云端大数据实战记录-大数据推荐
前言
WHY 云:为什么我们需要云,大数据时代我们面对两个问题,一个是大数据的存储,一个是大数据的计算。由于数据量过大,在单个终端上运行效率过差,所以人们用云来解决这两个问题。
WHAT IS 云:云得益于分布式计算的思想。举个简单的例子,执行一千万个数据每个数据都乘以10并输出,在个人pc上需要大概20分钟。如果是100台电脑做这个工作,可能只用几十秒就可以完成。云就是我们将复杂的工作通过一定的算法分配给云端的n个服务器,这样可以大大提高运算效率。
How 云:云的实现也就是分步式计算的过程。分布式的思想起源于MapReduce,是google最先发表的一篇论文中提到的,现在很多的分布式计算方法都是从中演变过来的。大体的思路是,将任务通过map分离——计算——合并——reduce——输出。
云的价值不光是存储数据,更是用来分析和处理数据,得益于云,更多的算法可以快捷的实现,所以说云计算和大数据倔是不可分割的,可能大家在平时的学习过程中还没有机会在云端接触大数据运算,下面就分享一下本人的一次云计算的经历。
1.背景
2.工具的简单说明
select distinct * from table_name;![]()
3.TRY

信息理论的鼻祖之一Claude E. Shannon把信息(熵)定义为离散随机事件的出现概率。说白了就是信息熵的值越大就表明这个信息集越混乱。
信息熵的计算公式,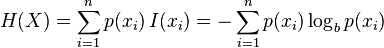 (建议去wiki学习一下)
(建议去wiki学习一下)
这里我们通过计算目标指数的熵和特征值得熵的差,也就是熵的增益来确定哪些特征值对于目标指数的影响最大。
第一部分-计算熵:函数主要是找出有几种目标指数,根据他们出现的频率计算其信息熵。


- def calcShannonEnt(dataSet):
- numEntries=len(dataSet)
- labelCounts={}
- for featVec in dataSet:
- currentLabel=featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel]=0
- labelCounts[currentLabel]+=1
- shannonEnt=0.0
- for key in labelCounts:
- prob =float(labelCounts[key])/numEntries
- shannonEnt-=prob*math.log(prob,2)
- return shannonEnt
第二部分-分割数据 因为要每个特征值都计算相应的信息熵,所以要对数据集分割,将所计算的特征值单独拿出来。
- def splitDataSet(dataSet, axis, value):
- retDataSet = []
- for featVec in dataSet:
- if featVec[axis] == value:
- reducedFeatVec = featVec[:axis] #chop out axis used for splitting
- reducedFeatVec.extend(featVec[axis+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
第三部分-找出信息熵增益最大的特征值
- def chooseBestFeatureToSplit(dataSet):
- numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
- baseEntropy = calcShannonEnt(dataSet)
- bestInfoGain = 0.0; bestFeature = -1
- for i in range(numFeatures): #iterate over all the features
- featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
- uniqueVals = set(featList) #get a set of unique values
- newEntropy = 0.0
- for value in uniqueVals:
- subDataSet = splitDataSet(dataSet, i, value)
- prob = len(subDataSet)/float(len(dataSet))
- newEntropy += prob * calcShannonEnt(subDataSet)
- infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
- if (infoGain > bestInfoGain): #compare this to the best gain so far
- bestInfoGain = infoGain #if better than current best, set to best
- bestFeature = i
- return bestFeature #returns an integer
第四部分-建立决策树
- def createTree(dataSet,labels):
- #把所有目标指数放在这个list里
- classList = [example[-1] for example in dataSet]
- #下面两个if是递归停止条件,分别是list中都是相同的指标或者指标就剩一个。
- if classList.count(classList[0]) == len(classList):
- return classList[0]
- if len(dataSet[0]) == 1:
- return majorityCnt(classList)
- #获得信息熵增益最大的特征值
- bestFeat = chooseBestFeatureToSplit(dataSet)
- bestFeatLabel = labels[bestFeat]
- #将决策树存在字典中
- myTree = {bestFeatLabel:{}}
- #labels删除当前使用完的特征值的label
- del(labels[bestFeat])
- featValues = [example[bestFeat] for example in dataSet]
- uniqueVals = set(featValues)
- #递归输出决策树
- for value in uniqueVals:
- subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
- myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
- return myTree
4.具体实现
(1)特征提取
(2)随机森林参数调试
5.总结
 (github.com/jimenbian,里面有很多算法的实现。
(github.com/jimenbian,里面有很多算法的实现。
/********************************
* 本文来自博客 “李博Garvin“
* 转载请标明出处:http://blog.csdn.net/buptgshengod
******************************************/
云端大数据实战记录-大数据推荐相关推荐
- 大数据推荐(个性化推荐)
大数据推荐分享.三场讲座系统的讲解了关于基于大数据的个性化推荐的体系和针对模型的探索.作为讲师主讲了关于个性化推荐的一些流程和算法. 转载于:https://www.cnblogs.com/wenBl ...
- 视频教程-全新大数据企业电商数据仓库项目实战教程-大数据
全新大数据企业电商数据仓库项目实战教程 张长志技术全才.擅长领域:区块链.大数据.Java等.10余年软件研发及企业培训经验,曾为多家大型企业提供企业内训如中石化,中国联通,中国移动等知名企业.拥有丰 ...
- 小白都能学会的Python基础 第六讲:综合实战2 - 大数据分词与词云图绘制
1.华小智系列 - Python基础(案例版) <Python基础>目录 第六讲:综合实战2 - 大数据分词与词云图绘制 1.大数据分词技巧 2.词频统计技巧 3.词云图绘制 4.微博词云 ...
- 视频教程-大数据分析师实战课-大数据
大数据分析师实战课 任老师,Cloudera管理/开发/分析认证讲师,华为高级特聘讲师,新华三大学高级特聘讲师,中国大数据技术与应用联盟高级讲师,全国高校大数据联盟特聘讲师,中国移动高级讲师,前IBM ...
- 视频教程-finereport从入门到实战视频教程-大数据
finereport从入门到实战视频教程 阿里云大学,腾讯云特骋讲师,曾任光华电子大数据项目总监,精通数据采集,处理,可视化全流程技术,具有极强的数据思维及数据变现能力. 孟光焱 ¥128.00 立即 ...
- 【云端大数据实战】大数据误区、大数据处理步骤分析
1.背景 首先感谢这次博客的主办方CSDN以及在初赛为我投票的网友们,你们的支持是Garvin前进的动力.本文思路的依据来源于本次天猫大数据竞赛长达三个月的参赛体验.博主作为 ...
- CSDN学霸课表——从应用解析到基础实战,大数据入门、晋级课程推荐
[大数据]Splunk企业级运维智能&大数据分析平台新手入门视频课程 讲师:张文星 本课程系Splunk入门系列课程,实战为主,实战中穿插相关概念和理论.课程包括Splunk基础知识.安装部署 ...
- hadoop+Spark实战基于大数据技术之电视收视率企业项目实战
课程简介 本课程将通过一个电视收视率项目实战驱动讲解,项目案例是国内的一家广电企业作为非洲国家的一个运营商,以用户收视行为数据作为基础数据,通过对频道和节目的分析,采用多维度统计分析的方法挖掘用户的收 ...
- 大数据推荐算法概念简述
Table of Contents 1.协同过滤 概念 如何协同过滤,来对用户A进行电影推荐? 2.内容推荐 概念 如何通过基于内容的推荐,来对求职者A进行职位推荐? 3.相似性推荐 概念 在给新用户 ...
最新文章
- Windows Phone 网络HttpWebRequest用法
- 2011软考软件设计师:C语言代码规范问题(1
- checkVector()
- html vue分页,Vue.js bootstrap前端实现分页和排序
- 前端学习(2586):如何设计高扩展路由
- 计算机与编程导论,计算机科学与编程导论
- OpenGL:显示一些立体图形示例程序(真不错)
- Practical JAVA(三)关于final
- 小米,红米手机miui安装谷歌服务框架GMS三件套安,安装Google Play商店
- java初级项目 小说_webmagic项目实战(爬小说网站)
- 30天自制操作系统第1天 - Hello World
- html涟漪效果,涟漪效果.html
- Word如何操作压缩图片?干货经验!怎么在Word中压缩图片?
- git安装、使用、建立github远程仓库、克隆远程仓库
- 如何构建虚拟机Hadoop集群,搭建3台ubuntu虚拟机集群
- 【控制理论】滑模控制最强解析
- 台式计算机用u盘给电脑安装系统,电脑台式机用u盘装系统教程
- 【LOJ6247】九个太阳(单位根反演)(二项式定理)
- Android studio 光标变粗的解决方法
- linux机器上crontab定时任务将日志输出到以日期命名的log文件
热门文章
- linux内核色彩管理,如何在Linux的色彩管理中获得标准结果
- 苹果11怎么关掉横屏_苹果手机这些常规操作你可能不会!教你省电又省心?
- C 语言读写中文出现乱码
- html页面多个按钮点击事件监听事件,HTML Button.onclick 事件汇总
- python中系列的含义_一篇文章让你彻底搞清楚Python中self的含义
- python的迭代器指向第一个字符_python(七)字符串格式化、生成器与迭代器
- 列出mongodb里的所有表的名字,合并所有表到一个大表,用pandas
- 分析linux系统的运行性能,Linux系统如何分析CPU的性能瓶颈
- vb.net限制datagridview不能选择_事业单位考试有哪些条件限制?
- 西工大与东北大学计算机,国内世界高水平大学排名:西北工业大学位居第一,东北大学排第二...