网站的工作原理:网络开发新手(或任何人)入门
网站的工作原理:网络开发新手(或任何人)入门
![]()
如果您刚接触Web开发,您认为自己知道网络的工作原理 - 至少在基本层面上。
...但是,当您尝试解释一个网站为什么出现空白。 什么是IP地址? “客户 - 服务”模型是如何工作的?
最近开发框架功能很强大。强大到让我们这些新码农忽视了网站工作的基本原理。
我确实是这样, 没什么不好意思承认的:网络很复杂,只有当您开式编程时,您才意识到这些基础知识有多重要。 (如果您想让你的web app正常工作)
所以我写了一个关于这些基础知识的四部分的指南,这些基础每个人都需要掌握,无论你是编程菜鸟还是只是对编程感兴趣。
Part 1: 网站工作原理
第2部分: Web应用程序的结构
第3部分: HTTP和REST
第4部分:客户端 - 服务器交互的代码示例
一个基本的网页搜索
让我们像之前那样开始,在浏览器的地址栏中输入“www.github.com” ,我们会看到页面开始加载。
看起来似乎很简单,幕后却隐藏着一大堆魔法。 让我们来深入学习吧。
定义网络的部分
了解网络是非常麻烦的,因为有很多术语。不幸的是,有些术语对于理解这篇文章的其余部分至关重要。
如果您想了解万维网的秘密,以下是最重要的术语:
客户端:在计算机上运行并连接到互联网的应用程序,如Chrome或Firefox。其主要作用是进行用户交互,并将其转换为对另一台称为Web服务器的计算机的请求。虽然我们通常使用浏览器访问网络,但您可以将整个计算机视为客户端 - 服务器模型的“客户端”。每个客户端计算机都有一个唯一的地址,称为IP地址,其他计算机可以用来识别它。
服务器:连接到互联网且具有IP地址的机器。服务器等待来自其他机器(例如客户机)的请求并对其进行响应。不同于您的计算机(即客户端),服务器也具有IP地址并安装运行特殊的服务器软件,确定如何响应来自浏览器的请求。 Web服务器的主要功能是将网页存储,处理和传送给客户端。有许多类型的服务器,包括Web服务器,数据库服务器,文件服务器,应用程序服务器等。 (在这篇文章中,我们在谈论Web服务器。)
IP地址:互联网协议地址。 TCP / IP网络上的设备(计算机,服务器,打印机,路由器等)的数字标识符。互联网上的每台计算机都有一个IP地址,用于识别和与其他计算机通信。 IP地址有四组数字,以小数点分隔(例如244.155.65.2)。这被称为“逻辑地址”。为了在网络中定位设备,通过TCP / IP协议软件将逻辑IP地址转换为物理地址。这个物理地址(即MAC地址)内置在您的硬件中。 ISP:互联网服务提供商。 ISP是客户端和服务器之间的中间人。典型的ISP通常是“有线电视公司”。当您的浏览器收请求www.github.com, 时,它不会知道在哪里寻找www.github.com, 因此,ISP的工作是进行DNS(域名系统)查找,以询问查找的网站的IP地址。
DNS:域名系统。跟踪计算机的域名及其在互联网上相应IP地址的分布式数据库。不要担心“分布式数据库”如何工作:只需要知道输入www.github.com, 而不是IP地址就行了。
域名:用于标识一个或多个IP地址。用户使用域名(例如www.github.com, )访问互联网上的网站。当您在浏览器中键入域名时,DNS使用它来查找该给定网站的IP地址。
TCP / IP:传输控制协议/互联网协议。最广泛使用的通信协议。 “协议”是一些标准的规则。TCP / IP被用作通过网络传输数据的标准。
端口号:一个16位整数,用于标识服务器上的特定端口,并始终与IP地址相关联。它可以用来识别服务器上可以转发网络请求的特定进程。
主机:连接到网络的计算机 - 它可以是客户端,服务器或任何其他类型的设备。每个主机都有唯一的IP地址。对于www.google.com, 等网站,主机可以是为该网站的网页提供服务的网络服务器。主机和服务器概念经常混合,但是它们是两个不同的东西。服务器是一种主机 - 它们是一个特定的机器。另一方面,提供托管服务来维护多个Web服务器的机器可以称作主机。在这个意义上,您可以从主机运行服务器。
HTTP:超文本传输协议。 Web浏览器和Web服务器用于通过互联网进行通信的协议。
URL:统一资源定位符。 URL识别特定的Web资源。一个简单的例子是https://github.com/someone. URL指定协议(“https”),主机名(github.com)和文件名(某人的个人资料页面)。用户可以从域名为github.com的网络主机通过HTTP获取该URL所标识的Web资源。(很绕口吗?)
从代码到网页的旅程
好的,现在我们有了必要的定义,让我们尝试Github的搜索,看看从地址栏输入一个网址到获取到网页经历了什么:
1)您在浏览器中输入URL ![]()
2)浏览器解析URL中包含的信息。包括协议(“https”),域名(“github.com”)和资源(“/”)。 在这种情况下,“.com”之后没有指示特定的资源,所以浏览器知道检索主(索引)页面 ![]()
3)浏览器与ISP进行通信,对主机的Web服务器的IP地址进行DNS查找www.github.com. DNS服务首先联系根服务器, 查询 https://www.github.com 顶级域服务器的IP地址。 该地址被发送回您的DNS服务。 DNS服务与“.com”名称服务器进行另外的沟通,并请求 https://www.github.com. 的地址。
![]()
source: https://technet.microsoft.com/en-us/library/bb962069.aspx
4)一旦ISP收到目标服务器的IP地址,它会将其发送到您的Web浏览器
![]()
5)您的浏览器从URL中获取IP地址和给定的端口号(HTTP协议默认为端口80,HTTPS默认为端口443),并打开TCP套接字连接。 此时,您的Web浏览器和Web服务器终于连接了。 6) 您的网络浏览器向网页服务器发送HTTP请求,请求 www.github.com. 的主页面
![]() 来自客户端的GET请求
来自客户端的GET请求
7)Web服务器接收请求并查找该HTML页面。 如果页面存在,则Web服务器准备响应并将其发送回您的浏览器。 如果服务器找不到请求的页面,它将发送一个HTTP 404错误消息,代表“找不到页面”。
![]()
服务端响应
8)您的Web浏览器将接收到HTML页面,然后通过它从上到按下解析寻找列出的其他资源,如图像,CSS文件,JavaScript文件等。
![]()
index.html 页面
9)对于列出的每个资源,浏览器重复上述整个过程,向服务器发送HTTP请求。
10)浏览器完成加载HTML页面中列出的所有其他资源后,页面将最终加载到浏览器窗口中,并且连接将被关闭 ![]()
Github
穿越互联网深渊
值得注意的一件事是当您提出信息请求时,如何传输信息。当您发出请求时,该信息被分解成许多称为数据包的小块。每个数据包都标有一个包括源和目标端口号的TCP报头,以及包含源IP地址和目标IP地址作为身份标识的IP报头。然后,数据包通过以太网,WiFi或蜂窝网络传输,并允许在任何路由上经过多次跳转,直到到达目的地。
(我们实际上并不关心数据包到达那里 - 重要的是它们到达目的地安全无恙!)一旦数据包到达目的地,它们将被重新组合。
那么所有的数据包怎么知道如何到达目的地而不会迷路?
答案是TCP / IP。
TCP / IP是一个两部分系统,作为互联网的基本“控制系统”。IP代表互联网协议;其作用是使用每个数据包上的IP头(即IP地址)将数据包发送到其他计算机。传输控制协议(TCP)负责将消息或文件分解成较小的数据包,使用TCP头将数据包路由到目的地计算机上的正确应用程序,如果丢包,则重新发送数据包;一旦到达另一端,重新组装数据包。
绘制最后的图片
等等 - 工作还没有完成! 现在,您的浏览器具有构成网站(HTML,CSS,JavaScript,图像等)的资源,必须通过几个步骤将资源呈现为可读的网页。
您的浏览器有一个渲染引擎,负责显示内容。 渲染引擎以小块形式接收资源的内容。 然后有一个HTML解析算法告诉浏览器如何解析资源。
![]() 一个DOM树
一个DOM树
构建DOM树后,将分析样式表以了解如何对每个节点进行样式化。 使用此信息,浏览器遍历DOM节点并计算每个节点的CSS样式,位置,坐标等。
一旦浏览器具有DOM节点及其样式,那么_最终_就可以将页面绘制到屏幕上了。 结果是:你在互联网上看过的一切。
网络很复杂,但你刚刚完成了很多的工作
所以这就是网络。迷惑吗? 我们都是,但是如果你已经读到这里,你已经完成了最艰难的部分。 我跳过了一些细节,以便在这里向大家展示这个大图; 但是如果你能记起上面列出事件的基本顺序,填写细节将是小菜一碟。
查看Part 2, 在那里我们将讲解一个基本的Web应用程序的结构)
网站工作原理第二部分:客户端 - 服务器模型和Web应用程序的结构
![]()
在 之前文章,我们分析了网站在基本工作原理,包括客户端(您的计算机)和服务器(响应客户端网站请求的另一台计算机)之间的交互。
作为四部分系列的第二部分,让我们双击了解基本Web应用程序的客户端,服务器和其他部分如何配置使您的网络浏览体验成为可能。
客户端 - 服务器模型
通过网络通信的客户端和服务器的这一想法称为“客户端 - 服务器”模型。 这让浏览网站(如此)和与Web应用程序(如Gmail)进行交互变为可能。
客户端 - 服务器模型实际上只是描述Web应用程序中客户端和服务器之间关系的方法 - 就像您可能使用“男朋友”和“女朋友”来描述您的个人关系一样。 信息是从一端到另一端的图像复杂化的细节。
基本Web应用程序配置
有数百种方式来配置Web应用程序。也就是说,大多数人都遵循相同的基本结构:客户端,服务器和数据库。
客户端
客户端是用户与之交互的。 因此,“客户端”代码对用户实际看到的大部分内容负责。 这包括:
1.定义网页的结构
2.设置网页的外观
3.实现响应用户交互的机制(点击按钮,输入文本等)
结构: 您的网页的布局和内容由HTML定义(通常是HTML 5,当涉及到Web app,这话得另说。)
HTML是超文本标记语言。 它允许您使用HTML标签来描述文档的基本物理结构。 每个HTML标签描述文档上的一个特定元素。
![]()
Web浏览器使用这些HTML标签来确定如何显示文档。
外观:为了定义网页的外观,Web开发人员使用CSS,即层叠样式表。 CSS是一种语言,可让您描述HTML中定义的元素应如何展示,允许更改字体,颜色,布局,简单动画和其他外观样式。
您可以为上述HTML页面设置样式,如下所示:
![]()
用户交互:最后,JavaScript处理用户交互。
例如,如果您想在用户单击按钮时执行某些操作,则可能会执行以下操作: ![]()
一些用户交互(如上所述)可以被处理,而无需请求服务器 - 称作“客户端JavaScript”。其他交互需要将请求发送到您的服务器来处理。
例如,如果用户发表评论,则可能需要将该评论存储在数据库中,以使所有的繁杂信息组织在一个位置。 因此,发送请求将用户ID和评论发送到服务器,并且服务器将侦听这些请求并相应地处理它们。
在本系列的下一部分中,我们将深入HTTP请求响应。
服务器
Web应用程序中的服务器监听来自客户端的请求。 当您设置HTTP服务器时,您将其设置监听一个端口号。 端口号始终与计算机的IP地址相关联。
您可以将每个计算机上的端口视为单独的通道,您可以使用它们来执行不同的任务:一个端口可以上网www.facebook.com , 而另一个端口则可以访问您的电子邮件。 这是可能的,因为每个应用程序(Web浏览器和电子邮件客户端)使用不同的端口号。
一旦您设置了HTTP服务器来侦听特定的端口,服务器将等待来自该特定端口的客户端请求,执行该请求所描述的操作,并通过HTTP发送响应请求的数据。
数据库
数据库是网络架构的基础设施 - 我们大多数人都害怕接触他们(前端开发者),但它们至关重要。 数据库是存储信息的地方,可以轻松访问,管理和更新信息。
例如,如果您正在构建社交媒体网站,则会使用数据库来存储有关用户,帖子和评论的信息。 当访问者请求页面时,来自站点的数据库中的数插入到页面,从而允许我们在诸如Facebook等(如Gmail)这样的网站上进行实时的用户互动。
这就是所有基础信息! (好吧,排序...)
就这么简单。 我们只是浏览了Web应用程序的所有基本功能。 ![]()
如何扩展简单的Web应用程序
上述配置对于简单应用来说非常棒。但随着应用程序的扩展,单个服务器将无法处理来自数千个乃至上万)访问者的的并发请求。
为了扩展以满足高并发,我们可以把请求分发到一组后端服务器。
这是事情变得有趣的地方。您有多个服务器,每个服务器都有自己的IP地址。那么域名服务器(DNS)如何知道您的应用程序发送请求到那个服务器?
答案是它不知道。管理所有这些单独实例的方法是通过称为负载平衡器的东西。
负载平衡器充当交通警察,可以最快,最有效的方式跨服务器分配客户端请求。
由于您无法广播所有服务器实例的IP地址,因此您将创建虚拟IP地址,这是您向客户公开广播的地址。此虚拟IP地址指向您的负载平衡器。因此,当您的站点有DNS查找时,它将指向负载均衡器。然后负载均衡器将请求实时分配给各种后端服务器。
您可能想知道负载均衡器如何知道给哪个服务器发送流量。答案:调度算法。
一种流行的算法Round Robin在您的服务器(所有可用的服务器)之间均匀分配传入的请求。如果您的所有服务器具有相似的处理速度和内存,通常会选择此方法。
另一种算法“最小连接”,下一个请求将请求活动链接最少的服务器。
根据您的需要,还可以实现更多的算法。
流程如下所示: ![]()
服务
好的,所以我们通过创建服务器池和负载均衡器来解决我们的流量问题。工作很好,对吧?
...但是,只要复制一堆服务器,仍然会导致问题,因为您的应用程序不断增长。当您为应用程序添加更多功能时,您必须保证服务器数量的增长。为了解决这个问题,我们需要一种解耦服务器功能的方法。
这时服务出现了。服务只是另一个服务器,它只与其他服务器交互,而不是像传统Web服务器与客户端进行交互。
每个服务都有一个独立的功能单元,例如授权用户或提供搜索功能。服务允许您将单个Web服务器分解成多个服务,每个服务执行特定功能。
将单个服务器分解成许多服务的主要好处是它允许您完全独立地扩展服务。
这里的另一个优点是它允许公司内部的团队独立工作,而不是在一台整体式服务器上工作10s,100s甚至1000s,这很快成为项目管理噩梦。
![]() 这里快速说明:负载平衡器和后端服务器和服务的概念在您为应用程序添加越来越多的服务器扩展时变得具有挑战性。 它会像会话持久性那样特别棘手,例如在会话期间如何处理从客户端向同一台服务器发送多个请求以及如何部署负载平衡解决方案。 我们将把这些高级主题留给这个帖子。
这里快速说明:负载平衡器和后端服务器和服务的概念在您为应用程序添加越来越多的服务器扩展时变得具有挑战性。 它会像会话持久性那样特别棘手,例如在会话期间如何处理从客户端向同一台服务器发送多个请求以及如何部署负载平衡解决方案。 我们将把这些高级主题留给这个帖子。
内容分发网络
以上所有功能都适用于扩展,但您的应用程序仍然集中在一个位置。 当您的用户从国家的其他地方(或世界的另一边)访问您的网站时,由于客户端和服务器之间的距离增加,可能会需要更长的加载时间。 毕竟,我们在谈论“万维网”,而不是“局域网”。:) ![]()
解决这个问题的一个普遍策略是使用内容分发网络(CDN)。 CDN是分布在许多数据中心的“代理”服务器的大型分布式系统。代理服务器只是作为客户端和服务器之间的中介的服务器。
拥有大量分布式流量的公司可以选择支付CDN公司,使用CDN的服务器向最终用户提供内容。 CDN的一个例子是Akamai。 Akamai拥有数千台位于世界各地的服务器。
让我们来比较一个网站如何与CDN一起工作。
正如我们在第1节中所讨论的,对于典型的网站,URL的域名被转换为主机服务器的IP地址。
但是,如果客户使用Akamai,则该URL的域名将被转换为由Akamai拥有的边缘服务器的IP地址。然后,Akamai将网络内容提供给客户的用户,而无需请求客户的服务器。
Akamai能够通过存储来自客户服务器的HTML,CSS,软件下载和媒体对象等常用元素来实现这个功能。
![]()
主要目标是让您的网站的内容更接近您的用户。 如果内容不需经过这么远的路由到达用户,这意味着更低的延迟,这将会减少加载时间。
接下里, 阅读 第三部分 我们将会详细介绍 HTTP and REST! :)
我们去了基本的网络架构中的一部分,我的,我们在谈论的Web应用程序结构第二部分。现在是时候卷起袖子来解决第三部分了:仔细看看HTTP和REST。
了解HTTP对Web开发人员至关重要,因为它有助于Web应用程序中的信息流 - 允许更好的用户交互并提高站点性能。
什么是HTTP?
在客户端 - 服务器模型中,客户端和服务器以“请求 - 响应”消息传递模式交换消息:客户端发送请求,服务器返回响应。
跟踪这些消息比听起来更棘手,因此客户端和服务器遵循一种通用语言和一套规则,以便他们知道会发生什么。这种语言或“协议”称为HTTP。
HTTP协议定义语法(数据格式和编码),语义(与语法相关的含义)和定时(速度和排序)。客户端和服务器之间交换的每个HTTP请求和响应都被视为单个HTTP事务。
HTTP:广泛的笔触
在深入了解细节之前,有一些值得注意的关于HTTP的事情。
首先,HTTP是基于文本的,这意味着客户端和服务器之间交换的消息是文本位。每条消息包含两部分:标题和正文。
其次,HTTP是一个应用层协议,这意味着它只是一个标准化主机通信方式的抽象层。HTTP本身不传输数据。它仍然依赖于底层的TCP / IP协议来获取从一台机器到另一台机器的请求和响应。
(提醒一下,TCP / IP是一个由两部分组成的系统,可作为Internet的基本“控制系统”。有关TCP / IP的更多信息,请参阅第I部分)
最后,您可能已经在浏览器的地址栏中看到了协议“HTTPS”,并想知道HTTP是否与HTTP +“S”相同。简短的回答是sorta,略有不同。
普通的HTTP请求或响应未加密,易受各种类型的安全攻击。另一方面,HTTPS是一种更安全的通信,它使用加密来保证安全。它代表HTTP over TLS / SSL。
SSL是一种安全协议,允许客户端和服务器以安全的方式通过网络进行通信 - 防止窃听和篡改 - 同时消息通过网络传输。
客户端通常使用特殊端口号来指示它是否需要TLS / SSL连接:443。一旦客户端和服务器同意使用TLS / SSL进行通信,它们就会通过执行所谓的“TLS握手”来协商有状态连接。然后,客户端和服务器建立秘密会话密钥,它们可以用来在消息相互通信时对消息进行加密和解密。
谷歌和Facebook等许多主要网站都使用HTTPS - 毕竟,它可以保证您的密码,个人信息和信用卡详细信息的安全。
HTTP:精细笔画
有了这些基础知识,让我们更深入地了解HTTP的结构。
我们可以先访问https://www.github.com与GitHub服务器进行通信。如果您使用安装了Firebug扩展程序的Chrome或Firefox,则可以转到“网络”标签调查HTTP请求的详细信息。如果您打开了这个,请访问www.github.com,在地址栏中键入它,您应该看到如下内容:
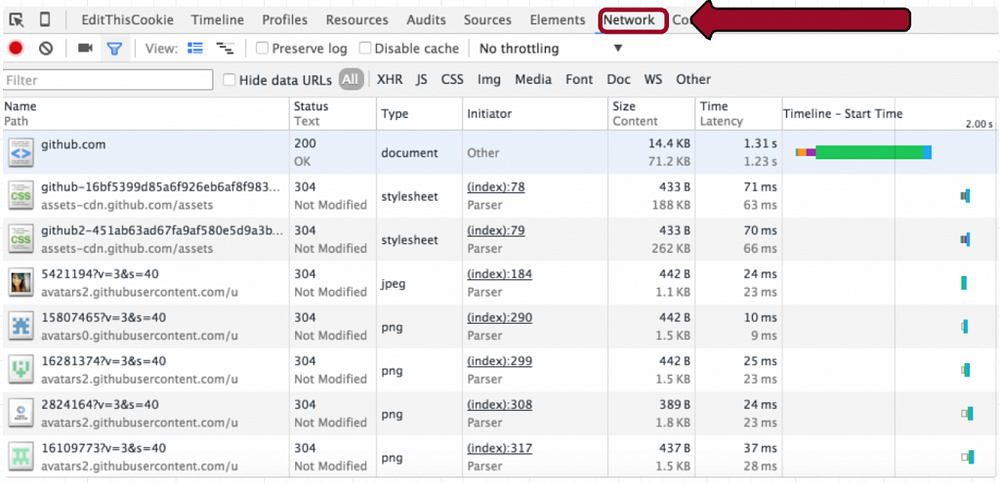
然后在左侧面板上,单击第一个路径“github.com”。您现在应该看到:
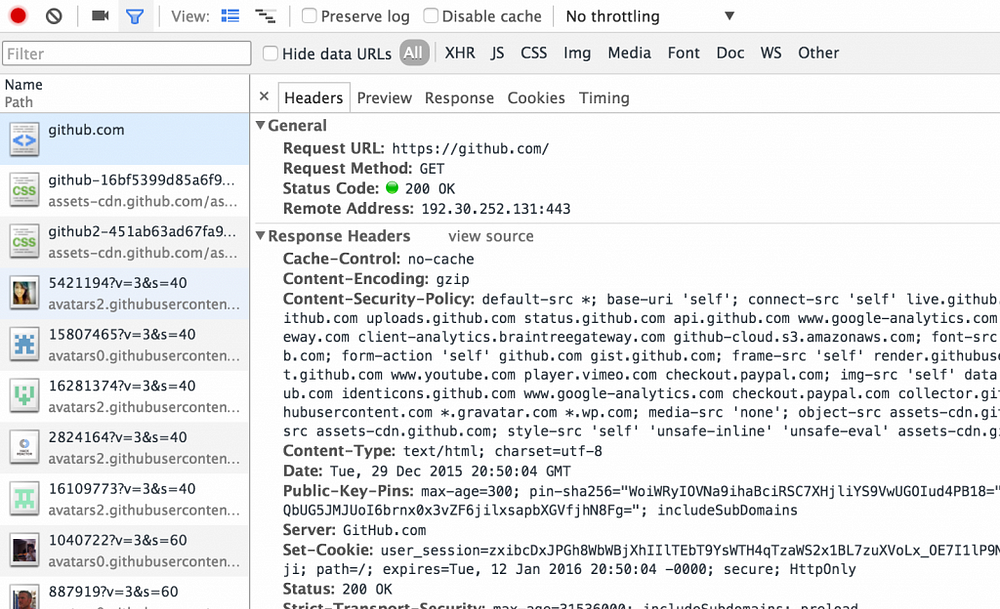
HTTP请求标头
HTTP标头通常包含元数据(有关数据的数据)。元数据包括请求类型(GET与POST与PUT与DELETE),路径,状态代码,内容类型,用户代理,cookie,帖子正文(有时)等。
让我们使用Github示例仔细查看标头的最重要部分,从“响应标头”部分开始:
- 请求网址:https://github.com/
- 我们要求的网址
- 请求方法:GET
- 正在使用的HTTP方法的类型。在我们的例子中,我们的浏览器说:“嘿,Github的服务器,把我带到你的主页。”
- 状态代码:200 OK
- 服务器告知客户端请求结果的标准方法。状态码200表示服务器已成功找到该资源,并将其发送给您。
- 远程地址:192.30.252.129:443
- 我们访问过的GitHub网站的IP地址和端口号。请注意,它的端口号为#443(这意味着我们使用的是HTTPS而不是HTTP)。
- 内容编码:gzip
- 我们收到的资源的编码。在我们的例子中,Github的服务器告诉我们它发回的内容是压缩的。Github可能正在压缩文件,以便您可以更快地下载时间。
- 内容类型:文本/ HTML; 字符集= utf-8的
- 指定响应正文中数据的表示形式,包括类型和子类型。类型描述数据类型,而子类型指定该类型数据的特定格式。在我们的例子中,我们将文本以HTML的形式发回
- 第二部分指定HTML文档的字符编码。这通常是UTF-8,如上所述。
还有一堆标头信息,客户端必须发送这些信息,以便服务器知道如何响应。看看“请求标题”部分:
- 用户代理:Mozilla / 5.0(Macintosh; Intel Mac OS X 10_10_5)AppleWebKit / 537.36(KHTML,与Gecko一样)Chrome / 47.0.2526.73 Safari / 537.36
- 代表用户行事的软件。有时网站需要知道如何查看。因此,浏览器发送此User-Agent字符串,服务器可以使用该字符串来确定用于访问网站的内容
- Accept-Encoding:gzip,deflate,sdch
- 指定浏览器愿意接受的编码内容。我们可以看到列出了gzip,这就是为什么Github的服务器能够以gzip格式向我们发送内容的原因。
- 接受语言:EN-US,EN; Q = 0.8
- 描述我们希望网页所在的语言。在我们的例子中,“en”代表英语。
- 主持人:github.com
- 不言自明:)
- Cookies:_octo = GH1.1.491617779.1446477115; LOGGED_IN =是; dotcom_user = IAM-peekay; _gh_sess = somethingFakesomething FakesomethingFakesomethingFakesomethingFakesomethingFakesomethingFakesomethingFake; user_session = FakesomethingFake somethingFakesomethingFakesomethingFake; _ga = 9389479283749823749; TZ =美国%2FLos_Angeles_
- Web服务器可以存储在用户计算机上并稍后检索的一段文本。信息存储为名称 - 值对。例如,Github为我的请求存储的名称 - 值对之一是“dotcom_user = iam-peekay”,它通知Github我的用户ID是iam-peekay。
tl; dr:所有这些名值对都有什么用?
长话短说,我们留下了很多名称 - 价值对。但是如何创建这些名称 - 值对?
只要您的浏览器访问某个网站,它就会在您的计算机上查找之前由该网站设置的cookie文件。
因此,如果我访问www.github.com,我的浏览器将查找GitHub已保存在硬盘上的cookie文件。如果找到cookie文件,它将发送请求头中的所有名称 - 值对。
GitHub的Web服务器现在可以通过许多不同的方式使用cookie数据,例如根据我存储的用户首选项呈现内容,计算我访问其站点的时间。
如果浏览器找不到cookie文件 - 因为之前从未访问过该站点或者用户阻止或删除了该文件 - 浏览器不会发送任何cookie数据。
在这种情况下,GitHub的服务器会创建一个新ID作为名称 - 值对,以及它想要的任何其他名称 - 值对,并通过HTTP标头将其发送到我的计算机 - 然后我的计算机将其存储在其硬盘上。
HTTP正文
如上所述,服务器保存了与客户端通信所需的大部分重要“元数据”(有关数据的数据)。
现在到了身上。
正如您可能猜到的那样,正文是信息的主体。根据请求的类型,它可以为空。
在我们的示例中,您可以在“响应”选项卡中看到正文。由于我们向www.github.com提出了GET请求,因此正文包含www.github.com的HTML页面内容。
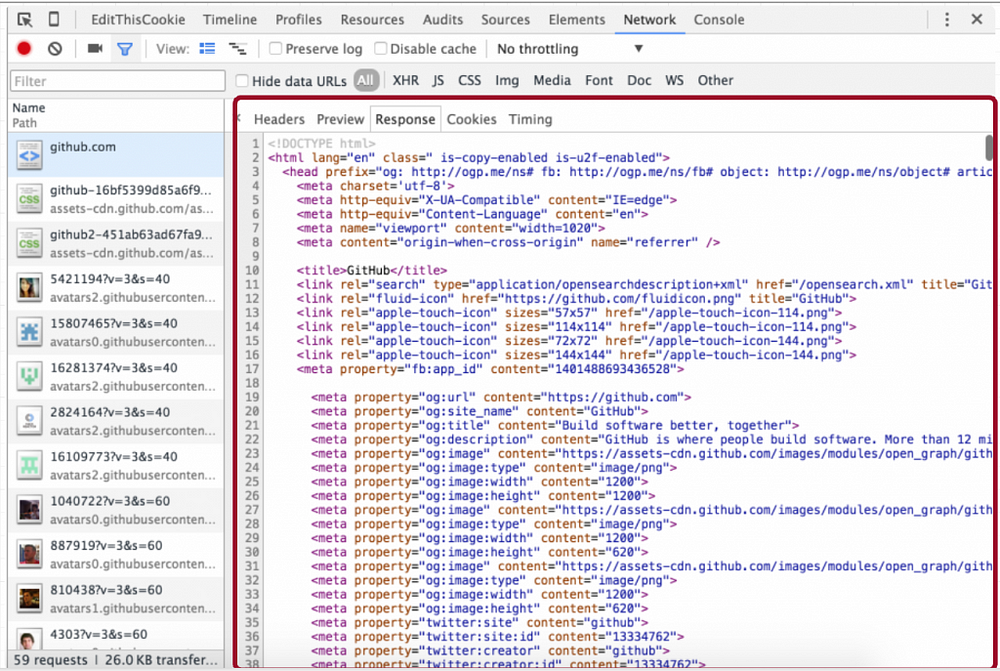
......当然,这对于显示该页面很重要。
额外的练习
我希望这能让您更好地理解HTTP的结构。对于练习,您可以在访问www.github.com时查看浏览器请求的所有其他资产(图像,JavaScript文件等)。
有了这个,让我们看一下客户端可以启动的各种类型的HTTP方法。
HTTP方法
HTTP谓词或方法告诉服务器如何处理URL标识的数据。URL始终标识特定资源。当客户端将URL与HTTP谓词结合使用时,这会告诉服务器需要在哪个资源上执行哪些操作。
URL的示例包括:
- 获取 http://www.example.com/users(获取所有用户)
- POST http://www.example.com/users/a-unique-id(创建新用户)
- PUT http://www.example.com/comments/a-unique-id(更新评论)
- 删除 http://www.example.com/comments/a-unique-id(删除评论)
当客户端发出请求时,它将使用这些动词指示请求的类型。最重要的是GET,POST,PUT和DELETE。还有其他方法,比如HEAD和OPTIONS,但它们比较少见,所以我们将跳过这篇文章。
GET
GET是最常用的方法。它用于从服务器读取给定URL的信息。
GET请求是只读的,这意味着不应该在服务器上修改数据 - 服务器应该只是检索数据不变。通过这种方式,GET请求被认为是安全操作,因为调用它一次或调用它20次将具有相同的效果。
此外,GET请求是幂等的。这意味着向同一个URL提交多个GET请求应该会产生与一个GET请求完全相同的效果,因为GET请求只是要求服务器提供数据而不是实际更改服务器上的任何数据。
如果资源成功找到,则GET请求以状态代码200(OK)响应,如果未找到资源,则返回404(NOT FOUND)。(因此,访问已停用或错误键入的URL时,错误消息的术语“404页面”。)


POST
POST用于创建新资源,例如注册表单。如果要为其他父资源(http://example.com/users)创建从属资源(例如,新用户),则使用POST。您发布到由URL标识的此父资源,服务器处理新资源并将其与父资源相关联。
POST既不安全也不是幂等。这是因为发出两个或多个相同的POST请求可能会导致创建两个新的相同资源。
POST请求使用状态代码201(CREATED)以及具有到新创建的资源的链接的位置标头进行响应。
PUT
PUT用于使用请求正文中的信息更新URL标识的资源。PUT还可用于创建新资源。PUT请求不被视为安全操作,因为它们会修改服务器上的状态。但是,它是幂等的,因为更新资源的多个相同PUT请求应该与第一个具有相同的效果。
如果资源已成功更新,则PUT请求的状态代码为200(OK),如果未找到资源,则为404(NOT FOUND)。
DELETE
DELETE用于删除URL标识的资源。DELETE请求是幂等的,因为如果删除资源,它将被删除,即使您发出多个相同的DELETE请求,结果也是相同的:删除的资源。
如果您为同一资源多次发送DELETE请求,则可能只会收到404错误消息,因为服务器一旦被删除就无法找到它。
如果成功删除DELETE请求,则使用200(OK)状态代码进行响应;如果找不到要删除的资源,则使用404(NOT FOUND)进行响应。
如果处理失败并且服务器出错,则上述所有请求都返回500(内部服务器错误)。
毕竟什么是REST?
在我们称之为一天之前,我有一个最后一个术语:REST。
您之前可能听说过“RESTful应用程序”这个术语。了解这意味着什么很重要,因为如果您使用HTTP在客户端和服务器之间进行通信,那么遵循REST准则是有益的。(事实上,我们上面定义的HTTP谓词代表了REST的大部分内容。)
REST代表“Representational State Transfer”。它是一种用于设计应用程序的架构风格。
基本思想是使用“无状态”,“客户端 - 服务器”,“可缓存”协议在机器之间进行调用 - 通常,此协议是HTTP。这只是一种说法,REST为您提供了一组设计应用程序的约束。这些约束有助于使系统更高性能,可扩展,简单,可修改,可见,便携和可靠。
完整的约束列表很长,您可以在这里相关信息。为了这篇文章,我想双击两个最重要的帖子:
- 统一接口:此约束告诉您如何以简化和分离体系结构的方式定义客户端和服务器之间的接口。它说:
- 资源必须在请求中可识别(例如,通过在URI中使用资源标识符)。资源(例如,数据库中的数据)是定义资源表示的数据(例如,JSON,HTML)。资源和资源表示是分开的 - 客户端仅与资源表示交互。
- 客户端必须具有足够的信息来使用资源的表示来操纵服务器上的资源。
- 客户端和服务器之间交换的每条消息都需要具有自我描述性,并提供有关如何处理消息的信息。
- 客户端必须使用HTTP正文内容,HTTP请求标头,查询参数和URL发送状态数据。服务器必须使用HTTP正文内容,响应代码和响应头发送状态数据。
- 注意:我们上面描述的HTTP谓词构成了这种“统一接口”约束的主要部分,因为它们代表了在资源上发生的统一操作。
2.无状态:此约束表示处理客户端请求所需的所有状态数据必须包含在请求本身(URL,查询参数,HTTP正文或HTTP标头)中,并且服务器必须将所有必需的状态数据发送回客户端通过响应本身(HTTP标头,状态代码和HTTP响应主体)。
附注:状态 - 或应用程序状态 - 是服务器完成请求所必需的数据。
这意味着对于每个请求,我们来回重新发送状态信息,以便服务器不必维护,更新和发送状态。
拥有这样的无状态系统使应用程序的可扩展性更高,因为没有服务器必须担心在多个请求的范围内保持相同的会话状态。获取状态数据所需的一切都可以在请求和响应中找到。
闭幕致辞
唷!HTTP远非简单。但正如您所看到的,它是客户端 - 服务器关系的关键组成部分。
制作RESTful应用程序至少需要对HTTP有基本的了解。有了这些内容,您就可以在下一个编码项目中解读客户端 - 服务器通信的奥秘。
原文链接: medium.freecodecamp.org
转自众成翻译
译文链接
https://www.zcfy.cc/article/how-the-web-works-a-primer-for-newcomers-to-web-development-or-anyone-really
https://www.zcfy.cc/article/how-the-web-works-part-ii-client-server-model-amp-the-structure-of-a-web-application
译者:众里寻他千百度,(part3来自谷歌翻译)
网站的工作原理:网络开发新手(或任何人)入门相关推荐
- 视频网站的工作原理-->m3u8视频文件的提取与解析(理论)
目录 一.视频网站的工作原理 二.抓取视频步骤 2.1.找到m3u8文件 2.2.把m3u8下载到ts文件 2.3.ts文件合并为mp4文件 一.视频网站的工作原理 古老的视频网站的视频一般是在源码放 ...
- 一文看懂汽车电子ECU bootloader工作原理及开发要点
随着半导体技术的不断进步(按照摩尔定律),MCU内部集成的逻辑功能外设越来越多,存储器也越来越大.消费者对于汽车节能(经济和法规对排放的要求)型.舒适性.互联性.安全性(功能安全和信息安全)的要求越来 ...
- FPGA组成、工作原理和开发流程
********************************LoongEmbedded******************************** 作者:LoongEmbedded(kandi ...
- 网络原理——网络开发
目录 网络开发 套接字 Java中使用UDP协议,相关的类介绍 DatagramSocket API DatagramPacket API InetSocketAddress API 服务器和客户端 ...
- FPGA概念、芯片结构、工作原理、开发流程以及xilinx公司主要可编程芯片
一.FPGA概念 可编程逻辑器件(Programmable Logic Device,PLD) 专用集成电路(Application Specific Integrated Circuit,ASIC) ...
- ViewRoot,DecorView,MeasureSpec和View的工作原理——Android开发艺术探索笔记
原文链接 http://sparkyuan.me/ 转载请注明出处 View的绘制流程是从ViewRoot的performTraversals方法開始的.它经过measure.layout和draw三 ...
- 虹科分享 | 基于流的流量分类的工作原理 | 网络流量监控
许多ntop产品,如ntopng.nProbe和PF_RING FT等都是基于网络流的.然而,并不是所有的用户都详细知道什么是网络流,以及它在实践中是如何工作的.这篇博客文章描述了它们是什么以及它们在 ...
- 解析新时代人工智能机器人的工作原理
尽管过去几年机器人学习取得了长足的进步,但在尝试模仿精确或复杂行为时,机器人智能体的某些策略仍然难以果断地选择操作.格物斯坦表示:每一种方法都需要精确的移动和修正.机器人必须只遵从其中一个选择,还必须 ...
- CDN工作过程及工作原理
CDN(Content Delivery Network)即内容分发网络,CDN的作用是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度.本文介绍CDN的工作 ...
最新文章
- mysql8.0 服务移除_Linux下彻底删除Mysql 8.0服务的方法
- PostgreSQL10.5安装后(Win10)环境变量配置与运行
- 如何清除服务器物理内存,服务器怎样清理物理内存
- when busy dialog closed iDuration renderFioriFlower jQuery Animation closeL
- 输出日志实例改成用Spring的AOP来实现
- 一次执行truncate触发ORA-02266解决过程
- java dom4j读写xml_Java:简单的读写XML文件之使用DOM4J读写
- 畅通工程(自己写的BFS,但后面想了下并查集更好更快)
- iStack详解(一)——iStack基本原理
- 1、Python基本对象类型----数字
- COleDateTime 使用方法
- linux备份文件_aptclone:备份已安装的软件包并在新的 Ubuntu 系统上恢复它们 | Linux 中国...
- C4D 展UV的那些坑
- 图形桌面与命令行模式相关切换快捷键
- Septentrio板卡接收机连接方式
- android补间动画有哪几种,Android补间动画、属性动画 常用功能总结
- 邮箱如何撤回已发送的邮件?
- 图片转文字的实用方法
- 计算机应用基础(专)【7】
- 积木拼图游戏-儿童游戏免费拼图3-6岁
热门文章
- tcpdump提取源IP
- MySQL插入emoji表情错误的2种解决方案,Incorrect string value: '\xF0\x9F\x98\x84'
- 在Ubuntu上安装NTL
- Apple Configurator 2使用教程: 修复或恢复搭载 Apple M1芯片的 Mac!
- 水管工游戏(代码附带注释)2020.10.6
- mysql8.0源码分析——文件管理fil_system
- 爱上python系列------python上下文管理器(二):对suppress进行装饰器重新实现
- 炉石传说服务器维修,《炉石》服务器崩溃,全部被强制回档,玩家损失几百万!...
- 如何查看博客是否被搜索引擎收录
- 一个阿里小二“改写”了《阿里巴巴与四十大盗》 | 悦读