pyspider 爬虫教程
pyspider 爬虫教程(一):HTML 和 CSS 选择器
虽然以前写过 如何抓取WEB页面 和 如何从 WEB 页面中提取信息。但是感觉还是需要一篇 step by step 的教程,不然没有一个总体的认识。不过,没想到这个教程居然会变成一篇译文,在这个爬虫教程系列文章中,会以实际的例子,由浅入深讨论爬取(抓取和解析)的一些关键问题。
在 教程一 中,我们将要爬取的网站是豆瓣电影:http://movie.douban.com/
你可以在: http://demo.pyspider.org/debug/tutorial_douban_movie 获得完整的代码,和进行测试。
开始之前
由于教程是基于 pyspider 的,你可以安装一个 pyspider(Quickstart,也可以直接使用 pyspider 的 demo 环境:http://demo.pyspider.org/。
你还应该至少对万维网是什么有一个简单的认识:
- 万维网是一个由许多互相链接的超文本页面(以下简称网页)组成的系统。
- 网页使用网址(URL)定位,并链接彼此
- 网页使用 HTTP 协议传输
- 网页使用 HTML 描述外观和语义
所以,爬网页实际上就是:
- 找到包含我们需要的信息的网址(URL)列表
- 通过 HTTP 协议把页面下载回来
- 从页面的 HTML 中解析出需要的信息
- 找到更多这个的 URL,回到 2 继续
选取一个开始网址
既然我们要爬所有的电影,首先我们需要抓一个电影列表,一个好的列表应该:
- 包含足够多的电影的 URL
- 通过翻页,可以遍历到所有的电影
- 一个按照更新时间排序的列表,可以更快抓到最新更新的电影
我们在 http://movie.douban.com/ 扫了一遍,发现并没有一个列表能包含所有电影,只能退而求其次,通过抓取分类下的所有的标签列表页,来遍历所有的电影: http://movie.douban.com/tag/
创建一个项目
在 pyspider 的 dashboard 的右下角,点击 “Create” 按钮
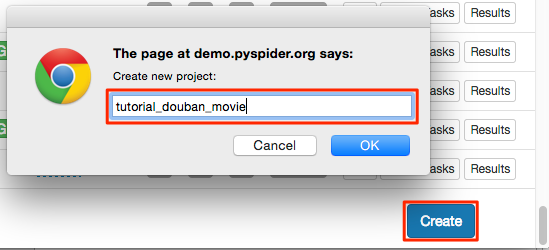
替换 on_start 函数的 self.crawl 的 URL:
|
1
2
3
|
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)
|
self.crawl告诉 pyspider 抓取指定页面,然后使用callback函数对结果进行解析。@every) 修饰器,表示on_start每天会执行一次,这样就能抓到最新的电影了。
点击绿色的 run 执行,你会看到 follows 上面有一个红色的 1,切换到 follows 面板,点击绿色的播放按钮:
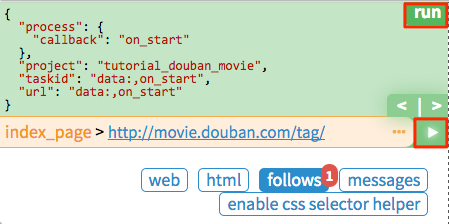
Tag 列表页
在 tag 列表页 中,我们需要提取出所有的 电影列表页 的 URL。你可能已经发现了,sample handler 已经提取了非常多大的 URL,所有,一种可行的提取列表页 URL 的方法就是用正则从中过滤出来:
|
1
2
3
4
5
6
7
8
|
import re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
|
- 由于 电影列表页和 tag列表页长的并不一样,在这里新建了一个
callback为self.list_page@config(age=10 * 24 * 60 * 60)在这表示我们认为 10 天内页面有效,不会再次进行更新抓取
由于 pyspider 是纯 Python 环境,你可以使用 Python 强大的内置库,或者你熟悉的第三方库对页面进行解析。不过更推荐使用 CSS选择器。
电影列表页
再次点击 run 让我们进入一个电影列表页(list_page)。在这个页面中我们需要提取:
- 电影的链接,例如,http://movie.douban.com/subject/1292052/
- 下一页的链接,用来翻页
CSS选择器
CSS选择器,顾名思义,是 CSS 用来定位需要设置样式的元素 所使用的表达式。既然前端程序员都使用 CSS选择器 为页面上的不同元素设置样式,我们也可以通过它定位需要的元素。你可以在 CSS 选择器参考手册 这里学习更多的 CSS选择器 语法。
在 pyspider 中,内置了 response.doc 的 PyQuery 对象,让你可以使用类似 jQuery 的语法操作 DOM 元素。你可以在 PyQuery的页面上找到完整的文档。
CSS Selector Helper
在 pyspider 中,还内置了一个 CSS Selector Helper,当你点击页面上的元素的时候,可以帮你生成它的 CSS选择器 表达式。你可以点击 Enable CSS selector helper 按钮,然后切换到 web 页面:
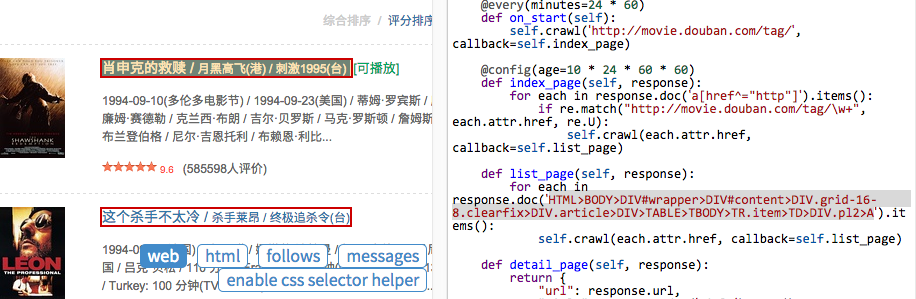
开启后,鼠标放在元素上,会被黄色高亮,点击后,所有拥有相同 CSS选择器 表达式的元素会被高亮。表达式会被插入到 python 代码当前光标位置。创建下面的代码,将光标停留在单引号中间:
|
1
2
|
def list_page(self, response):
for each in response.doc('').items():
|
点击一个电影的链接,CSS选择器 表达式将会插入到你的代码中,如此重复,插入翻页的链接:
|
1
2
3
4
5
6
|
def list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)
|
- 翻页是一个到自己的
callback回调
电影详情页
再次点击 run,follow 到详情页。使用 css selector helper 分别添加电影标题,打分和导演:
|
1
2
3
4
5
6
7
|
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
}
|
注意,你会发现 css selector helper 并不是总是能提取到合适的 CSS选择器 表达式。你可以在 Chrome Dev Tools 的帮助下,写一个合适的表达式:
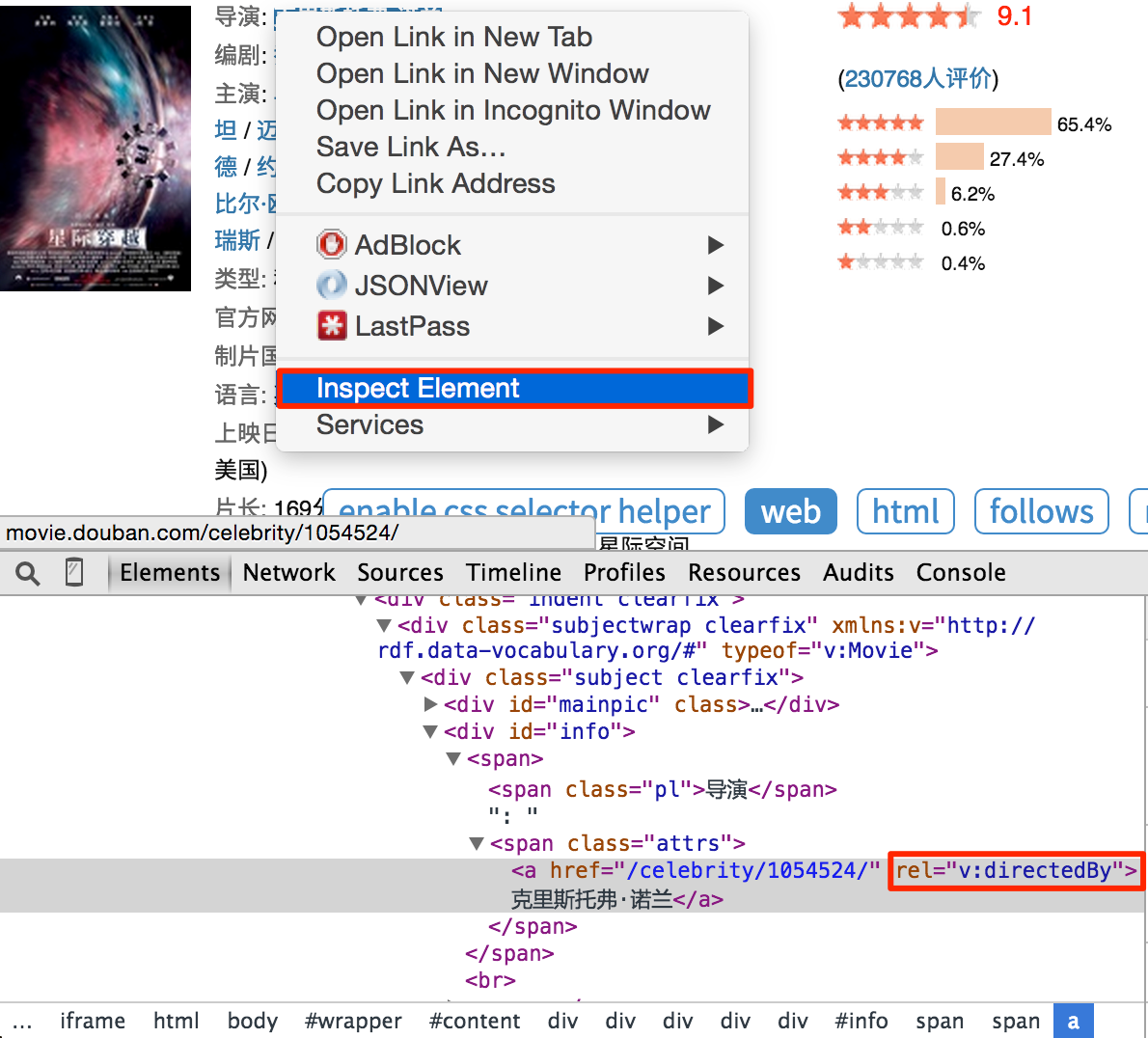
右键点击需要提取的元素,点击审查元素。你并不需要像自动生成的表达式那样写出所有的祖先节点,只要写出那些能区分你不需要的元素的关键节点的属性就可以了。不过这需要抓取和网页前端的经验。所以,学习抓取的最好方法就是学会这个页面/网站是怎么写的。
你也可以在 Chrome Dev Tools 的 Javascript Console 中,使用 $$(a[rel="v:directedBy"]) 测试 CSS Selector。
开始抓取
- 使用
run单步调试你的代码,对于用一个callback最好使用多个页面类型进行测试。然后保存。 - 回到 Dashboard,找到你的项目
- 将
status修改为DEBUG或RUNNING - 按
run按钮
pyspider 爬虫教程相关推荐
- Pyspider爬虫教程
Pyspider爬虫教程 https://www.cnblogs.com/ruqinzhe/p/7569985.html
- python爬虫scrapy框架教程_Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- python requests模块_Python 爬虫教程 requests 模块
经过 前边文章<简单Python爬虫教程 (一)>.简单Python爬虫教程 (二)两篇文章的学习,能写一些比较简单的爬虫了,但是还不够,这一篇文章主要介绍Requests模块,reque ...
- scrapy爬虫储存到mysql_详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
获取要爬取的URL 爬虫前期工作 用Pycharm打开项目开始写爬虫文件 字段文件items # Define here the models for your scraped items # # S ...
- python网络爬虫教程-教你从零开始学会写 Python 爬虫
原标题:教你从零开始学会写 Python 爬虫 写爬虫总是非常吸引IT学习者,毕竟光听起来就很酷炫极客,我也知道很多人学完基础知识之后,第一个项目开发就是自己写一个爬虫玩玩. 其实懂了之后,写个爬虫脚 ...
- python爬虫抓取图片-简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- python爬虫教程pdf-《Python爬虫开发与项目实战》pdf完整版
[实例简介] [实例截图] [核心代码] 目录 前言 基础篇 第1章 回顾Python编程2 1.1 安装Python2 1.1.1 Windows上安装Python2 1.1.2 Ubuntu上的P ...
- python 爬虫实例 电影-Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 爬虫python代码-Python爬虫教程:200行代码实现一个滑动验证码
Python爬虫教程:教你用200行代码实现一个滑动验证码 做网络爬虫的同学肯定见过各种各样的验证码,比较高级的有滑动.点选等样式,看起来好像挺复杂的,但实际上它们的核心原理还是还是很清晰的,本文章大 ...
最新文章
- Codeforces Round #361(div 2)
- git啊,你让我好费劲啊
- 元胞自动机交通流模型c++_MATLAB——含出入匝道的交织区快速路元胞自动机模型...
- 无向图 是什么 如何保存 如何搜索 求分组 求最短路径
- 芒格:如何面对投资中的巨大回撤?
- css文字覆盖线性渐变,利用css使文字渐变
- php计算时间差js,js 求时间差怎么求实例代码
- 样式穿透和实现固钉效果
- 4.0寸86盒显示屏调试(一)
- tracker使用_如何使用Tracker查找钥匙,钱包,电话或其他任何东西
- Github上的开源工具帮助你实现“十一”回家的愿望
- java security_java.security.NoSuchAlgorithmException
- count distinct
- 高性能计算(HPC)
- linux修复笔记本电池电量,我戴尔笔记本电池损耗到百分之三十了!怎么修好啊!晕...
- 没有实习经验,没有项目经验,简历怎么写?
- 客户关系应该如何管理?
- Echarts --- 可视化练习(pie01 --- 南丁格尔玫瑰图)
- 贾樟柯监制X水井坊呈现,微电影《以桌·会友》
- 无人机倾斜摄影测量技术的优势有哪些?