一、降维——机器学习笔记——降维(特征提取)
目录
一、为什么要降维
1、降维的分类
2、示例
二、第一部分,线性降维方法
1、【PCA】主成分分析
2、【LDA】判别分析
3、【MDS】多维尺度分析
三、第二部分,非线性降维方法
1、【流形学习】
2、【ISOMAP】等距特征映射
3、【LLE】局部线性嵌入
四、总结什么时候使用哪种降维技术
一、为什么要降维
维数灾难:在给定精度下,准确地对某些变量的函数进行估计,所需样本量会随着样本维数的增加而呈指数形式增长。
降维的意义:克服维数灾难,获取本质特征,节省存储空间,去除无用噪声,实现数据可视化
1、降维的分类
数据降维分为特征选择和特征提取两种方法,此文介绍的是特征提取方法,即经已有特征的某种变换获取约简特征。
- By only keeping the most relevant variables from the original dataset (this technique is called feature selection)
- By finding a smaller set of new variables, each being a combination of the input variables, containing basically the same information as the input variables (this technique is called dimensionality reduction)
2、示例
实例一:假如现在我们只有两个variables,为了了解这两者之间的关系,可以使用散点图将它们两者的关系画出:
那如果我们有100variables时,如果我们要看每个变量之间的关系,那需要100(100-1)/2 = 5000个图,而且把它们分开来看也没什么意义?
示例二:假如我们现在有两个意义相似的variables——Kg (X1) and Pound (X2),如果两个变量都使用会存在共线性,所以在这种情况下只使用一个变量就行。可以将二维数据降维一维
二、第一部分,线性降维方法
假设数据集采样来自高维空间的一个全局线性的子空间,即构成数据的各变量之间是独立无关的。
···通过特征的线性组合来降维
···本质上是把数据投影到低维线性子空间
···线性方法相对比较简单且容易计算
···适用于具有全局线性结构的数据集
1、【PCA】主成分分析
基本思想:构造原变量的一系列线性组合形成几个综合指标,以去除数据的相关性,并使低维数据最大程度保持原始高维数据的方差信息。
主成分个数的确定:
贡献率:第i个主成分的方差在全部方差中所占比重,反映第i个主成分所提取的总信息的份额。
累计贡献率:前k个主成分在全部方差中所占比重
主成分个数的确定:累计贡献率>0.85
相关系数矩阵or协方差阵?
当涉及变量的量纲不同或取值范围相差较大的指标时,应考虑从相关系数矩阵出发进行主成分分析;
对同度量或取值范围相差不大的数据,从协方差阵出发.
相关系数矩阵消除了量纲的影响。
---------R实现
princomp函数
princomp(x, cor = FALSE, scores = TRUE, ...)
cor 逻辑值,该值指示是否计算应使用相关矩阵(TRUE)或协方差 (FALSE)矩阵
scores 逻辑值,该值指示是否计算主成分得分
--------返回值
loadings 是一个矩阵,每列是一个特征向量,即原始特征的旋转系数
scores 所提供的数据在各个主成分上的得分
2、【LDA】判别分析
至多能把C类数据降维到C-1维子空间
---------R实现
library(MASS)
> params <- lda(y~x1+x2+x3, data=d)
##第一个参数是判别式的形式,第二个参数是用来训练的样本数据。lda命令执行后,会输出构成判别式的各个系数。
> predict(params, newdata)
##使用predict命令对未分类的样本进行判别。第一个参数是上一阶段lda命令的结果,第二个参数是用来分类的样本数据。自此,整个fisher判别过程完成。
3、【MDS】多维尺度分析
当 n 个研究对象之间的相似性(或距离)给定时,确定这些对象在低维空间中的表示,并使其尽可能与原先的相似性(或距离)“大体匹配”,使得由降维所引起的任何变形达到最小。
将研究对象在一个低维(二维或三维)的空间形象地表示出来(感知图),简单明了地说明各研究对象之间的相对关系。
-----------R示例
city<-read.csv('airline.csv',header=TRUE)
city1<-city[,-1]#这个数据集的第一列是名字,先把它去掉
for (i in 1:9)
for (j in (i+1):10)
city1[i,j]=city1[j,i] #把上三角部分补足
rownames(city1)<-colnames(city1) #再把行名加回来
city2<-as.dist(city1, diag = TRUE, upper = TRUE)#转换为dist类型
city3<-as.matrix(city2) #转化为矩阵
citys<-cmdscale(city3,k=2) #计算MDS,为可视化,取前两个主坐标
plot(citys[,1],citys[,2],type='n') #绘图
text(citys[,1],citys[,2],labels(city2),cex=.7) #标上城市名字
#看看图和真实的地图方向是反的,修改一下:
plot(-citys[,1],-citys[,2],type='n')
text(-citys[,1],-citys[,2],labels(city2),cex=.7)
三、第二部分,非线性降维方法
数据的各个属性间是强相关的
1、【流形学习】
流形是线性子空间的一种非线性推广,流形学习是一种非线性的维数约简方法
假设:高维数据位于或近似位于潜在的低维流行上
思想:保持高维数据与低维数据的某个“不变特征量”而找到低维特征表示
以不变特征量分为:
·····Isomap:测地距离
·····LLE:局部重构系数
·····LE:数据领域关系
2、【ISOMAP】等距特征映射
基本思想:通过保持高维数据的测地距离与低维数据的欧式距离的不变性来找到低维特征表示
测地距离:离得较近的点间的测地距离用欧氏距离代替;离得远的点间的测地距离用最短路径逼近
3、【LLE】局部线性嵌入
假设:采样数据所在的低维流形在局部是线性的,即每个采样点可以用它的近邻点线性表示
基本思想:通过保持高维数据与低维数据间的局部领域几何结构,局部重构系数来实现降维
四、总结什么时候使用哪种降维技术
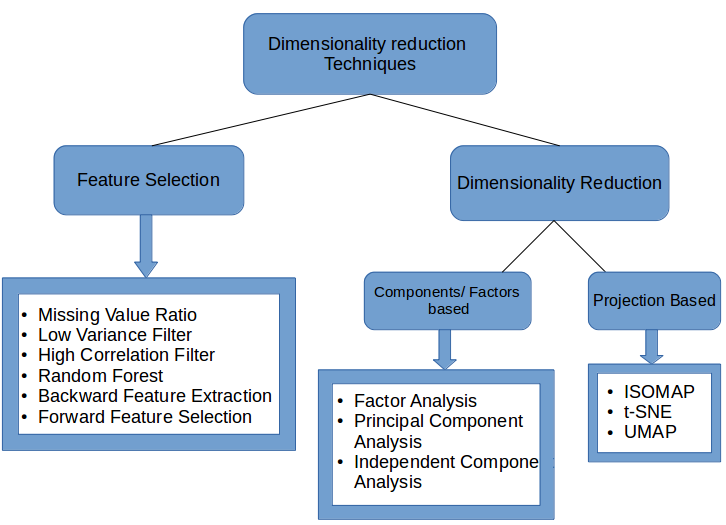
- Missing Value Ratio: If the dataset has too many missing values, we use this approach to reduce the number of variables. We can drop the variables having a large number of missing values in them
- Low Variance filter: We apply this approach to identify and drop constant variables from the dataset. The target variable is not unduly affected by variables with low variance, and hence these variables can be safely dropped
- High Correlation filter: A pair of variables having high correlation increases multicollinearity in the dataset. So, we can use this technique to find highly correlated features and drop them accordingly
- Random Forest: This is one of the most commonly used techniques which tells us the importance of each feature present in the dataset. We can find the importance of each feature and keep the top most features, resulting in dimensionality reduction
- Both Backward Feature Elimination and Forward Feature Selection techniques take a lot of computational time and are thus generally used on smaller datasets
- Factor Analysis: This technique is best suited for situations where we have highly correlated set of variables. It divides the variables based on their correlation into different groups, and represents each group with a factor
- Principal Component Analysis: This is one of the most widely used techniques for dealing with linear data. It divides the data into a set of components which try to explain as much variance as possible
- Independent Component Analysis: We can use ICA to transform the data into independent components which describe the data using less number of components
- ISOMAP: We use this technique when the data is strongly non-linear
- t-SNE: This technique also works well when the data is strongly non-linear. It works extremely well for visualizations as well
- UMAP: This technique works well for high dimensional data. Its run-time is shorter as compared to t-SNE
本文为转载文章,原文地址:https://www.douban.com/note/469279998/
一、降维——机器学习笔记——降维(特征提取)相关推荐
- 机器学习笔记之降维(一)维数灾难
机器学习笔记之降维--维数灾难 引言 回顾:过拟合 维度灾难 从数值角度观察维数灾难 从几何角度观察维度灾难 示例1 示例2 引言 本节将介绍降维算法,并介绍降维算法的相关背景. 回顾:过拟合 我们在 ...
- 机器学习笔记之降维(二)样本均值与样本方差的矩阵表示
机器学习笔记之降维--样本均值与样本方差的矩阵表示 引言 场景介绍 样本均值与样本方差 样本均值与样本方差的矩阵表示 样本均值的矩阵表达 样本方差的矩阵表达 中心矩阵的性质 引言 上一节介绍了维数灾难 ...
- Python机器学习笔记 使用scikit-learn工具进行PCA降维...
Python机器学习笔记 使用scikit-learn工具进行PCA降维 之前总结过关于PCA的知识:深入学习主成分分析(PCA)算法原理.这里打算再写一篇笔记,总结一下如何使用scikit-lear ...
- Python机器学习笔记 使用scikit-learn工具进行PCA降维
Python机器学习笔记 使用scikit-learn工具进行PCA降维 之前总结过关于PCA的知识:深入学习主成分分析(PCA)算法原理.这里打算再写一篇笔记,总结一下如何使用scikit-lear ...
- 机器学习笔记(十一)----降维
机器学习中往往会遇到样本特征非常多的情况,往往成千过万,这对于机器学习是非常不利的,被称为维数灾难: 1.高维空间样本具有稀疏性,模型较难找到数据特征: 2.维度过高,导致计算量太大. 维度过高,那么 ...
- 机器学习——经典降维算法与框架综述
目录 综述 一.介绍 二. 降维算法回顾 1.KNN 1.1 KNN核心思想 1.2 KNN算法流程 1.3 KNN算法优缺点 2.线性降维 (1)PCA 2.1.1 PCA简介 2.1 ...
- 机器学习sklearn-PCA降维算法
1 概述 1.1 什么叫"维度" 对于数组和Series来说,维度就是功能shape返回的结果,shape中返回了几个数字,就是几维. 针对每一张表,维度指的是样本的数量或特征的数 ...
- MachineLearning 13. 机器学习之降维方法UMAP及可视化 (umap)
点击关注,桓峰基因 桓峰基因公众号推出机器学习应用于临床预测的方法,跟着教程轻松学习,每个文本教程配有视频教程大家都可以自由免费学习,目前已有的机器学习教程整理出来如下: MachineLearnin ...
- MachineLearning 12. 机器学习之降维方法t-SNE及可视化 (Rtsne)
点击关注,桓峰基因 桓峰基因公众号推出机器学习应用于临床预测的方法,跟着教程轻松学习,每个文本教程配有视频教程大家都可以自由免费学习,目前已有的机器学习教程整理出来如下: MachineLearnin ...
最新文章
- Multiple substitutions specified in non-positional format; did you mean to add the formatted=”false”
- 2016年4月计算机组成原理试题答案,年4月自考计算机组成原理试题及答案.doc
- linux ranger 文本模式,Ranger – 给命令行用户一个基于文本的文件管理器
- springboot使用redisTemplate 报错:APP FAILED TO START Field template in required a single bean redis工具类
- jsp整合mybatis案例
- java 多层异常_Java多层嵌套异常处理的基本流程
- SIGGRAPH 2020 | 基于样例的虚拟摄影和相机控制
- 谈谈Android 6.0运行时权限理解
- java实战 ——分类模块的开发
- 样本不平衡 pytorch_CVPR2019 | 面对高度不均衡数据如何提高精度?这篇文章有妙招...
- 杰控连接mysql_工控自动化应用方案:杰控FameView组态软件在数据库连接和查询方面的应用...
- 新版掌上阅读小说源码+支持公众号/分站/封装APP
- Python给gif图片加文字水印
- 组态王bitset用法_组态王使用问题解答6
- The flowing processes must be stopped before the CUDA Visual studio integration installation can pro
- Android Studio将html5网址封装成APP
- Python 如何被证明是 2021 年的转折点语言
- Cadence 中贴片元件焊盘的制作
- 简谈:如何学习FPGA
- 给硬件工程师的入门课-做硬件还有前途吗?聊聊一些机遇