LSTM文本预测分析python
本文只介绍学习LSTM,循环神经网络参考:深度学习之RNN(循环神经网络)_笨拙的石头的博客-CSDN博客_rnn了解。
循环神经网络简单结构如下:
![]()
由于RNN的结构限制,输入为x(t)和上一时刻的h(t-1),输出为y。如 ,
, 。但由于每次运算都用到U,V,W权重,而这三个值是一直不变的,这就导致RNN运算中经常产生梯度爆炸等问题。如若权重值W,经过时间的循环,到达t时刻时,权重W一直相乘,数值越来越小,导致有用信息可能会丢失。因此就有了改进RNN,引出了LSTM。
。但由于每次运算都用到U,V,W权重,而这三个值是一直不变的,这就导致RNN运算中经常产生梯度爆炸等问题。如若权重值W,经过时间的循环,到达t时刻时,权重W一直相乘,数值越来越小,导致有用信息可能会丢失。因此就有了改进RNN,引出了LSTM。
简介:
LSTM也就是长短期记忆网络,此算法在解决梯度消失问题时,由于存在记忆功能,对以前梯度较大的部分不会立马就忘记,在一定程度上可以克服梯度消失问题;而对于梯度爆炸问题,当你计算的梯度超过阈值c或者小于阈值-c的时候,便把此时的梯度设置成c或-c。
LSTM结构图如下:
除输入外包含三个部分,遗忘门,记忆门,输出门。
遗忘门:
![]()
上图便是遗忘门,包含了一个sigmoid神经网络层,神经网络参数为和
,接收t时刻的输入信号
和 t-1 时刻LSTM的上一个输出信号,将这两个信号进行拼接以后共同输入到神经网络层中,然后输出信号
。而图中的
的维度则决定了
的维度。
注意:其中sigmoid是神经网络层,而不是激活函数sigmoid。
记忆门:记忆门的作用与遗忘门相反,它将决定新输入的信息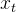 和
和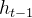 中哪些信息将被保留。
中哪些信息将被保留。
![]()
记忆门包含2个部分。第一个是包含sigmoid神经网络层,神经网络网络参数为和
;另外一个是 tanh神经网络层,神经网络参数为
和
。tanh层也一样不是激活函数。
输出门:用来最后输出。
![]()
输出门就是将t-1时刻的和
传递过来,经过一个sigmoid神经网络层,并把经过了前面遗忘门与记忆门选择后的细胞状态
,经过一个tanh函数,并非tanh神经网络层,整合到一起作为当前时刻的输出信号
。
简单python案例:
1.导入所需要的库
from pandas import read_csv
from pandas import datetime
from pandas import concat
from pandas import DataFrame
from pandas import Series
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from math import sqrt
from matplotlib import pyplot
import numpy2.转换成差分数据:就是相邻的两个数相减,求得两个数之间的差,一两个数之间的差作为一个数组,这样的数组体现了相邻两个数的变化情况,获得差分序列,更好预测。
def difference(dataset, interval=1):diff = list()for i in range(interval, len(dataset)):value = dataset[i] - dataset[i - interval]diff.append(value)return Series(diff)其中Series能把一个数组建立起一个一一对应的索引,方便预测。
3.定义数据转换监督数据:将数据转换成有监督数据,即包含输入和输出,训练的目的就是找到训练数据输入和输出的关系,具体就是将整体的时间数据向后滑动一格,和原始数据拼接,就是有监督的数据。
def timeseries_to_supervised(data, lag=1):df = DataFrame(data)columns = [df.shift(i) for i in range(1, lag + 1)] # 数据滑动一格,作为input,df原数据为outputcolumns.append(df)df = concat(columns, axis=1)df.fillna(0, inplace=True)return df4.缩放:把数据缩放到[-1,1]之间,能够更适合预测。
def scale(train, test):# 根据训练数据建立缩放器scaler = MinMaxScaler(feature_range=(-1, 1))scaler = scaler.fit(train)# 转换train datatrain = train.reshape(train.shape[0], train.shape[1])train_scaled = scaler.transform(train)# 转换test datatest = test.reshape(test.shape[0], test.shape[1])test_scaled = scaler.transform(test)return scaler, train_scaled, test_scaled5.定义LSTM网络:采用Adam算法优化
def fit_lstm(train, batch_size, nb_epoch, neurons):X, y = train[:, 0:-1], train[:, -1]X = X.reshape(X.shape[0], 1, X.shape[1])model = Sequential()# 添加LSTM层model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))model.add(Dense(1)) # 输出层1个node# 编译,损失函数mse+优化算法adammodel.compile(loss='mean_squared_error', optimizer='adam')for i in range(nb_epoch):# 按照batch_size,一次读取batch_size个数据model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)model.reset_states()print("当前计算次数:"+str(i))return model6.定义训练预测步长:预测步长不仅影响着迭代时间,也影响着预测效果,自行调节。
def forcast_lstm(model, batch_size, X):X = X.reshape(1, 1, len(X))yhat = model.predict(X, batch_size=batch_size)return yhat[0, 0]7.进行预测值还原:逆缩放,逆差分。
# 逆缩放
def invert_scale(scaler, X, value):new_row = [x for x in X] + [value]array = numpy.array(new_row)array = array.reshape(1, len(array))inverted = scaler.inverse_transform(array)return inverted[0, -1]# 逆差分
def inverse_difference(history, yhat, interval=1): return yhat + history[-interval]8.主程序预测:
# 加载数据
series = read_csv('E:/bear3/3_3v_tezheng/liutezheng/pca.csv', header=None, index_col=0, squeeze=True)# 让数据变成稳定的
raw_values = series.values
diff_values = difference(raw_values, 1) # 转换成差分数据# 把稳定的数据变成有监督数据
supervised = timeseries_to_supervised(diff_values, 1)
supervised_values = supervised.values# 数据拆分:训练数据、测试数据,前650行是训练集,后435行是测试集
train, test = supervised_values[0:650], supervised_values[650:]# 数据缩放
scaler, train_scaled, test_scaled = scale(train, test)# 训练模型,定义参数
lstm_model = fit_lstm(train_scaled, 1, 50, 4)
# 预测
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1) # 训练数据集转换为可输入的矩阵
lstm_model.predict(train_reshaped, batch_size=1) # 用模型对训练数据矩阵进行预测# 训练次数足够多的时候才会体现出来训练结果
predictions = list()
P = []
E = []
for i in range(len(test_scaled)): # 根据测试数据进行预测,取测试数据的一个数值作为输入,计算出下一个预测值,以此类推# 1步长预测X, y = test_scaled[i, 0:-1], test_scaled[i, -1]yhat = forcast_lstm(lstm_model, 1, X)# 逆缩放yhat = invert_scale(scaler, X, yhat)# 逆差分yhat = inverse_difference(raw_values, yhat, len(test_scaled) + 1 - i)predictions.append(yhat)expected = raw_values[len(train) + i + 1]P.append(yhat)E.append(expected)print('Moth=%d, Predicted=%f, Expected=%f' % (i + 1, yhat, expected))
numpy.savetxt('E:/LSTM/3_3p_pca.txt', P)
numpy.savetxt('E:/LSTM/3_3y_pca.txt', E)# 性能报告
rmse = sqrt(mean_squared_error(raw_values[651:1085], predictions))
print('Test RMSE:%.3f' % rmse)
r2 = r2_score(raw_values[651:1085], predictions)
print('Test R2:%.3f' % r2)y_data = read_csv('E:/LSTM/3_3y_pca.txt', header=None)
y_predict = read_csv('E:/LSTM/3_3p_pca.txt', header=None)
yy = numpy.sum(y_data)/(len(y_data))
R2 = 1-(numpy.sum((y_data-y_predict)**2))/(numpy.sum((yy-y_data)**2))
print(R2)# 绘图
pyplot.plot(raw_values[651:1085])
pyplot.plot(predictions)
pyplot.show()Test RMSE:0.055
Test R2:0.878
![]()
总体上来说,预测效果还算可以,还是没有优化参数的情况下。
LSTM文本预测分析python相关推荐
- 中文文本情感分析-python包SnowNLP入门
目录 1.情感分析是什么? 2.情感分析有什么用? 3.情感分析实战-SnowNLP SnowNLP官方参考资料: SnowNLP两个坑: 自己用snownlp训练模型: 1.情感分析是什么? 极性: ...
- 【毕业设计】LSTM股票预测系统 - python 深度学习
文章目录 0 前言 1 课题意义 1.1 股票预测主流方法 2 什么是LSTM 2.1 循环神经网络 2.1 LSTM诞生 3 如何用LSTM做股票预测 3.1 算法构建流程 3.2 部分代码 4 实 ...
- 预测分析 Python ARIMA模型预测(学习笔记)
import numpy as np import pandas as pd import matplotlib.pyplot as plt import statsmodels.api as sm# ...
- [深度学习]-基于tensorflow的CNN和RNN-LSTM文本情感分析对比
基于tensorflow的CNN和LSTM文本情感分析对比 1. 背景介绍 2. 数据集介绍 2.0 wordsList.npy 2.1 wordVectors.npy 2.2 idsMatrix.n ...
- R语言对推特twitter数据进行文本情感分析
原文链接:http://tecdat.cn/?p=4012 我们以R语言抓取的推特数据为例,对数据进行文本挖掘,进一步进行情感分析,从而得到很多有趣的信息(点击文末"阅读原文"获取 ...
- python程序写诗_万能的 LSTM:可以写代码可以写诗还能做文本情感分析
LSTM,全称为「长短期记忆」,是一种「时间递归神经网络」(RNN).LSTM 适合于处理和预测时间序列中间隔和延迟非常长的重要事件. 通俗来讲,LSTM 非常适合用来预测与时间相关的数据,在文本处理 ...
- 【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析|数据分享...
全文下载链接:http://tecdat.cn/?p=23544 在本文中,长短期记忆网络--通常称为"LSTM"--是一种特殊的RNN递归神经网络,能够学习长期依赖关系(点击文末 ...
- Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
原文链接:http://tecdat.cn/?p=23544 下面是一个关于如何使用长短期记忆网络(LSTM)来拟合一个不平稳的时间序列的例子. 每年的降雨量数据可能是相当不平稳的.与温度不同,温度 ...
- python短期预测图_Python中利用长短期记忆模型LSTM进行时间序列预测分析
原文链接:http://tecdat.cn/?p=6663 此示例中,神经网络用于使用2011年4月至2013年2月期间的数据预测都柏林市议会公民办公室的能源消耗. 每日数据是通过总计每天提供的15分 ...
最新文章
- c语言日期星期程序,C语言程序设计: 输入年月日 然后输出是星期几
- CVPR 2020 Oral 文章汇总,包括论文解读与代码实现
- mongodb 3.4单实例安装与备
- 埃夫特机器人回零偏差太大_新松、华中数控、埃斯顿、埃夫特国内主流机器人厂商近年最新动态...
- python功能代码_整理几个常用的Python功能代码片段【收藏】
- java byte 二维数组_[编程入门]二维数组的转置-题解(Java代码)
- 34营销的三要素:真实诚信、诱饵引入、合理宣传
- LTE网络测试仪器和监控系统
- 机器学习中的范数规则化之L0、L1、L2范数
- ASP.NET前台html页面AJAX提交数据后台ashx页面接收数据
- STM32固件库下载步骤
- 【Visual C++】游戏开发笔记二十六 DirectX 11各组件的介绍第一个DirectX 11 Demo的创建
- 系统工程利用python求解可达矩阵
- t分布(Student t distribution)——正态分布的小样本抽样分布
- 数字方法--按零补位
- Android开发技术学习之下拉刷新功能的实现
- c++中的有符号数与无符号数一起运算
- 跟领导汇报工作时,这句话建议你不要说
- Halcon DrawRegion()后会阻塞直到右键按下,请问如何主动取消绘制区域
- 做相关性分析时,如何排除奇异值Outliers,以增加相关分析的准确性