阿里云高性能AI服务 -- 基于Docker和EGS一键创建高性能Tensorflow分布式训练
一. 概述
Tensorflow是目前使用最为广泛的深度学习框架之一,但是目前搭建分布式多机多卡训练比较困难,而且Tensorflow原生的分布式的性能很差,特别在云计算虚拟化环境下并行的挑战更大。
为了解决这个问题,我们创建了一个容器镜像:registry.cn-beijing.aliyuncs.com/ai_beijing/deep_learning:vx.x.x,目前包含了Tensorflow很新版本v1.6.0-rc0以及NVidia工具系列很新的版本:CUDA v9.0, cuDNN v7.0.5, NCCL v2.1;分布式训练上引入了horovod v0.11.2 + NCCL v2.1作为高性能Tensorflow分布式运行的框架,Horovod是基于MPI的Tensorflow分布式框架,因此也加入了Tensorflow对OpenMPI v3.0.0的支持,Horovod通过调用NCCL做了多机多卡的环形All-Reduce性能优化,分布式训练性能比原生的Tensorflow提高很多;另外通过Docker容器的host网络、不同的ssh登陆端口和免密登陆,为MPI和NCCL提供了高性能的通信通道;该镜像还打入了支持Horovod的性能优化的ResNet-50分布式训练的Demo程序。
本文通过容器服务一键创建EGS训练集群,并通过容器服务的资源编排一键搭建分布式训练环境,并运行性能优化的ResNet-50分布式训练程序获得基于EGS的高性能分布式训练性能。
二. 创建步骤
2.1. 创建集群
进入阿里云首页:https://www.aliyun.com/
在“弹性计算”里打开“容器服务”,点击“管理控制台”,点击侧边栏的"集群"->"创建Swarm集群":

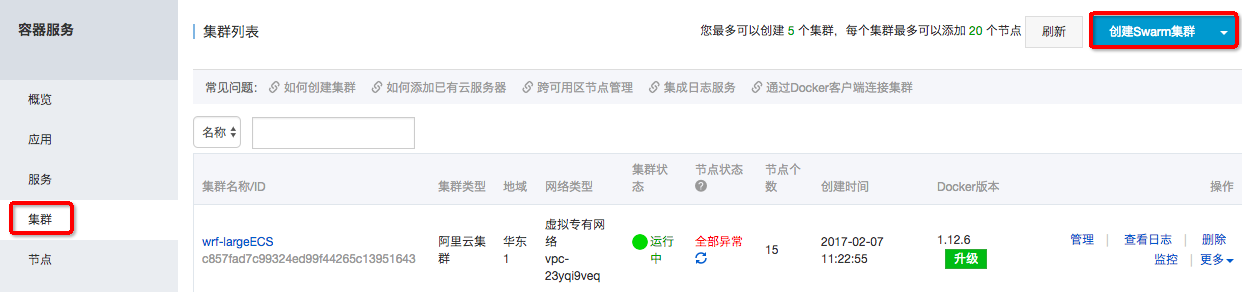
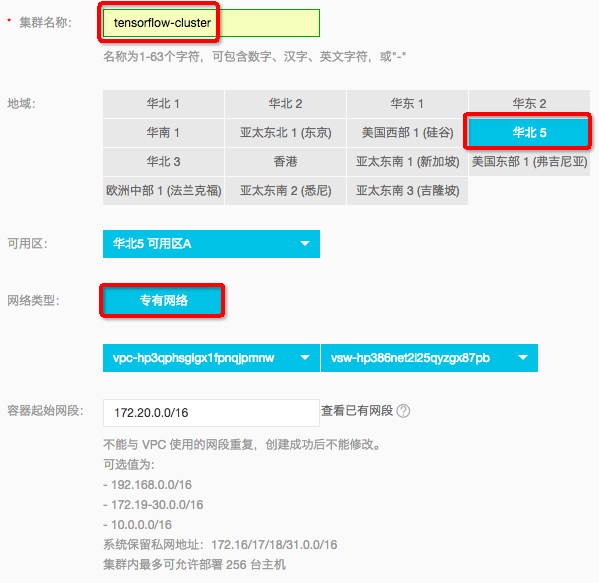
“集群名称”填写:tensorflow-cluster,“地域”选择“华北5”(华北5的EGS特惠),网络类型选择“专有网络”,其他的默认:
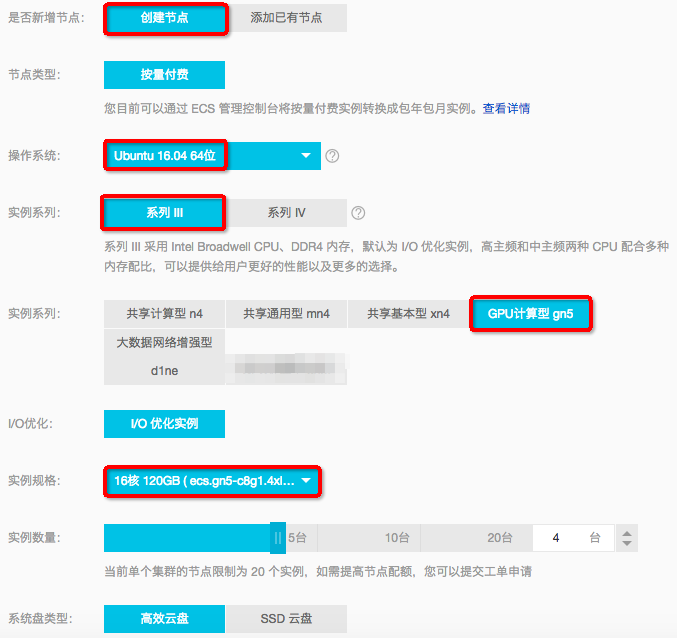
2.2. 创建节点
点击“创建节点”,“操作系统”选择“Ubuntu 16.04 64位”,“实例系列”选择“系列III”,“实例类型”选择“GPU计算型gn5”,“实例规格”选择“ecs.gn5-c8g1.4xlarge”(这是双卡实例:2xP100 GPU、vCPU 16核心、Memory 120GB、网络带宽为Ethernet 8Gbps以太网,也可以选择别的实例),“实例数量”自选,至少需要2台,当前创建了4台:
点击“创建集群”,等待集群创建成功:


2.3. 创建应用
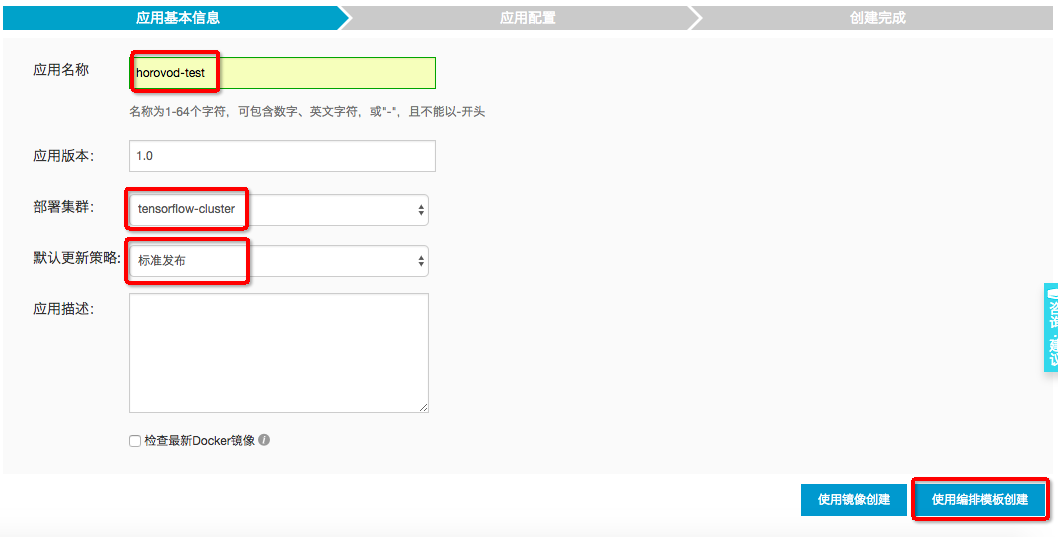
点击侧边栏的“应用”,选择刚才创建的集群,点击“创建应用”:

“应用名称”填“horovod-test”,“部署集群”选刚才创建的集群,点“使用编排模板创建”:
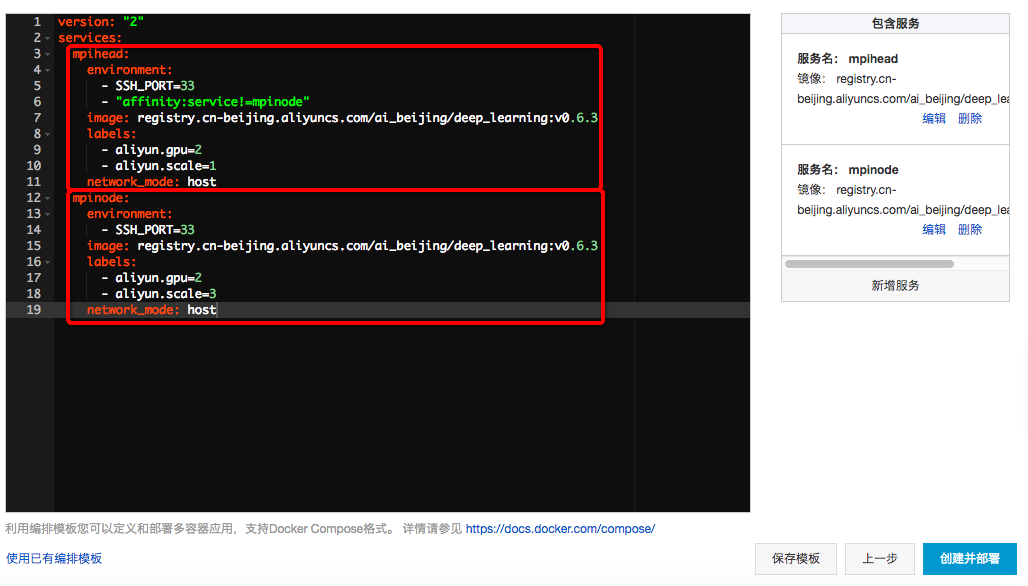
要创建的支持MPI的Service有2种类型,一种是mpihead作为MPI的头节点,设置网络类型为host:network_mode: host,设置ssh通信端口SSH_PORT为33端口(因为使用host网络,需要不同于默认的22端口),image镜像名填:registry.cn-beijing.aliyuncs.com/ai_beijing/deep_learning:vx.x.x,每个容器使用2块GPU:aliyun.gpu=2,mpihead容器数量为1个:aliyun.scale=1;
另一种是mpinode作为MPI的计算节点,设置网络类型为host:network_mode: host,设置ssh通信端口SSH_PORT为33端口,image镜像名填:registry.cn-beijing.aliyuncs.com/ai_beijing/deep_learning:vx.x.x,每个容器使用2块GPU:aliyun.gpu=2,mpinode容器数量为3个:aliyun.scale=3(根据创建的节点数:1个mpihead+3个mpinode=当前创建的4个EGS节点),点击右下角“创建并部署”:
点击“查看应用列表”:

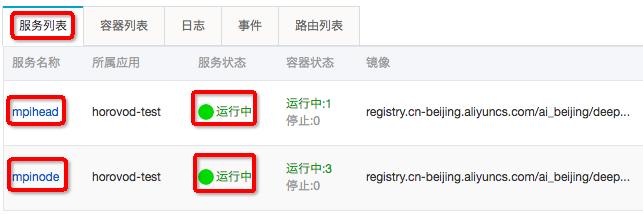
点击刚创建的应用“horovod-test”进去可以看到“服务列表”里的2个服务mpihead, mpinode都运行正常:
2.4. 执行单机多卡训练
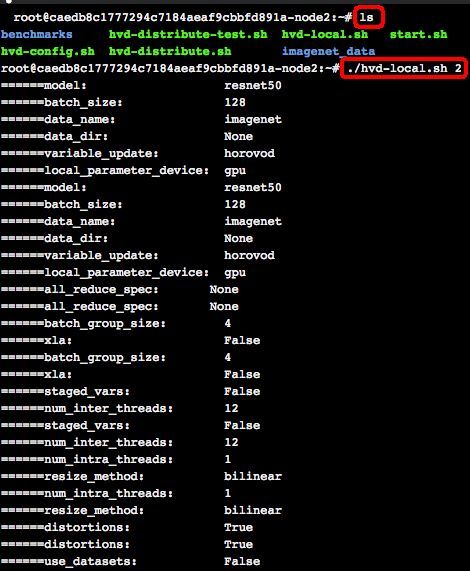
点击“mpihead”,再点击“远程终端”,进入mpihead容器的控制台,执行ls,在当前目录下,benchmark里有ResNet-50的Horovod分布式代码;start.sh是每次容器拉起来都会执行的脚本,会修改ssh的端口号和启动sshd;hvd-local.sh会执行单机多卡的训练程序;hvd-distribute.sh会执行多机多卡训练程序。先执行./hvd-local.sh 1/2,会执行单机1卡和2卡的训练程序:
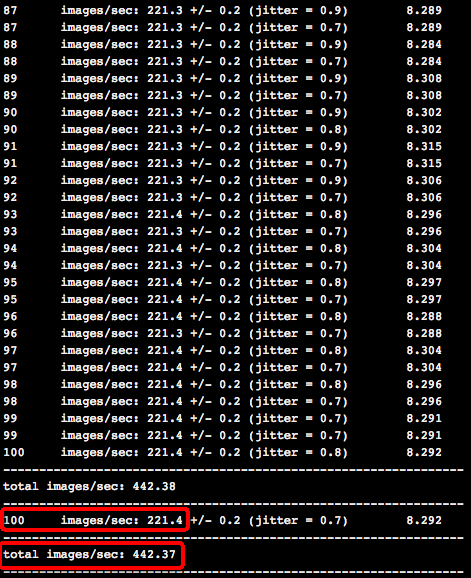
经过100步的训练,双卡训练性能为442.37 images/second:
2.5. 执行多机多卡训练
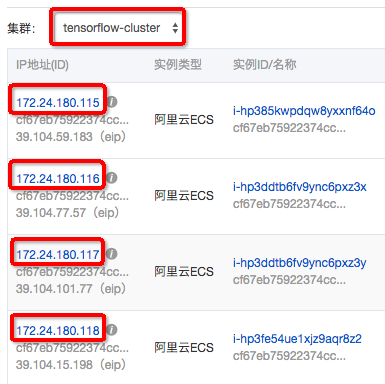
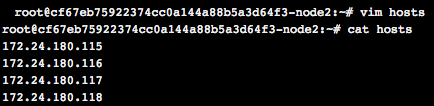
点击左侧栏的“节点”,获取当前集群tensorflow-cluster的所有节点的IP地址,填入到hosts文件中:
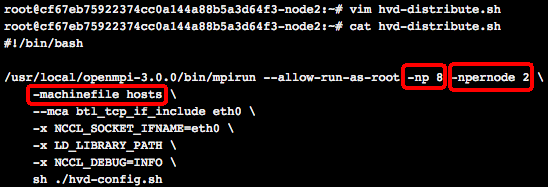
编辑当前“远程终端”下的hvd-distribute.sh文件,-np后面填所有的GPU卡数(这里填4台*2卡=8),-npernode后面填每台节点的GPU卡数(这里每台是2卡),执行./hvd-distribute.sh就会运行4机一共8卡的分布式训练:

经过100步的训练,4机一共8卡训练性能为1701.23 images/second:
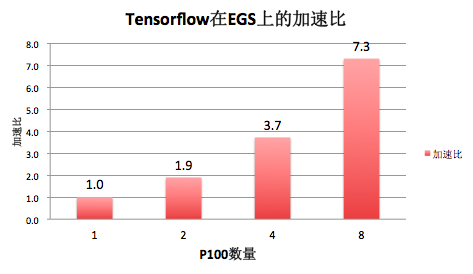
三. 本文Tensorflow多机多卡性能加速比
我们把相关的性能优化都打到docker容器镜像里了,用户可以基于Docker和EGS一键创建高性能Tensorflow分布式训练。本文跑的ResNet-50分布训练,4机一共8块P100比单卡的加速比可以达到7.3倍,多机多卡的并行效率可以达到91.2%。
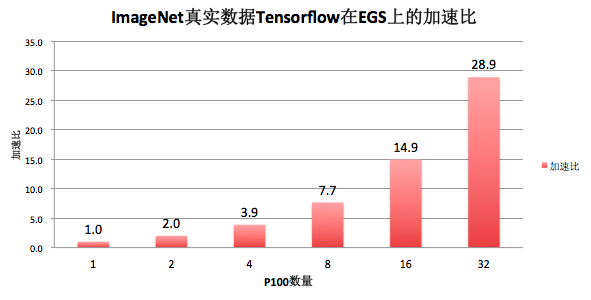
四. 性能优化的ImageNet真实数据Tensorflow的加速比
上面是基于拟合数据的性能,我们在持续优化基于EGS的Tensorflow分布式训练性能,目前ImageNet真实数据的性能加速比如下,4机一共32块P100 GPU比单卡的加速比可以达到28.9倍,多机多卡的并行效率可以达到90.3%。
阿里云高性能AI服务 -- 基于Docker和EGS一键创建高性能Tensorflow分布式训练相关推荐
- 阿里云深度学习实验室(DL-Lab) -- 基于Docker和EGS一键创建高性能Tensorflow分布式训练
原文链接:点击打开链接 摘要: ## 一. 概述 Tensorflow是目前使用最为广泛的深度学习框架之一,但是目前搭建分布式多机多卡训练比较困难,而且Tensorflow原生的分布式的性能很差. 为 ...
- 五、基于github+阿里云容器镜像服务进行docker部署
将代码(jar包)托管在github上,使用阿里云容器镜像服务绑定github上的源代码,实现github上发生变更时,阿里云自动构建镜像,docker从阿里云拉取最新镜像并运行,关系如下: 本例主要 ...
- 阿里云容器镜像服务(Docker Registry)
文章目录 一. 容器镜像服务 二.开通容器镜像服务 三.配置使用 1. 配置Docker官方镜像加速地址 2. 镜像托管 一. 容器镜像服务 说到容器镜像服务,代表作那就是Docker了,和代 ...
- 基于docker的 Hyperledger Fabric 多机环境搭建(上)
环境:ubuntu 16.04 Docker 17.04.0-ce go 1.7.4 consoul v0.8.0.4 ======================================= ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_汇总
小D课堂 - 新版本微服务springcloud+Docker教程_1_01课程简介 小D课堂 - 新版本微服务springcloud+Docker教程_1_02技术选型 小D课堂 - 新版本微服务s ...
- TensorNet——基于TensorFlow的大规模稀疏特征模型分布式训练框架
女主宣言 今天小编为大家分享一篇有关于TensorNet的文章.TensorNet是一个构建在TensorFlow之上针对广告推荐等大规模稀疏场景优化的分布式训练框架.希望能对大家有所帮助. PS:丰 ...
- 阿里云高级技术专家林立翔:基于阿里云弹性GPU服务的神龙AI加速引擎,无缝提升AI训练性能
2023 年 3 月 23 日 14:00,NVIDIA GTC 开发者大会阿里云开发者社区观看入口正式开放,阿里云高级技术专家林立翔带来了题为<基于阿里云弹性 GPU 服务的神龙 AI 加速引 ...
- 基于阿里云容器服务的微服务实践 - Part 1. 微服务与Docker
基于阿里云容器服务的微服务实践 基于阿里云容器服务的微服务实践 - Part 1. 微服务与Docker 作者:chszs,未经博主允许不得转载.经许可的转载需注明作者和博客主页:http://blo ...
- 深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化
作者 | 车漾(阿里云高级技术专家).顾荣(南京大学 副研究员) 导读:Alluxio 项目诞生于 UC Berkeley AMP 实验室,自开源以来经过 7 年的不断开发迭代,支撑大数据处理场景的数 ...
最新文章
- 英特尔变身数据公司 未来最大数据市场定是中国
- 树莓派的Perl 遨游之旅
- 求1+2+......+100的和
- python opencv录制视频_如何使用OpenCV和Python录制视频?
- 【CodeForces - 527C】Glass Carving(线段树或者SBT或者set)
- java中Comparable实现对象的比较
- 思科和华为路由器OSPF之对比学习
- [.NET] 怎样使用 async await 一步步将同步代码转换为异步编程
- 开源数据库再创里程碑,PingCAP 获 2.7 亿美元融资
- C++的性能C#的产能?! - .Net Native 系列向导
- 定时任务_SpringTask 定时任务
- 20201130-C语言-重新认识ASCII码表
- w3school离线手册
- 最新支持备案域名后缀列表
- Swift语言实战晋级-第9章 游戏实战-跑酷熊猫-4 熊猫的跳和打滚
- vue图片时间轴滑动_vue 写的时间区间拖动控件
- 混合波束成形|进阶:深入浅出混合波束赋形
- JQuery之append和appendTo的区别,还有js中的appendChild用法
- 从0到1 拿下C语言——绪论(计算机的组成、进制转换、算法表示、程序结构、C语言基本词汇)
- 高精度仿凡客VANCL 商品属性代码