kegra:用Keras深度学习知识图
你好。 我在过去的文章中提到我正在为企业数据集进行认知计算。 就是这样。
本文将需要深入学习的一些理解,但您应该能够遵循对数据科学的最小理解。
我一直致力于在GPU上深入学习的图形中检测模式。 Thomas Kipf 编写了一个用 Keras对图形节点进行分类的好库 。 本文基于他的作品“ 图形卷积网络的半监督分类 ”。 我们来看一下。
首先,图表是什么?
那么,我关心我工作中的知识图。 这些图表代表像“白宫”和“唐纳德特朗普”这样的实体作为节点,像“作品”这样的关系是边缘。 我们如何构建这些图表是另一回事。 在本文中,我正在研究交易数据以训练分类器来识别欺诈交易。 如果你更喜欢顶点和圆弧而不是节点和边缘,那么阅读这篇文章 。
我在这个奇怪的图表世界中感到宾至如归。 我在图表上的工作可以追溯到我的硕士论文。 在那项工作中,我有兴趣在有向无环图内找到共同元素(凸子图)。 我正在确定基于它运行的软件添加到处理器的定制指令。 我用整数线性规划来解决这个问题。 在大图上,求解器可能需要数小时甚至数天。
这一系列研究的链接:
- 嵌入式人工神经网络硬件/软件代号研究
- 可调指令集扩展标识
- 用于人工神经网络的ASIP
- 用定制指令在FPGA上进行人工神经网络加速
- 硬件约束下改进的ISE识别
- 并行指令集扩展标识
- 针对可配置多处理器的静态任务调度
- 为多处理器片上系统硬件/软件协同设计工具链设计和实现指令集扩展标识
- SING:多处理器系统芯片设计和系统生成工具
以下是OrientDB中知识图本体的一个例子:
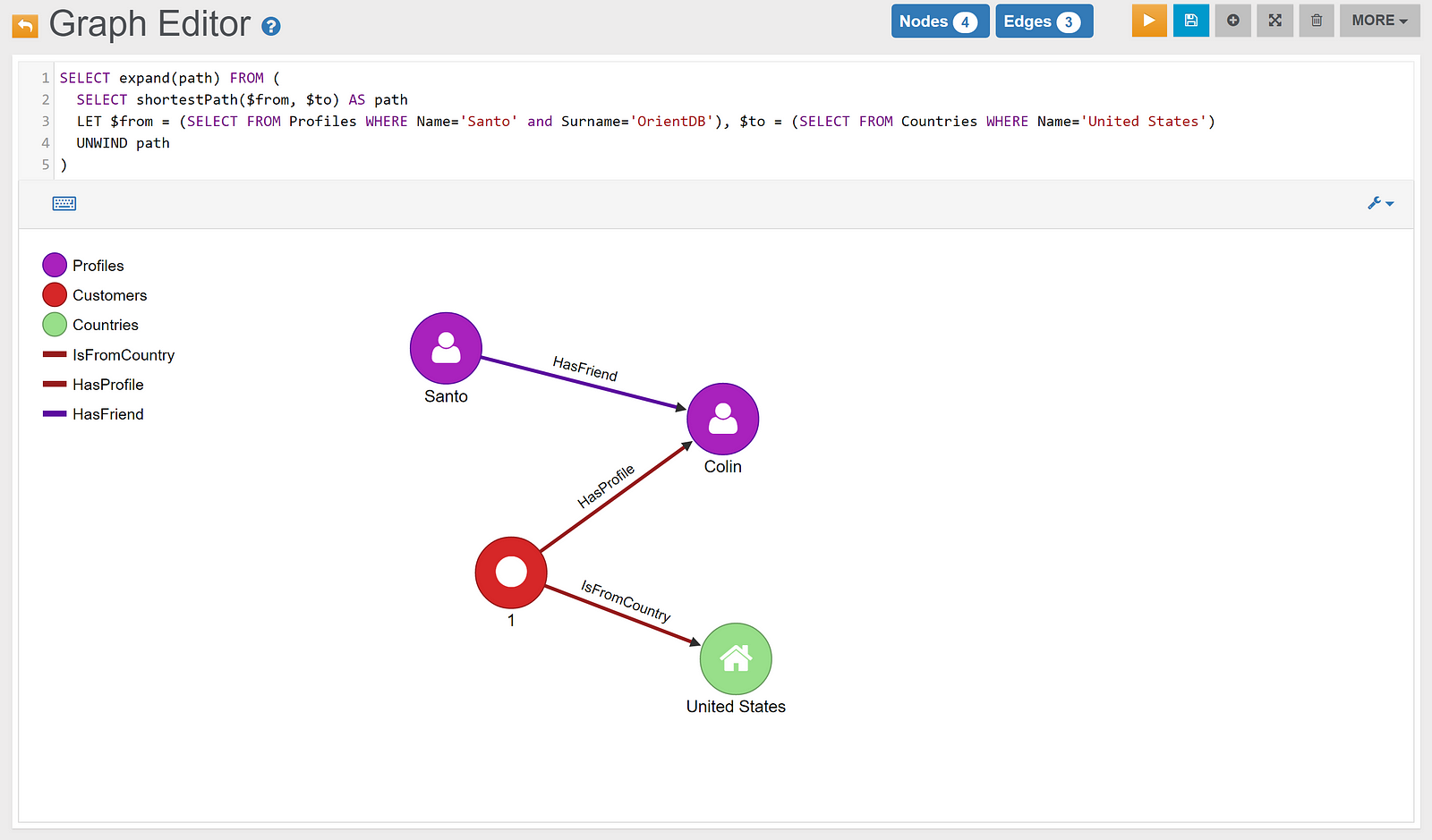
来源: OrientDB演示页面
其次,我们可以发现什么样的模式?
我们想要标记节点。 图中的每个实体都有一些我们想要分类的特征,而我们只有一些节点的标签。 我们可以预测出简单的布尔标签,比如“人物”或“不是人物”,还有更有趣的标签,比如节点分类到几个类别之一。 然后我们可以做更复杂的回归,比如根据图表中的实体数据预测实体所带来的风险。 这包括节点到其他节点的连接。 让我们坚持本文中的布尔节点标签/分类问题,以保持简单。 我们希望通过大约4,000个银行帐户标记594,643笔交易,要么是可疑的,要么是不可疑。 我们希望在不到一分钟的时间内完成 。 不是几小时或几天。
第三,我们如何定义kegra理解的图形?
我们需要指定两个文件。 第一个节点具有节点描述,第二个节点说明节点如何连接。 在kegra提供的cora示例中,有2,708个节点的描述和标签,其中有5,429个边(节点对),用于定义节点彼此的连接。
以下是每个文件几行的视图:
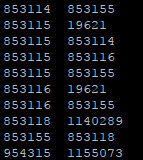
节点之间的链接
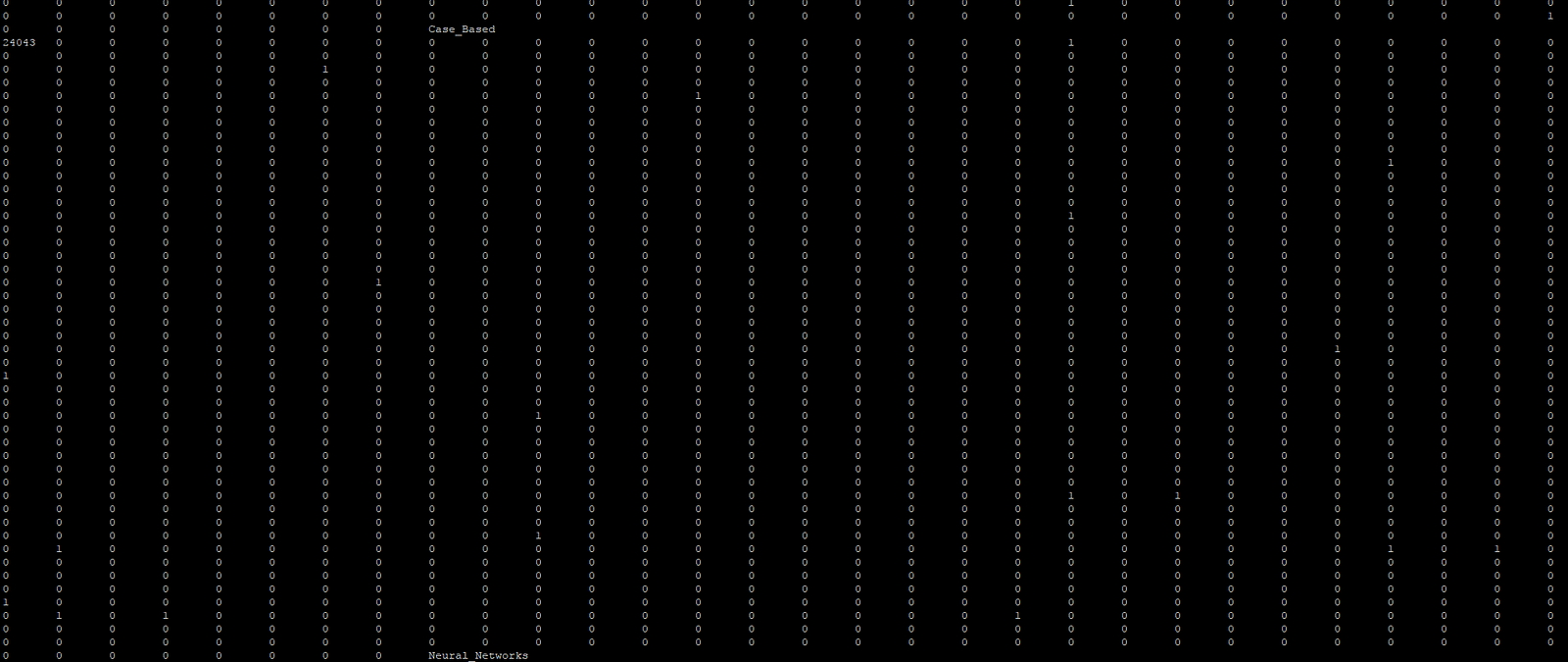
每个节点ID后面跟着特征(大多数为0),最后还有一个节点标签(例如Neural_Networks,Case_Based)。 这些功能大多为0,并在上面的屏幕截图中为许多行换行。 每个特征表示在某个单词的文档(节点)中的使用。 更多信息请点击此处kegra自述文件 。
让我们试试看
首先,你需要Keras 2,所以这样做:
点安装keras - 升级
假设你安装了Keras和TensorFlow,keras-gcn依赖于gcn,所以让我们克隆并逐个安装它们。
#install gcn git clone https://github.com/tkipf/gcn.git cd gcn / python setup.py安装 cd ..
#install keras-gcn git clone https://github.com/tkipf/keras-gcn.git cd keras-gcn / python setup.py安装
首先,让我们使用kegra称为cora的现成示例运行代码。 我们在输出中看到cora从原始数据中检测并打印了预期的节点数和边数。
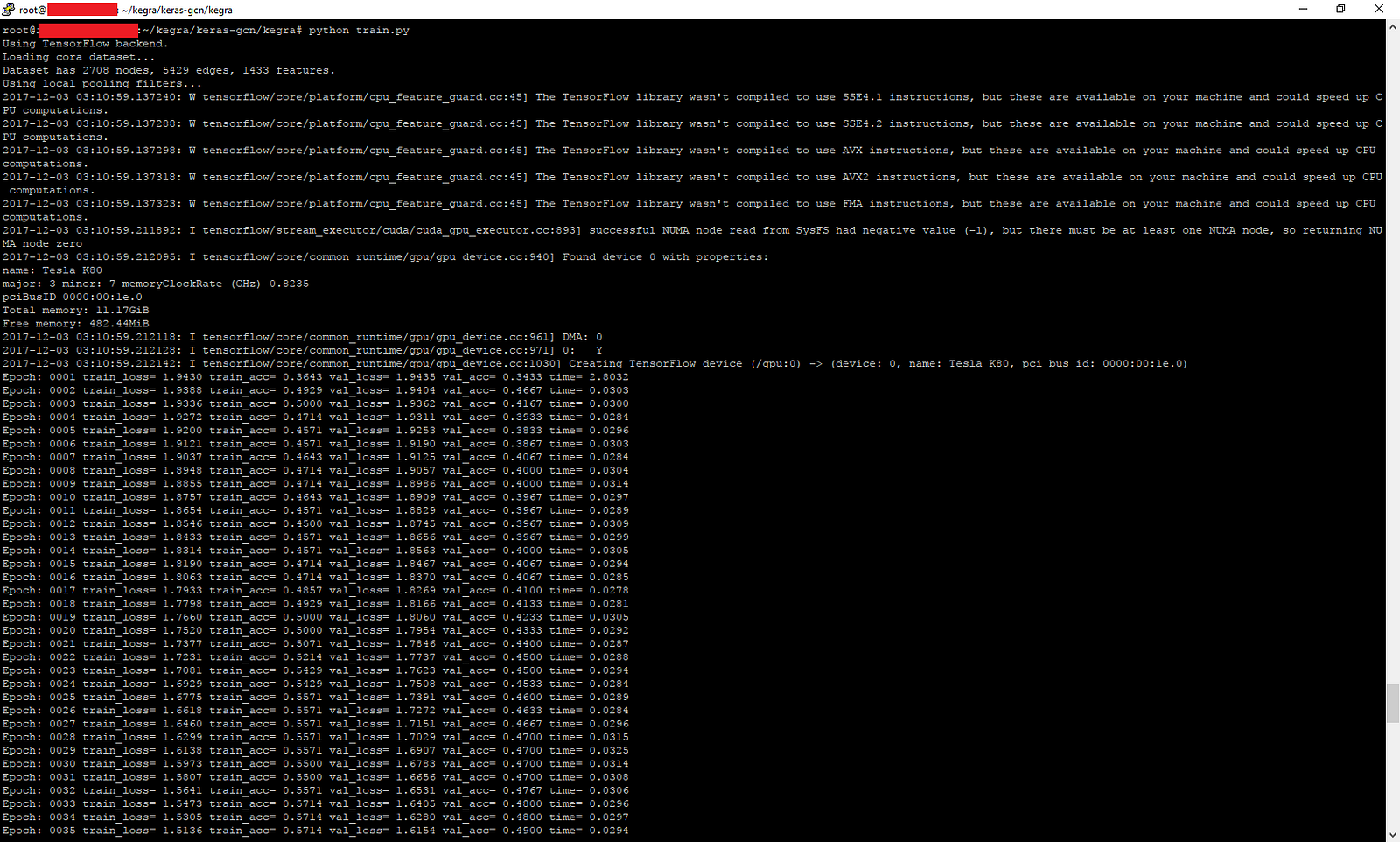
训练运行在cora数据集上:36%的准确性和上升。

cora数据集的测试结果:77.6%的准确性。
我们现在对kegra理解输入文件的方式做一些小改动,只是为了让这些名字更好。 在github的当前版本中,输入文件是描述节点之间的弧的“* .cites”,描述节点的“* .content”。 相反,我改变了kegra以读取“* .link”和“* .node”文件。 你的数据文件夹现在应该是这样的:
〜/ kegra / keras-gcn / kegra $ ls -l data / cora / 总计7720 -rwxrwxr-x 1 ubuntu ubuntu 69928 Dec 3 02:52 cora.link(was cora.cites) -rwxrwxr-x 1 ubuntu ubuntu 7823427 Dec 3 02:52 cora.node(was cora.content) -rwxrwxr-x 1 ubuntu ubuntu 1560 Dec 3 02:52自述文件 〜/ kegra / keras-gcn / kegra $ ls -l data / customerTx / 总计7720 -rwxrwxr-x 1 ubuntu ubuntu 7823427 Dec 3 05:20 customerTx.node -rwxrwxr-x 1 ubuntu ubuntu 1560 Dec 3 05:20自述文件 -rwxrwxr-x 1 ubuntu ubuntu 69928 Dec 3 05:20 customerTx.link
现在让我们用交易数据填写customerTx.node和customerTx.link 。 第一个文件是银行客户及其功能的列表。 格式是:
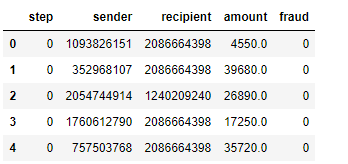
快速查看一些交易记录。 在这种情况下,有货币的发送者和收款人,以及已发送金额的记录(金额栏),以及由审阅交易的人类分析员(欺诈栏)应用的标签。 我们可以忽略前两列(索引和步骤栏)。
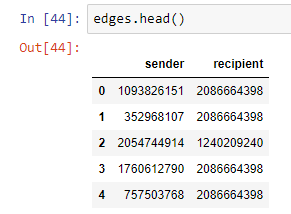
边缘文件( customerTx.link )记录双方在每次交易中的人员。
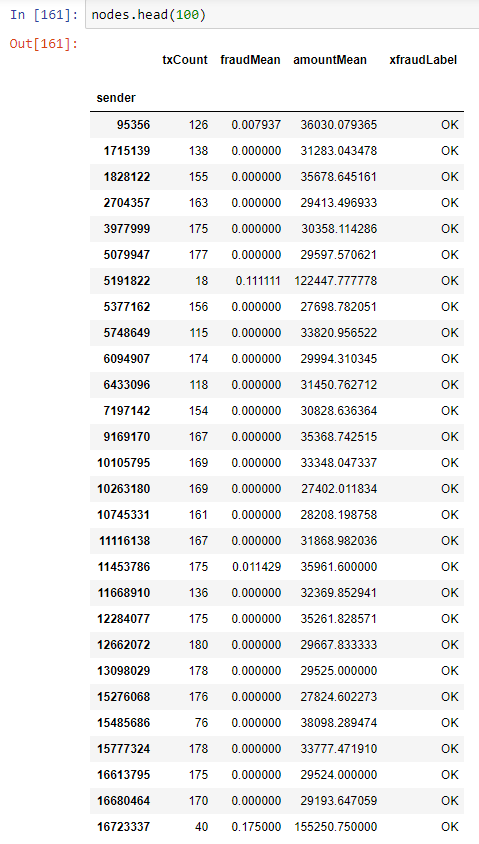
节点文件( customerTx.node )将图表中每个节点上的信息记录为每笔交易的资金发送者。 txCount列列出了离开节点的事务(边)的数量。 amountMean列指定平均事务大小。 “ 欺诈平均值”列是此数据涵盖期间发件人帐户上标记的交易的平均值。 请注意,绝大多数交易都可以,而不是FRAUD,这是一种数据集失衡 。
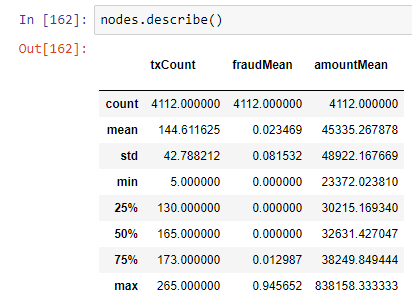
图中有4112个节点。 分析师平均有2.3%被标记为问题。
我们现在可以使用kegra来分析各种分析精度的图表。
如果系统是由完美的分析师对数据进行培训的,那么应该完全学会如何分析图表。 但是,如果人类分析师在20%的时间内出错,那么kegra模型的预测能力应该同样被限制在80%。 为了试验这个,我给图形标签添加了不同数量的随机噪声,看看kegra会如何做,因为训练数据的质量越来越差。
以表格和图表形式显示的结果如下:
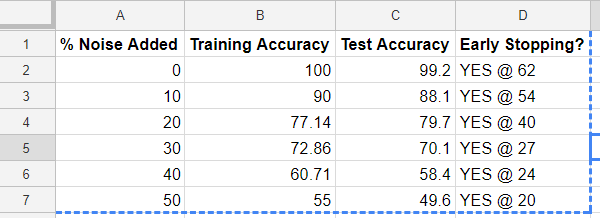
交易标签实验的原始结果,在知识图上使用深度学习

这与上表中的数据相同,但更易于理解图形
这里有很多东西需要消化。 首先,我们看到,随着数据(蓝色)中的噪声增加,早期停止(x轴上的标签)会在训练中更早和更早地进行踢球。 这告诉我们,特征数量太少(少数列)导致训练数据过度拟合。 其次,我们看到测试精度通常低于训练精度。 这是预期的,因为训练数据对于分类器而言是熟悉的,而测试数据则不是。 第三,测试精度不为零。 好! 这意味着分类器可以仅使用图形和每个节点的特征(txCount,amountMean和fraudMean)重新生成OK / FRAUD标签。 第四,随着注入的噪声(蓝色)上升,分类器(橙色)的准确度下降。 这意味着结果不是随机的。 第五,我们看到,训练准确度(红色)加上附加噪声(蓝色)增加了大约100%,这意味着分类器与标注数据集的分析师一样好/坏,但不会更糟。
总之,kegra在知识图谱分类上表现得非常好。 与他们的论文中的结果相比,这些结果可能太好了。 我将检查交易文件中的欺诈标签列是否太具有说明性,并将其替换为难以用来从诸如原籍国,城市,邮政编码等更广泛的数据集中预测的功能。
我的下一个动作是从源文件中重新生成具有更多列的交易数据集,并查看kegra是否仍然表现如此出色。 在cora数据集上没有提前停止,所以我怀疑交易数据对kegra来说并不具有挑战性,这是我之前提到的原因之一。 也许如果我将更多语义特征嵌入到生成的图中......我可以做很多有趣的事情作为下一步。
特别感谢Thomas Kipf在出版前观察这篇文章。 与我平常的高级文章相比,这是一篇非常复杂的文章,可以准备(和阅读)。 如果你喜欢这篇关于图表的深度学习文章,那么请让我知道写出更多这样的研究内容。 我也很高兴在评论中听到您的意见。 你怎么看?
https://towardsdatascience.com/kegra-deep-learning-on-knowledge-graphs-with-keras-98e340488b93
kegra:用Keras深度学习知识图相关推荐
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- 复旦大学邱锡鹏教授:一张图带你梳理深度学习知识脉络
Datawhale 作者:邱锡鹏,复旦大学教授 寄语:本文梳理了深度学习知识体系,分为机器学习.神经网络和概率图模型,同时对机器学习算法类型.深度学习原理框架等进行了梳理,帮助大家更好地学习和入手深度 ...
- 深度学习者的入门福利-Keras深度学习笔记
Keras深度学习笔记 最近本人在github上发现一个不错的资源,是利用keras来学习深度学习的笔记,笔记内容充实,数据完善,本人亲自实操了里面的所有例子,深感收获颇丰,今天特意推荐给大家,希望能 ...
- [Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
从本专栏开始,作者正式研究Python深度学习.神经网络及人工智能相关知识.前一篇文章分享了生成对抗网络GAN的基础知识,包括什么是GAN.常用算法(CGAN.DCGAN.infoGAN.WGAN). ...
- 为什么将表格的method改为post后就无法工作_用Python将Keras深度学习模型部署为Web应用程序...
构建一个很棒的机器学习项目是一回事,但归根结底,你希望其他人能够看到你的辛勤工作.当然,你可以将整个项目放在GitHub上,但是怎么让你的祖父母也看到呢?我们想要的是将深度学习模型部署为世界上任何人都 ...
- Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(2)--使用Keras构建神经网络 0 前言 1. Keras 简介与安装 2. Keras 构建神经网络初体验 3. 训练香草神经网络 3.1 香草神经网络与 MNIST 数 ...
- Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(1)--神经网络基础与模型训练过程详解 0. 前言 1. 神经网络基础 1.1 简单神经网络的架构 1.2 神经网络的训练 1.3 神经网络的应用 2. 从零开始构建前向传播 ...
- [Python图像识别] 四十七.Keras深度学习构建CNN识别阿拉伯手写文字图像
该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门.OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子.图像增强技术.图像分割等,后期结合深度学习研究图像识别 ...
- Windows+Anaconda+tensorflow+keras深度学习框架搭建--reproduced
转载于网络,已备查用. 现在把windows下的Anaconda+tensorflow+keras深度学习框架搭建过程记录如下 1.下载安装Anaconda记住支持版本一定是python3以上的版本 ...
最新文章
- QEMU和KVM 中断处理过程
- 安卓java增加属性_如何使用Java读取Android属性
- C++实现选择排序(附完整源码)
- Web 开发时需要注意到的一些性能问题
- 网络编程释疑之:TCP连接拔掉网线后会发生什么
- ISO C99中的一些扩展(草稿)
- 2020 ccf推荐中文期刊_CCF推荐国际学术期刊
- S3C DMA使用方法,2410-2440 dma介绍
- 我的docker随笔28:基于容器的升级方案实验
- 08-01 Jmeter 核心原理与性能测试理论
- 吴恩达机器学习笔记3——线性代数
- 应该如何理解mobx_如何使用mobx观察observable数组上的object.property更改
- 三分钟了解域名怎么备案?
- source insight 4.0 的一些设置
- APP——adb命令——背诵实操——背诵总结
- Pymol获得蛋白中二级结构信息
- Go语言核心之美-必读
- 阅读笔记:Single Shot Multibox Detector(SSD)
- html框架自动居中,html 宽度固定并布局居中模板框架
- 最新钣金设备制造公司网站模板源码+手机端+后台