sql组合索引和独立索引_SQL索引概述和策略
sql组合索引和独立索引
A SQL index is used to retrieve data from a database very fast. Indexing a table or view is, without a doubt, one of the best ways to improve the performance of queries and applications.
SQL索引用于非常快速地从数据库检索数据。 毫无疑问,索引表或视图是提高查询和应用程序性能的最佳方法之一。
A SQL index is a quick lookup table for finding records users need to search frequently. An index is small, fast, and optimized for quick lookups. It is very useful for connecting the relational tables and searching large tables.
SQL索引是一种快速查找表,用于查找用户需要频繁搜索的记录。 索引小,快速,并且针对快速查找进行了优化。 这对于连接关系表和搜索大型表非常有用。
SQL indexes are primarily a performance tool, so they really apply if a database gets large. SQL Server supports several types of indexes but one of the most common types is the clustered index. This type of index is automatically created with a primary key. To make the point clear, the following example creates a table that has a primary key on the column “EmployeeId”:
SQL索引主要是一种性能工具,因此,如果数据库很大,它们确实适用。 SQL Server支持几种类型的索引,但是最常见的一种类型是聚集索引。 此类索引是使用主键自动创建的。 为了清楚说明这一点,下面的示例创建一个表,该表在“ EmployeeId”列上具有主键:
CREATE TABLE dbo.EmployeePhoto
(EmployeeId INT NOT NULL PRIMARY KEY, Photo VARBINARY(MAX) NULL, MyRowGuidColumn UNIQUEIDENTIFIER NOT NULLROWGUIDCOL UNIQUEDEFAULT NEWID()
);
You’ll notice in the create table definition for the “EmployeePhoto” table, the primary key at the end of “EmployeeId” column definition. This creates a SQL index that is specially optimized to get used a lot. When the query is executed, SQL Server will automatically create a clustered index on the specified column and we can verify this from Object Explorer if we navigate to the newly created table, and then the Indexes folder:
您会在“ EmployeePhoto”表的创建表定义中注意到,“ EmployeeId”列定义末尾的主键。 这将创建一个经过特别优化以大量使用SQL索引。 执行查询时,SQL Server将在指定的列上自动创建聚簇索引,如果我们导航到新创建的表,然后导航到Indexes文件夹,则可以从Object Explorer进行验证。
Notice that not only creating a primary key creates a unique SQL index. The unique constraint does the same on the specified columns. Therefore, we got one additional unique index for the “MyRowGuidColumn” column. There are no remarkable differences between the unique constraint and a unique index independent of a constraint. Data validation happens in the same manner and the query optimizer does not differentiate between a unique SQL index created by a constraint or manually created. However, a unique or primary key constraint should be created on the column when data integrity is the objective because by doing so the objective of the index will be clear.
请注意,不仅创建主键还会创建唯一SQL索引。 唯一约束在指定列上执行相同的操作。 因此,我们为“ MyRowGuidColumn”列获得了另一个唯一索引。 唯一约束和独立于约束的唯一索引之间没有显着差异。 数据验证以相同的方式发生,并且查询优化器不会区分由约束创建或手动创建的唯一SQL索引。 但是,当以数据完整性为目标时,应在列上创建唯一或主键约束,因为这样做可以使索引的目标明确。
Note: The detailed explanation of each type of these SQL indexes can be found in the following article: How to create and optimize SQL Server indexes for better performance
注意:在下面的文章中可以找到这些SQL索引的每种类型的详细说明: 如何创建和优化SQL Server索引以获得更好的性能
So, if we use a lot of joins on the newly created table, SQL Server can lookup indexes quickly and easily instead of searching sequentially through potentially a large table.
因此,如果我们在新创建的表上使用大量联接,则SQL Server可以快速,轻松地查找索引,而不是顺序搜索潜在的大表。
SQL indexes are fast partly because they don’t have to carry all the data for each row in the table, just the data that we’re looking for. This makes it easy for the operating system to cache a lot of indexes into memory for faster access and for the file system to read a huge number of records simultaneously rather than reading them from the disk.
SQL索引之所以快速,部分原因是它们不必携带表中每一行的所有数据,而只需要携带我们要查找的数据。 这使操作系统很容易将大量索引缓存到内存中,以加快访问速度,并使文件系统更容易同时读取大量记录,而不是从磁盘读取它们。
Additional indexes can be created by using the Index keyword in the table definition. This can be useful when there is more than one column in the table that will be searched often. The following example creates indexes within the Create table statement:
可以使用表定义中的Index关键字来创建其他索引。 当表中经常搜索多个列时,此功能很有用。 下面的示例在Create table语句中创建索引:
CREATE TABLE Bookstore2
(ISBN_NO VARCHAR(15) NOT NULL PRIMARY KEY, SHORT_DESC VARCHAR(100), AUTHOR VARCHAR(40), PUBLISHER VARCHAR(40), PRICE FLOAT, INDEX SHORT_DESC_IND(SHORT_DESC, PUBLISHER)
);
This time, if we navigate to Object Explorer, we’ll find the index on multiple columns:
这次,如果我们导航到Object Explorer ,我们将在多个列上找到索引:
We can right-click the index, hit Properties and it will show us what exactly this index spans like table name, index name, index type, unique/non-unique, and index key columns:
我们可以右键单击索引,单击“ 属性” ,它将向我们显示该索引的确切范围,例如表名,索引名,索引类型,唯一/非唯一和索引键列:
We must briefly mention statistics. As the name implies, statistics are stat sheets for the data within the columns that are indexed. They primarily measure data distribution within columns and are used by the query optimizer to estimate rows and make high-quality execution plans.
我们必须简要提及统计数据 。 顾名思义,统计信息是被索引列中数据的统计表。 它们主要测量列内的数据分布,并由查询优化器用来估计行并制定高质量的执行计划。
Therefore, any time a SQL index is created, stats are automatically generated to store the distribution of the data within that column. Right under the Indexes folder, there is the Statistics folder. If expanded, you’ll see the sheet with the same specified name as we previously did to our index (the same goes for the primary key):
因此,无论何时创建SQL索引,都会自动生成统计信息以存储该列中数据的分布。 在“ 索引”文件夹的正下方,有“ 统计”文件夹。 如果展开,您将看到工作表具有与之前对索引相同的指定名称(主键也是如此):
There is not much for users to do on SQL Server when it comes to statistics because leaving the defaults is generally the best practice which ultimately auto-creates and updates statistics. SQL Server will do an excellent job with managing statistics for 99% of databases but it’s still good to know about them because they are another piece of the puzzle when it comes to troubleshooting slow running queries.
对于统计信息,用户在SQL Server上不需要做太多事情,因为保留默认值通常是最终自动创建和更新统计信息的最佳做法。 SQL Server在管理99%的数据库的统计信息方面将做得很好,但是了解它们仍然很高兴,因为在解决运行缓慢的查询时,它们是另一个难题。
For detailed information on statistics, please see the following article: How to optimize SQL Server query performance – Statistics, Joins and Index Tuning
有关统计信息的详细信息,请参见以下文章: 如何优化SQL Server查询性能–统计信息,联接和索引调整
Also worth mentioning are selectivity and density when creating SQL indexes. These are just measurements used to measure index weight and quality:
还值得一提的是创建SQL索引时的选择性和密度。 这些只是用于测量索引权重和质量的度量:
- Selectivity – number or distinct keys values 选择性–数字或不同的键值
- Density – number of duplicate key values 密度–重复键值的数量
These two are proportional one to another and are used to measure both index weight and quality. Essentially how this works in the real world can be explained in an artificial example. Let’s say that there’s an Employees table with 1000 records and a birth date column that has an index on it. If there is a query that hits that column often coming either from us or application and retrieves no more than 5 rows that means that our selectivity is 0.995 and density is 0.005. That is what we should aim for when creating an index. In the best-case scenario, we should have indexes that are highly selective which basically means that queries coming at them should return a low number of rows.
这两者是成比例的,用于衡量指标的权重和质量。 本质上,这可以在一个人工示例中进行解释。 假设有一个雇员表,其中有1000条记录,并且出生日期列上有索引。 如果有一个查询命中该列通常来自我们或应用程序,并且检索到的行不超过5行,则表明我们的选择性为0.995,密度为0.005。 这就是我们在创建索引时应该追求的目标。 在最佳情况下,我们应该具有高度选择性的索引,这基本上意味着到达它们的查询应返回少量的行。
When creating SQL indexes, I always like to set SQL Server to display information of disk activity generated by queries. So the first thing we can do is to enable IO statistics. This is a great way to see how much work SQL Server has to do under the hood to retrieve the data. We also need to include the actual execution plan and for that, I like to use a free SQL execution plan viewing and analysis tool called ApexSQL Plan. This tool will show us the execution plan that was used to retrieve the data so we can see what SQL indexes, if any, are used. When using ApexSQL Plan, we don’t really need to enable IO statistics because the application has advanced I/O reads stats like the number of logical reads including LOB, physical reads (including read-ahead and LOB), and how many times a database table was scanned. However, enabling the stats on SQL Server can help when working in SQL Server Management Studio. The following query will be used as an example:
创建SQL索引时,我总是喜欢将SQL Server设置为显示由查询生成的磁盘活动信息。 因此,我们要做的第一件事就是启用IO统计信息 。 这是查看SQL Server在后台检索数据必须完成多少工作的好方法。 我们还需要包括实际的执行计划,为此,我想使用一个名为ApexSQL Plan的免费SQL执行计划查看和分析工具。 该工具将向我们展示用于检索数据的执行计划,以便我们可以查看所使用SQL索引(如果有)。 使用ApexSQL Plan时,我们实际上并不需要启用IO统计信息,因为应用程序具有高级I / O读取统计信息,例如逻辑读取的数量(包括LOB),物理读取(包括预读和LOB)以及一次已扫描数据库表。 但是,在SQL Server Management Studio中工作时,启用SQL Server上的统计信息会有所帮助。 以下查询将作为示例:
CHECKPOINT;
GO
DBCC DROPCLEANBUFFERS;
DBCC FREESYSTEMCACHE('ALL');
GO
SET STATISTICS IO ON;
GO
SELECT sod.SalesOrderID, sod.ProductID, sod.ModifiedDate
FROM Sales.SalesOrderDetail sodJOIN Sales.SpecialOfferProduct sop ON sod.SpecialOfferID = sop.SpecialOfferIDAND sod.ProductID = sop.ProductID
WHERE sop.ModifiedDate >= '2013-04-30 00:00:00.000';
GO
Notice that we also have the CHECKPOINT and DBCC DROPCLEANBUFFERS that are used to test queries with a clean buffer cache. They are basically creating a clean system state without shutting down and restarting the SQL Server.
注意,我们还有CHECKPOINT和DBCC DROPCLEANBUFFERS ,它们用于使用干净的缓冲区高速缓存来测试查询。 他们基本上是在创建干净系统状态,而无需关闭并重新启动SQL Server。
So, we got a table inside the sample AdventureWorks2014 database called “SalesOrderDetail”. By default, this table has three indexes, but I’ve deleted those for the testing purposes. If expanded, the folder is empty:
因此,我们在AdventureWorks2014示例数据库中获得了一个名为“ SalesOrderDetail”的表。 默认情况下,该表具有三个索引,但是出于测试目的,我已经删除了那些索引。 如果展开,则文件夹为空:
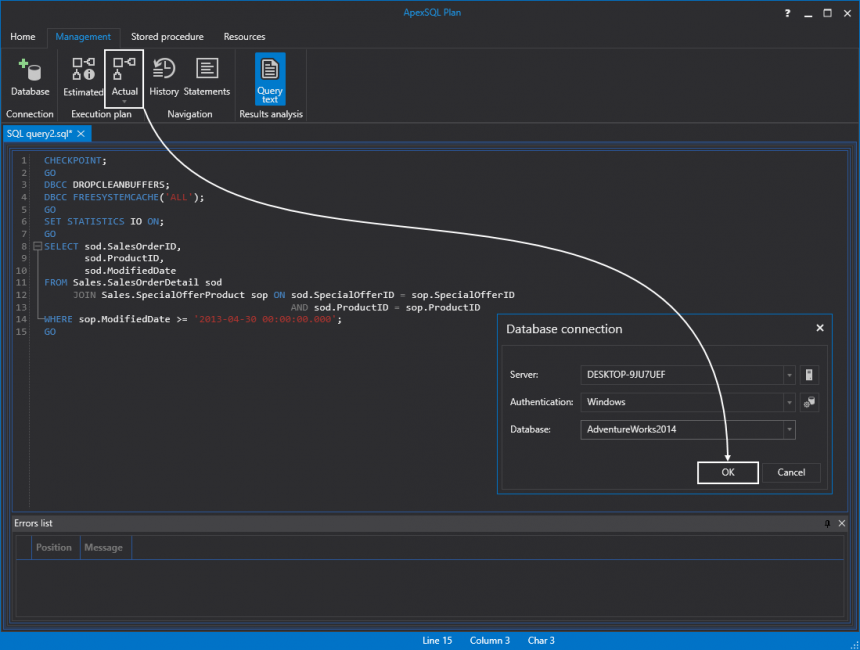
Next, let’s get the actual execution plan by simply pasting the code in ApexSQL Plan and clicking the Actual button. This will prompt the Database connection dialog first time in which we have to choose the SQL Server, authentication method and the appropriate database to connect to:
接下来,让我们通过简单地将代码粘贴到ApexSQL Plan中并单击“ 实际”按钮来获得实际的执行计划。 这将在第一次时提示“ 数据库连接”对话框,在该对话框中,我们必须选择SQL Server,身份验证方法和适当的数据库来连接:
This will take us to the query execution plan where we can see that SQL Server is doing a table scan and it’s taking most resources (56.2%) relative to the batch. This is bad because it’s scanning everything in that table to pull a small portion of the data. To be more specific, the query returns only 1.021 rows out of 121.317 in total:
这将带我们进入查询执行计划,在该计划中我们可以看到SQL Server正在执行表扫描,并且相对于批处理而言,它占用的资源最多(56.2%)。 这很糟糕,因为它正在扫描该表中的所有内容以提取一小部分数据。 更具体地说,查询总共只返回121.317个行中的1.021行:
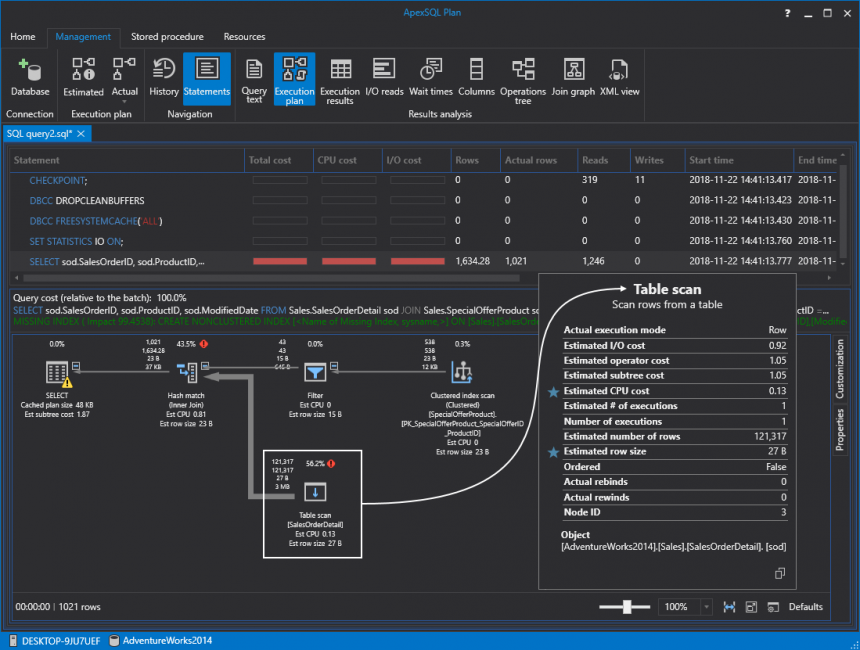
If we hover the mouse over the red exclamation mark, an additional tooltip will show the IO cost as well. In this case, 99.5 percent:
如果我们将鼠标悬停在红色感叹号上,则其他工具提示也会显示IO成本。 在这种情况下,99.5%:
So, 1.021 rows out of 121.317 returned almost instantly on the modern machine but SQL Server still has to do a lot of work and as data fills up in the table the query could get slower and slower over time. So, the first thing we have to do is create a clustered index on the “SalesOrderDetail” table. Bear in mind that we should always choose the clustered index wisely. In this case, we are creating it on the “SalesOrderID” and “SalesOrderDetailID” because we’re expecting so much data on them. Let’s just go ahead and create this SQL index by executing the query from below:
因此,在现代计算机上,121.317中的1.021行几乎立即返回,但是SQL Server仍然需要做很多工作,并且随着表中数据的填充,查询随着时间的推移会越来越慢。 因此,我们要做的第一件事是在“ SalesOrderDetail”表上创建聚簇索引。 请记住,我们应该始终明智地选择聚簇索引。 在这种情况下,我们在“ SalesOrderID”和“ SalesOrderDetailID”上创建它,因为我们期望它们上有很多数据。 让我们继续通过从下面执行查询来创建此SQL索引:
ALTER TABLE [Sales].[SalesOrderDetail] ADD CONSTRAINT [PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID] PRIMARY KEY CLUSTERED
([SalesOrderID] ASC,[SalesOrderDetailID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
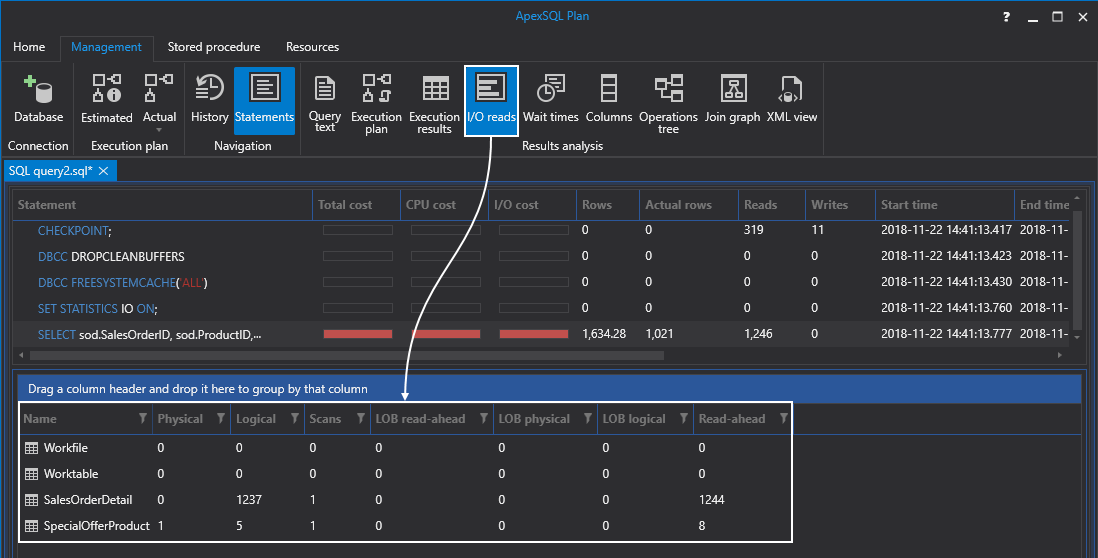
Actually, before we do that. Let’s quickly switch over to the IO reads tab and take a shot from there just so we have this information before doing anything:
实际上,在我们这样做之前。 让我们快速切换到“ IO读取”选项卡,然后从那里进行拍摄,以便在执行任何操作之前获得此信息:
After executing the above query, we will have a clustered index created by a primary key constraint. If we refresh the Indexes folder in Object Explorer, we should see the newly created clustered, unique, primary key index:
执行完上述查询后,我们将有一个由主键约束创建的聚簇索引。 如果我们在Object Explorer中刷新Indexes文件夹,则应该看到新创建的群集的,唯一的主键索引:

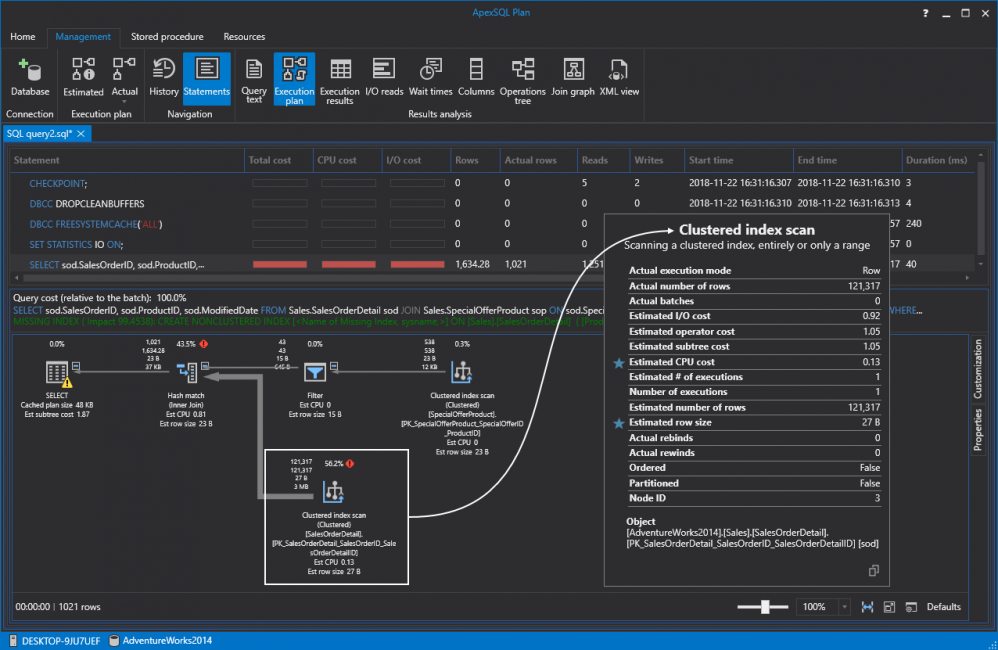
Now, this isn’t going to improve performance a great deal. As a matter of fact, if we run the same query again it will just switch from the table scan to a clustered index scan:
现在,这不会大大提高性能。 事实上,如果我们再次运行相同的查询,它将仅从表扫描切换到聚集索引扫描:
However, we paved the way for the future nonclustered SQL indexes. So, without further ado let’s create a nonclustered index. Notice that ApexSQL Plan determines missing indexes and create queries for (re)creating them from the tooltip. Feel free to review and edit the default code or just hit Execute to create the index:
但是,我们为将来的非聚集SQL索引铺平了道路。 因此,事不宜迟,让我们创建一个非聚集索引。 请注意,ApexSQL Plan确定丢失的索引并创建查询,以便从工具提示中(重新)创建索引。 随时查看和编辑默认代码,或单击执行以创建索引:
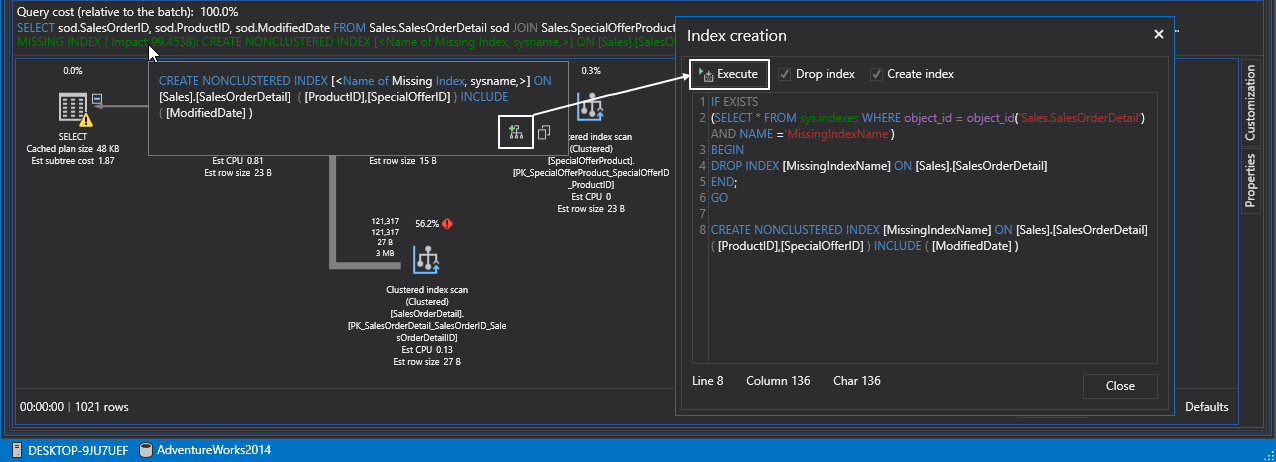
If we execute the query again, SQL Server is doing a nonclustered index seek instead of the previous scan. Remember seeks are always better than scans:
如果再次执行查询,则SQL Server将执行非聚集索引查找,而不是先前的扫描。 请记住,搜寻总是比扫描更好:
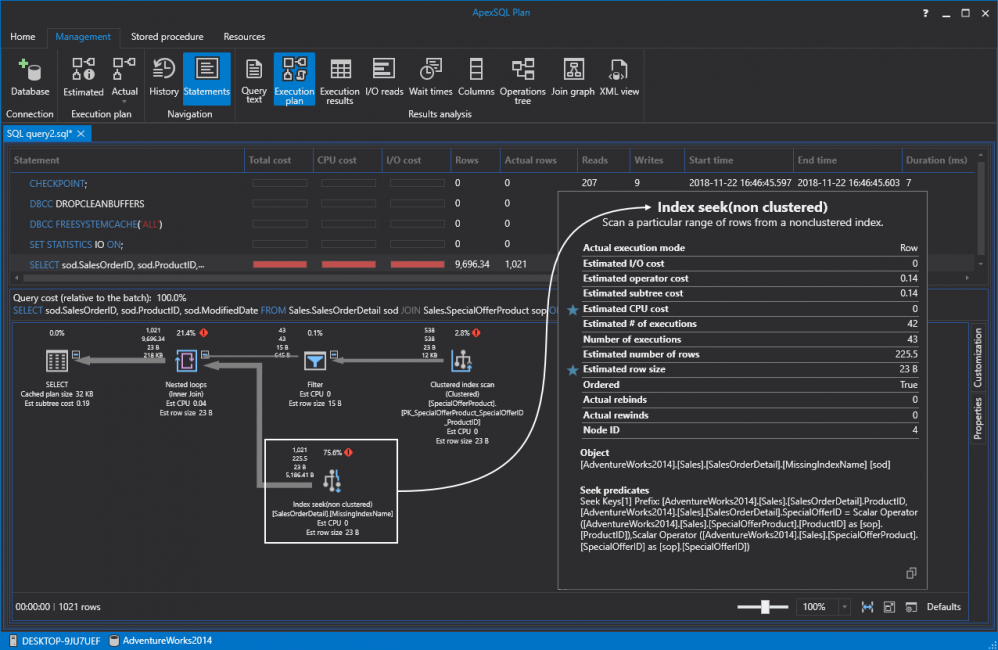
Don’t let the number fools you. Even though some numbers are higher relative to the batch compared to the previous runs this doesn’t necessarily mean that it’s a bad thing. If we switch over to IO reads again and compare them to the previous results, just look at those reads going drastically down from 1.237 to 349, and 1.244 to 136. The reason this was so efficient is that SQL Server used only the SQL indexes to retrieve the data:
不要让数字骗了你。 即使相对于批处理而言,某些数字比以前的运行要高,但这并不一定意味着这是一件坏事。 如果我们再次切换到IO读取并将它们与以前的结果进行比较,则只需查看从1.237到349,从1.244到136急剧下降的那些读取。之所以如此高效,是因为SQL Server仅使用SQL索引检索数据:
Indexing strategy guidelines
索引策略准则
Poorly designed SQL indexes and a lack of them are primary sources of database and application performance issues. Here are a few indexing strategies that should be considered when indexing tables:
设计不良SQL索引和缺少索引的主要原因是数据库和应用程序性能问题。 索引表时,应考虑以下几种索引策略:
- Avoid indexing highly used table/columns – The more indexes on a table the bigger the effect will be on a performance of Insert, Update, Delete, and Merge statements because all indexes must be modified appropriately. This means that SQL Server will have to do page splitting, move data around, and it will have to do that for all affected indexes by those DML statements 避免为高使用率的表/列建立索引 -表上的索引越多,对Insert,Update,Delete和Merge语句的性能的影响就越大,因为必须适当修改所有索引。 这意味着SQL Server将必须进行页面拆分,移动数据,并且必须对那些DML语句对所有受影响的索引执行此操作
- Use narrow index keys whenever possible – Keep indexes narrow, that is, with as few columns as possible. Exact numeric keys are the most efficient SQL index keys (e.g. integers). These keys require less disk space and maintenance overhead 尽可能使用狭窄的索引键 –保持索引狭窄,即列数尽可能少。 确切的数字键是最有效SQL索引键(例如,整数)。 这些密钥需要更少的磁盘空间和维护开销
- Use clustered indexes on unique columns – Consider columns that are unique or contain many distinct values and avoid them for columns that undergo frequent changes
- 在唯一列上使用聚簇索引 –考虑唯一列或包含许多不同值的列,并避免频繁更改的列使用它们
- Nonclustered indexes on columns that are frequently searched and/or joined on – Ensure that nonclustered indexes are put on foreign keys and columns frequently used in search conditions, such as Where clause that returns exact matches 经常搜索和/或联接的列上的非聚集索引–确保将非聚集索引放在搜索条件中经常使用的外键和列上,例如返回完全匹配的Where子句
- Cover SQL indexes for big performance gains – Improvements are attained when the index holds all columns in the query
- 覆盖SQL索引以提高性能 -当索引包含查询中的所有列时,将得到改进
I hope this article on the SQL indexing strategy has been informative and I thank you for reading.
我希望有关SQL索引策略的这篇文章能为您提供有益的信息,并感谢您的阅读。
翻译自: https://www.sqlshack.com/sql-index-overview-and-strategy/
sql组合索引和独立索引
sql组合索引和独立索引_SQL索引概述和策略相关推荐
- 处理字典值是把字典放内存还是用sql处理_SQL索引及其底层实现
准备 1.对关系型数据库有基本的了解 2.对树,平衡二叉树有了解. 目录 一.什么是索引以及为什么要用索引 二.索引的分类 三.实现原理 四.物理存储 五.索引的优化 在实际的面试中,遇到数 ...
- server sql top速度变慢解决方案_SQL Server:执行计划教会我如何创建索引?(解决SQL加了TOP之后变很慢的问题)...
今天,在测试一个SQL语句,是EF自动生成的,发现很奇怪的事情:SQL 加了TOP (20)之后,速度慢了很多,变成36秒,如果没有TOP (20),只需要2秒,查看执行计划,发现变成了全表扫描,但是 ...
- sql 数据库维护索引_SQL索引维护
sql 数据库维护索引 One of the main DBA responsibilities is to ensure databases to perform optimally. The mo ...
- 索引利弊,如何创建索引,单键索引还是组合索引
** 索引的利弊与如何判定,是否需要索引** 相信读者都知道索引能够极大地提高数据检索的效率,让Query 执行得更快,但是可能并不是每一位朋友都清楚索引在极大提高检索效率的同时,也给数据库带来了一些 ...
- SQL中的索引知识点总结(聚集索引、非聚集索引)
SQL里的索引(index)知识: 索引分为聚集索引和非聚集索引,数据库中的索引类似于一本书的目录,在一本书中通过目录可以快速找到你想要的信息(例如字典里按照拼音或部首查找).索引的目的是提高系统性能 ...
- MySQL调优(三):索引基本实现原理及索引优化,哈希索引 / 组合索引 / 簇族索引等
索引基本知识 索引匹配方式 哈希索引 当需要存储大量的URL,并且根据URL进行搜索查找,如果使用B+树,存储的内容就会很大 select id from url where url="&q ...
- c oracle 多条语句,Oracle 实践:如何编写一条 sql 语句获取数据表的全部索引信息(兼容 Oracle 19c、Oracle 11g)...
一.引言 部门使用 Oracle 已经有一些时日,最近在工作中遇到了这么一个需求: 我们希望拿到某些数据表的全部索引信息,对索引信息进行检查,检查是否有漏掉没有创建的索引 这个需求,核心的点在于,我需 ...
- 索引的使用以及常见索引类型,组合索引的具体使用方法。
索引是数据库中的一种预先建立的数据结构,用于加速数据的检索速度.在数据库中,通常会在一个表中的一个字段上建立索引,以便快速查询该字段的数据. 常见的索引类型包括: 单列索引:只包含单个字段的索引. 联 ...
- Mysql索引的类型(单列索引、组合索引 btree索引 聚簇索引等)
一.索引的类型 Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE. FULLTEXT 即为全文索引,目前只有MyISAM引擎支持.其可以在CREATE TABL ...
最新文章
- USBSpirit(USB精灵)更新到1.2.300.105
- PS2 KBC will hang
- 危害网络安全或入信用“黑名单”
- android icon在线更新,Android在线更新下载方案
- anaconda2/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.20' not found Import No module named googl
- PAT真题乙类1006 换个格式输出整数
- mysql整理_MySQL 日常整理
- 01-Windows下安装Node.js及环境配置
- 成功在MP4封装的H264视频中提取能播放的裸流
- excel 瀵煎叆mysql_hypermesh瀵煎叆ansys
- 【WPS单元格】汉字转拼音的方法
- android自动调节亮度是怎么实现的,Android亮度调节的几种实现方法
- 2021安徽省安全员B证 多选题考试题库及答案
- Stack frame omission (FPO) optimization part1
- 如果你是一个Java面试官,你会问哪些问题?
- 环视拼接-鱼眼镜头模型
- 一个没有混进大厂的普通程序员,10年真实收入变化
- php对接AliGenie天猫精灵服务器控制智能硬件esp8266③ 渗入熟悉AliGenie 对接协议,揭开第三方云平台是如何让天猫精灵是发送消息到私有服务器的!
- Mac打开所有分辨率的HiDPI
- java实现bitmap签到,BITMAP实现签到