互联网文本内容安全:腾讯云天御AI对抗实践
作为国内领先的云解决方案企业,腾讯云在革新云端技术的同时,也肩负着保证互联网安全秩序、抵御黑产黑客的责任和使命。2018 QCon 北京“人工智能与深度学习实践”专场,腾讯云专家级研究员王国印分享了腾讯云在互联网安全防御上的系列解决方案和措施。本文整理了主要王国印老师的主要演讲内容,感兴趣的读者可移步观看王国印老师现场演讲视频。
\\
一、引言
\\
随着互联网、智能设备及各种新生业务的飞速发展,互联网上的数据呈现爆炸式增长,图片、视频、发文、聊天等互动内容已经成为人们表达感情、记录事件和日常工作不可或缺的部分。
\\
这些日益增长的内容中也充斥着各种不可控的风险因素,比如不雅不良评论、垃圾广告、违法违规交易/宣传、低俗不文明等垃圾内容,需要各网站及平台亟待认真对待和管理的工作。
\\
二、内容安全现状
\\
不良不雅评论,违规违法交易严重影响主营业务的健康发展 。面对此类问题,企业主该如何解决呢?
\\
一种方法是投入人力加大审核力度,此种方式的特点如下:
\\
- 垃圾评论占比较小,人力逐条审核容易漏审\\t
- UGC评论数据规模巨大,每日多达数十亿、百亿等,人力成本太高\\t
- 审核人员的招聘成本,管理成本较高\
另外一种方式是招聘专业的AI工程师自建识别模型,此种方式特点如下:
\\
- AI工程师非常昂贵\\t
- 内容安全一般不属于主营业务,投入较少\\t
- 识别模型的效果受限于样本规模和样本质量,在数据标注上需要持续投入\
最后一种途径是购买保险:将内容安全问题交给专业的公司来解决,从而实现“四两拨千斤”。
\\
三、现有解决方案
\\
当前识别此类垃圾内容的主流方法有:关键词过滤模式、关键词文法过滤模式、在打标数据上训练垃圾识别模型的机器学习模式,或融合关键词与机器学习的混合模式,其特点分析如下:
\\
- 基于关键词过滤模式:该模式的优点是立竿见影生效快,但是由于分词歧义问题导致误杀,对未登录的case泛化能力弱,词库的维护成本高\\t
- 基于关键词文法的过滤模式:由于考虑了关键词的上下文,此种方式相比关键词过滤拥有了一定的消歧义能力,但是关键词文法需要人工总结归纳,再加上上下文不易枚举,使得人力成本成倍上升,于此同时随着变种不断涌现,从变种中挖掘拦截文法,人力成本不可控\\t
- 静态机器学习模型或融合了关键词文法过滤的混合模式:由于模型是静态的,上线之后,应对不了变种问题,使得模型很快失灵\
新变种不断涌现,会快速绕过当前垃圾识别方法,使得当前的方法“失灵”,各公司不得不投入大量人力研究变种,归纳拦截策略或标注新样本,于此同时每个业务平台上的垃圾内容存在较大差异,同一垃圾类型,客户的尺度也存在较大差别。在节约人力成本的条件下,如何解决此类对抗性的问题,并做到客户级的个性化定制,成为困扰业界一大难题。腾讯云天御分别从:
\\
- Active learning方式挖掘高质量语料,降低人工审核量\\t
- 打造数据闭环降低研发运维投入\\t
- KV分布式存储实现GB级模型秒级更新\\t
- T+1滚动式升级模型对抗变种\
等四大维度搭建内容安全完整解决方案。
\\
四、腾讯云天御的方案
\\
4.1 UGC分类
\\
天御把UGC评论文本类型分为6大类:
\\
- 不良\\t
- 不雅\\t
- 违法违规:UGC中含有违法违规词汇,或法律禁止网上交易的内容\\t
- 广告:为第三方导流的合法广告,其尺度因平台业务类型而异\\t
- 低俗不文明:骂人,爆粗口等\\t
- 正常\
4.2 UGC特点及天御应对策略
\\
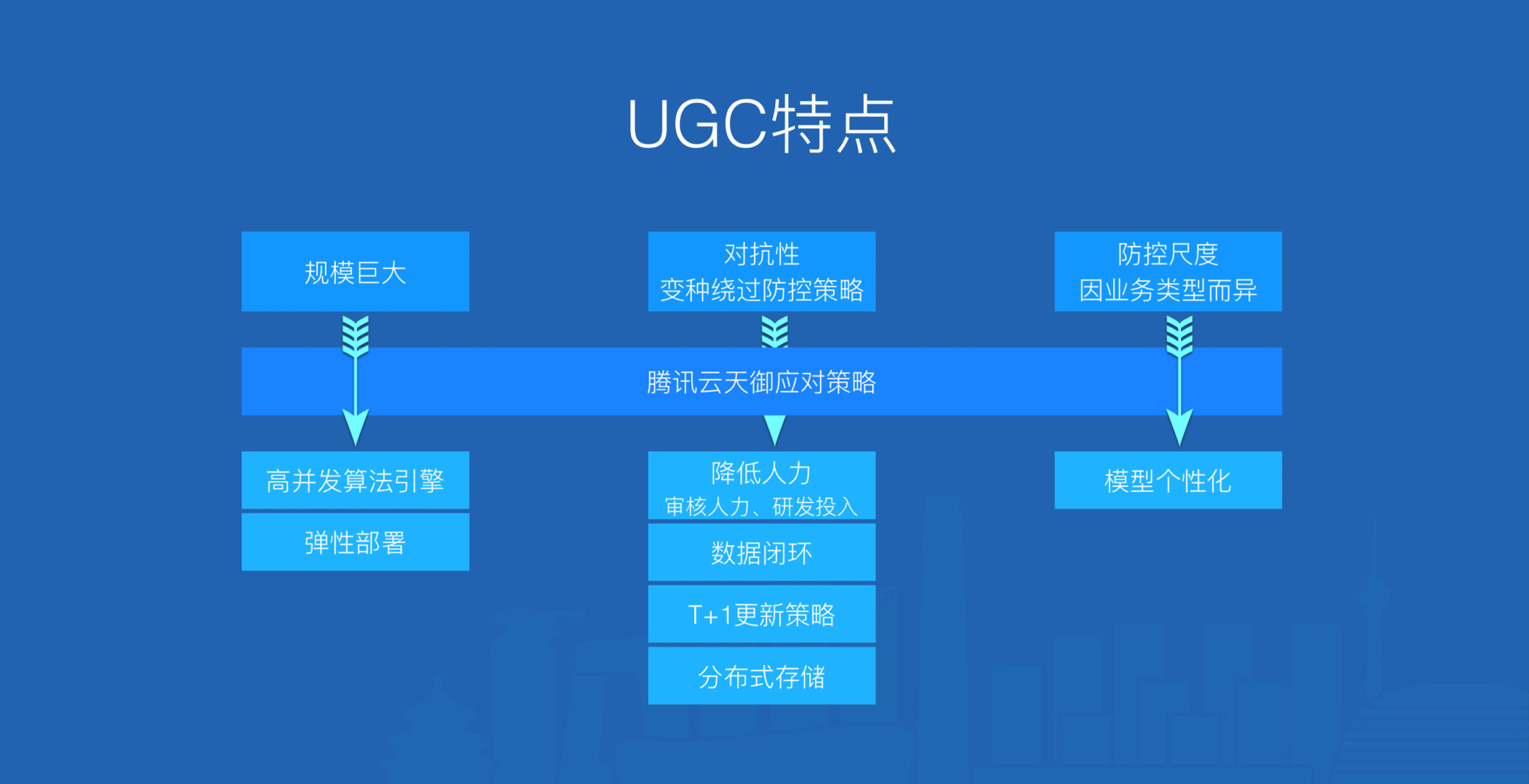
\\
图1. 天御应对策略
\\
图1可以看出互联网UGC主要特点如下:
\\
- 规模巨大,天御通过研发可弹性部署的高并发算法引擎来应对每日上百亿的垃圾评论拦截请求\\t
- 对抗性:新变种很容易绕过当前防控策略,腾讯云天御通过异常识别(基于Active Learning)为垃圾识别挖掘变种语料,大大节约人工审核量;垃圾识别会每隔一段时间拉取异常识别历史记录(已被人工审核),训练出最新的垃圾识别模型,为异常识别和垃圾识别构建一个数据环路,使得模型随着垃圾内容的变异而升级,有效解决了对抗性问题,大大降低研发投入;再将每一个客户的模型表格化,每一行追加上客户信息,实现不同客户之间的模型隔离,模型按行分布式存储使得在秒级实现多模型自动批量上线,大大降低系统维护成本。\\t
- 防控尺度因业务类型而异,天御会针对每一种业务类型针对性的训练模型,从而实现模型的个性化定制\
4.3 天御UGC过滤系统架构
\\

\\
图2. 天御系统架构
\\
从图2看出腾讯云天御UGC过滤垃圾评论的系统架构主要分为四层:
\\
- 底层数据层\\t
- 核心能力层\\t
- 拒绝类型\u0026amp;拒绝策略层\\t
- 客户层\
其中核心能力层包括4大模块:
\\
1. 异常识别,目的是从各种异常类型中发掘最新变种,异常识别所做的工作见图3:
\\
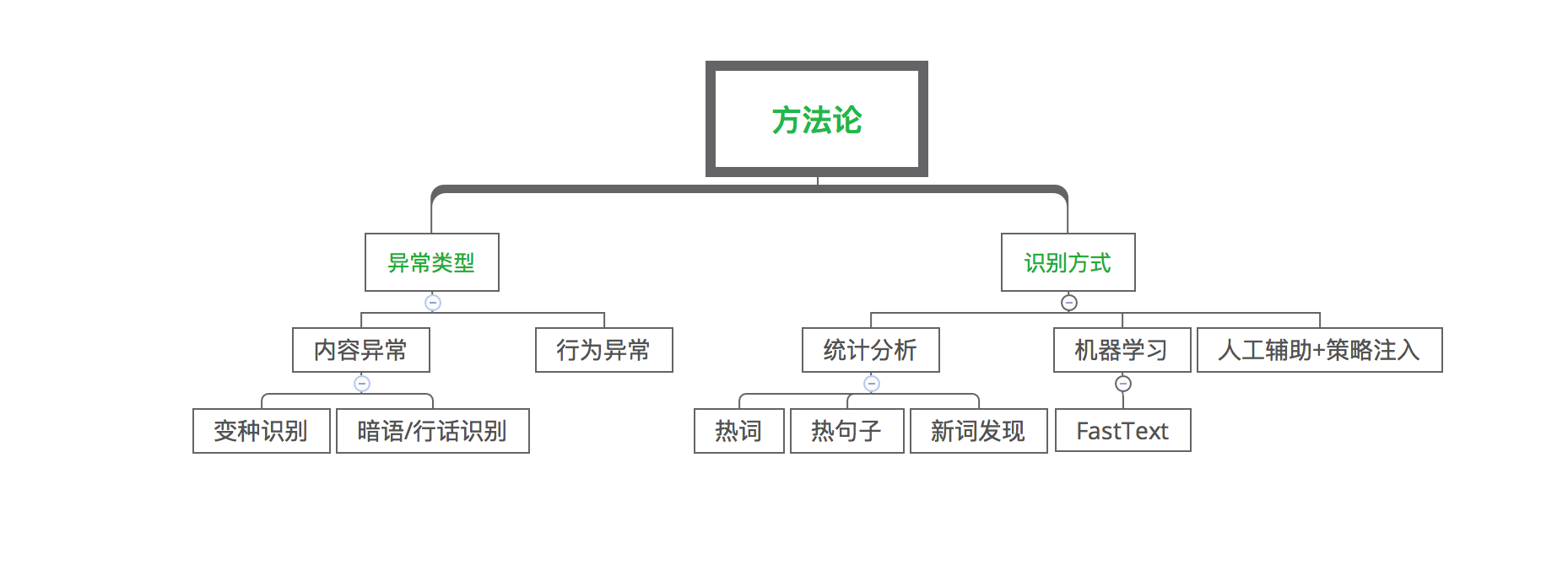
\\
图3. 异常识别
\\
图3中异常类型主要分为内容异常和行为异常,常见的内容异常主要包括变种和行话/暗语,而行为异常表现为同一个人在不同地方发布相同内容,或同一内容被不同人转发等。异常识别的手段主要是通过统计分析发现变种词汇,变种表达等;有些变种是在内容里相间插入特殊符号,其语言构成和正常文本有区别,可通过机器学习的方式来发掘此类变种;对于可疑的内容一般通过人工辅助+策略注入来确定是否为变种。
\\
2. 打标平台,提供数据打标、算法效果每日抽检等等。主要功能分为:
\\
- a) 多人协同:目的是为了提升打标效率,会把一份数据分割成多分由多人完成打标\\t
- b) 抽样策略,由于UGC评论规模巨大,不论是抽取样本还是每日抽检算法效果,需要不同的抽样策略,最终实现少量样本覆盖全部case\\t
- c) 审核策略,分为单人初审、多人投票式的盲审,客户拦截效果评估等等,此块保证数据的打标质量\
3. 模型平台,含模型训练和模型上线,具体包括:
\\
- a) partition策略,不同的客户、不同的业务场景,其防控尺度均不相同,需要针对性训练,模型平台会一次性训练多达上千个模型。partition策略起着分割数据,标识模型的作用\\t
- b) 特征工程:含有特征提取、特征选择,特征变换等,特征变换如各类账号,数字,表情符号归一化操作等等\\t
- c) 模型训练\\t
- d) KV分布式化,其作用是提升上线效率,支撑弹性部署,降低人工干预度\\t
- e) 评估策略,其作用是评估模型效果,判断模型是否可以上线,主要的手段是封闭测试\\t
- f) 更新策略,模型支持T+N滚动式更新,具体流程详见下图\
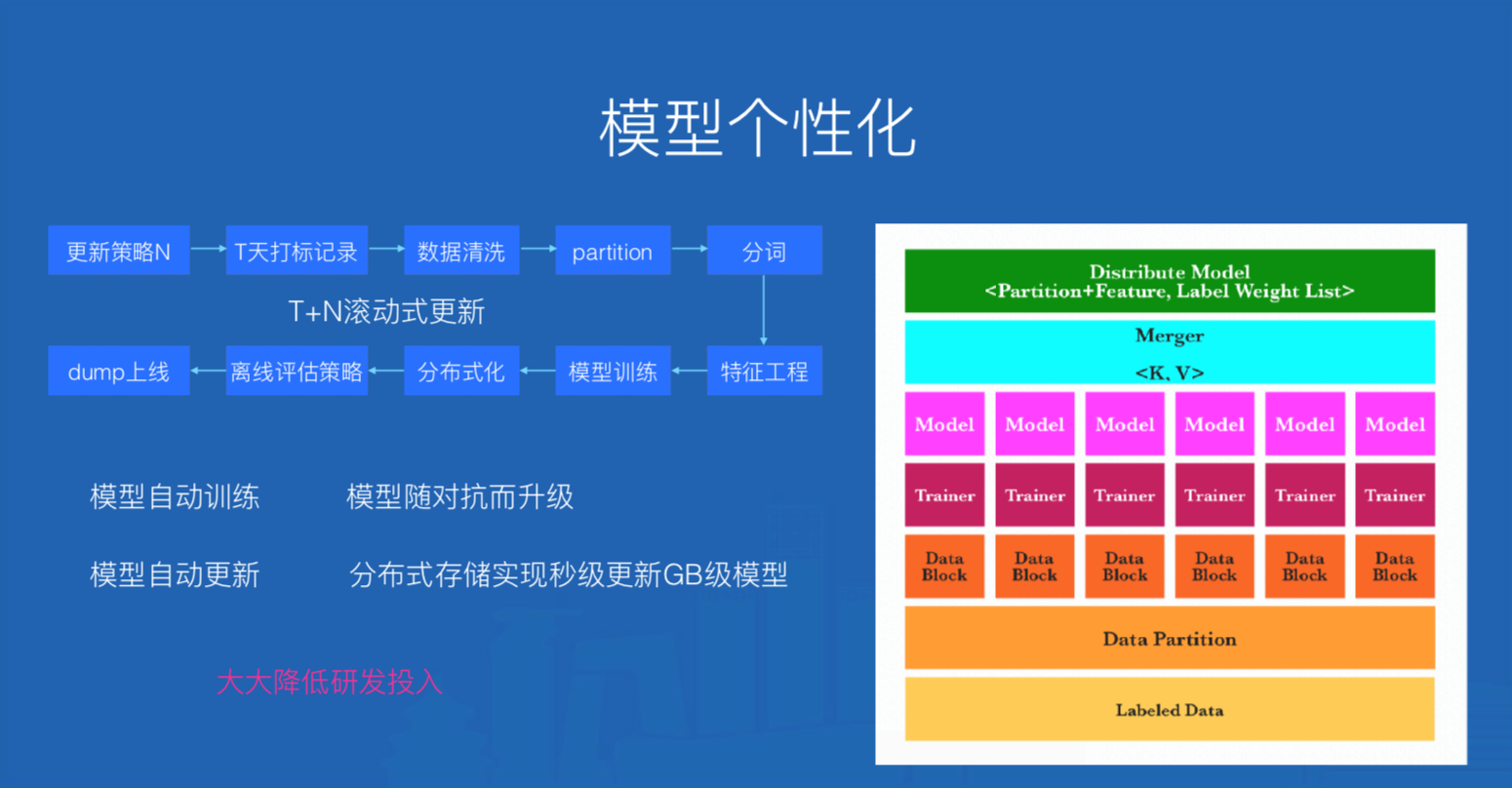
\\
图4. 模型平台及流程
\\
图4中“更新策略N”代表一个定时任务,N的值代表相隔多少天更新一次,T表示模型训练语料集是T天的沉淀数据。在模型训练时,一个Trainer表示一个Reducer任务,其结果是产出一个模型,Merger是将所有模型分布式KV存储的操作,并在K中注入模型ID信息【partition+feature】,V是分类标签和标签权重信息的列表。
\\
4. 垃圾识别,其工作如下图所示:
\\
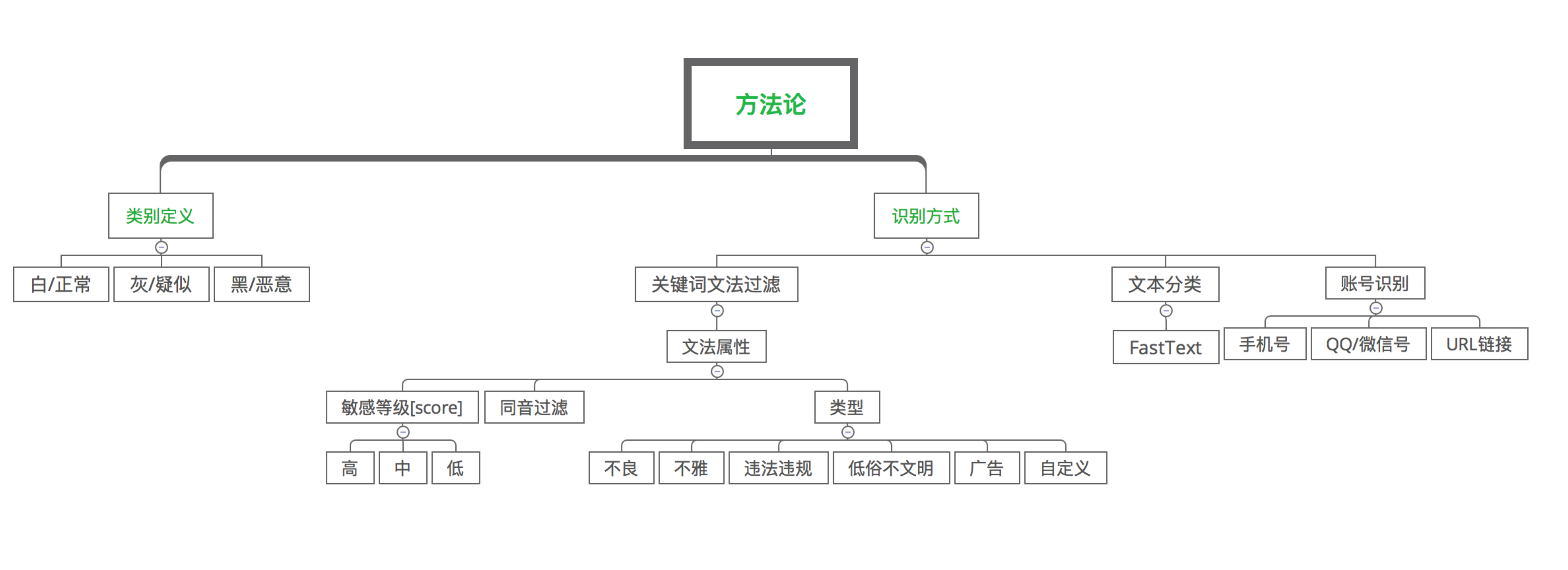
\\
图5. 垃圾识别
\\
从图5可见,依据影响业务健康度的程度和客户不同类型的拒绝策略,总体上将同一类垃圾类型划分为2类或3类:
\\
- 白:正常内容\\t
- 灰:疑似[可选]\\t
- 黑:恶意内容\
在垃圾内容识别上腾讯云天御采用关键词文法过滤+模型动态更新的文本分类方法实现的垃圾识别系统,支持单条关键词文法上的个性化配置。
\\
垃圾广告、违规违法交易中一般含有各类联系方式,是否含有联系方式成为垃圾识别最显著的特征。联系方式常见的有:
\\
- 手机号\\t
- QQ号\\t
- 微信号\\t
- URL链接\
4.4 文本分类算法选型:FastText
\\
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法。FastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。
\\
4.4.1 FastText模型架构
\\
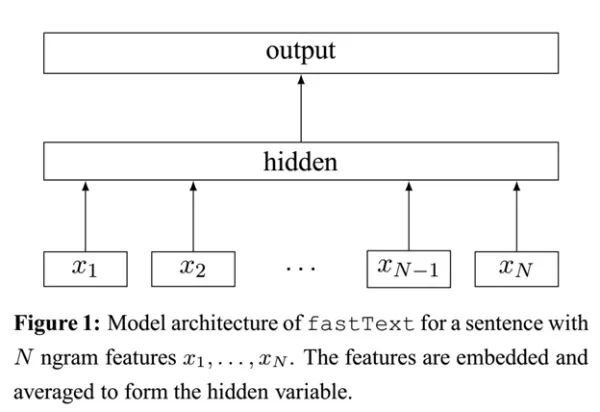
\\
图6. FastText模型架构
\\
FastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
\\
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
\\
FastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
\\
FastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词,见下图所示:
\\
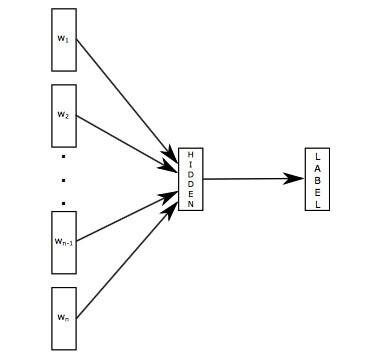
\\
图7. FastText模型结构
\\
4.4.2 FastText层次Softmax
\\
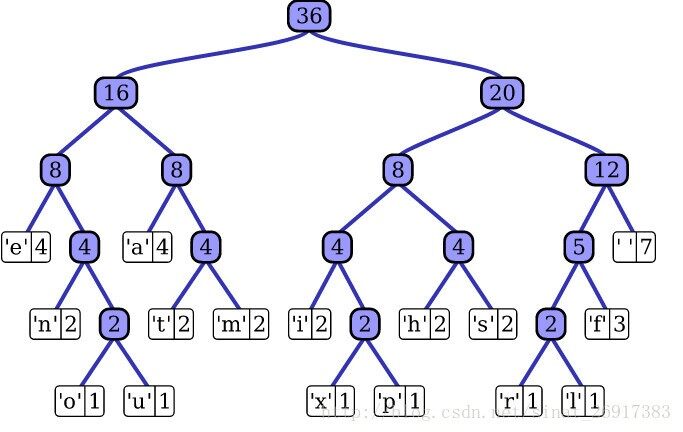
\\
图8. FastText 层次softmax
\\
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,FastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
\\
考虑到线性以及多种类别的对数模型,这大大减少了训练复杂性和测试文本分类器的时间。FastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
\\
4.4.3 FastText N-gram特征
\\
常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 FastText 还加入了 N-gram 特征。 “我爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱她” 和 “她 爱 我” 就能区别开来了。当然,为了提高效率,我们需要过滤掉低频的 N-gram。
\\
在 fastText 中一个低维度向量与每个单词都相关。隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
\\
举例来说:fastText能够学会“男孩”、“女孩”、“男人”、“女人”指代的是特定的性别,并且能够将这些数值存在相关文档中。然后,当某个程序在提出一个用户请求(假设是“我女友现在在儿?”),它能够马上在fastText生成的文档中进行查找并且理解用户想要问的是有关女性的问题。
\\
4.4.5 FastText词向量优势
\\
1. 适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。使用一个标准多核 CPU,得到了在10分钟内训练完超过10亿词汇量模型的结果。此外,FastText还能在五分钟内将50万个句子分成超过30万个类别。
\\
2. 支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。它还使用了一种简单高效的纳入子字信息的方式,在用于像捷克语这样词态丰富的语言时,这种方式表现得非常好,这也证明了精心设计的字符 n-gram 特征是丰富词汇表征的重要来源。FastText的性能要比时下流行的word2vec工具明显好上不少,也比其他目前最先进的词态词汇表征要好。
\\

\\
图9. FastText与其他方法对比
\\
3. FastText专注于文本分类,在许多标准问题上实现当下最好的表现(例如文本倾向性分析或标签预测)。FastText与基于深度学习方法对比:
\\
4. 比word2vec更考虑了相似性,比如 fastText 的词嵌入学习能够考虑 english-born 和 british-born 之间有相同的后缀,但 word2vec 却不能
\\
4.5 数据闭环
\\
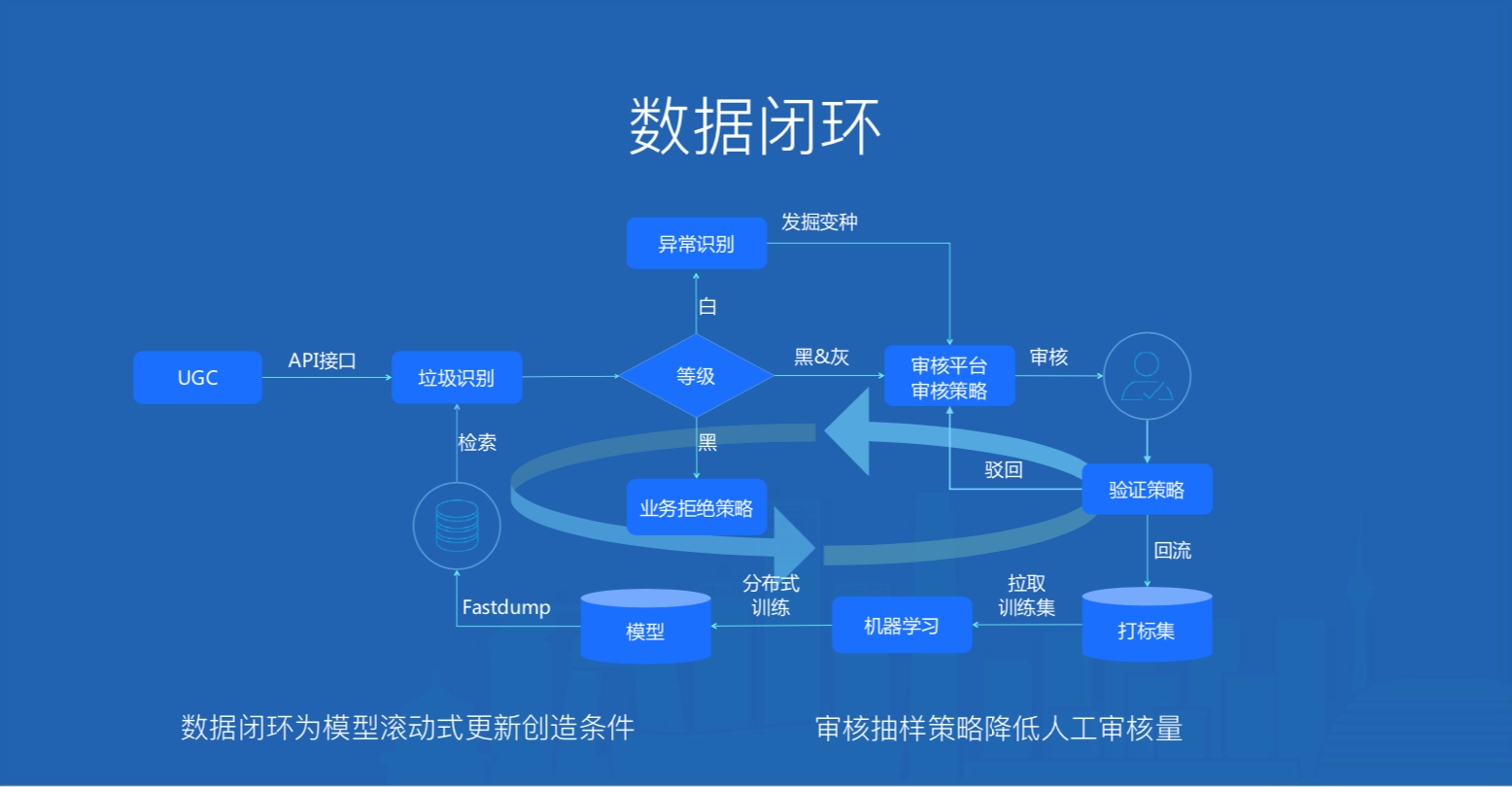
\\
图10. 天御数据闭环
\\
腾讯云天御在垃圾识别、异常识别和人工审核构建一个数据闭环:
\\
- 人工审核沉淀的数据为垃圾识别提供训练语料,由于每天都有数据被打标,为垃圾识别T+1滚动式更新模型创造了条件\\t
- 每日抽检被识别为黑的部分,作为统计算法效果的审核样本,于此同时将不能识别的最新变种交给异常识别来发掘\\t
- 审核平台的审核抽样策略挖掘最能反映总体的小量样本,覆盖尽可能多的case,大大降低人工审核量\
五、总结\u0026amp;思考
\\
5.1 系统指标
\\

\\
图11. 系统指标
\\
- 封闭测试准确率、召回率、准确度用来衡量样本的打标质量\\t
- 测试集上的准确率和召回率用来衡量模型的质量\\t
- 抽样准确率用来衡量算法线上效果\\t
- 进审量、人效、审核平均延时直接决定着人力审核成本\\t
- 盲审抽样率、盲审一致率体现数据打标人员对数据标注的标准理解深度\
5.2 天御的表现
\\

\\
图12. 天御的表现
\\
5.3 思考
\\
文本内容对甲方来说:
\\
- 非主营业务,对此块的重视程度不够\\t
- 业务价值不易衡量,员工投入其中其职业发展受限\\t
- 业务数据规模巨大,投入产出不划算\\t
- 预算偏少,不雅、不良评论、违法违规容易触及法律红线,严重影响主营业务\
综上,未来内容安全一条便宜省心的趋势,选择行业成熟的解决方案,可以实现业务健康发展的同时,确保内容安全。
\\
5月23日-24日,2018腾讯云+未来峰会将在广州举行。24日上午举行的安全分论坛,将齐聚来自腾讯集团多个安全团队的顶尖专家( TK(于旸)、 Killer(董志强) 等)以及业内重磅合作伙伴;将首次揭晓腾讯在企业安全领域的云管端全景布局;更有抗量子、加密算法与安全相结合的前沿技术分享。报名移步腾讯云官网~
互联网文本内容安全:腾讯云天御AI对抗实践相关推荐
- Excel 文本内容一行快速分为多行(亲自实践)
演示动画由ExcelHome论坛微领祝洪忠提供 微博发布地址:http://e.weibo.com/1341556070/zm0D4kpbQ 更多精彩内容尽在新浪微博@ExcelHome,欢迎关注.h ...
- 腾讯基于预训练模型的文本内容理解实践
分享嘉宾:赵哲博士 腾讯 高级研究员 编辑整理:张书源 爱丁堡大学 出品平台:DataFunTalk 导读:预训练已经成为自然语言处理任务的重要组成部分,为大量自然语言处理任务带来了显著提升.本文将围 ...
- 践行科技向善,腾讯优图联合腾讯天御发布面向未成年人的内容安全审核解决方案
日前,在2020腾讯全球数字生态大会AI专场上,腾讯优图实验室副总经理黄飞跃发表了以<技术爆炸时代里的优图:从跋山涉水,到越过山丘>为主题的演讲,并正式发布了面向未成年人的内容安全审核解决 ...
- 如何用Python批量提取PDF文本内容?
本文为你展示,如何用Python把许多PDF文件的文本内容批量提取出来,并且整理存储到数据框中,以便于后续的数据分析. 问题 最近,读者们在后台的留言,愈发五花八门了. 写了几篇关于自然语言处理的文章 ...
- 基于互联网大脑架构的腾讯未来趋势分析[系列1]
作者:刘锋,计算机博士 <互联网进化论> 前言 互联网大脑架构不是人为规划出来的,而是过去50年,互联网在科学探索和商业竞争两大动力推动下,形成的类脑架构. 它的提出是基于2008年以来, ...
- c语言如何用fscanf将字符串读取,在c语言中如何将文本内容 赋给一个 字符串
在c语言中如何将文本内容 赋给一个 字符串 来源:互联网 宽屏版 评论 2009-08-13 04:59:12 分类: 电脑/网络 >> 程序设计 >> 其他编程语言 问题 ...
- 丘比特之箭——知乎多场景内容匹配项目:实现各种不同类型的文本之间的准确匹配 |百万人学AI评选
2020 无疑是特殊的一年,而 AI 在开年的这场"战疫"中表现出了惊人的力量.站在"新十年"的起点上,CSDN[百万人学AI]评选活动正式启动.本届评选活动在 ...
- Excel表格中多个文本内容快速合并到一个单元格内
Excel表格中多个文本内容快速合并到一个单元格内 目录 Excel表格中多个文本内容快速合并到一个单元格内 1.在合并单元格内输入"=PHONETIC()"函数 2.框选需要合并 ...
- 马化腾:移动互联网上半场接近尾声 腾讯将拥抱产业互联网
雷帝网 乐天 10月31日报道 腾讯CEO马化腾今日发布公开信,称移动互联网的上半场已经接近尾声,下半场的序幕正在拉开. "伴随数字化进程,移动互联网的主战场,正在从上半场的消费互联网,向下 ...
最新文章
- yii2手册_史上最全的技术手册整理总结,编程小白都从这篇文章迅速成为大牛...
- linux php和java环境变量配置_Linux下Java环境变量的安装与配置
- 【C++深度剖析教程12】数组操作符的重载
- [2-sat]HDOJ3062 Party
- shell 脚本学习(一)
- 水滴石穿C语言之typedef的问题
- harbor 多端口_安装Harbor并修改默认使用的80端口
- 图解TCPIP-DNS
- 国内流行的两大开源.net微信公众平台SDK对比分析
- Windows网络编程获得本机IP地址
- 利用MATLAB对乐曲进行钢琴演奏【matlab调音_1】
- 九月热点:EasyDL智能边缘控制台、EdgeBoard路内停车分析盒全新发布
- CAN与CANFD的区别
- 干货!Web 网页设计规范
- 图像处理中的深度学习技术
- 计算机专业买什么牌子的笔记本,买笔记本电脑什么牌子好(2020年6月笔记本电脑推荐)...
- hdu 6078 Wavel Sequence
- matlab 一些函数的用法
- model.parameters()的理解与使用
- 彩色空间(Color Space)
热门文章
- 编程中定义的方法报异常问题
- Ubuntu16.04系统运行VINS-Mono(安装、环境配置)
- 一文攻破结构体-C语言
- 一些常用的gcc指令(持续更新)
- vue中用table_Ant-Design-Vue中关于Table组件的使用
- springsecurity不拦截某个接口_SpringSecurity 默认表单登录页展示流程源码
- SLAM | SLAM流程图集合
- 视觉里程计 | OF-VO:Robust and Efficient Stereo Visual Odometry Using Points and Feature Optical Flow
- java fast math,Java FastMath.ceil方法代碼示例
- python文字识别并获取位置_python实现简单的文字识别