python数据分析最基本的库_Python数据分析库pandas基本操作方法_python
下面就为大家分享一篇Python数据分析库pandas基本操作方法,具有很好的参考价值,希望对大家有所帮助。一起过来看看吧
pandas是什么?

是它吗?
。。。。很显然pandas没有这个家伙那么可爱。。。。
我们来看看pandas的官网是怎么来定义自己的:
pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language.
很显然,pandas是python的一个非常强大的数据分析库!
让我们来学习一下它吧!
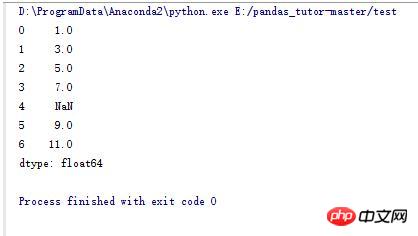
1.pandas序列
import numpy as np
import pandas as pd
s_data = pd.Series([1,3,5,7,np.NaN,9,11])#pandas中生产序列的函数,类似于我们平时说的数组
print s_data
2.pandas数据结构DataFrame
import numpy as np
import pandas as pd
#以20170220为基点向后生产时间点
dates = pd.date_range('20170220',periods=6)
#DataFrame生成函数,行索引为时间点,列索引为ABCD
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print data.shape
print data.values

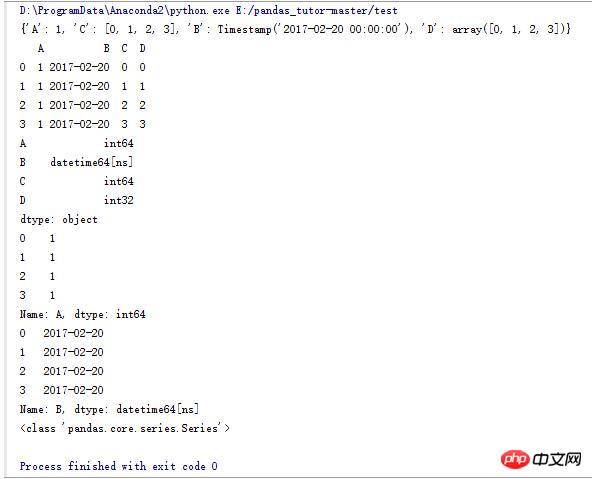
3.DataFrame的一些操作(1)
import numpy as np
import pandas as pd
#设计一个字典
d_data = {'A':1,'B':pd.Timestamp('20170220'),'C':range(4),'D':np.arange(4)}
print d_data
#使用字典生成一个DataFrame
df_data = pd.DataFrame(d_data)
print df_data
#DataFrame中每一列的类型
print df_data.dtypes
#打印A列
print df_data.A
#打印B列
print df_data.B
#B列的类型
print type(df_data.B)
4.DataFrame的一些操作(2)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#输出DataFrame头部数据,默认为前5行
print data.head()
#输出输出DataFrame第一行数据
print data.head(1)
#输出DataFrame尾部数据,默认为后5行
print data.tail()
#输出输出DataFrame最后一行数据
print data.tail(1)
#输出行索引
print data.index
#输出列索引
print data.columns
#输出DataFrame数据值
print data.values
#输出DataFrame详细信息
print data.describe()

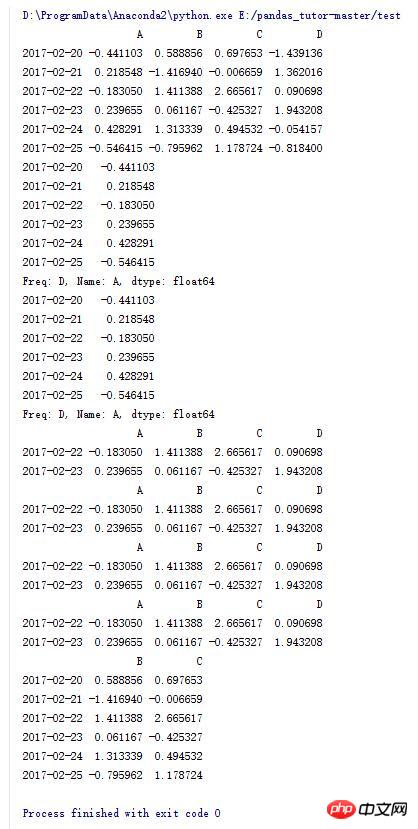
5.DataFrame的一些操作(3)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#转置
print data.T
#输出维度信息
print data.shape
#转置后的维度信息
print data.T.shape
#将列索引排序
print data.sort_index(axis = 1)
#将列索引排序,降序排列
print data.sort_index(axis = 1,ascending=False)
#将行索引排序,降序排列
print data.sort_index(axis = 0,ascending=False)
#按照A列的值进行升序排列
print data.sort_values(by='A')

6.DataFrame的一些操作(4)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#输出A列
print data.A
#输出A列
print data['A']
#输出3,4行
print data[2:4]
#输出3,4行
print data['20170222':'20170223']
#输出3,4行
print data.loc['20170222':'20170223']
#输出3,4行
print data.iloc[2:4]
输出B,C两列
print data.loc[:,['B','C']]
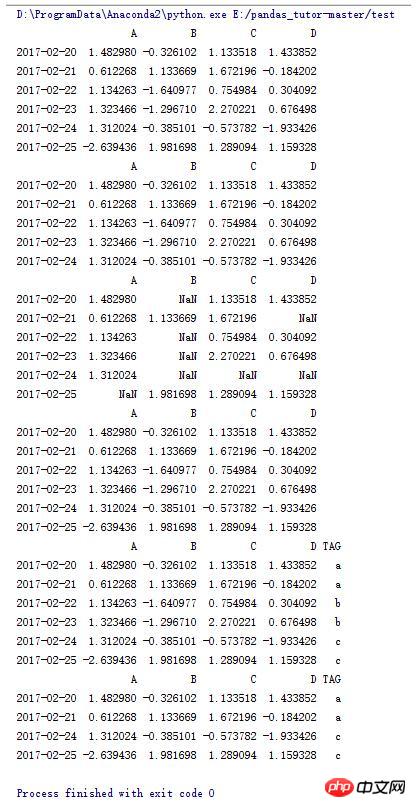
7.DataFrame的一些操作(5)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#输出A列中大于0的行
print data[data.A > 0]
#输出大于0的数据,小于等于0的用NaN补位
print data[data > 0]
#拷贝data
data2 = data.copy()
print data2
tag = ['a'] * 2 + ['b'] * 2 + ['c'] * 2
#在data2中增加TAG列用tag赋值
data2['TAG'] = tag
print data2
#打印TAG列中为a,c的行
print data2[data2.TAG.isin(['a','c'])]
8.DataFrame的一些操作(6)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#将第一行第一列元素赋值为100
data.iat[0,0] = 100
print data
#将A列元素用range(6)赋值
data.A = range(6)
print data
#将B列元素赋值为200
data.B = 200
print data
#将3,4列元素赋值为1000
data.iloc[:,2:5] = 1000
print data

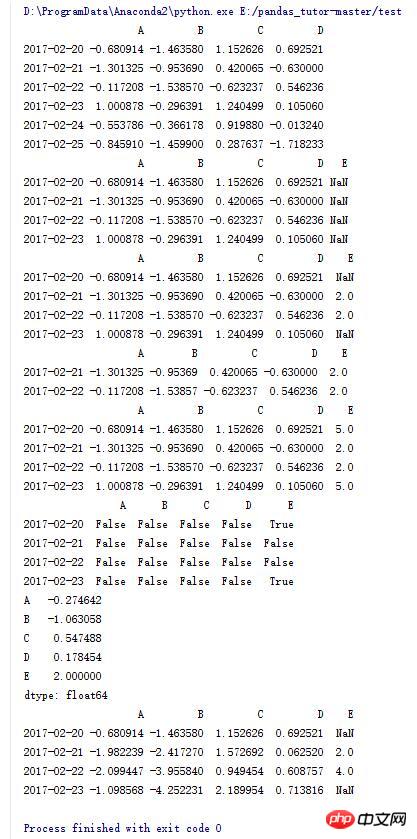
9.DataFrame的一些操作(7)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
#重定义索引,并添加E列
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
#将E列中的2,3行赋值为2
dfl.loc[dates[1:3],'E'] = 2
print dfl
#去掉存在NaN元素的行
print dfl.dropna()
#将NaN元素赋值为5
print dfl.fillna(5)
#判断每个元素是否为NaN
print pd.isnull(dfl)
#求列平均值
print dfl.mean()
#对每列进行累加
print dfl.cumsum()
10.DataFrame的一些操作(8)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
#针对行求平均值
print dfl.mean(axis=1)
#生成序列并向右平移两位
s = pd.Series([1,3,5,np.nan,6,8],index = dates).shift(2)
print s
#df与s做减法运算
print df.sub(s,axis = 'index')
#每列进行累加运算
print df.apply(np.cumsum)
#每列的最大值减去最小值
print df.apply(lambda x: x.max() - x.min())

11.DataFrame的一些操作(9)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
#定义一个函数
def _sum(x):
print(type(x))
return x.sum()
#apply函数可以接受一个函数作为参数
print df.apply(_sum)
s = pd.Series(np.random.randint(10,20,size = 15))
print s
#统计序列中每个元素出现的次数
print s.value_counts()
#返回出现次数最多的元素
print s.mode()

12.DataFrame的一些操作(10)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
print df
#合并函数
dfl = pd.concat([df.iloc[:3],df.iloc[3:7],df.iloc[7:]])
print dfl
#判断两个DataFrame中元素是否相等
print df == dfl

13.DataFrame的一些操作(11)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
print df
left = pd.DataFrame({'key':['foo','foo'],'lval':[1,2]})
right = pd.DataFrame({'key':['foo','foo'],'rval':[4,5]})
print left
print right
#通过key来合并数据
print pd.merge(left,right,on='key')
s = pd.Series(np.random.randint(1,5,size = 4),index = list('ABCD'))
print s
#通过序列添加一行
print df.append(s,ignore_index = True)

14.DataFrame的一些操作(12)
import numpy as np
import pandas as pd
df = pd.DataFrame({'A': ['foo','bar','foo','bar',
'foo','bar','foo','bar'],
'B': ['one','one','two','three',
'two','two','one','three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})
print df
#根据A列的索引求和
print df.groupby('A').sum()
#先根据A列的索引,在根据B列的索引求和
print df.groupby(['A','B']).sum()
#先根据B列的索引,在根据A列的索引求和
print df.groupby(['B','A']).sum()

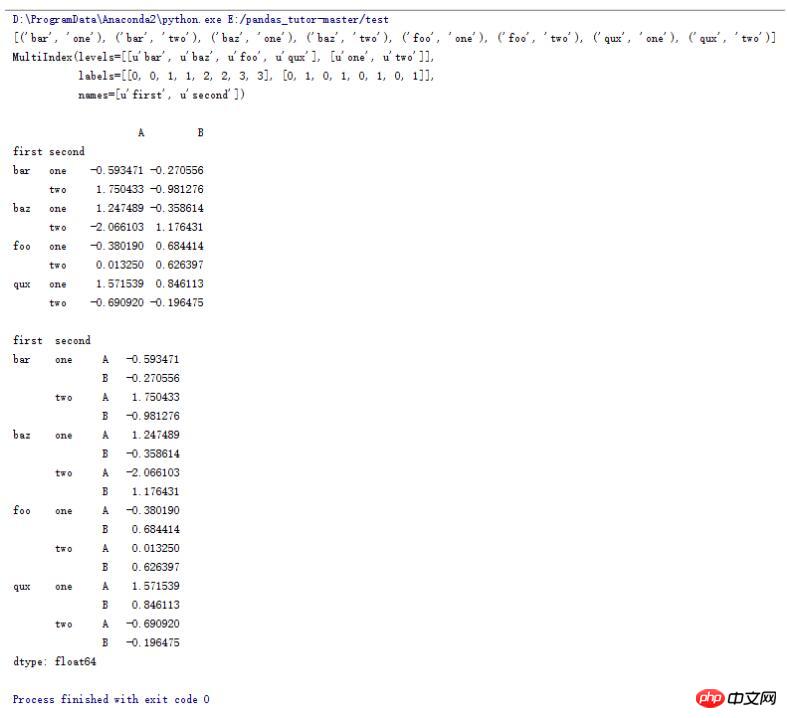
15.DataFrame的一些操作(13)
import pandas as pd
import numpy as np
#zip函数可以打包成一个个tuple
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
print tuples
#生成一个多层索引
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
print index
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
print df
#将列索引变成行索引
print df.stack()
16.DataFrame的一些操作(14)
import pandas as pd
import numpy as np
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
print df
stacked = df.stack()
print stacked
#将行索引转换为列索引
print stacked.unstack()
#转换两次
print stacked.unstack().unstack()

17.DataFrame的一些操作(15)
import pandas as pd
import numpy as np
df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3,
'B' : ['A', 'B', 'C'] * 4,
'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D' : np.random.randn(12),
'E' : np.random.randn(12)})
print df
#根据A,B索引为行,C的索引为列处理D的值
print pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
#感觉A列等于one为索引,根据C列组合的平均值
print df[df.A=='one'].groupby('C').mean()

18.时间序列(1)
import pandas as pd
import numpy as np
#创建一个以20170220为基准的以秒为单位的向前推进600个的时间序列
rng = pd.date_range('20170220', periods=600, freq='s')
print rng
#以时间序列为索引的序列
print pd.Series(np.random.randint(0, 500, len(rng)), index=rng)

19.时间序列(2)
import pandas as pd
import numpy as np
rng = pd.date_range('20170220', periods=600, freq='s')
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
#重采样,以2分钟为单位进行加和采样
print ts.resample('2Min', how='sum')
#列出2011年1季度到2017年1季度
rng1 = pd.period_range('2011Q1','2017Q1',freq='Q')
print rng1
#转换成时间戳形式
print rng1.to_timestamp()
#时间加减法
print pd.Timestamp('20170220') - pd.Timestamp('20170112')
print pd.Timestamp('20170220') + pd.Timedelta(days=12)

20.数据类别
import pandas as pd
import numpy as np
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})
print df
#添加类别数据,以raw_grade的值为类别基础
df["grade"] = df["raw_grade"].astype("category")
print df
#打印类别
print df["grade"].cat.categories
#更改类别
df["grade"].cat.categories = ["very good", "good", "very bad"]
print df
#根据grade的值排序
print df.sort_values(by='grade', ascending=True)
#根据grade排序显示数量
print df.groupby("grade").size()

21.数据可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ts = pd.Series(np.random.randn(1000), index=pd.date_range('20170220', periods=1000))
ts = ts.cumsum()
print ts
ts.plot()
plt.show()

22.数据读写
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD'))
#数据保存,相对路径
df.to_csv('data.csv')
#数据读取
print pd.read_csv('data.csv', index_col=0)

数据被保存到这个文件中:

打开看看:

相关推荐:
以上就是Python数据分析库pandas基本操作方法_python的详细内容,更多请关注php中文网其它相关文章!

本文原创发布php中文网,转载请注明出处,感谢您的尊重!
python数据分析最基本的库_Python数据分析库pandas基本操作方法_python相关推荐
- python 热力图_python数据分析:数据缺失机制及利用missingno库对缺失可视化
缺失数据是一个非常普遍的问题,也是好多人不太能弄懂的问题,包括自己也是,为了加强理解,今天给大家写一写缺失数据的缺失机制,和在python中用missingno库对缺失数据可视化的操作方法. 数据缺失 ...
- python对二维数组统计某一行的去重计数_Python数据分析笔记——Numpy、Pandas库
利用Python进行数据分析中有两个重要的库是Numpy和Pandas,本章将围绕这两个库进行展开介绍. Numpy库 Numpy最重要的一个特点是就是其N维数组对象,即ndarray,ndarray ...
- python数据分析基础 阮敬_Python数据分析用到的几个重要的库
NumPy NumPy(Numerical Python的简称)是Python科学计算的基础包.它提供了以下功能(不限于此):快速高效的多维数组对象ndarray. 用于对数组执行元素级计算以及直接对 ...
- python 数据分析 库_Python数据分析库
python 数据分析 库 什么是数据分析? (What is Data Analytics?) Data is power. Insights acquired from data is the k ...
- python数据分析用什么库_Python数据分析常用的库总结
Python之所以能够成为数据分析与挖掘领域的最佳语言,是有其独特的优势的.因为他有很多这个领域相关的库可以用,而且很好用,比如Numpy.SciPy.Matploglib.Pandas.Scikit ...
- python数据分析方向的第三方库是_python数据分析方向的第三方库是什么
python数据分析方向的第三方库是:1.Numpy:2.Pandas:3.SciPy:4.Matplotlib:5.Scikit-Learn:6.Keras:7.Gensim:8.Scrapy. 本 ...
- python统计小说人物_Python数据分析之基情的择天记
人一生都可能无法逆天改命,但你却是要去奋斗一把 本文章主要通过最简单的共线性关系,利用gephi工具绘制择天记的人物关系图. 准备工作在网上下载<择天记>小说以及创建小说人物的txt. j ...
- python结课报告_Python数据分析课程到底是学什么内容的?
2020年12月4日,博为峰旗下学掌门召开了<Python 商业(大)数据分析师>新课程发布会.据悉,此次发布会上发布的<Python 商业(大)数据分析师>课程是在原< ...
- python数据分析软件_Python数据分析工具
Numpy Python没有提供数组功能,虽然列表可以完成基本的数组功能,但他不是真正的数组.Numpy内置函数处理速度是c语言级别,因此尽量使用内置函数,避免出现效率瓶颈的现象. Numpy的安装: ...
最新文章
- 从 Blast2GO 本地化聊一聊 Linux 下 MySQL 的源码安装
- 使用C#检验.NET FrameWork版本
- Cracking the coding interview--Q1.2
- linux 链接ln的使用 创建和删除符号连接(软、硬链接)
- ECCV 2020《Linguistic Structure Guided Context Modeling for Referring Image Segmentation》论文笔记
- 个人作业——软件工程实践总结
- mac idea在mybatis xml文件里引入全限定类名报红解决
- 禁止选择文字和文本超出显示省略号
- tone mapping简介
- 第四章 Linux命令
- 蓝桥杯 ALGO-115 算法训练 和为T
- vue项目实现文字转换成语音播放功能
- 图的深度优先遍历和广度优先遍历算法流程图
- stephen boyd著王书宁译凸优化课后题答案
- 关于UE4坐标换算涉及到的知识
- DBG、DMB、DSB 和 ISB
- 如何自己制作小程序?
- PYTHON 画一支圆珠笔
- 正在连接localhost...无法打开到主机的连接。 在port 8080: 连接失败
- [MATLAB][转载]MATLAB2018b的VS2017编译器配置