百度');
INSERT INTO tab_name(ID,cName) VALUES (2,'Google');
INSERT INTO tab_name(ID,cName) VALUES (3,'网易');
INSERT INTO tab_name2(ID,pName) VALUES (1,'研发部');
INSERT INTO tab_name2(ID,pName) VALUES (1,'市场部');
INSERT INTO tab_name2(ID,pName) VALUES (2,'研发部');
INSERT INTO tab_name2(ID,pName) VALUES (2,'平台架构');
INSERT INTO tab_name2(ID,pName) VALUES (3,'研发部');
COMMIT;
期望结果:
ID cName pName
1 百度 研发部,市场部
2 Google 研发部
3 网易 研发部,平台架构
方法一:使用wmsys.wm_concat()
SELECT t1.ID,t1.cName,wmsys.wm_concat(t2.pName) FROM tab_name t1,tab_name2 t2 WHERE t1.ID=t2.ID GROUP BY t1.cName,t1.id;
方法二:使用sys_connect_by_path
select id, cName, ltrim(max(sys_connect_by_path(pName, ',')), ',') from (select row_number() over(PARTITION by t1.id ORDER by cName) r,t1.*, t2.pName from tab_name t1, tab_name2 t2 where t1.id = t2.id)
start with r=1 CONNECT by prior r =r-1 and prior id = id group by id ,cName order by id;
方法三:使用自定义函数
create or replace function coltorow(midId INT) RETURN VARCHAR2 is
Result VARCHAR2(1000);
begin
FOR cur IN (SELECT pName FROM tab_name2 t2 WHERE midId=t2.id) LOOP
RESULT:=RESULT||cur.pName||',';
END LOOP;
RESULT:=rtrim(RESULT,',');
return(Result);
end coltorow;
SELECT t1.*,coltorow(t1.ID) FROM tab_name t1,tab_name2 t2 WHERE t1.ID=t2.ID GROUP BY t1.ID,t1.cname ORDER BY t1.ID;
u 字符函数举例
全小写 LOWER('SQL Course')
全大写 UPPER('SQL Course')
首字母大写 INITCAP('SQL Course')
拼接 CONCAT('Good', 'String')
取子串 SUBSTR('String',1,3)
求长度 LENGTH('String')
posstr(arg1,arg2):返回arg2第一次在arg1中出现的位置。
u 数字函数举例
ROUND -- 对数值进行四舍五入操作
TRUNC -- 截断。注意截断和舍入的位数,可以是负数。
ROUND (45.923, 2) 45.92
ROUND (45.923, 0) 46
ROUND (45.923, -1) 50
TRUNC (45.923, 2) 45.92
TRUNC (45.923) 45
TRUNC (45.923, -1) 40
MOD -- 返回两数相除的余数
MOD(1600, 300) -- 100
u 日期函数
Oracle将日期按照内部格式将日期存成以下七个字节-世纪、年、月、日、时、分、秒。
在Oracle中日期缺省的显示格式为:DD - MON - YY 。
可以使用系统变量SYSDATE 获取系统时间。
查看 SYSDATE时,可以使用虚拟表DUAL。
举例:
求两个日期间有多少个月
MONTHS_BETWEEN('01-SEP-95','11-JAN-94')
1.9774194
在日期上加指定的月数
ADD_MONTHS('11-JAN-94',6)
'11-JUL-94'
下一个星期几是什么时候
NEXT_DAY('01-SEP-95','FRIDAY')
'08-SEP-95'
某月最后一天
LAST_DAY('01-SEP-95')
'30-SEP-95'
把日期四舍五入到月份
ROUND('25-MAY-95','MONTH')
01-JUN-95
ROUND('25-MAY-95 ','YEAR')
01-JAN-95
把日期截断到月份
TRUNC('25-MAY-95 ','MONTH')
01-MAY-95
TRUNC('25-MAY-95 ','YEAR')
01-JAN-95
u 转换函数TO_[]
TO_CHAR 将数字或日期转换为字符串
TO_NUMBER 将字符串转换成数字
TO_DATE 将字符串转换成日期在转换函数中会使用格式串
TO_DATE('2007-4-4','yyyy-mm-dd'); TO_DATE('','YYYYMMDD HH24:MI:SS')
TO_CHAR(date, 'fmt')格式串包含在''中, 大小写敏感, 可以是任意有效的日期格式
格式串:
YYYY 表示完整的四位数字年
YEAR 表示英文拼写的年
MM 表示两位数字月
MONTH 表示英文全拼的年
DY 表示三位缩写的星期
DAY 表示英文全拼的星期
一些特殊用法:
时间格式
HH24:MI:SS AM 15:45:32 PM
在格式串中加入字符串
DD " of " MONTH 12 of OCTOBER
用后缀拼出整个日期
ddspth fourteenth
TO_CHAR(number, 'fmt')使用此函数将数字转换成数字
9 表示数字
0 强制为0
$ 设置美元符号
L 使用当前字符集的货币符号
. 小数点
, 千位分隔符
可以使用TO_NUMBER将字符串转换成数字
可以使用TO_DATE将字符串转换成格式日期
TO_DATE ('10 September 1992', 'dd Month YYYY')
使用格式串
TO_DATE(char [, 'fmt'])
u 普通函数
NVL (expr1, expr2)
如果expr1为NULL,返回expr2
NVL2 (expr1, expr2, expr3)
如果expr1为非空,则返回expr2,如果expr1为NULL,则返回expr3
NULLIF (expr1, expr2)
如果expr1=expr2,返回NULL,否则返回expr1
COALESCE (expr1, expr2, ..., exprn)
返回表达式列表中的第一个非空表达式
条件表达式,用case表达式或decode实现条件逻辑
CASE表达式
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
decode函数
DECODE(col|expression, search1, result1
[, search2,result2,...,]
[, default])
分组函数:
AVG (DISTINCT|ALL|n)
COUNT (DISTINCT|ALL|expr|*)
MAX (DISTINCT|ALL|expr)
MIN (DISTINCT|ALL|expr)
STDDEV (DISTINCT|ALL|n)
SUM (DISTINCT|ALL|n)
VARIANCE (DISTINCT|ALL|n)
u 常用SQL字符串函数问题集锦
问:
select * from itemcode where code like '40%'
如何让code=40101001 变成code=401-01-001目前有666个CODE是类似40101001,用什么语句能把它变成401-01-001
答:
update itemcode set code=replace(code,left(code,8),left(code,3)+'-'+substring(code,4,2)+'-'+substring(code,6,3)) where code like '40%'
或:
update itemcode set code=replace(code,left(code,8),left(code,3)||'-'||substr(code,4,2)||'-'||substr(code,6,3)) where code like '40%'(PL/SQL语法)
SQL字符串函数
字符串函数对二进制数据、字符串和表达式执行不同的运算。此类函数作用于CHAR、VARCHAR、 BINARY、 和VARBINARY 数据类型以及可以隐式转换为CHAR 或VARCHAR的数据类型。可以在SELECT 语句的SELECT 和WHERE 子句以及表达式中使用字符串函数。常用的字符串函数有:
一、字符转换函数
1、ASCII()
返回字符表达式最左端字符的ASCII 码值。在ASCII()函数中,纯数字的字符串可不用‘’括起来,但含其它字符的字符串必须用‘’括起来使用,否则会出错。
2、CHAR()
将ASCII 码转换为字符。如果没有输入0 ~ 255 之间的ASCII 码值,CHAR() 返回NULL 。
3、LOWER()和UPPER()
LOWER()将字符串全部转为小写;UPPER()将字符串全部转为大写。
4、STR()
把数值型数据转换为字符型数据。
STR (<float_expression>[,length[, <decimal>]])
length 指定返回的字符串的长度,decimal 指定返回的小数位数。如果没有指定长度,缺省的length 值为10, decimal 缺省值为0。
当length 或者decimal 为负值时,返回NULL;
当length 小于小数点左边(包括符号位)的位数时,返回length 个*;
先服从length ,再取decimal ;
当返回的字符串位数小于length ,左边补足空格。
二、去空格函数
1、LTRIM() 把字符串头部的空格去掉。
2、RTRIM() 把字符串尾部的空格去掉。
三、取子串函数
1、left()
LEFT (<character_expression>, <integer_expression>)
返回character_expression 左起 integer_expression 个字符。
2、RIGHT()
RIGHT (<character_expression>, <integer_expression>)
返回character_expression 右起 integer_expression 个字符。
3、SUBSTRING()
SUBSTRING (<expression>, <starting_ position>, length)
返回从字符串左边第starting_ position 个字符起length个字符的部分。
四、字符串比较函数
1、CHARINDEX()
返回字符串中某个指定的子串出现的开始位置。
CHARINDEX (<’substring_expression’>, <expression>)
其中substring _expression 是所要查找的字符表达式,expression 可为字符串也可为列名表达式。如果没有发现子串,则返回0 值。
此函数不能用于TEXT 和IMAGE 数据类型。
2、PATINDEX()
返回字符串中某个指定的子串出现的开始位置。
PATINDEX (<’%substring _expression%’>, <column_ name>)其中子串表达式前后必须有百分号“%”否则返回值为0。
与CHARINDEX 函数不同的是,PATINDEX函数的子串中可以使用通配符,且此函数可用于CHAR、 VARCHAR 和TEXT 数据类型。
五、字符串操作函数
1、QUOTENAME()
返回被特定字符括起来的字符串。
QUOTENAME (<’character_expression’>[, quote_ character]) 其中quote_ character 标明括字符串所用的字符,缺省值为“[]”。
2、REPLICATE()
返回一个重复character_expression 指定次数的字符串。
REPLICATE (character_expression integer_expression) 如果integer_expression 值为负值,则返回NULL 。
3、REVERSE()
将指定的字符串的字符排列顺序颠倒。
REVERSE (<character_expression>) 其中character_expression 可以是字符串、常数或一个列的值。
4、REPLACE()
返回被替换了指定子串的字符串。
REPLACE (<string_expression1>, <string_expression2>, <string_expression3>) 用string_expression3 替换在string_expression1 中的子串string_expression2。
4、SPACE()
返回一个有指定长度的空白字符串。
SPACE (<integer_expression>) 如果integer_expression 值为负值,则返回NULL 。
5、STUFF()
用另一子串替换字符串指定位置、长度的子串。
STUFF (<character_expression1>, <start_ position>, <length>,<character_expression2>)
如果起始位置为负或长度值为负,或者起始位置大于character_expression1 的长度,则返回NULL 值。
如果length 长度大于character_expression1 中 start_ position 以右的长度,则character_expression1 只保留首字符。
六、数据类型转换函数
1、CAST()
CAST (<expression> AS <data_ type>[ length ])
2、CONVERT()
CONVERT (<data_ type>[ length ], <expression> [, style])
1)data_type为SQL Server系统定义的数据类型,用户自定义的数据类型不能在此使用。
2)length用于指定数据的长度,缺省值为30。
3)把CHAR或VARCHAR类型转换为诸如INT或SAMLLINT这样的INTEGER类型、结果必须是带正号或负号的数值。
4)TEXT类型到CHAR或VARCHAR类型转换最多为8000个字符,即CHAR或VARCHAR数据类型是最大长度。
5)IMAGE类型存储的数据转换到BINARY或VARBINARY类型,最多为8000个字符。
6)把整数值转换为MONEY或SMALLMONEY类型,按定义的国家的货币单位来处理,如人民币、美元、英镑等。
7)BIT类型的转换把非零值转换为1,并仍以BIT类型存储。
8)试图转换到不同长度的数据类型,会截短转换值并在转换值后显示“+”,以标识发生了这种截断。
9)用CONVERT() 函数的style 选项能以不同的格式显示日期和时间。style 是将DATATIME 和SMALLDATETIME 数据转换为字符串时所选用的由SQL Server 系统提供的转换样式编号,不同的样式编号有不同的输出格式。
七、日期函数
1、day(date_expression)
返回date_expression中的日期值
2、month(date_expression)
返回date_expression中的月份值
3、year(date_expression)
返回date_expression中的年份值
4、DATEADD()
DATEADD (<datepart>, <number>, <date>)
返回指定日期date 加上指定的额外日期间隔number 产生的新日期。参数“datepart” 取值如下:
5、DATEDIFF()
DATEDIFF (<datepart>, <date1>, <date2>)
返回两个指定日期在datepart 方面的不同之处,即date2 超过date1的差距值,其结果值是一个带有正负号的整数值。
6、DATENAME()
DATENAME (<datepart>, <date>)
以字符串的形式返回日期的指定部分此部分。由datepart 来指定。
7、DATEPART()
DATEPART (<datepart>, <date>)
以整数值的形式返回日期的指定部分。此部分由datepart 来指定。
DATEPART (dd, date) 等同于DAY (date)
DATEPART (mm, date) 等同于MONTH (date)
DATEPART (yy, date) 等同于YEAR (date)
8、GETDATE()
以DATETIME 的缺省格式返回系统当前的日期和时间
REGEXP_REPLACE
select regexp_replace('123,232,4343,32423,3252,553,23423,5435,2354,234,54535',
'(\d+,\d+,\d+),',
'\1#')
from dual;
Oracle中Decode()函数使用技巧
文章分类:数据库
DECODE函数是ORACLE PL/SQL是功能强大的函数之一,目前还只有ORACLE公司的SQL提供了此函数,其他数据库厂商的SQL实现还没有此功能。DECODE有什么用途呢? 先构造一个例子,假设我们想给智星职员加工资,其标准是:工资在8000元以下的将加20%;工资在8000元以上的加15%,通常的做法是,先选出记录中的工资字段值? select salary into var-salary from employee,然后对变量var-salary用if-then-else或choose case之类的流控制语句进行判断。 如果用DECODE函数,那么我们就可以把这些流控制语句省略,通过SQL语句就可以直接完成。如下:select decode(sign(salary - 8000),1,salary*1.15,-1,salary*1.2,salary from employee 是不是很简洁? DECODE的语法:DECODE(value,if1,then1,if2,then2,if3,then3,...,else),表示如果value等于if1时,DECODE函数的结果返回then1,...,如果不等于任何一个if值,则返回else。初看一下,DECODE 只能做等于测试,但刚才也看到了,我们通过一些函数或计算替代value,是可以使DECODE函数具备大于、小于或等于功能。
decode()函数使用技巧
•软件环境:
1、Windows NT4.0+ORACLE 8.0.4
2、ORACLE安装路径为:C:\ORANT
•含义解释:
decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)
该函数的含义如下:
IF 条件=值1 THEN
RETURN(翻译值1)
ELSIF 条件=值2 THEN
RETURN(翻译值2)
......
ELSIF 条件=值n THEN
RETURN(翻译值n)
ELSE
RETURN(缺省值)
END IF
• 使用方法:
1、比较大小
select decode(sign(变量1-变量2),-1,变量1,变量2) from dual; --取较小值
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
例如:
变量1=10,变量2=20
则sign(变量1-变量2)返回-1,decode解码结果为“变量1”,达到了取较小值的目的。
2、表、视图结构转化
现有一个商品销售表sale,表结构为:
month char(6) --月份
sell number(10,2) --月销售金额
现有数据为:
200001 1000
200002 1100
200003 1200
200004 1300
200005 1400
200006 1500
200007 1600
200101 1100
200202 1200
200301 1300
想要转化为以下结构的数据:
year char(4) --年份
month1 number(10,2) --1月销售金额
month2 number(10,2) --2月销售金额
month3 number(10,2) --3月销售金额
month4 number(10,2) --4月销售金额
month5 number(10,2) --5月销售金额
month6 number(10,2) --6月销售金额
month7 number(10,2) --7月销售金额
month8 number(10,2) --8月销售金额
month9 number(10,2) --9月销售金额
month10 number(10,2) --10月销售金额
month11 number(10,2) --11月销售金额
month12 number(10,2) --12月销售金额
结构转化的SQL语句为:
create or replace view
v_sale(year,month1,month2,month3,month4,month5,month6,month7,month8,month9,month10,month11,month12)
as
select
substrb(month,1,4),
sum(decode(substrb(month,5,2),'01',sell,0)),
sum(decode(substrb(month,5,2),'02',sell,0)),
sum(decode(substrb(month,5,2),'03',sell,0)),
sum(decode(substrb(month,5,2),'04',sell,0)),
oracle sign
oracle--sign 取数字n的符号,大于0返回1,小于0返回-1,等于0返回0 SQL> select sign( 100 ),sign(- 100 ),sign( 0 ) from dual; SIGN(123 ) SIGN(- 100 ) SIGN( 0 ) --------- ---------- --------- 1 - 1 0 SQL> select sign(100),sign(-100),sign(0) from dual; SIGN(123) SIGN(-100) SIGN(0) --------- ---------- --------- 1 -1 0
给用户授可执行函数权限
grant execute on DATE_TEST to inms;
Decode():
DECODE(value, if1, then1, if2,then2, if3,then3, . . . else )
Value 代表某个表的任何类型的任意列或一个通过计算所得的任何结果。当每个value值被测试,如果value的值为if1,Decode 函数的结果是then1;如果value等于if2,Decode函数结果是then2;等等。事实上,可以给出多个if/then 配对。如果value结果不等于给出的任何配对时,Decode 结果就返回else 。
需要注意的是,这里的if、then及else 都可以是函数或计算表达式。
Eg1:
select sid,serial#,username,
DECODE(command,
0,’None’,
2,’Insert’,
3,’Select’,
6,’Update’,
7,’Delete’,
8,’Drop’,
‘Other’) command
from v$session where username is not null;
例子2:
DECODE(VALUE,'0','1','2')
若value为0,则为1,否则为2
Eg2:Select decode(columnname,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)From talbename Where …
其中columnname为要选择的table中所定义的column,
•含义解释:
decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)的理解如下:
if (条件==值1) then return(翻译值1)
elsif (条件==值2)then return(翻译值2)
......
elsif (条件==值n) then return(翻译值n)
else return(缺省值)
end if
注:其中缺省值可以是你要选择的column name 本身,也可以是你想定义的其他值,比如Other等;
Eg3: 数据为
1 1 一班 NUM_1
2 2 二班 NUM_2
3 3 三班 NUM_3
4 4 四班 NUM_4
select t.* from classes t order by decode(t.classnum,'NUM_1',4,'NUM_2',3,'NUM_3',1);
1 3 三班 NUM_3
2 2 二班 NUM_2
3 1 一班 NUM_1
4 4 四班 NUM_4
Oracle 数据库萌新经验小结相关推荐
- 【4如何添加Oracle数据库ORCL2新实例】
4如何添加Oracle数据库ORCL2新实例 输入用户名:sys 输入口令: change_on_install as sysdba select name from v$database; 注意,以 ...
- oracle数据库创建新用户
最近一直在用oracle数据库.有一次在用oracle数据库创建新用户,导入dmp文件时,只把表结构导入成功,并没有数据.研究一番之后,发现是创建用户没有创建好,特此记录以下. 步骤:
- 12c oracle 修改内存_关于Oracle数据库12c 新特性总结
概述 今天主要简单介绍一下Oracle12c的一些新特性,仅供参考. 参考: http://docs.oracle.com/database/121/NEWFT/chapter12102.htm#NE ...
- Oracle 数据库12c 新特性总结
1. 在线重命名和重新定位活跃数据文件 不同于以往的版本,在Oracle数据库12c R1版本中对数据文件的迁移或重命名不再需要太多繁琐的步骤,即把表空间置为只读模式,接下来是对数据文件进行离线操作. ...
- Oracle segment啥意思,关于oracle数据库段segment的小结
段(segment)是一种在数据库中消耗物理存储空间的任何实体(一个段可能存在于多个数据文件中,因为物理的数据文件 是组成逻辑表空间的基本物理存储单位) 今天碰到一个高水位问题: 一个分区表,删除某个 ...
- oracle数据库增加新字段
--Add/modify columns alter table 表名 add 字段名 类型; ---------------------------------------------------- ...
- 深夜发文,大事发生!菊厂萌新的半年挣扎!
深夜发文,大事发生!菊厂萌新的半年挣扎! 引言 找工作阶段 入职萌新阶段 萌新阶段小结 本文首发于微信公众号:来知晓,欢迎造访公众号感受图文并茂版最佳阅读体验 原文链接:深夜发文,大事发生!菊厂萌新的 ...
- oracle中aix至Linux导出,aix 迁移linux oracle数据库
EBS R12的11g库从AIX迁移到Linux不能采用 Cross Platform Incremental Backup 的原因 详见红色字体部分,估计是EBS中一些特殊的object不适用这种方 ...
- oracle数据库集群采用的是形式,铁道部采用Oracle集群数据库进行TMIS系统“三级建库”...
综述 铁道部利用Oracle9i集群数据库系统(Oracle9i RAC),顺利开展铁道部运输管理信息系统(TMIS)的"三级建库"工程--在各铁路局和铁路分局利用Oracle9i ...
最新文章
- C#读取数据库图片显示、缩小、更新
- orcad如何设置模块化设计_充气膜结构送风设置设计以及通风效果如何呢?
- 矩阵求导术(上、下)
- TS对象类型 -- 接口(interface)
- 面试系列12 redis和memcached有什么区别
- WDLINUX (Centos5.8) 安装 bcmath
- JAVA实现Token学习笔记001--Token入门案例
- java日期格式正则表达式_Java-日期 正则表达式
- (10)数据分析-变量分析
- 删除exchange误发邮件
- opensuse安装pycharm
- 大规模分布式系统架构与设计实战
- Redis 菜鸟教程学习笔记- Redis 配置
- 第17章:使用 concurrent.futures 模块处理并发-使用 futures.as_completed 函数立刻获取多线程任务执行结果
- 《众妙之门——网页排版设计制胜秘诀》——导读
- 无线网络性能测试 软件,WiFi性能测试
- html预览页面做成a4纸,html页面,A4纸竖向打印,网页页面的宽度应该设置成多少?...
- 【Unity3D】图片纹理压缩方式,干货走起!
- 企业邮箱安全防盗措施
- 一万个数查找两个重复数,快速二分查找法 O(logN)(转)
热门文章
- 1:60V5A半桥LLC 2: 800w半桥LLC设计资料 1:60V5A半桥LLC 2: 800w半桥LLC设计资料全套
- pmp-隐性知识显性知识
- 什么是产品?什么是产品经理?
- android 3d壁纸源码,3D Wallpaper Parallax app下载-3D Wallpaper Parallax(3D视差壁纸)下载v1.3安卓版-西西软件下载...
- [数据集][VOC][目标检测]西瓜数据集目标检测可用yolo训练-1702张介绍
- 知物由学 | 基于移动设备屏幕触摸数据的模拟点击检测研究与应用
- matlab数学模型怎么写,MATLAB-Mathematical-Modeling 当年数学建模比赛时,收集的代码和自己写 ,在这里和大家分享 249万源代码下载- www.pudn.com...
- WebService应用通信
- 测试贵在坚持,看一名普通测试人员的经历
- DDR200T TFT - LCD 显示屏 显示图片 NucleiStudio 蜂鸟E203 详细教程 RISC-V