推荐系统遇上深度学习(二十)-贝叶斯个性化排序算法原理及实战
排序推荐算法大体上可以分为三类,第一类排序算法类别是点对方法(Pointwise Approach),这类算法将排序问题被转化为分类、回归之类的问题,并使用现有分类、回归等方法进行实现。第二类排序算法是成对方法(Pairwise Approach),在序列方法中,排序被转化为对序列分类或对序列回归。所谓的pair就是成对的排序,比如(a,b)一组表明a比b排的靠前。第三类排序算法是列表方法(Listwise Approach),它采用更加直接的方法对排序问题进行了处理。它在学习和预测过程中都将排序列表作为一个样本。排序的组结构被保持。
之前我们介绍的算法大都是Pointwise的方法,今天我们来介绍一种Pairwise的方法:贝叶斯个性化排序(Bayesian Personalized Ranking, 以下简称BPR)
1、BPR算法简介
1.1 基本思路
在BPR算法中,我们将任意用户u对应的物品进行标记,如果用户u在同时有物品i和j的时候点击了i,那么我们就得到了一个三元组<u,i,j>,它表示对用户u来说,i的排序要比j靠前。如果对于用户u来说我们有m组这样的反馈,那么我们就可以得到m组用户u对应的训练样本。
这里,我们做出两个假设:
- 每个用户之间的偏好行为相互独立,即用户u在商品i和j之间的偏好和其他用户无关。
- 同一用户对不同物品的偏序相互独立,也就是用户u在商品i和j之间的偏好和其他的商品无关。
为了便于表述,我们用>u符号表示用户u的偏好,上面的<u,i,j>可以表示为:i >u j。
在BPR中,我们也用到了类似矩阵分解的思想,对于用户集U和物品集I对应的U*I的预测排序矩阵,我们期望得到两个分解后的用户矩阵W(|U|×k)和物品矩阵H(|I|×k),满足:

那么对于任意一个用户u,对应的任意一个物品i,我们预测得出的用户对该物品的偏好计算如下:

而模型的最终目标是寻找合适的矩阵W和H,让X-(公式打不出来,这里代表的是X上面有一个横线,即W和H矩阵相乘后的结果)和X(实际的评分矩阵)最相似。看到这里,也许你会说,BPR和矩阵分解没有什区别呀?是的,到目前为止的基本思想是一致的,但是具体的算法运算思路,确实千差万别的,我们慢慢道来。
1.2 算法运算思路
BPR 基于最大后验估计P(W,H|>u)来求解模型参数W,H,这里我们用θ来表示参数W和H, >u代表用户u对应的所有商品的全序关系,则优化目标是P(θ|>u)。根据贝叶斯公式,我们有:

由于我们求解假设了用户的排序和其他用户无关,那么对于任意一个用户u来说,P(>u)对所有的物品一样,所以有:

这个优化目标转化为两部分。第一部分和样本数据集D有关,第二部分和样本数据集D无关。
第一部分
对于第一部分,由于我们假设每个用户之间的偏好行为相互独立,同一用户对不同物品的偏序相互独立,所以有:

上面的式子类似于极大似然估计,若用户u相比于j来说更偏向i,那么我们就希望P(i >u j|θ)出现的概率越大越好。
上面的式子可以进一步改写成:

而对于P(i >u j|θ)这个概率,我们可以使用下面这个式子来代替:

其中,σ(x)是sigmoid函数,σ里面的项我们可以理解为用户u对i和j偏好程度的差异,我们当然希望i和j的差异越大越好,这种差异如何体现,最简单的就是差值:
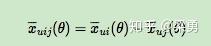
省略θ我们可以将式子简略的写为:

因此优化目标的第一项可以写作:

哇,是不是很简单的思想,对于训练数据中的<u,i,j>,用户更偏好于i,那么我们当然希望在X-矩阵中ui对应的值比uj对应的值大,而且差距越大越好!
第二部分
回想之前我们通过贝叶斯角度解释正则化的文章:https://www.jianshu.com/p/4d562f2c06b8
当θ的先验分布是正态分布时,其实就是给损失函数加入了正则项,因此我们可以假定θ的先验分布是正态分布:

所以:

因此,最终的最大对数后验估计函数可以写作:

剩下的我们就可以通过梯度上升法(因为是要让上式最大化)来求解了。我们这里就略过了,BPR的思想已经很明白了吧,哈哈!让我们来看一看如何实现吧。
2、算法实现
本文的github地址为:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-BPR-Demo
所用到的数据集是movieslen 100k的数据集,下载地址为:http://grouplens.org/datasets/movielens/
数据预处理
首先,我们需要处理一下数据,得到每个用户打分过的电影,同时,还需要得到用户的数量和电影的数量。
def load_data():user_ratings = defaultdict(set)max_u_id = -1max_i_id = -1with open('data/u.data','r') as f:for line in f.readlines():u,i,_,_ = line.split("\t")u = int(u)i = int(i)user_ratings[u].add(i)max_u_id = max(u,max_u_id)max_i_id = max(i,max_i_id)print("max_u_id:",max_u_id)print("max_i_idL",max_i_id)return max_u_id,max_i_id,user_ratings
下面我们会对每一个用户u,在user_ratings中随机找到他评分过的一部电影i,保存在user_ratings_test,后面构造训练集和测试集需要用到。
def generate_test(user_ratings):"""对每一个用户u,在user_ratings中随机找到他评分过的一部电影i,保存在user_ratings_test,我们为每个用户取出的这一个电影,是不会在训练集中训练到的,作为测试集用。"""user_test = dict()for u,i_list in user_ratings.items():user_test[u] = random.sample(user_ratings[u],1)[0]return user_test
构建训练数据
我们构造的训练数据是<u,i,j>的三元组,i可以根据刚才生成的用户评分字典得到,j可以利用负采样的思想,认为用户没有看过的电影都是负样本:
def generate_train_batch(user_ratings,user_ratings_test,item_count,batch_size=512):"""构造训练用的三元组对于随机抽出的用户u,i可以从user_ratings随机抽出,而j也是从总的电影集中随机抽出,当然j必须保证(u,j)不在user_ratings中"""t = []for b in range(batch_size):u = random.sample(user_ratings.keys(),1)[0]i = random.sample(user_ratings[u],1)[0]while i==user_ratings_test[u]:i = random.sample(user_ratings[u],1)[0]j = random.randint(1,item_count)while j in user_ratings[u]:j = random.randint(1,item_count)t.append([u,i,j])return np.asarray(t)
构造测试数据
同样构造三元组,我们刚才给每个用户单独抽出了一部电影,这个电影作为i,而用户所有没有评分过的电影都是负样本j:
def generate_test_batch(user_ratings,user_ratings_test,item_count):"""对于每个用户u,它的评分电影i是我们在user_ratings_test中随机抽取的,它的j是用户u所有没有评分过的电影集合,比如用户u有1000部电影没有评分,那么这里该用户的测试集样本就有1000个"""for u in user_ratings.keys():t = []i = user_ratings_test[u]for j in range(1,item_count + 1):if not(j in user_ratings[u]):t.append([u,i,j])yield np.asarray(t)
模型构建
首先回忆一下我们需要学习的参数θ,其实就是用户矩阵W(|U|×k)和物品矩阵H(|I|×k)对应的值,对于我们的模型来说,可以简单理解为由id到embedding的转化,因此有:
u = tf.placeholder(tf.int32,[None])
i = tf.placeholder(tf.int32,[None])
j = tf.placeholder(tf.int32,[None])user_emb_w = tf.get_variable("user_emb_w", [user_count + 1, hidden_dim],initializer=tf.random_normal_initializer(0, 0.1))
item_emb_w = tf.get_variable("item_emb_w", [item_count + 1, hidden_dim],initializer=tf.random_normal_initializer(0, 0.1))u_emb = tf.nn.embedding_lookup(user_emb_w, u)
i_emb = tf.nn.embedding_lookup(item_emb_w, i)
j_emb = tf.nn.embedding_lookup(item_emb_w, j)
回想一下我们要优化的目标,第一部分是ui和uj对应的预测值的评分之差,再经由sigmoid变换得到的[0,1]值,我们希望这个值越大越好,对于损失来说,当然是越小越好。因此,计算如下:
x = tf.reduce_sum(tf.multiply(u_emb,(i_emb-j_emb)),1,keep_dims=True)
loss1 = - tf.reduce_mean(tf.log(tf.sigmoid(x)))
第二部分是我们的正则项,参数就是我们的embedding值,所以正则项计算如下:
l2_norm = tf.add_n([tf.reduce_sum(tf.multiply(u_emb, u_emb)),tf.reduce_sum(tf.multiply(i_emb, i_emb)),tf.reduce_sum(tf.multiply(j_emb, j_emb))])
因此,我们模型整个的优化目标可以写作:
regulation_rate = 0.0001
bprloss = regulation_rate * l2_norm - tf.reduce_mean(tf.log(tf.sigmoid(x)))train_op = tf.train.GradientDescentOptimizer(0.01).minimize(bprloss)
至此,我们整个模型就介绍完了,如果大家想要了解完整的代码实现,可以参考github哟。
3、总结
1.BPR是基于矩阵分解的一种排序算法,它不是做全局的评分优化,而是针对每一个用户自己的商品喜好分贝做排序优化。
2.它是一种pairwise的排序算法,对于每一个三元组<u,i,j>,模型希望能够使用户u对物品i和j的差异更明显。
3.同时,引入了贝叶斯先验,假设参数服从正态分布,在转换后变为了L2正则,减小了模型的过拟合。
参考文献
1、http://www.cnblogs.com/pinard/p/9128682.html
2、http://www.cnblogs.com/pinard/p/9163481.html
推荐系统遇上深度学习(二十)-贝叶斯个性化排序算法原理及实战相关推荐
- 推荐系统遇上深度学习(二十一)--贝叶斯个性化排序(BPR)算法原理及实战
笔者是一个痴迷于挖掘数据中的价值的学习人,希望在平日的工作学习中,挖掘数据的价值,找寻数据的秘密,笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据 ...
- 知识图谱论文阅读(八)【转】推荐系统遇上深度学习(二十六)--知识图谱与推荐系统结合之DKN模型原理及实现
学习的博客: 推荐系统遇上深度学习(二十六)–知识图谱与推荐系统结合之DKN模型原理及实现 知识图谱特征学习的模型分类汇总 知识图谱嵌入(KGE):方法和应用的综述 论文: Knowledge Gra ...
- 推荐系统遇上深度学习(二十二):DeepFM升级版XDeepFM模型强势来袭!
今天我们要学习的模型是xDeepFM模型,论文地址为:https://arxiv.org/abs/1803.05170.文中包含我个人的一些理解,如有不对的地方,欢迎大家指正!废话不多说,我们进入正题 ...
- 推荐系统遇上深度学习(二十)--探秘阿里之完整空间多任务模型ESSM
笔者是一个痴迷于挖掘数据中的价值的学习人,希望在平日的工作学习中,挖掘数据的价值,找寻数据的秘密,笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据 ...
- 推荐系统遇上深度学习(二十六)--知识图谱与推荐系统结合之DKN模型原理及实现
作者:石晓文 Python爱好者社区专栏作者个人公众号:小小挖掘机 添加微信sxw2251,可以拉你进入小小挖掘机技术交流群哟!博客专栏:wenwen 在本系列的上一篇中,我们大致介绍了一下知识图谱在 ...
- 推荐系统遇上深度学习(三十九)-推荐系统中召回策略演进!
推荐系统中的核心是从海量的商品库挑选合适商品最终展示给用户.由于商品库数量巨大,因此常见的推荐系统一般分为两个阶段,即召回阶段和排序阶段.召回阶段主要是从全量的商品库中得到用户可能感兴趣的一小部分候选 ...
- 推荐系统遇上深度学习(二)--FFM模型理论和实践
全文共1979字,6张图,预计阅读时间12分钟. FFM理论 在CTR预估中,经常会遇到one-hot类型的变量,one-hot类型变量会导致严重的数据特征稀疏的情况,为了解决这一问题,在上一讲中,我 ...
- 推荐系统遇上深度学习(三十六)--Learning and Transferring IDs Representation in E-commerce...
本文介绍的文章题目为<Learning and Transferring IDs Representation in E-commerce>,下载地址为:https://arxiv.org ...
- 推荐系统遇上深度学习,9篇阿里推荐论文汇总!
作者 | 石晓文 转载自小小挖掘机(ID: wAIsjwj) 业界常用的推荐系统主要分为两个阶段,召回阶段和精排阶段,当然有时候在最后还会接一些打散或者探索的规则,这点咱们就不考虑了. 前面九篇文章中 ...
最新文章
- 一张心酸得不想起名字的照片,人艰就别拆了好吗 | 每日趣闻
- ie8开发人员工具无法使用,按f12任务栏里出现任务,但是窗体不弹出
- BCH压力测试最终统计
- FastReport.net分组排序、打印顺序、分页、函数使用语法、数据块编辑
- Fedora安装Nvidia显卡驱动方法
- jsp中两个字符串格式的日期可以相减吗_举个栗子!Tableau 技巧(126):学几个常用的日期函数...
- tf.global_variables_initializer()什么时候用?
- mysql数据设置浮动_浮动float
- HDMI和DVI的HDCP握手问题分析及其解决方案精粹
- Kinect+OpenNI学习笔记之2(获取kinect的颜色图像和深度图像)
- markdown测试文章
- 开源微信商城java源码_微信小程序商城 带java后台源码
- 内存分区0x00000000-0x0000FFFF共64K是null指针
- 如何设置WiFi密码才不会被WiFi万能钥匙破解
- php receivemail下载,php receivemail,php mail,preceive
- Python之面向对象
- 戰女神V、ef_latter、BaldrSky 注册表补丁
- 【算法】常见数据结构基本算法整理
- Vi编辑器的常用命令2(文件操作)
- correl函数相关系数大小意义_相关系数越大,说明两个变量之间的关系就越强吗...
热门文章
- 电脑复制粘贴_手机扫一扫,现实物体隔空复制粘贴进电脑!北大校友的AI新研究,现在变成AR酷炫应用...
- Linux进程和计划任务管理(详细图例)
- 南京晓庄学院计算机网络试卷,南京晓庄学院计算机网络8套卷(完整含答案)
- GHOST装双系统图文教程
- python psutil库安装_安装psutil模块报错安装python-devel
- elasticsearch 索引_Elasticsearch系列---索引管理
- python selenium鼠标点击_Python+Selenium学习--鼠标事件
- mysql 读写分离 max_MaxScale实现MySQL读写分离和负载均衡
- 乐迪智能陪伴机器人_【团品】AI未来人工智能陪伴机器人(爆款复团)
- 底部分页栏_2020年执业药师考试教材各科目增加页数!最多203页