azure云数据库_Azure SQL数据库的性能调优
azure云数据库
With the latest versions of Azure SQL database, Microsoft has introduced a number of new mechanisms to help users and administrators better optimize their workload.
借助最新版本的Azure SQL数据库,Microsoft引入了许多新机制来帮助用户和管理员更好地优化其工作负载。
Automatic index management and Adaptive query processing provide us with the possibility to rely on the built-in intelligence mechanism that can automatically tune and improve the performance of our workload.
自动索引管理和自适应查询处理为我们提供了依赖内置的智能机制的可能性,该机制可以自动调整和改善工作负载的性能。
With minimal effort, we can setup and configure automatic index management feature that dynamically adapts our database schema to our workload. And with adaptive query processing introduced originally with SQL Server 2017 we can rely on the engine to identify queries that can be improved during the current or next execution.
我们只需花费很少的精力,即可设置和配置自动索引管理功能,该功能可动态地使数据库架构适应工作负载。 借助SQL Server 2017最初引入的自适应查询处理 ,我们可以依靠引擎来识别可在当前或下一次执行期间改进的查询。
自动索引管理 (Automatic index management)
Automatic index management is an Azure SQL Server and Azure SQL database level option; you can configure it either on your whole logical server or only on a single database.
自动索引管理是Azure SQL Server和Azure SQL数据库级别的选项。 您可以在整个逻辑服务器上或仅在单个数据库上对其进行配置。
To enable the setting on your logical Azure SQL Server you would need to access the Automatic tuning menu under the Support + Troubleshooting category. The same option can be found in each Azure SQL database under the same menu.
若要在逻辑Azure SQL Server上启用设置,您需要访问“支持+故障排除”类别下的“ 自动调整”菜单。 在每个Azure SQL数据库的同一菜单下可以找到相同的选项。
The available options are Create index and Drop index, which are initially set to OFF and inherited from your logical server configuration.
可用的选项是Create index和Drop index ,它们最初设置为OFF并从逻辑服务器配置继承。
Once the feature is enabled the built-in intelligence mechanism will dynamically adapt to our database schema.
启用该功能后,内置的智能机制将动态适应我们的数据库架构。
The allowed schema changes are CREATE INDEX and DROP INDEX; No other schema changes can be automatically performed.
允许的模式更改为CREATE INDEX和DROP INDEX; 没有其他架构更改可以自动执行。
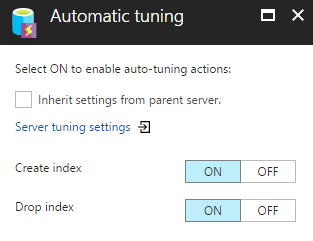
The Create index option will automatically create new indexes that are recommended and found suitable for our workload. Although the addition of indexes provides a great performance benefit where we access our data with read operations they may cause a slowdown to the queries that update data. It is required to approach creating an additional index with caution, wide indexes that include many columns or duplicate indexes are very common occurrences.
“ 创建索引”选项将自动创建建议并发现适合我们的工作负载的新索引。 尽管添加索引在通过读取操作访问数据方面提供了巨大的性能优势,但它们可能会导致更新数据的查询变慢。 需要谨慎地创建其他索引,包含许多列或重复索引的宽索引是非常常见的情况。
During the normal usage and lifecycle of the database, the data and workload type may change resulting in unused indexes that would provide no benefits, but slow down the performance of our database.
在数据库的正常使用和生命周期中,数据和工作负载类型可能会更改,从而导致未使用的索引没有任何益处,但会降低数据库的性能。
The Drop index option will automatically find and remove indexes that provide no benefits.
删除索引选项将自动查找和删除没有任何益处的索引。
Relying on the two automatic options together will help us achieve a more optimal set of indexes. Such settings would be the minimal necessary that will optimize our read workload without causing the negative impact on the data update queries.
一起依靠这两个自动选项将帮助我们获得一组更优化的索引。 这样的设置将是优化我们的读取工作量而又不会对数据更新查询造成负面影响的最小必需的设置。
The Automatic index creation is a great solution for a wide variety of unpredictable heavy read workloads.
自动索引创建是解决各种不可预测的繁重读取工作负载的绝佳解决方案。
In addition, we do have the possibility to monitor the actions that have been performed automatically and, in the case of a need, to revert them by removing a newly created index or restoring an index that was dropped 1.
此外,我们确实有可能监视自动执行的操作,并在需要时通过删除新创建的索引或恢复已删除的索引1来还原它们。
自适应查询处理 (Adaptive query processing)
Adaptive query processing in SQL databases was first introduced with SQL Server 2017 and it is now made available within Microsoft Azure for the Azure SQL Databases.
SQL数据库中的自适应查询处理最早是在SQL Server 2017中引入的,现在可以在Microsoft Azure中用于Azure SQL数据库。
In order to enable the adaptive query processing it is required to alter the compatibility level of our database to ‘140’ as follows:
为了启用自适应查询处理,需要将数据库的兼容性级别更改为“ 140”,如下所示:
ALTER DATABASE [AdventureWorksLT] SET COMPATIBILITY_LEVEL = 140;As of now the three available query processing features that are available are batch mode memory grant feedback, batch mode adaptive join, and interleaved execution. Probably within the future we would see Automatic Tuning focused on SQL plan choice regressions implemented within Azure SQL Databases as well.
到目前为止,可用的三个可用查询处理功能是批处理模式内存授予反馈 , 批处理模式自适应连接和交错执行。 也许在将来,我们会看到自动调整也将重点放在Azure SQL数据库中实现SQL计划选择回归上。
Batch mode memory grant feedback is a mechanism to locate incorrectly sized memory grant sizes for query plans. Within each query plan, SQL Server will include the minimum required memory that is needed for the execution and what would be the optimal memory grant size to have all query data fit into memory. On some occasions, this size is incorrectly calculated and may result either in excessive or insufficient grants.
批处理模式内存授权反馈是一种为查询计划定位大小错误的内存授权大小的机制。 在每个查询计划中,SQL Server将包括执行所需的最小内存,以及使所有查询数据都适合内存的最佳内存授权大小。 在某些情况下,此金额计算不正确,可能会导致赠款过多或不足。
Excessive grants are such that result in wasted memory and insufficient grants will cause expensive spills to disk slowing the query processing. Batch mode memory grant feedback recalculates the required memory that is required for problematic query and updates the already cached plan.
授予过多会导致内存浪费,而授予不足会导致磁盘大量溢出,从而降低查询处理速度。 批处理模式内存授予反馈将重新计算问题查询所需的必需内存,并更新已缓存的计划。
For queries with excessive grants that have memory grants more than two (2) times than memory that was actually used, the memory grant will be re-calculated and the cached plan will be updated. For queries with insufficiently size memory grants the batch mode memory grant feedback will be triggered to recalculate the memory grant and update the cached plan.
对于具有过多授权的查询,这些查询具有的内存授权是实际使用的内存的两(2)倍以上,将重新计算内存授权并更新缓存的计划。 对于内存授权大小不足的查询,将触发批处理模式的内存授权反馈,以重新计算内存授权并更新缓存的计划。
When the plan is reused by identical query it will use the revised memory grant size, acquiring the needed memory resources.
当该计划被相同的查询重用时,它将使用修改后的内存授权大小,获取所需的内存资源。
Batch mode adaptive joins is an operator that will dynamically switch either between hash join or nested loop join. The strategy which join method will be used is decided until after the first input is scanned.
批处理模式自适应联接是一种运算符,它将在哈希 联接或嵌套循环 联接之间动态切换。 确定使用哪种连接方法的策略,直到扫描完第一个输入之后。
Depending on a threshold set by the Adaptive join if the first input is small enough it can dynamically switch to a nested loop join. The threshold is calculated for each statement depending on the input data.
如果第一个输入足够小,则取决于自适应连接设置的阈值,它可以动态切换到嵌套循环连接。 根据输入数据为每个语句计算阈值。
If the first input row count is above the threshold set by the Adaptive join operator no switch will occur and the query will continue using the hash join.
如果第一个输入行计数高于Adaptive join运算符设置的阈值,则不会发生切换,查询将继续使用哈希联接。
Workloads that have frequent variations between large and small inputs would benefit the most, as batch mode adaptive joins work for both the initial and all consecutive executions of the statement. The consecutive executions will be adaptive as well based on the compiled adaptive join threshold. You can now revise your workload where JOIN hints are used and test if the adaptive join improves both large and small inputs.
大和小输入之间频繁变化的工作负载将受益最大,因为批处理模式自适应联接适用于语句的初始执行和所有连续执行。 基于编译的自适应联接阈值,连续执行也将是自适应的。 现在,您可以在使用JOIN提示的情况下修改工作量,并测试自适应联接是否可以改善大小输入。
The cached plan will be recompiled 2 as usual when schema change occurs or when the plan is not optimal.
当发生架构更改或计划不是最佳方案时,将照常重新编译缓存的计划2 。
Note that the adaptive join operator can only be viewed when using SQL Server Management Studio 17 3.
请注意,只有在使用SQL Server Management Studio 17 3时才能查看自适应联接运算符。
Interleaved execution is mechanism to help fight cardinality issues caused by Multi-Statement-Table-Valued-Functions (MSTVF). Up until now, the SQL Server compiler was not able to use any table statistics on the tables from within the MSTVF and fixed cardinality value of ‘100’ in SQL Server 2016 and SQL Server 2014 was used. Older versions used a value of ‘1’.
交错执行是一种机制,可解决由多语句表值函数(MSTVF)引起的基数问题。 到目前为止,SQL Server编译器无法在MSTVF内使用表的任何表统计信息,并且在SQL Server 2016和SQL Server 2014中使用固定基数值“ 100”。 旧版本使用的值为“ 1”。
Starting with SQL Server 2017 and Azure SQL databases with compatibility mode of ‘140’, during the optimization phase of a query, when the compiler faces a candidate for interleaved execution, (MSTVF) it will pause and then execute the query subtree for the Multi-Statement-Table-Valued-Functions and finally capture the correct and real cardinality estimation and resume with the previously paused operations.
从SQL Server 2017和兼容模式为'140'的Azure SQL数据库开始,在查询的优化阶段,当编译器面临交错执行的候选者(MSTVF)时,它将暂停然后执行Multi的查询子树-Statement-Table-Valued-Functions,最后捕获正确和真实的基数估计,并使用先前暂停的操作恢复。
As of now, within the CTP2.1 release of SQL Server 2017, the interleaved execution mechanism has limitations that MSTVF should be performing only read-only operations and should not be used with a CROSS APPLY operator.
截至目前,在SQL Server 2017的CTP2.1版本中,交错执行机制具有以下限制:MSTVF应该仅执行只读操作,而不应与CROSS APPLY运算符一起使用。
翻译自: https://www.sqlshack.com/performance-tuning-improvement-for-azure-sql-databases/
azure云数据库
azure云数据库_Azure SQL数据库的性能调优相关推荐
- azure云数据库_Azure SQL数据库的安全注意事项
azure云数据库 You have to agree with me, when public clouds were introduced your thought was that you wi ...
- azure云数据库_Azure SQL数据库地理复制
azure云数据库 In this article, we will review how to set up Geo-Replication on Azure SQL databases. Geo- ...
- azure云数据库_Azure SQL数据库中的地理复制
azure云数据库 介绍 (Introduction) If you have an Azure SQL Database, it is possible to replicate the data ...
- azure云数据库_Azure SQL数据库中的高级数据安全性–数据发现和分类
azure云数据库 Azure SQL supports in building and managing wide range of SQL databases, tools, frameworks ...
- azure云数据库_Azure SQL数据库中的漏洞评估和高级威胁防护
azure云数据库 In today's time where data breaches are highly expected to happen, there is a high need to ...
- azure云数据库_Azure SQL数据库上的透明数据加密(TDE)
azure云数据库 In this article, we will review on Transparent Data Encryption (TDE) on an Azure SQL datab ...
- sql索引调优_使用内置索引利用率指标SQL Server索引性能调优
sql索引调优 描述 (Description) Indexing is key to efficient query execution. Knowing what indexes are unne ...
- SQL Server 2008+ 性能调优
目录 机器指标 机器处理时间(Machine Processor TIme) 解释 指导值 另请检查 可能的解决方案 平均Cpu队列长度(Avg.Cpu Queue Length) 等效性能计数器 解 ...
- SQL Server 执行计划(8) - 使用 SQL 执行计划进行查询性能调优
在本系列的前几篇文章(见底部索引)中,我们介绍了SQL 执行计划的多个方面,我们讨论了执行计划是如何在内部生成的,不同类型的计划,主要组件和运算符以及如何阅读和分析使用不同工具生成的计划.在本文中,我 ...
最新文章
- Java Review - Queue和Stack 源码解读
- 解决重写父类的方法且不会影响继承的子类的问题
- python deque索引超出范围_Python基础语法
- Microsoft Windows Phone 7 Toolkit Silverlight SDK XNA Game Studio 4.0 开发工具套件正式版下载...
- 研讨会 | 知识图谱引领认知智能+
- leetcode —— 238. 除自身以外数组的乘积
- 关于Web面试的基础知识点--Html+Css(三)
- Linux 引导过程精讲
- SQL2008数据类型
- 杭电1869六度分离
- MySQL查询优化之索引
- python学了真的很有用吗-python学了真的很有用吗?当然!赶紧学,不学后悔!
- Jibun 银行:一家纯网络银行,利用智能手机打开金融服务领域的新天地
- 中心药库管理系统 v6.85 是什么
- foobar2000播放器简单配置 [李园7舍_404]
- verilog学习笔记——三段式状态机
- 2020腾讯广告大赛 :13.5 baseline
- su - root 和 su root 的区别
- python语言支持函数式编程_python 函数式编程学习笔记
- Python的学习笔记案例8--空气质量指数计算1.0