集合类之番外篇:深入解析HashMap、HashTable
Java集合类是个非常重要的知识点,HashMap、HashTable、ConcurrentHashMap等算是集合类中的重点,可谓“重中之重”,首先来看个问题,如面试官问你:HashMap和HashTable有什么区别,一个比较简单的回答是:
1、HashMap是非线程安全的,HashTable是线程安全的。
2、HashMap的键和值都允许有null值存在,而HashTable则不行。
3、因为线程安全的问题,HashMap效率比HashTable的要高。
能答出上面的三点,简单的面试,算是过了,但是如果再问:Java中的另一个线程安全的与HashMap及其类似的类是什么?同样是线程安全,它与HashTable在线程同步上有什么不同?能把第二个问题完整的答出来,说明你的基础算是不错的了。带着这个问题,本章开始系Java之美[从菜鸟到高手演变]系列之深入解析HashMap和HashTable类应用而生!总想在文章的开头说点儿什么,但又无从说起。从最近的一些面试说起吧,感受就是:知识是永无止境的,永远不要觉得自己已经掌握了某些东西。如果对哪一块知识感兴趣,那么,请多多的花时间,哪怕最基础的东西也要理解它的原理,尽量往深了研究,在学习的同时,记得多与大家交流沟通,因为也许某些东西,从你自己的角度,是很难发现的,因为你并没有那么多的实验环境去发现他们。只有交流的多了,才能及时找出自己的不足,才能认识到:“哦,原来我还有这么多不知道的东西!”。
一、HashMap的内部存储结构 Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表,数组的特点:连续空间,寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增删较慢。而链表正好相反,由于空间不连续,寻址困难,增删元素只需修改指针,所以查询慢、增删快。有没有一种数据结构来综合一下数组和链表,以便发挥他们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增删速度,所以很适合在海量数据的环境中使用。一般实现哈希表的方法采用“拉链法”,我们可以理解为“链表的数组”,如下图:
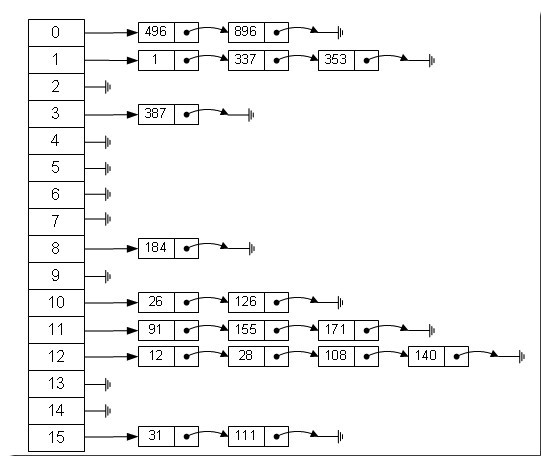
从上图中,我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。它的内部其实是用一个Entity数组来实现的,属性有key、value、next。接下来我会从初始化阶段详细的讲解HashMap的内部结构。
1、初始化 首先来看三个常量: static final int DEFAULT_INITIAL_CAPACITY = 16; 初始容量:16 static final int MAXIMUM_CAPACITY = 1 << 30; 最大容量:2的30次方:1073741824 static final float DEFAULT_LOAD_FACTOR = 0.75f; 装载因子,后面再说它的作用 来看个无参构造方法,也是我们最常用的:
- public HashMap() {
- this.loadFactor = DEFAULT_LOAD_FACTOR;
- threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
- table = new Entry[DEFAULT_INITIAL_CAPACITY];
- init();
- }
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR;threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);table = new Entry[DEFAULT_INITIAL_CAPACITY];init();}loadFactor、threshold的值在此处没有起到作用,不过他们在后面的扩容方面会用到,此处只需理解table=new Entry[DEFAULT_INITIAL_CAPACITY].说明,默认就是开辟16个大小的空间。另外一个重要的构造方法:
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- thrownew IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- thrownew IllegalArgumentException("Illegal load factor: " +
- loadFactor);
- // Find a power of 2 >= initialCapacity
- int capacity = 1;
- while (capacity < initialCapacity)
- capacity <<= 1;
- this.loadFactor = loadFactor;
- threshold = (int)(capacity * loadFactor);
- table = new Entry[capacity];
- init();
- }
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);// Find a power of 2 >= initialCapacityint capacity = 1;while (capacity < initialCapacity)capacity <<= 1;this.loadFactor = loadFactor;threshold = (int)(capacity * loadFactor);table = new Entry[capacity];init();}就是说传入参数的构造方法,我们把重点放在:
- while (capacity < initialCapacity)
- capacity <<= 1;
while (capacity < initialCapacity)capacity <<= 1;上面,该代码的意思是,实际的开辟的空间要大于传入的第一个参数的值。举个例子: new HashMap(7,0.8),loadFactor为0.8,capacity为7,通过上述代码后,capacity的值为:8.(1 << 2的结果是4,2 << 2的结果为8<此处感谢网友wego1234的指正>)。所以,最终capacity的值为8,最后通过new Entry[capacity]来创建大小为capacity的数组,所以,这种方法最红取决于capacity的大小。 2、put(Object key,Object value)操作 当调用put操作时,首先判断key是否为null,如下代码1处:
- <p>public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key.hashCode());
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }</p><p> modCount++;
- addEntry(hash, key, value, i);
- returnnull;
- }</p>
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
modCount++; addEntry(hash, key, value, i); return null; }
如果key是null,则调用如下代码:
- private V putForNullKey(V value) {
- for (Entry<K,V> e = table[0]; e != null; e = e.next) {
- if (e.key == null) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(0, null, value, 0);
- returnnull;
- }
private V putForNullKey(V value) {for (Entry<K,V> e = table[0]; e != null; e = e.next) {if (e.key == null) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(0, null, value, 0);return null;}就是说,获取Entry的第一个元素table[0],并基于第一个元素的next属性开始遍历,直到找到key为null的Entry,将其value设置为新的value值。 如果没有找到key为null的元素,则调用如上述代码的addEntry(0, null, value, 0);增加一个新的entry,代码如下:
- void addEntry(int hash, K key, V value, int bucketIndex) {
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
- if (size++ >= threshold)
- resize(2 * table.length);
- }
void addEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<K,V>(hash, key, value, e);if (size++ >= threshold)resize(2 * table.length);}先获取第一个元素table[bucketIndex],传给e对象,新建一个entry,key为null,value为传入的value值,next为获取的e对象。如果容量大于threshold,容量扩大2倍。 如果key不为null,这也是大多数的情况,重新看一下源码:
- public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key.hashCode());//---------------2---------------
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {//--------------3-----------
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }//-------------------4------------------
- modCount++;//----------------5----------
- addEntry(hash, key, value, i);-------------6-----------
- returnnull;
- }
public V put(K key, V value) {if (key == null)return putForNullKey(value);int hash = hash(key.hashCode());//---------------2---------------int i = indexFor(hash, table.length);for (Entry<K,V> e = table[i]; e != null; e = e.next) {//--------------3-----------Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}//-------------------4------------------modCount++;//----------------5----------addEntry(hash, key, value, i);-------------6-----------return null;}看源码中2处,首先会进行key.hashCode()操作,获取key的哈希值,hashCode()是Object类的一个方法,为本地方法,内部实现比较复杂,我们 会在后面作单独的关于Java中Native方法的分析中介绍。hash()的源码如下:
- staticint hash(int h) {
- // This function ensures that hashCodes that differ only by
- // constant multiples at each bit position have a bounded
- // number of collisions (approximately 8 at default load factor).
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
- }
static int hash(int h) {// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}int i = indexFor(hash, table.length);的意思,相当于int i = hash % Entry[].length;得到i后,就是在Entry数组中的位置,(上述代码5和6处是如果Entry数组中不存在新要增加的元素,则执行5,6处的代码,如果存在,即Hash冲突,则执行 3-4处的代码,此处HashMap中采用链地址法解决Hash冲突。此处经网友bbycszh指正,发现上述陈述有些问题)。重新解释:其实不管Entry数组中i位置有无元素,都会去执行5-6处的代码,如果没有,则直接新增,如果有,则将新元素设置为Entry[0],其next指针指向原有对象,即原有对象为Entry[1]。具体方法可以解释为下面的这段文字:(3-4处的代码只是检查在索引为i的这条链上有没有重复的,有则替换,无则无处理)
上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。如, 第一个键值对A进来,通过计算其key的hash得到的i=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其i也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,i也等于0,那么C.next = B,Entry[0] = C;这样我们发现i=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起,也就是说数组中存储的是最后插入的元素。
到这里为止,HashMap的大致实现,我们应该已经清楚了。当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个i的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为因子),随着map的size越来越大,Entry[]会以一定的规则加长长度。
2、get(Object key)操作 get(Object key)操作时根据键来获取值,如果了解了put操作,get操作容易理解,先来看看源码的实现:
- public V get(Object key) {
- if (key == null)
- return getForNullKey();
- int hash = hash(key.hashCode());
- for (Entry<K,V> e = table[indexFor(hash, table.length)];
- e != null;
- e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k)))//-------------------1----------------
- return e.value;
- }
- returnnull;
- }
public V get(Object key) {if (key == null)return getForNullKey();int hash = hash(key.hashCode());for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k)))//-------------------1----------------return e.value;}return null;}
意思就是:1、当key为null时,调用getForNullKey(),源码如下:
- private V getForNullKey() {
- for (Entry<K,V> e = table[0]; e != null; e = e.next) {
- if (e.key == null)
- return e.value;
- }
- returnnull;
- }
private V getForNullKey() {for (Entry<K,V> e = table[0]; e != null; e = e.next) {if (e.key == null)return e.value;}return null;}2、当key不为null时,先根据hash函数得到hash值,在更具indexFor()得到i的值,循环遍历链表,如果有:key值等于已存在的key值,则返回其value。如上述get()代码1处判断。
总结下HashMap新增put和获取get操作:
- //存储时:
- int hash = key.hashCode();
- int i = hash % Entry[].length;
- Entry[i] = value;
- //取值时:
- int hash = key.hashCode();
- int i = hash % Entry[].length;
- return Entry[i];
//存储时:
int hash = key.hashCode();
int i = hash % Entry[].length;
Entry[i] = value;//取值时:
int hash = key.hashCode();
int i = hash % Entry[].length;
return Entry[i];理解了就比较简单。
此处附一个简单的HashMap小算法应用:
- package com.xtfggef.hashmap;
- import java.util.HashMap;
- import java.util.Map;
- import java.util.Set;
- /**
- * 打印在数组中出现n/2以上的元素
- * 利用一个HashMap来存放数组元素及出现的次数
- * @author erqing
- *
- */
- publicclass HashMapTest {
- publicstaticvoid main(String[] args) {
- int [] a = {2,3,2,2,1,4,2,2,2,7,9,6,2,2,3,1,0};
- Map<Integer, Integer> map = new HashMap<Integer,Integer>();
- for(int i=0; i<a.length; i++){
- if(map.containsKey(a[i])){
- int tmp = map.get(a[i]);
- tmp+=1;
- map.put(a[i], tmp);
- }else{
- map.put(a[i], 1);
- }
- }
- Set<Integer> set = map.keySet();//------------1------------
- for (Integer s : set) {
- if(map.get(s)>=a.length/2){
- System.out.println(s);
- }
- }//--------------2---------------
- }
- }
package com.xtfggef.hashmap;import java.util.HashMap;
import java.util.Map;
import java.util.Set;/*** 打印在数组中出现n/2以上的元素* 利用一个HashMap来存放数组元素及出现的次数* @author erqing**/
public class HashMapTest {public static void main(String[] args) {int [] a = {2,3,2,2,1,4,2,2,2,7,9,6,2,2,3,1,0};Map<Integer, Integer> map = new HashMap<Integer,Integer>();for(int i=0; i<a.length; i++){if(map.containsKey(a[i])){int tmp = map.get(a[i]);tmp+=1;map.put(a[i], tmp);}else{map.put(a[i], 1);}}Set<Integer> set = map.keySet();//------------1------------for (Integer s : set) {if(map.get(s)>=a.length/2){System.out.println(s);}}//--------------2---------------}
}此处注意两个地方,map.containsKey(),还有就是上述1-2处的代码。
理解了HashMap的上面的操作,其它的大多数方法都很容易理解了。搞清楚它的内部存储机制,一切OK!
二、HashTable的内部存储结构
HashTable和HashMap采用相同的存储机制,二者的实现基本一致,不同的是:
1、HashMap是非线程安全的,HashTable是线程安全的,内部的方法基本都是synchronized。
2、HashTable不允许有null值的存在。
在HashTable中调用put方法时,如果key为null,直接抛出NullPointerException。其它细微的差别还有,比如初始化Entry数组的大小等等,但基本思想和HashMap一样。
三、HashTable和ConcurrentHashMap的比较
如我开篇所说一样,ConcurrentHashMap是线程安全的HashMap的实现。同样是线程安全的类,它与HashTable在同步方面有什么不同呢?
之前我们说,synchronized关键字加锁的原理,其实是对对象加锁,不论你是在方法前加synchronized还是语句块前加,锁住的都是对象整体,但是ConcurrentHashMap的同步机制和这个不同,它不是加synchronized关键字,而是基于lock操作的,这样的目的是保证同步的时候,锁住的不是整个对象。事实上,ConcurrentHashMap可以满足concurrentLevel个线程并发无阻塞的操作集合对象。关于concurrentLevel稍后介绍。
1、构造方法
为了容易理解,我们先从构造函数说起。ConcurrentHashMap是基于一个叫Segment数组的,其实和Entry类似,如下:
- public ConcurrentHashMap()
- {
- this(16, 0.75F, 16);
- }
public ConcurrentHashMap(){this(16, 0.75F, 16);}
默认传入值16,调用下面的方法:
- public ConcurrentHashMap(int paramInt1, float paramFloat, int paramInt2)
- {
- if ((paramFloat <= 0F) || (paramInt1 < 0) || (paramInt2 <= 0))
- thrownew IllegalArgumentException();
- if (paramInt2 > 65536) {
- paramInt2 = 65536;
- }
- int i = 0;
- int j = 1;
- while (j < paramInt2) {
- ++i;
- j <<= 1;
- }
- this.segmentShift = (32 - i);
- this.segmentMask = (j - 1);
- this.segments = Segment.newArray(j);
- if (paramInt1 > 1073741824)
- paramInt1 = 1073741824;
- int k = paramInt1 / j;
- if (k * j < paramInt1)
- ++k;
- int l = 1;
- while (l < k)
- l <<= 1;
- for (int i1 = 0; i1 < this.segments.length; ++i1)
- this.segments[i1] = new Segment(l, paramFloat);
- }
public ConcurrentHashMap(int paramInt1, float paramFloat, int paramInt2){if ((paramFloat <= 0F) || (paramInt1 < 0) || (paramInt2 <= 0))throw new IllegalArgumentException();if (paramInt2 > 65536) {paramInt2 = 65536;}int i = 0;int j = 1;while (j < paramInt2) {++i;j <<= 1;}this.segmentShift = (32 - i);this.segmentMask = (j - 1);this.segments = Segment.newArray(j);if (paramInt1 > 1073741824)paramInt1 = 1073741824;int k = paramInt1 / j;if (k * j < paramInt1)++k;int l = 1;while (l < k)l <<= 1;for (int i1 = 0; i1 < this.segments.length; ++i1)this.segments[i1] = new Segment(l, paramFloat);}你会发现比HashMap的构造函数多一个参数,paramInt1就是我们之前谈过的initialCapacity,就是数组的初始化大小,paramfloat为loadFactor(装载因子),而paramInt2则是我们所要说的concurrentLevel,这三个值分别被初始化为16,0.75,16,经过:
- while (j < paramInt2) {
- ++i;
- j <<= 1;
- }
while (j < paramInt2) {++i;j <<= 1;}后,j就是我们最终要开辟的数组的size值,当paramInt1为16时,计算出来的size值就是16.通过:
this.segments = Segment.newArray(j)后,我们看出了,最终稿创建的Segment数组的大小为16.最终创建Segment对象时:
- this.segments[i1] = new Segment(cap, paramFloat);
this.segments[i1] = new Segment(cap, paramFloat);需要cap值,而cap值来源于:
- int k = paramInt1 / j;
- if (k * j < paramInt1)
- ++k;
- int cap = 1;
- while (cap < k)
- cap <<= 1;
int k = paramInt1 / j;if (k * j < paramInt1)++k;int cap = 1;while (cap < k)cap <<= 1;组后创建大小为cap的数组。最后根据数组的大小及paramFloat的值算出了threshold的值:
this.threshold = (int)(paramArrayOfHashEntry.length * this.loadFactor)。
2、put操作
- public V put(K paramK, V paramV)
- {
- if (paramV == null)
- thrownew NullPointerException();
- int i = hash(paramK.hashCode());
- return segmentFor(i).put(paramK, i, paramV, false);
- }
public V put(K paramK, V paramV){if (paramV == null)throw new NullPointerException();int i = hash(paramK.hashCode());return segmentFor(i).put(paramK, i, paramV, false);}与HashMap不同的是,如果key为null,直接抛出NullPointer异常,之后,同样先计算hashCode的值,再计算hash值,不过此处hash函数和HashMap中的不一样:
- privatestaticint hash(int paramInt)
- {
- paramInt += (paramInt << 15 ^ 0xFFFFCD7D);
- paramInt ^= paramInt >>> 10;
- paramInt += (paramInt << 3);
- paramInt ^= paramInt >>> 6;
- paramInt += (paramInt << 2) + (paramInt << 14);
- return (paramInt ^ paramInt >>> 16);
- }
private static int hash(int paramInt){paramInt += (paramInt << 15 ^ 0xFFFFCD7D);paramInt ^= paramInt >>> 10;paramInt += (paramInt << 3);paramInt ^= paramInt >>> 6;paramInt += (paramInt << 2) + (paramInt << 14);return (paramInt ^ paramInt >>> 16);}- final Segment<K, V> segmentFor(int paramInt)
- {
- returnthis.segments[(paramInt >>> this.segmentShift & this.segmentMask)];
- }
final Segment<K, V> segmentFor(int paramInt){return this.segments[(paramInt >>> this.segmentShift & this.segmentMask)];}根据上述代码找到Segment对象后,调用put来操作:
- V put(K paramK, int paramInt, V paramV, boolean paramBoolean)
- {
- lock();
- try {
- Object localObject1;
- Object localObject2;
- int i = this.count;
- if (i++ > this.threshold)
- rehash();
- ConcurrentHashMap.HashEntry[] arrayOfHashEntry = this.table;
- int j = paramInt & arrayOfHashEntry.length - 1;
- ConcurrentHashMap.HashEntry localHashEntry1 = arrayOfHashEntry[j];
- ConcurrentHashMap.HashEntry localHashEntry2 = localHashEntry1;
- while ((localHashEntry2 != null) && (((localHashEntry2.hash != paramInt) || (!(paramK.equals(localHashEntry2.key)))))) {
- localHashEntry2 = localHashEntry2.next;
- }
- if (localHashEntry2 != null) {
- localObject1 = localHashEntry2.value;
- if (!(paramBoolean))
- localHashEntry2.value = paramV;
- }
- else {
- localObject1 = null;
- this.modCount += 1;
- arrayOfHashEntry[j] = new ConcurrentHashMap.HashEntry(paramK, paramInt, localHashEntry1, paramV);
- this.count = i;
- }
- return localObject1;
- } finally {
- unlock();
- }
- }
V put(K paramK, int paramInt, V paramV, boolean paramBoolean){lock();try {Object localObject1;Object localObject2;int i = this.count;if (i++ > this.threshold)rehash();ConcurrentHashMap.HashEntry[] arrayOfHashEntry = this.table;int j = paramInt & arrayOfHashEntry.length - 1;ConcurrentHashMap.HashEntry localHashEntry1 = arrayOfHashEntry[j];ConcurrentHashMap.HashEntry localHashEntry2 = localHashEntry1;while ((localHashEntry2 != null) && (((localHashEntry2.hash != paramInt) || (!(paramK.equals(localHashEntry2.key)))))) {localHashEntry2 = localHashEntry2.next;}if (localHashEntry2 != null) {localObject1 = localHashEntry2.value;if (!(paramBoolean))localHashEntry2.value = paramV;}else {localObject1 = null;this.modCount += 1;arrayOfHashEntry[j] = new ConcurrentHashMap.HashEntry(paramK, paramInt, localHashEntry1, paramV);this.count = i;}return localObject1;} finally {unlock();}}先调用lock(),lock是ReentrantLock类的一个方法,用当前存储的个数+1来和threshold比较,如果大于threshold,则进行rehash,将当前的容量扩大2倍,重新进行hash。之后对hash的值和数组大小-1进行按位于操作后,得到当前的key需要放入的位置,从这儿开始,和HashMap一样。
从上述的分析看出,ConcurrentHashMap基于concurrentLevel划分出了多个Segment来对key-value进行存储,从而避免每次锁定整个数组,在默认的情况下,允许16个线程并发无阻塞的操作集合对象,尽可能地减少并发时的阻塞现象。
在多线程的环境中,相对于HashMap,ConcurrentHashMap会带来很大的性能提升!
欢迎读者批评指正,有任何建议请联系:
EGG:xtfggef@gmail.com http://weibo.com/xtfggef
四、HashMap常见问题分析
此处我觉得网友huxb23@126的一篇文章说的很好,分析多线程并发写HashMap线程被hang住的原因 ,因为是优秀的资源,此处我整理下搬到这儿。
以下内容转自博文:http://blog.163.com/huxb23@126/blog/static/625898182011211318854/
先看原问题代码:
- import java.util.HashMap;
- publicclass TestLock {
- private HashMap map = new HashMap();
- public TestLock() {
- Thread t1 = new Thread() {
- publicvoid run() {
- for (int i = 0; i < 50000; i++) {
- map.put(new Integer(i), i);
- }
- System.out.println("t1 over");
- }
- };
- Thread t2 = new Thread() {
- publicvoid run() {
- for (int i = 0; i < 50000; i++) {
- map.put(new Integer(i), i);
- }
- System.out.println("t2 over");
- }
- };
- t1.start();
- t2.start();
- }
- publicstaticvoid main(String[] args) {
- new TestLock();
- }
- }
import java.util.HashMap;public class TestLock {private HashMap map = new HashMap();public TestLock() {Thread t1 = new Thread() {public void run() {for (int i = 0; i < 50000; i++) {map.put(new Integer(i), i);}System.out.println("t1 over");}};Thread t2 = new Thread() {public void run() {for (int i = 0; i < 50000; i++) {map.put(new Integer(i), i);}System.out.println("t2 over");}};t1.start();t2.start();}public static void main(String[] args) {new TestLock();}
}
就是启了两个线程,不断的往一个非线程安全的HashMap中put内容,put的内容很简单,key和value都是从0自增的整数(这个put的内容做的并不好,以致于后来干扰了我分析问题的思路)。对HashMap做并发写操作,我原以为只不过会产生脏数据的情况,但反复运行这个程序,会出现线程t1、t2被hang住的情况,多数情况下是一个线程被hang住另一个成功结束,偶尔会两个线程都被hang住。说到这里,你如果觉得不好好学习ConcurrentHashMap而在这瞎折腾就手下留情跳过吧。 好吧,分析下HashMap的put函数源码看看问题出在哪,这里就罗列出相关代码(jdk1.6):
- public V put(K paramK, V paramV)
- {
- if (paramK == null)
- return putForNullKey(paramV);
- int i = hash(paramK.hashCode());
- int j = indexFor(i, this.table.length);
- for (Entry localEntry = this.table[j]; localEntry != null; localEntry = localEntry.next)
- {
- if (localEntry.hash == i) { java.lang.Object localObject1;
- if (((localObject1 = localEntry.key) == paramK) || (paramK.equals(localObject1))) {
- java.lang.Object localObject2 = localEntry.value;
- localEntry.value = paramV;
- localEntry.recordAccess(this);
- return localObject2;
- }
- }
- }
- this.modCount += 1;
- addEntry(i, paramK, paramV, j);
- returnnull;
- }
- private V putForNullKey(V paramV)
- {
- for (Entry localEntry = this.table[0]; localEntry != null; localEntry = localEntry.next)
- if (localEntry.key == null) {
- java.lang.Object localObject = localEntry.value;
- localEntry.value = paramV;
- localEntry.recordAccess(this);
- return localObject;
- }
- this.modCount += 1;
- addEntry(0, null, paramV, 0);
- returnnull;
- }
public V put(K paramK, V paramV){if (paramK == null)return putForNullKey(paramV);int i = hash(paramK.hashCode());int j = indexFor(i, this.table.length);for (Entry localEntry = this.table[j]; localEntry != null; localEntry = localEntry.next){if (localEntry.hash == i) { java.lang.Object localObject1;if (((localObject1 = localEntry.key) == paramK) || (paramK.equals(localObject1))) {java.lang.Object localObject2 = localEntry.value;localEntry.value = paramV;localEntry.recordAccess(this);return localObject2;}}}this.modCount += 1;addEntry(i, paramK, paramV, j);return null;}private V putForNullKey(V paramV){for (Entry localEntry = this.table[0]; localEntry != null; localEntry = localEntry.next)if (localEntry.key == null) {java.lang.Object localObject = localEntry.value;localEntry.value = paramV;localEntry.recordAccess(this);return localObject;}this.modCount += 1;addEntry(0, null, paramV, 0);return null;}通过jconsole(或者thread dump),可以看到线程停在了transfer方法的while循环处。这个transfer方法的作用是,当Map中元素数超过阈值需要resize时,它负责把原Map中的元素映射到新Map中。我修改了HashMap,加上了@标记2和@标记3的代码片断,以打印出死循环时的状态,结果死循环线程总是出现类似这样的输出:“Thread-1,e==next:false,e==next.next:true,e:108928=108928,next:108928=108928,eq:true”。 这个输出表明: 1)这个Entry链中的两个Entry之间的关系是:e=e.next.next,造成死循环。 2)e.equals(e.next),但e!=e.next。因为测试例子中两个线程put的内容一样,并发时可能同一个key被保存了多个value,这种错误是在addEntry函数产生的,但这和线程死循环没有关系。
接下来就分析transfer中那个while循环了。先所说这个循环正常的功能:src[j]保存的是映射成同一个hash值的多个Entry的链表,这个src[j]可能为null,可能只有一个Entry,也可能由多个Entry链接起来。假设是多个Entry,原来的链是(src[j]=a)->b(也就是src[j]=a,a.next=b,b.next=null),经过while处理后得到了(newTable[i]=b)->a。也就是说,把链表的next关系反向了。
再看看这个while中可能在多线程情况下引起问题的语句。针对两个线程t1和t2,这里它们可能的产生问题的执行序列做些个人分析:
1)假设同一个Entry列表[e->f->...],t1先到,t2后到并都走到while中。t1执行“e.next = newTable[i];newTable[i] = e;”这使得e.next=null(初始的newTable[i]为null),newTable[i]指向了e。这时t2执行了“e.next = newTable[i];newTable[i] = e;”,这使得e.next=e,e死循环了。因为循环开始处的“final Entry next = e.next;”,尽管e自己死循环了,在最后的“e = next;”后,两个线程都会跳过e继续执行下去。
2)在while中逐个遍历Entry链表中的Entry而把next关系反向时,newTable[i]成为了被交换的引用,可疑的语句在于“e.next = newTable[i];”。假设链表e->f->g被t1处理成e<-f<-g,newTable[i]指向了g,这时t2进来了,它一执行“e.next = newTable[i];”就使得e->g,造成了死循环。所以,理论上来说,死循环的Entry个数可能很多。尽管产生了死循环,但是t1执行到了死循环的右边,所以是会继续执行下去的,而t2如果执行“final Entry next = e.next;”的next为null,则也会继续执行下去,否则就进入了死循环。
3)似乎情况会更复杂,因为即便线程跳出了死循环,它下一次做resize进入transfer时,有可能因为之前的死循环Entry链表而被hang住(似乎是一定会被hang住)。也有可能,在put检查Entry链表时(@标记1),因为Entry链表的死循环而被hang住。也似乎有可能,活着的线程和死循环的线程同时执行在while里后,两个线程都能活着出去。所以,可能两个线程平安退出,可能一个线程hang在transfer中,可能两个线程都被hang住而又不一定在一个地方。
4)我反复的测试,出现一个线程被hang住的情况最多,都是e=e.next.next造成的,这主要就是例子put两份增量数据造成的。我如果去掉@标记3的输出,有时也能复现两个线程都被hang住的情况,但加上后就很难复现出来。我又把put的数据改了下,比如让两个线程put范围不同的数据,就能复现出e=e.next,两个线程都被hang住的情况。
上面罗哩罗嗦了很多,一开始我简单的分析后觉得似乎明白了怎么回事,可现在仔细琢磨后似乎又不明白了许多。有一个细节是,每次死循环的key的大小也是有据可循的,我就不打哈了。感觉,如果样本多些,可能出现问题的原因点会很多,也会更复杂,我姑且不再蛋疼下去。至于有人提到ConcurrentHashMap也有这个问题,我觉得不大可能,因为它的put操作是加锁的,如果有这个问题就不叫线程安全的Map了。
转载于:https://www.cnblogs.com/pipijiqimao/archive/2012/12/02/2798494.html
集合类之番外篇:深入解析HashMap、HashTable相关推荐
- 【JAVA进阶】java中的集合(番外篇3)- HashMap源码底层数据结构分析
写在前面的话 脑子是个好东西,可惜的是一直没有搞懂脑子的内存删除机制是什么,所以啊,入行多年,零零散散的文章看了无数,却总是学习了很多也忘了很多. 痛定思痛的我决定从今天开始系统的梳理下知识架构,记录 ...
- 教你从0到1搭建秒杀系统-Canal快速入门(番外篇)
Canal用途很广,并且上手非常简单,小伙伴们在平时完成公司的需求时,很有可能会用到.本篇介绍一下数据库中间件Canal的使用. 很多时候为了缩短调用延时,我们会对部分接口数据加入了缓存.一旦这些数据 ...
- PostCSS自学笔记(二)【番外篇二】
图解PostCSS的插件执行顺序 文章其实是一系列的早就写完了. 才发现忘了发在SegmentFault上面, 最早发布于https://gitee.com/janking/Inf... 这次我继续研 ...
- Java番外篇2——jdk8新特性
Java番外篇2--jdk8新特性 1.Lambda 1.1.无参无返回值 public class Test {interface Print{void print();}public static ...
- 给深度学习入门者的Python快速教程 - 番外篇之Python-OpenCV
转载自:https://zhuanlan.zhihu.com/p/24425116 本篇是前面两篇教程:给深度学习入门者的Python快速教程 - 基础篇 给深度学习入门者的Python快速教程 - ...
- iOS冰与火之歌(番外篇) - 基于PEGASUS(Trident三叉戟)的OS X 10.11.6本地提权
0x00 序 这段时间最火的漏洞当属阿联酋的人权活动人士被apt攻击所使用的iOS PEGASUS(又称Trident三叉戟)0day漏洞了.为了修复该漏洞,苹果专门发布了一个iOS 9.3.5版本. ...
- 神经网络学习小记录-番外篇——常见问题汇总
神经网络学习小记录-番外篇--常见问题汇总 前言 问题汇总 1.下载问题 a.代码下载 b. 权值下载 c. 数据集下载 2.环境配置问题 a.20系列所用的环境 b.30系列显卡环境配置 c.CPU ...
- CyberController手机外挂番外篇:源代码的二次修改
文章目录 前言 调试过程中的疑问 为什么一段时间不使用CyberController,翻译就无法触发了? 为什么连接成功了,但却依然无法进行语音识别和翻译? 多长时间TCP连接就会挂掉 连接正常与断开 ...
- 一起实践量化番外篇——TensorRT-8的量化细节
好久不见各位~ 这篇文章很久之前写完一直没有整理,最近终于是整理差不多了,赶紧发出来. 本文接着<必看部署系列-神经网络量化教程:第一讲!>这一篇接着来说.上一篇主要说了量化的一些基本知识 ...
最新文章
- html5 FileReader初识
- 模型蒸馏(Distillation)
- SAP S4HANA如何取到采购订单ITEM里的'条件'选项卡里的条件类型值?
- 透视表提取不反复记录(3)-每组最小值
- Crawler:利用Beautifulsoup库+find_all方法实现下载在线书架小说《星祖的电影世界》
- svm通俗易懂的理解
- 使用alertmanager对监控对象进行报警(微信)三
- 电子徽章:融创意、疯狂与电子设计中
- python绘制饼图双层_有趣!如何用Python-matplotlib绘制双层饼图及环形图?
- 设计模式のStrategyPattern(策略模式)----行为模式
- LeetCode【3--无重复的最长字串】 LeetCode【4--有序数组中的中位数】
- 验证客户端和服务端可以传输经SM4加密的密文数据,从而验证发送数据已使用服务器密码机进行SM4加密,而不是随便的字符串乱码
- ceiling和floor转化
- [转载]高性能托管应用程序设计入门
- 【bzoj 4675】 点对游戏
- [投稿]一个频域语音降噪算法实现及改进方法
- 基于STM32的DS1302时钟模块驱动程序
- 基于matlab的红外图像处理算法研究,基于小波的红外图像去噪算法研究
- Qt面对高分辨率屏幕的解决方法思考
- java使用RabbitMQ,学习了解
热门文章
- java openresty 调用_Openresty使用zlib解压缩response body
- 知识图谱组队学习Task05——图数据库查询
- 手把手教你搭建pytorch深度学习网络
- php5.2 sqlserver2000,Linux系统下让PHP连sqlserver2000
- mysql 5.5.29 winx64_【转载】MySQL 5.7.29详细下载安装配置教程winx64
- java for mat,在Java绑定中通过OpenCV Mat进行循环
- Linux IO控制命令生成
- 安装配置oracle11gR2、client、plsql developer及学习
- 【转】成为一名推荐系统工程师永远都不晚
- 【Redis】redis cluster 添加 删除 重分配 节点