Analyzing User-Level Privacy Attack Against Federated Learning
Analyzing User-Level Privacy Attack Against Federated Learning
IEEE JSAC CCF-A期刊 宋梦凯(武汉大学网络安全实验室)
Summary
- 提出了针对FL用户级隐私的基于GAN的攻击(mGAN-AI),主要是从每个client的更新中计算出相应的数据代表,然后用这些近似真实的数据训练GAN的鉴别器和生成器,最终GAN的生成器就可以生成某个client的私有数据。
- 其中比较重要的是client representative的计算和匿名条件下representative 近似度衡量的设计,其中包括鉴别模型和识别模型的训练。
- 最后再MNIST和AT&T数据集上进行测试,并与基于参数更新的攻击对比,体现了基于Representative攻击的优势。
- 与MI攻击、GAN-based攻击对比。体现了在non-IID数据上的优越性。
Threat Model
Learning Scenario
- 应用环境:学习环境,有N(>=2)个client。客户端k的偏置分布pk被认为是其客户端级隐私,为了简单起见,后面的模型用图片分类器。基于图片分类进行攻击,并查看效果,因为图片重构效果可视化也比较好。
Malicious Server
- 本文中Server是攻击主体,也是比较早的将攻击主体作为服务器的,一般攻击者都是恶意的client。
- 恶意的server:目的是重构某个client的数据。
只分析来自客户端的周期性更新(即被动攻击),也可以故意隔离受害者训练的共享模型,以进行下一步的攻击(主动攻击)。
被动攻击这里应该是半诚实的server,在进行攻击的时候不会影响模型的正常训练、学习。而主动攻击会将受害者client与其他client隔离,并单独针对victim client训练GAN,这里server是恶意的,因为改变的模型,影响了学习过程。
Communication Protocol
- 采用加密的聚合可以防止攻击者直接获取跟新,但是server不能评估client更新的有效性,万一存在恶意client的时候会影响模型的可用性。
- 在本论文的实验中采用明文传输。实际上聚合的时候不需要知道更新的来源,匿名化可以通过第三方匿名网络来实现,这里考虑了client匿名和非匿名两种情况。实际为了隐私用匿名的更好。
APPROACH UNDER NON -ANONYMOUS ENVIRONMENT
Overview of mGAN-AI
- GAN的原理是在真实数据和生成数据上共同训练鉴别器和生成器,在FL环境下,server接触不到client的真实数据。server只能接触到来自client 的更新,这里用client提交的更新当作client本地训练鉴别器的更新,就相当于将FL的思想用到GAN中。生成器可以在server中产生数据。

mGAN-AI的结构介绍- 其中有N个client,victim代表受害者,第t次迭代的共享模型表示为Mt, u t k u^k_t utk表示第t次迭代,第k个client的更新。其中利用client的更新计算出client representatives,然后将辅助数据集aux的representatives、other client的representative和representative of victim 放入鉴别器D和生成器G进行训练,其中辅助数据将是server判断收敛的真实数据集(小部分)。
- 其中多任务鉴别器可以鉴别输入特征的来源身份、真实性、类别。鉴别器的模型结构与共享模型的一样,只是输出层不同,因为之前的层都是提出特征,最后才分类输出。
Structure
- 鉴别器的三个功能:
- 真假数据判断(GAN初始的功能)
- 对输入的分类
- 分辨身份,是victim还是other
- 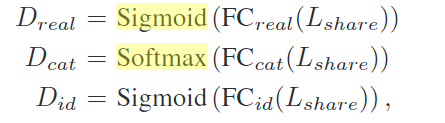 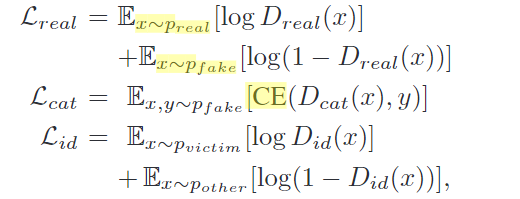 - D就是鉴别器的输出,Loss 就是训练时对三个输出的损失函数。Loss损失函数的定义时GAN论文中提出的。Lshare是除输出层以外的所有层,因为他们共享除输出层以外的层,只是输出时的激活函数不同(分类任务不同)。 - x是输入样本,但是server无法访问这些具体的数据,因此根据每个客户端对服务器的更新来计算client特征X。 - $Loss_c$是X类别(伪造的X)的损失函数,CE是交叉熵函数,这里就是求鉴别器D鉴别身份与真实身份y的交叉熵损失。 - 更新D的目标是$Loss_r+Loss_i$越来越小。就是鉴别真实与否和鉴别X的client身份越来越准。 - 更新G的目标是$Loss_c-Loss_r+Loss_i$是类别的损失-真实性的损失+client身份ID的损失,越来越小。 - 其实这里是不太明白为什么minimize上面两个Loss组合的。 - 不应该D越更新,越可以更好的区分real and fake,那当x来自Preal的时候,Dreal(x)应该趋于1,当x来自Pfake的时候,Dreal(x)应该会减小吧,最后,那Loss_real 应该越大吧。我也是刚接触这方面,如果哪里错了或者学的不足还请您多指教。
Passive Attack

- 当被动攻击的时候,server充当半诚实的server,只获取client的更新进行分析,而不修改共享模型 M t M_t Mt或引入对抗性影响。
- 鉴别器D在每次迭代时由Mt+uvt初始化,这样模型就会倾向于受害者v。就相当于额外victim会再进行一次更新。
- 因为D每次继承M,这是根据真实数据训练的,所以慢慢基于fake data的训练会少与真实数据,这时候需要补偿fake data的训练。
- 算法一中的Update是通过以下更新完成。
-
- 和 平时的梯度优化类似。
Active Attack
- 被动攻击是隐蔽的,因为server只需要获取client的更新即可。而主动攻击是将victim与其他client进行隔离,即除了恶意的server还包含一个管理的server。这个关联server只连接victim client,只接收他的更新,就做到了隔离。其中共享的模型不再是 M t M_t Mt而是 M i s o M^{iso} Miso。 M i s o M^{iso} Miso只受到victim跟新的影响。这个关联server也只在victim上执行mGAN-AI攻击。初始化的时候和被动攻击一样, M i s o M^{iso} Miso = M 0 M_0 M0=D.
- 通过遵循与被动攻击类似的训练方案,在附属服务器上训练mGAN AI,生成器将生成具有更高质量和更可区分身份的样本,因为mGAN是纯基于目标victim数据训练的,不会受到其他数据的影响。而且鉴别器将不用进行身份鉴别和代表数据计算。恶意server会主动向victim发送 M i s o M^{iso} Miso进行更新,违反了FL初始规则,但不会影响FL。
Calculation of Client Representatives
- 之前攻击的时候需要计算客户表示来与生成的fake representative进行训练,来优化G和D。这里介绍了怎么通过更新来计算每个client的表示。
- 客户端的表示被定义为在共享模型上训练后实现与真实样本相同更新的合成样本,就是要求输入到同一个模型中,输出相同更新的数据。二者的主要特征分布应该趋同。理想的是 u t X k u^{X_k}_t utXk = u t k u^{k}_t utk,二者更新u相同。
- 上式6基于优化的方法基于共享模型来计算 X k X_k Xk,目标就是最小 u t X k u^{X_k}_t utXk 和 u t k u^{k}_t utk的二范数。
- 式子6进一步正则化利用(7)
- 7中 X k X_k Xk是一组图片,也就是一个小批次的。i和j是单个图像x的行和列(长和宽)
- L o s s T V Loss_{TV} LossTV计算邻域方差来增强图像的空间平滑度。
- 式子(8):λ平衡了增强图像平滑度的效果。我们使用盒约束的L-BFGS来计算XK。根据经验,有效的Xt可以在几次更新后实现。第七节的实验验证了代表在识别任务中的有效性。
APPROACH UNDER ANONYMOUS ENVIRONMENT
- 为了解决匿名化带来的挑战。提出了一种预链接性攻击,用于关联来自相应客户端的更新,确保匿名环境下的重建攻击。
Problem Formulation and Overview
- 非匿名下,client更新是带有身份的。但是一般的联邦学习只需要收集所有的更新进行聚合,不需要知道哪个更新是来自哪个client,所以攻击要考虑匿名条件下。
- 将预链接攻击形似化为验证任务。
- 其中恶意服务器旨在验证在不同的训练迭代中两个给定的参数更新集是否属于同一客户端的更新。通过关联来自不同客户端的定期更新来重新识别匿名模型更新,而不是通过识别IP地址这种方式进行验证。
- 周期性的参数更新也存在与client相关的对应模式,这种模式反映了客户端数据分布特征。参数更新在每轮更新中都会受到不可预测的影响,因此也会影响我们的验证,所以用之前提到的client representative来替代参数更新进行验证。
- 预链接攻击

- 每个身份id都有一个对应的队列Q存储client表示。
- 从匿名更新 U 1 ∗ U^{*}_1 U1∗中计算出X1(应该是一组client表示),并随机附上身份标签。就是每个身份id的Q都有了对应的K个X,因为后面来了新的 X t + 1 X_{t+1} Xt+1进行比较的时候要进行K次投票,每次投票就是将 X t + 1 X_{t+1} Xt+1与Q中的一个X进行相似度计算,最后哪个相似度最大,哪个Q代表的身份就是 X t + 1 X_{t+1} Xt+1的身份。
- 经过之前投票机制和相似度计算求出 X t + 1 X_{t+1} Xt+1的身份后,将 X t + 1 X_{t+1} Xt+1更新到 Q i d Q_{id} Qid中,之前需要把之前的X出队。
Representatives Similarity Measurement Design(之前讲了代表计算)
-
- 将识别模型和验证模型融合在一起,同时预测身份和计算相似性度量。给定一对客户端代表,卷积层首先提取他们的特征嵌入。然后利用平均池化层对特征表示进行下采样,提高了模型的泛化能力,加快了训练速度。最后,由softmax激活的识别层输出与每个客户端身份对应的概率向量。同时,平方层计算特征的差异,sigmoid层输出特征的相似度。
- R e p 1 Rep_1 Rep1和 R e p 2 Rep_2 Rep2是一对client 表示,所为上图模型的输入,输出是[0,1],表示是否来自同一client。
- 使用CE(交叉熵损失)作为训练损失,而不是文献36中的方法。使用Imagenet上的与训练模型作为初始化 M t M_t Mt,这更有助于收敛。
- 算法二中sim()函数的实现:将平均池化层的输出作为客户端代表的区分描述符。然后通过它们的L2归一化CNN嵌入之间的欧几里德距离来计算相似度。
- 训练损失
因为代表相似度设计要实现验证和识别身份两种功能,所以相应有两个损失。识别损失和验证损失。它们由识别标签和验证标签监督。- 识别损失
-
- CE:求模型预测的身份和真实身份的CE(交叉熵),这就是身份识别的损失函数。
- M i d M_id Mid是身份识别模型的输出,也就是模型的预测,后面的id是实际的id。
- 身份鉴别损失
- 孪生网络直接将后几层嵌入作为客户端代表描述符d1、d2。通常,来自微调CNN的后几层具有辨别能力。它比中间层中的激活输出更紧凑。为了融合该特征,我们使用了一个非参数平方层,该层将两个描述符d1、d2作为输入,然后求二者平方,也就是对应Square Layer。
- 最后Square Layer层的输出进行Sigmoid函数激活,输出的是两个client代表为统同一client的概率。
- 与传统二分类方法类似,我们使用CE进行身份鉴别。
- 其中s是匹配的标签,当s为1的时候(来自一个client),损失函数只用前半部分,否则用后半部分。
- 之前提到的 R e p 1 Rep_1 Rep1和 R e p 2 Rep_2 Rep2
- 就是之前提到了client代表,为了训练模型来判断两者是否来自一个client,和来自哪个client。这里的client 代表也就是X,从每个client更新那计算得来。非匿名条件是通过第五部分,E中解释的。当时可以得知哪个client是哪个client。
- 设计了一个影子联邦学习模型来生成 R e p 1 Rep_1 Rep1和 R e p 2 Rep_2 Rep2来训练上面的识别和鉴别模型。
- 其中恶意server拥有 X a u x X_{aux} Xaux数据集(本来目的是判断FL训练效果或者收敛什么的)来训练这个影子模型。
- 首先将Xaux辅助数据集划分为M部分,每个部分都是一个训练集。将每个部分随机用1-N标记(即身份标识)。这么模拟某部分数据集是某client的训练数据集。
然后攻击者初始化一个和原始模型一样的共享模型并设置一样的目标。
然后用这些数据集中的影子client进行训练,并对共享模型进行更新。 - M t ‘ M^`_t Mt‘、 u t k ′ u_t^{k'} utk′:获取这两个就可以计算client代表,方法同上文中的 非匿名情况下的client representatives计算。相当于用真实的辅助数据模拟生成了Rep。
- 最后的( X t k X_t^{k} Xtk, k k k)作为识别模型的训练数据(输出是身份).
- ( X t k 1 X_t^{k1} Xtk1, X t k 2 , X_t^{k2}, Xtk2,s)是验证模型的训练数据,s就是标签(1 or 0).
- 首先将Xaux辅助数据集划分为M部分,每个部分都是一个训练集。将每个部分随机用1-N标记(即身份标识)。这么模拟某部分数据集是某client的训练数据集。
- 总之就是用知道的数据集Xaux随机分为N部分并随即标为1-N,模拟N个client,用这些client的更新和模型 M t M_t Mt计算出X(其中身份是已知的),用X和已知的身份信息训练上文中提到的鉴别模型、识别模型。
- 识别损失
Experiment
Datasets and setup
- MNIST和AT&T(人脸)数据集。
Performance of Linkability Attack
模拟10个client,投票数3
- 评估标准:匹配准确性和精度
- 前者描述了当馈送可能来自非相邻迭代的随机选择对时的精度,而后者描述了当从相邻迭代馈送不同客户端的Rep和Repk的匹配库时的排序精度。
- 在实验中,共享模型在迭代150次左右达到收敛,因此使用第150个共享模型。优化目标由识别损失和验证损失两部分组成。我们给他们定了同等的权重。训练中,从相同/不同的客户身份中抽样正/负对。
-
- 基于rep的攻击实现了高的训练/测试匹配精度,这表明了代表在辨别能力方面的进步。特别是在AT&T数据集上,与基于更新的攻击相比,基于rep的攻击收敛更快,测试精度更高。这里比较的测试精度
- MNIST上二者差异不明显。MNIST数据集上的较小方差导致共享模型对客户端本地模型的影响较小。周期性更新的辨别能力不会因外部干扰而大大减弱,从而使基于更新的攻击获得与基于rep的攻击类似的结果。因此,考虑到联合学习中的非IID数据,与基于更新的攻击相比,基于rep的攻击带来了更强的威胁。
Privacy Attack
- 评估被动攻击,这里数据分布模拟真实不平衡的数据分布。而且一个client可以拥有不同的类。被动攻击是只分析client的更新,不对FL结构或者学习过程进行改变。
- 基于MNIST
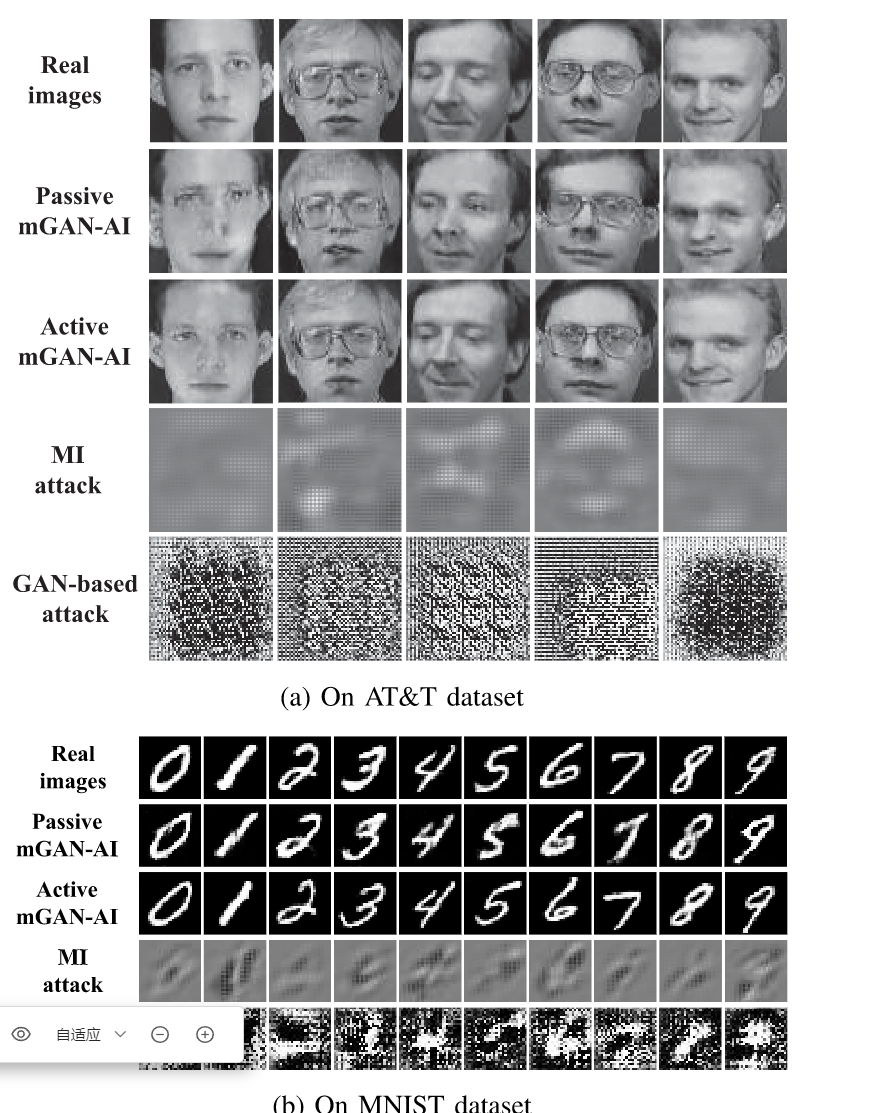
- 10个client,每个随机选3种数字作为自己的训练数据。图7为实验结果,图7中有10种数字,所以图7不是一次实验结果。

- 基于AT&T
- N=10。受害者的可分辨特征被指定为戴眼镜.实验结果图8表明,mGAN-AI工具具有针对性。因为重建的照片是两张戴眼镜的,而且其他照片比较模糊。

Quantitative and Qualitative Comparison(定量和定性分析)
- 与反演攻击和之前基于GAN的攻击进行对比
Defenses
- 加密传输,对发送的参数进行加密,安全聚合、同态加密,让敌手无法获取真实的更新信息。
- 可信执行环境(TEE): TEE创建一个与操作系统并行的隔离环境,保证所加载代码和数据的机密性和完整性。在联邦学习的情况下,训练可以在服务器上的TEE内部执行。那么中间值,例如参数更新,就不能被恶意服务器访问
- 动态参与,训练了可以退出,让攻击不能持续更新。因为这里是每一个迭代,D都会用 M t M_t Mt和 u t v u_t^{v} utv进行更新。如果以后没有v的更新了,就不好继续更新了。
Related Work
GAN
- https://www.bilibili.com/video/BV1rb4y187vD
- GAN就是同时训练两个模型一个是鉴别器,一个是生成器,鉴别器的目的是鉴别什么是生成的数据,什么是原来真实的数据,生成器的目的是生成鉴别器无法鉴别的伪造数据。让两者相互博弈,达到纳什均衡,GAN对抗网络的初衷还是想让生成器更胜一筹,让鉴别器鉴别不出来真假。
Analyzing User-Level Privacy Attack Against Federated Learning相关推荐
- Protect Privacy from Gradient Leakage Attack in Federated Learning
wangjunxiao/GradDefense: Defense against Gradient Leakage Attack (github.com) Summary 针对DGA和DIA攻击,提出 ...
- 【论文阅读】 Beyond Inferring Class Representatives: User-Level Privacy Leakage From Federated Learning
本文提出了一种 multi-task 的 GAN(multi-task GAN for Auxiliary Identification (mGAN-AI)) ,可以恢复 client 级别的多种隐私 ...
- 2.Paper小结——《Privacy-preserving blockchain-based federated learning for traffic flow prediction》
题目: 基于区块链的基于隐私保护的交通流量预测的联邦学习 0.Abstract: 交通流量预测已成为智能交通系统的重要组成部分.然而,现有的基于集中式机器学习的交通流量预测方法需要收集原始数据以进行模 ...
- (翻译)DBA: DISTRIBUTED BACKDOOR ATTACKS AGAINST FEDERATED LEARNING
摘要 后门攻击旨在通过注入对抗性触发器来操纵训练数据的子集,从而使在受篡改数据集上训练的机器学习模型将在嵌入了相同触发器的测试集上进行任意(目标)错误预测.尽管联邦学习(FL)能够汇总由不同方面提供的 ...
- 《DBA: DISTRIBUTED BACKDOOR ATTACKS AGAINST FEDERATED LEARNING》阅读笔记
DBA: DISTRIBUTED BACKDOOR ATTACKS AGAINST FEDERATED LEARNING ** 本文发在ICLR 2020,针对联邦学习进行的后门攻击.其提出的方案针对 ...
- 【Paper Reading】Privacy-Preserving Aggregation in Federated Learning: A Survey
Privacy-Preserving Aggregation in Federated Learning: A Survey 原文来源:[Arxiv2022] Privacy-Preserving A ...
- 【Paper Reading】BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning
BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning 原文来源:[ATC 2020] Batch ...
- 【FL-GAN】Private FL-GAN: Differential Privacy Synthetic Data Generation Based on Federated Learning
Private FL-GAN: Differential Privacy Synthetic Data Generation Based on Federated Learning 私有FL-GAN: ...
- 联邦学习安全与隐私保护综述 A survey on security and privacy of federated learning
联邦学习安全与隐私保护综述 写在前面的话 联邦学习是什么 联邦学习工作流程 联邦学习的技术分类 安全问题和解答 隐私问题和解答 未来方向 写在前面的话 本篇博客参考<A survey on se ...
最新文章
- (三)Sass和Compass--制作精灵图片
- linux下使用gcp拷贝数据的时候显示进度条
- 【Android 异步操作】手写 Handler ( Handler 发送与处理消息 | Handler 初始化 | 完整 Handler 代码 )
- php调用函数的变量,从内PHP函数调用的变量在外部函数使用
- 从零学习SwinTransformer
- AM335 嵌入式 linux,am335x开发板建立嵌入式 Linux NFS 开发环境
- 计算机一级ftp协议传输,文件传输协议(FTP)必将消亡
- 《IT项目管理》读书笔记(1) —— 概述
- Android App性能测试之二:CPU、流量
- Python3利用BeautifulSoup4抓取站点小说全文的代码
- 剑指offer 数组中只出现一次的数字
- 转 Apache Ignite——新一代数据库缓存系统
- 三个重要的事件来看软件测试的重要性和软件测试的行情
- python pandas 可视化初步使用 -- 股票价格区间天数统计柱状图
- 循环控制语句--for循环
- 8、135条最全弱电智能化综合布线常用术语
- MTK平台如何确定Tuning的Scenario
- IE里兼容性视图是做什么用的?该如何设置?
- 手机微信下载的文件存储在哪一个文件夹?
- 原生js实现扫雷游戏
热门文章
- 纺织助剂能够提效降本,市场需求前景广阔
- ElasticSearch~main ERROR Unable to locate appender “rolling_old“ for logger config “root“
- PV操作 黑白子问题 C#
- Linux下配置IPV6,C程序适配IPV6
- 解决MySQL_python-1.2.5-cp27-none-win_amd64.whl is not a supported wheel on this platform.(win10)
- WinCE的cab文件
- 通过statCounter计算给定的RDD[Double]的统计信息的方法
- 427 建立四叉树(递归、二维前缀和)
- org.postgresql.util.PSQLException: 不良的类型值 long : \x
- springboot实现条形码_基于SpringBoot+Mybatis+Thymeleaf商品信息管理系统