ssas表格模型 权限控制_性能调整SSAS表格模型
ssas表格模型 权限控制
Modeling for the xVelocity/Vertipaq engine is a completely different beast than modeling for your trusty multi-dimensional SSAS cubes.
In-memory = blazingly fast; At least that’s what you would think.
As Tabular models gain popularity with business users and developers alike, we’re starting to see that this isn’t always the case.
We’re going to take a look at some of the common errors and mistakes and how to avoid them.
And since the PowerPivot engine is the same – you will learn how to tune your PowerPivot-based Excel workbooks as well.
xVelocity / Vertipaq引擎的建模与可信赖的多维SSAS多维数据集的建模完全不同。
内存中=极快的速度; 至少那是您的想法。
随着表格模型在企业用户和开发人员中越来越受欢迎,我们开始发现情况并非总是如此。
我们将研究一些常见的错误和错误以及如何避免它们。
由于PowerPivot引擎是相同的–您还将学习如何调整基于PowerPivot的Excel工作簿。
PowerPivot was launched with the Vertipaq engine back in 2010, but when MS SQL Server 2012 was released with the SSAS Tabular mode, the Vertipaq engine had been rebranded as the xVelocity Engine.
PowerPivot于2010年与Vertipaq引擎一起启动,但是当MS SQL Server 2012以SSAS表格模式发布时,Vertipaq引擎已更名为xVelocity引擎。
It is, in fact, the same technology, which might confuse newcomers. I for one tend to use both names interchangeably, seeing as the Vertipaq name pops up all over the place.
实际上,这是同一技术,可能会使新来者感到困惑。 我倾向于将两个名称互换使用,因为Vertipaq名称随处可见。
At the heart of the engine – no matter what you call it – is the in-memory columnstore technology and some nifty compression techniques. The techniques have been discussed in-depth elsewhere and is not a topic for this article. But it’s worth knowing a bit about what is happening and why columnstore is different from your standard row-based SQL server.
不管您叫什么名字,引擎的核心都是内存中的列存储技术和一些精巧的压缩技术。 该技术已在其他地方进行了深入讨论,而不是本文的主题。 但是值得了解一下正在发生的事情以及为什么列存储与标准的基于行SQL Server不同。
As the name indicates, columnstore stores values in columns instead of in pages of rows with columns. This provides significantly increased performance when trying to fetch a sum of a column, or a distinct count – but takes a not so much when having to fetch an entire table.
To keep track of the values in each column, xVelocity uses a dictionary of unique values and an index of where the values are found. This can give a significant compression in the right circumstances.
顾名思义,columnstore将值存储在列中,而不是存储在具有列的行的页面中。 尝试获取列的总和或不同的计数时,这可以显着提高性能,但是在必须获取整个表时,所需的花费却不那么多。
为了跟踪每一列中的值,xVelocity使用唯一值的字典和找到值的位置的索引。 在适当的情况下,这可能会给您带来很大的压力。
Here’s a simple illustration of how this works:
这是它如何工作的简单说明:
There are several topics to consider when designing your model, I’ve grouped these into three areas ranging from the most basic – and where you gain the most effect to the more advanced and the effect varies more.
设计模型时,有几个主题需要考虑,我将这些主题分为三个区域,从最基本的到最有效的地方,再到最高级的地方,效果变化更大。
您的数据: (Your data: )
Try having as few unique records in your columns as you can. In other words, avoid high granularity in your columns. The larger the column dictionary is, the less effective your compression is, and your memory usage increases.
尝试在您的列中尽量减少唯一记录。 换句话说,请避免在列中使用高粒度。 列字典越大,压缩效果越差,并且内存使用量增加。
Avoid DateTime columns, better to split time and date into two separate columns. Don’t store time down to milliseconds unless it’s really needed, and so on.
避免使用DateTime列,最好将时间和日期分成两个单独的列。 除非确实需要,否则不要将时间存储到毫秒,依此类推。
Just as low granularity helps, so does the sorting of the columns – the closer the unique values are to each other in your column the smaller the dictionary index is. However, it’s not possible to sort all columns perfectly – so you need to consider which column sorting gives the best result for you.
就像低粒度一样,列的排序也有帮助-列中唯一值彼此越近,字典索引越小。 但是,不可能对所有列进行完美排序–因此,您需要考虑哪种列排序最适合您。
Since the data is stored by column and not by row, you should never pull an entire table into your model if you aren’t going to use all the columns. Yes, you can always hide the column from view – but the data in those hidden columns will still fill up memory. I’ve seen tables with 30+ columns being pulled in, just so that the developer could use one single column from the table.
由于数据是按列而不是按行存储的,因此,如果不打算使用所有列,则永远不要将整个表拉入模型。 是的,您始终可以从视图中隐藏该列-但这些隐藏列中的数据仍会填满内存。 我已经看到插入了30多个列的表,以使开发人员可以使用表中的单个列。
您的计算: (Your calculations:)
The calculation language of PowerPivot and Tabular – DAX – is a powerful language that lets you do all sorts of things with your data. You can calculate a running average, do simple distinct counts, add calculated columns to your tables and so on.
PowerPivot和Tabular的计算语言– DAX –是一种功能强大的语言,可让您对数据进行各种处理。 您可以计算移动平均值,进行简单的非重复计数,将计算出的列添加到表中等等。
This is all great, calculations are important and calculated columns lets you add functionality to your model quite easily, depending on your knowledge of DAX of course.
这一切都很好,计算很重要,并且计算列使您可以轻松地向模型添加功能,这当然取决于您对DAX的了解。
But, this comes with a price. Every calculation comes with a memory cost. For instance, on a small 5+ million row model – adding a simple «RELATED» column can add 2,5 MB to your model. And this will impact the performance of your cube. Therefore, when modeling your data, it’s important to consider exactly what you need to calculate in the model and what you can calculate before sending data to the model.
但是,这是有代价的。 每次计算都会带来内存成本。 例如,在一个5百万以上的小型行模型上,添加一个简单的“相关”列可以为您的模型增加2,5 MB。 这将影响多维数据集的性能。 因此,在对数据建模时,重要的是要仔细考虑在模型中需要计算的内容以及在将数据发送到模型之前可以计算的内容。
If you are using PowerPivot and not using PowerQuery, you are not using all your tools. PowerQuery is an excellent self-service ETL tool. And you can do a lot here.
如果您使用的是PowerPivot而不是PowerQuery,则说明您并未使用所有工具。 PowerQuery是出色的自助ETL工具。 您可以在这里做很多事情。
Likewise, if you are working with a Tabular model you will have access to both regular MS SQL Server as well as Integration Services. Both of which will let you do transformations and calculations that will be delivered ready for use in your model. And now it’ll be just regular data – taking no more memory or CPU than any of your other columns. Pulling entire tables into your model, just so you can use one column in a RELATED-formula in your fact table is a waste of resources. Add the column to your fact table before pulling it in instead.
同样,如果您使用表格模型,则可以访问常规的MS SQL Server以及Integration Services。 两者都可以让您进行转换和计算,以准备在模型中使用。 现在,它只是常规数据–占用的内存或CPU不超过其他任何列。 将整个表放入模型中,只是为了在事实表的RELATED公式中使用一列是浪费资源。 将该列添加到您的事实表中,然后再拉入。
事实和维度表: (Your Fact and Dimension tables:)
Now this is an area that you should consider more closely if you – after having tweaked both your data and your calculations – still see the need for tuning. This will also be a good place to look if you are inheriting a model someone else made.
现在,在调整数据和计算之后,如果仍然认为有必要进行调整,则应该更仔细地考虑这一领域。 如果您要继承别人制作的模型,那么这也是一个不错的地方。
It doesn’t always give the needed results, and sometimes you will trade off memory consumption for increased processing time. But it might be the right thing for you, so take it into consideration.
它并不总是能提供所需的结果,有时您会在内存消耗方面进行权衡以增加处理时间。 但这可能对您来说是正确的事情,因此请考虑在内。
Consider the following model
考虑以下模型
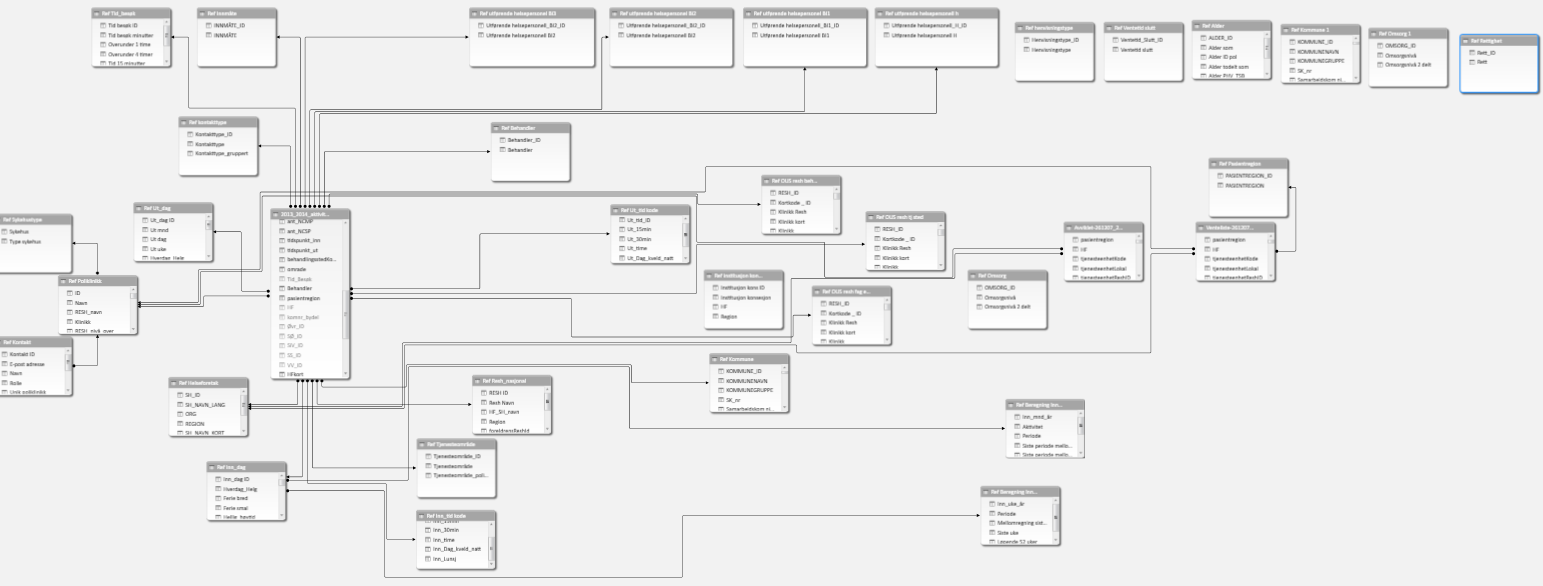
This a mostly standard snowflake schema – except for the six tables that are isolated from the rest – and do nothing. This is, of course, a total waste of memory. Remember to remove unused tables when you are done modeling.
这是一个最标准的雪花模式-除了与其余表隔离的六个表之外,什么也不做。 当然,这完全是浪费内存。 完成建模后,请记住删除未使用的表。
However, there are still quite a few dimensions here. And as mentioned earlier – dragging in an entire table to use only one column is a waste. Even if you drag in just two – one you want to use and then a link-column you might be better off merging this into either the fact table or into a related dimension. Every join and lookup will also take up some resources, and even if that seems minimal in the larger scale of things, it all adds up.
但是,这里仍然有很多尺寸。 如前所述,将整个表拖到只使用一列是一种浪费。 即使您只拖入两个-您要使用一个,然后拖入一个链接列,您最好将其合并到事实表或相关维中。 每次连接和查找也将占用一些资源,即使在较大规模的事情中看起来很少,也全部累加了。
To illustrate, here is a compact version of the same model as above:
为了说明这一点,这是与上述相同模型的紧凑版本:
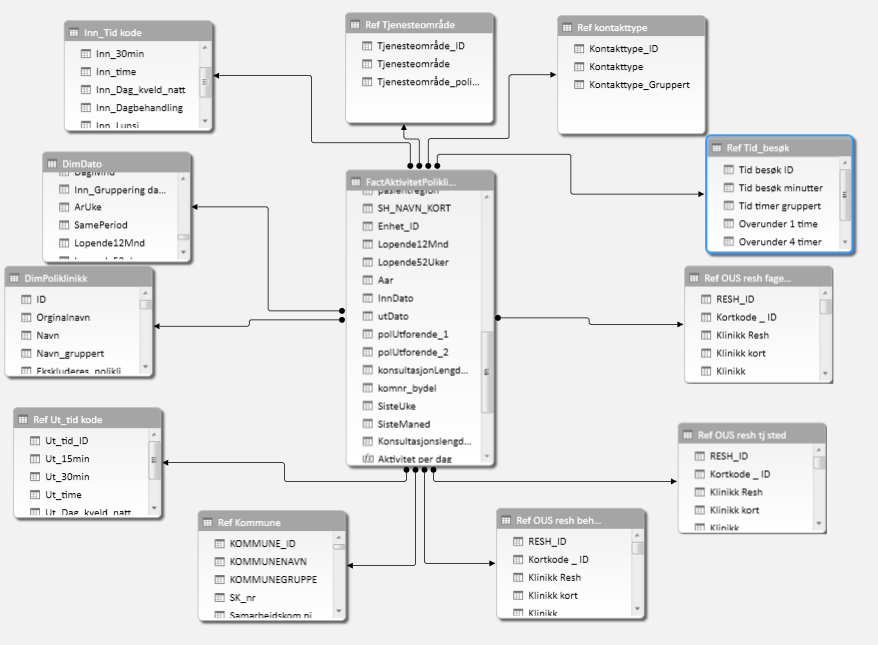
Dimensions have been merged into either the fact table or dimension tables that contained much of the same information or similar information.
维度已合并到事实表或包含许多相同或相似信息的维度表中。
There are fewer jumps and the model performs well. A potential downside to this is that a large fact table can take longer to process, though it might perform better once it’s in memory. This is something that might be totally fine or a deal breaker. And it will be up to you to decide what is best in any given scenario.
跳跃少,模型运行良好。 潜在的不利因素是大型事实表可能需要更长的处理时间,尽管一旦将其存储在内存中可能会表现更好。 这可能完全没问题,或者破坏了交易。 在任何给定情况下,由您决定什么是最好的。
翻译自: https://www.sqlshack.com/performance-tuning-an-ssas-tabular-model/
ssas表格模型 权限控制
ssas表格模型 权限控制_性能调整SSAS表格模型相关推荐
- ssas表格模型 权限控制_创建第一个SSAS表格模型数据库
ssas表格模型 权限控制 Considering BI environment, when comparing Multidimensional Vs Tabular model databases ...
- ssas表格模型 权限控制_如何在SQL Server 2016中自动执行SSAS表格模型处理
ssas表格模型 权限控制 There are many ways to process your SSAS Tabular Model. This can be achieved in SSIS u ...
- ssas表格模型 权限控制_如何使用DAX函数查询SSAS表格模型数据库
ssas表格模型 权限控制 To make the first steps into the BI world easier, you just need to build one SSAS Tabu ...
- ssas表格模型 权限控制_Analysis Services(SSAS)表格模型中的时间智能
ssas表格模型 权限控制 In the analytical world, time is an important slicer. The ability to view data over ti ...
- 实现权限控制_在 Go 语言中使用 casbin 实现基于角色的 HTTP 权限控制
Go语言中文网,致力于每日分享编码.开源等知识,欢迎关注我,会有意想不到的收获! 身份认证和授权对 web 应用的安全至关重要.最近,我用 Go 完成了我的第一个正式的 web 应用,这篇文章是在这个 ...
- 权限控制_多租户系统设计之权限控制
概述 业务层面的隔离是用户可以直接感知的隔离,也是多租户系统必须实现的隔离,在上篇文章中提到的数据隔离主要是针对数据存储层面而言的,用户一般感知不到,所以如"基于数据行的租户唯一标识&quo ...
- hue权限控制_如何通过键盘快捷键控制Philips Hue灯
hue权限控制 Being able to turn your lights on and off with your voice is one of the best things about ha ...
- java按钮权限控制_详解Spring Security 中的四种权限控制方式
Spring Security 中对于权限控制默认已经提供了很多了,但是,一个优秀的框架必须具备良好的扩展性,恰好,Spring Security 的扩展性就非常棒,我们既可以使用 Spring Se ...
- hive表级权限控制_数据库权限管理:表、行、列级别的权限控制
权限规则 1. 在配有主从集群时建议在主节点上做权限相关操作 2. 只有管理员和超级管理员才有将数据导入至表中的权限 3. 管理员用户赋予的是以整表为单位的权限,所有能赋予的权限为create/sel ...
最新文章
- error MIDL2025/2026
- 机器学习笔记 时间序列预测(基本数据处理,Box-Cox)
- hdu 5182 PM2.5
- 吴恩达机器学习笔记(三) —— Regularization正则化
- 查看xxx.a库架构的命令
- 重现江湖!大数据高并发——架构师秘籍
- php在线模拟高考志愿,高考志愿模拟填报系统
- 【飞秋】一起学Windows Phone7开发(十三.二 按钮控件)
- RabbitMQ的基础知识与使用
- css hack 笔记 for ie8,ie7
- 计算机维汉输入法表格,维语输入法
- 计算机系统时间显示不准确的原因,电脑时间总是不对原因 电脑时间总是不对三种解决方案...
- lodash中curry的实现
- Python输出函数print()总结(python print())
- [python]用flask框架搭建微信公众号的后台
- Mysql 5.7 免安装版windows安装完整教程
- vue项目打包出错:Unexpected token arrow «=>», expected punc «,» [static/js/chunk-1558f5a0.b64bfa00.js:626,2
- app运营业绩统计管理框架模板
- 软考网管教程精讲之提高交换机网络整体效率
- 2021-07-19
热门文章
- python中颜色空间直方图_OpenCV—python 颜色空间(RGB,HSV,Lab)与 颜色直方图
- cip协议服务器,控制及信息协议(CIP)
- 锐捷服务器虚拟化技术_用它!锐捷“双擎”云桌面助力检察机关统一业务应用系统2.0上线...
- [Swift]LeetCode212. 单词搜索 II | Word Search II
- 记一次成功部署kolla-ansible ocata版本过程
- 给考研迷茫中的你的一封信
- initializer element is not a compile-time constant
- 《C++标准程序库》学习笔记(一)C++相关特性
- 使用Cygwin登录Raspberry PI
- MVC如何分离Controller与View在不同的项目?