转 Apache Ignite——新一代数据库缓存系统
分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
Apache Ignite——新一代数据库缓存系统
【编者按】飞速增长的数据需要大量存储,对这些数据的管理也不是一件容易的事。但相比于存储和管理,如何处理数据才是开发人员真正的挑战。对于TB级别数据的存储和处理通常会让开发人员陷入速度、可扩展性和开销的矛盾困境中。近日,Dmitriy Setrakyan在Dzone上撰文,为大家介绍了新一代数据库缓存系统Apache Ignite,由OneAPM工程师编译。
以下为译文
将数据存储在缓存中能够显著地提高应用的速度,因为缓存能够降低数据在应用和数据库中的传输频率。Apache Ignite允许用户将常用的热数据储存在内存中,它支持分片和复制两种方式,让开发者可以均匀地将数据分布式到整个集群的主机上。同时,Ignite还支撑任何底层存储平台,不管是RDBMS、NoSQL,又或是HDFS。

在集群配置好之后,数据集增加只需在Ignite集群中增加节点而不需要重启整个集群。节点数目可以无限增加,所以Ignite的扩展性是无穷的。在Ignite的配置上有下面这几个选项可供选择:
Write-Through和 Read-Through
在Write-Through模式中,缓存中的数据更新会被同步更新到数据库中。 Read-Through则是指请求的数据在缓存中不可用时,会自动从数据库中拉取。
Write-Behind Caching
Ignite还提供了一种叫做Write-Behind Caching的数据库异步更新模式。默认情况下,Write-Through中每一次更新都会对数据库发起一次请求。如果使用Write-Behind Caching后写,对缓存的更新会整合成批次然后再发送给数据库。这对改删频繁的应用来说可以达到相当的性能提升。
自动化持久数据
Ignite提供了易用的schema映射工具,从而系统可以自动地与数据库整合。这一工具可以自动地连接数据库,并生成所有需要的XML OR-mapping配置以及Java域模型POJOs。
SQL查询
查询Ignite缓存很简单,使用的就是标准的SQL。Ignite支持所有的SQL函数、聚合和group操作,甚至支持分布式SQL JOINs。下面Ignite中一个SQL查询示例:
IgniteCache<Long, Person> cache = ignite.cache("mycache");// ‘Select’ query to concatenate the first and last name of all persons.SqlFieldsQuery sql = new SqlFieldsQuery( "select concat(firstName, ' ', lastName) from Person");// Execute the query on Ignite cache and print the result.try (QueryCursor<List<?>> cursor = cache.query(sql)) { for (List<?> row : cursor) System.out.println("Full name: " + row.get(0));}
小结
Apache Ignite是一个聚焦分布式内存计算的开源项目,它在内存中储存数据,并分布在多个节点上以提供快速数据访问。此外,可选地将数据同步到缓存层同样是一大优势。最后,可以支持任何底层数据库存储同样让 Ignite成为数据库缓存的首先。
想要了解更多信息、文档、示例,请移步Apache Ignite官网。
原文链接:Apache Ignite for Database Caching (责编/仲浩)
来源:http://www.csdn.net/article/2015-09-28/2825815
内存数据组织 Apache Ignite
Apache Ignite 内存数组组织框架是一个高性能、集成和分布式的内存计算和事务平台,用于大规模的数据集处理。Ignite 为应用和不同的数据源之间提供一个高性能、分布式内存中数据组织管理的框架。
集群计算特性:
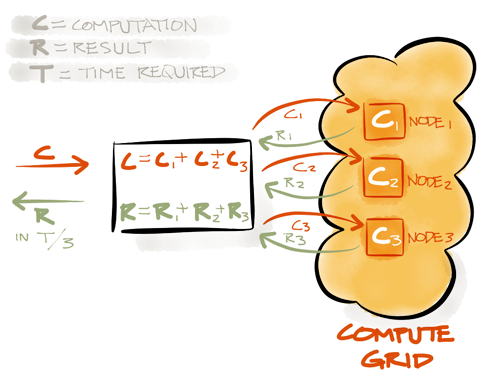
动态集群
Fork-Join & MapReduce 处理
分布式闭包执行
负载均衡和容错
分布式消息和事件
线性可伸缩
内存缓存和数据网格关键特性:
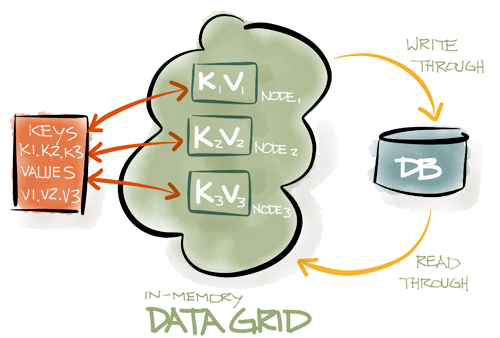
分布式内存中缓存
优雅的伸缩方案
高性能
分布式内存中事务支持
分布式内存队列和其他数据结构
Web 会话集群
Hibernate L2 缓存集成
分布式 SQL 联合查询
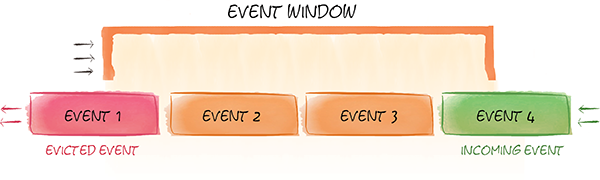
内存数据流:
来源:http://www.oschina.net/p/apache-ignite
Apache Ignite(一):简介以及和Coherence、Gemfire、Redis等的比较
一、Ignite简介
Apache Ignite 内存数组组织框架是一个高性能、集成和分布式的内存计算和事务平台,用于大规模的数据集处理,比传统的基于磁盘或闪存的技术具有更高的性能,同时他还为应用和不同的数据源之间提供高性能、分布式内存中数据组织管理的功能。
二、Ignite历史
Ignite来源于尼基塔·伊万诺夫于2007年创建的GridGain系统公司开发的GridGain软件,尼基塔领导公司开发了领先的分布式内存片内数据处理技术-领先的Java内存片内计算平台,今天在全世界每10秒它就会启动运行一次。他有超过20年的软件应用开发经验,创建了HPC和中间件平台,并在一些创业公司和知名企业都做出过贡献,包括Adaptec, Visa和BEA Systems。尼基塔也是使用Java技术作为服务器端开发应用的先驱者,1996年他在为欧洲大型系统做集成工作时他就进行了相关实践。
2014年3月,GridGain公司将该软件90%以上的功能和代码开源,仅在商业版中保留了高端企业级功能,如安全性,数据中心复制,先进的管理和监控等。2015年1月,GridGain通过Apache 2.0许可进入Apache的孵化器进行孵化,很快就于8月25日毕业并且成为Apache的顶级项目,9月28日即发布了1.4.0版,应该说发展、迭代速度非常之快。该技术相关资料较少,但确是一个很有潜力的技术,解决了大规模、大数据量、高并发企业级或者互联网应用面临的若干痛点。
三、Ignite和Hadoop以及Spark的关系
Ignite和Hadoop解决的是不同的问题,即使在一定程度上可能应用了类似的底层基础技术。Ignite是一种多用途,和OLAP/ OLTP内存中数据结构相关的,而Hadoop仅仅是Ignite原生支持(和加速)的诸多数据来源之一。
Spark是一个和Ignite类似的项目。但是Spark聚焦于OLAP,而Ignite凭借强大的事务处理能力在混合型的OLTP/ OLAP场景中表现更好。特别是针对Hadoop,Ignite将为现有的Map/Reduce,Pig或Hive作业提供即插即用式的加速,避免了推倒重来的做法,而Spark需要先做数据ETL,更适合新写的分析应用。
四、和类似技术的比较
在Ignite以前,大规模、大数据量、高并发企业级或者互联网应用为了解决数据缓存、降低数据库负载、提高查询性能等突出问题,很多采用了Hazelcast或者Oracle Coherence或者GemFire(比如12306网站)或者目前应用越来越广泛的Redis等缓存技术,本文对这些相关的技术做了简单的比较,基本内容来源于其官方网站,进行了翻译整理,方便更多的人了解他。
1.Ignite和Hazelcast
Apache Ignite和Hazelcast都提供了富数据网格的特性,解决了可扩展的分布式集群环境下在内存中对数据进行缓存和分区的问题。
Ignite和Hazelcast在缓存的方式上是有很多不同的,同时支持事务和数据的查询,下面的表格列出了一些主要的不同点,这些都是我们在选择内存数据网格产品时需要特别关注的。
|
序号 |
对比项目 |
Apache Ignite |
Hazelcast |
| 1 | 聚焦于开源 | Ignite是一个Apache的开源项目,还在不断的增加新特性,对C++、.NET/C#和Node.js的支持也会很快到来。 | Hazelcast正在持续的减少开源版本的功能,更多的功能加入了企业版中,比如堆外内存,持续查询,Web-Session集群,SSL加密支持等。 |
| 2 | JCache(JSR107) | Ignite完全兼容JCache (JSR 107)缓存规范 | Hazelcast完全兼容JCache (JSR 107)缓存规范 |
| 3 | 堆外存储 | Ignite根据用户配置支持将数据存储在堆内或者堆外 |
Hazelcast仅在商业版中提供堆外存储的功能 |
| 4 | 堆外索引 | 只要配置了堆外存储,Ignite就会在堆外存储索引(为了不影响使用堆内内存的用户应用。) | 不支持 |
| 5 | 持续查询 | Ignite支持持续查询,比如允许客户端和服务器端订阅数据变化的持续通知 | Hazelcast仅在商业版中提供持续查询的功能。 |
| 6 | SQL查询 | Ignite支持完整的SQL(ANSI-99)语法以查询内存中的数据 | Hazelcast仅对SQL提供有限的支持(只有几个关键字) |
| 7 | 关联查询 | Ignite支持完整的SQL关联,包括跨多个缓存的关联,比如:select * from A a, B b where a.b_id = b.id | Hazelcast不支持任何的关联查询,不管用不用SQL,如果需要,开发者需要手工处理多个查询的结果。 |
| 8 | 查询一致性 | Ignite提供完整的查询一致性,即查询是在一个特定的快照中执行的,查询开始之后的数据更新不影响查询的结果。 | Hazelcast查询是不一致的,这是可能的,查询结果的一部分将看到一定的更新,而另一部分则不会。 |
| 9 | 查询容错 |
Ignite查询是容错的,即查询结果始终是一致的不会受到集群拓扑发生变化的影响,比如节点的加入,退出或崩溃。 |
Hazelcast查询是不容错的,即查询结果在集群拓扑发生变化时不一致,而数据正在后台重新平衡。 |
| 10 | 数据一致性 | Ignite支持内存中数据的原子性和事务一致性,不管数据存储在分区或者复制缓存中。 | Hazelcast仅在分区缓存中支持原子性和事务一致性,而存储在复制缓存中的数据没有任何事务一致性的保证。 |
| 11 | SSL加密 | Ignite为所有的网络传输提供SSL加密,包括客户端和服务器端以及服务器之间。 | Hazelcast仅在商业版中提供SSL加密功能。 |
| 12 | Web-Session集群 | Ignite为所有已知的应用服务器提供Web-Session的缓存和集群化支持。 | Hazelcast仅在商业版中提供Web-Session集群化支持。 |
| 13 | 计算网格 | Ignite提供集群上的M/R,Fork/Join和基本的分布式lambda处理,包括任务负载平衡,容错,检查点,计划任务等。 |
Hazelcast仅支持M/R和集群内的分布式随机任务。 |
| 14 | 流式网格 | Ignite支持内存流,包括对数据流浮动窗口的查询和维护支持 | 不支持 |
| 15 | 服务网格 | Ignite可以使用户方便地将其服务集群化,包括支持各种单例集群。 | Hazelcast管理的服务不提供单例集群的功能。 |
| 16 | .Net/C#,C++支持 | Ignite将在1.5.0版中提供完整的内存组织API | Hazelcast仅在商业版中提供有限的客户端API支持。 |
| 17 | Node.js支持 | Ignite将在1.5.0版中提供Node.js的客户端API。 | 不支持 |
2.Ignite和Coherence
Apache Ignite和Oracle Coherence都提供了富数据网格的特性,解决了可扩展的分布式集群环境下在内存中对数据进行缓存和分区的问题。
Ignite和Coherence在缓存的方式上是有很多不同的,同时支持事务和数据的查询,下面的表格列出了一些主要的不同点,这些都是我们在选择数据网格产品时需要特别关注的。
|
序号 |
对比项目 |
Apache Ignite |
Oracle Coherence |
| 1 | 开源和闭源 | Ignite是一个Apache的开源项目,并且还在不断的增加新特性,对C++、.NET/C#和Node.js的支持也会很快到来。 | Coherence是一个Oracle的专有软件,并不提供开源和免费的版本。 |
| 2 | JCache (JSR 107) | Ignite完全兼容JCache (JSR 107)缓存规范 | Coherence完全兼容JCache (JSR 107)缓存规范 |
| 3 | 堆外存储 | Ignite根据用户配置支持将数据存储在堆内或者堆外 | Coherence对开发者提供了有限的选项支持将数据存储在堆外 |
| 4 | 堆外索引 | 只要配置了堆外存储,Ignite就会在堆外存储索引(为了不影响使用堆内内存的用户应用。) | 不支持 |
| 5 | SQL查询 | Ignite支持完整的SQL(ANSI-99)语法以查询查询内存中的数据 | 不支持 |
| 6 | 关联查询 | Ignite支持完整的SQL关联,包括跨多个缓存的关联,比如:select * from A a, B b where a.b_id = b.id | Coherence不支持任何的关联查询,不管用不用SQL,如果需要,开发者需要手工处理多个查询的结果。 |
| 7 | ACID事务 | Ignite提供了每台服务器每秒成千上万事务的优异性能。 | Coherence因为性能原因不建议使用事务。 |
| 8 | 分层存储 | Ignite支持分层存储模型,数据可以在堆内、堆外以及交换空间内存储和移动,上层将提供更多的存储能力,当然延迟也会增加。 | 不支持 |
| 9 | 数据流 | Ignite提供内存流的支持,包括支持流数据的维护、查询和浮动窗口 | 不支持 |
| 10 | 配置 | Ignite支持通过Java Bean以及原生的Spring XML集成对系统进行配置,同时也支持通过代码对系统进行方便配置的能力。 | Coherence通过专有的XML格式文件进行配置,不支持通过代码进行配置。 |
3.Ignite和Gemfire
Apache Ignite和Pivotal Gemfire都提供了富数据网格的特性,解决了可扩展的分布式集群环境下在内存中对数据进行缓存和分区的问题。
Ignite和Gemfire在缓存的方式上是有很多不同的,同时支持事务和数据的查询,下面的表格列出了一些主要的不同点,这些都是我们在选择数据网格产品时需要特别关注的。
|
序号 |
对比项目 |
Apache Ignite |
Pivotal Gemfire |
| 1 | 开源和闭源 | Ignite是一个Apache的开源项目,并且还在不断的增加新特性,对C++和.NET/C#和Node.js的支持也会很快到来。 |
Gemfire是Pivotal的专有软件。 |
| 2 | JCache (JSR107) | Ignite数据网格是JCache(JSR107)规范的一个实现,该API为数据访问提供了简单易用、但是功能强大的API。 | Gemfire没有实现JCache,使用专有的API。 |
| 3 | 堆外存储 | Ignite根据用户配置支持将数据存储在堆内和堆外 | Gemfire不支持将数据存储在堆外 |
| 4 | SQL查询 | Ignite支持完整的SQL(ANSI-99) 查询语法以查询内存中的数据。 |
Gemfire不支持标准的SQL语法,但是他提供了他自己的叫做OQL的对象查询语言。 |
| 5 | 关联查询 | Ignite支持完整的SQL关联,包括跨多个缓存的关联,比如:select * from A a, B b where a.b_id = b.id | Gemfire不支持任何的跨区或者跨缓存的关联查询,如果需要,开发者需要手工处理多个查询的结果。 |
| 6 | 跨分区事务 | Ignite支持跨分区事务,事务可以在整个集群中缓存的所有分区中执行。 | Gemfire不支持跨越多个缓存分区或者节点的事务。 |
| 7 | 分层存储 | Ignite支持分层存储模型,数据可以在堆内、堆外以及交换空间内存储和移动,上层将提供更多的存储能力,当然延迟也会增加。 | 不支持 |
| 8 | 数据流 | Ignite提供内存流的支持,包括支持流数据的维护、查询和浮动窗口 | 不支持 |
| 9 | 配置 | Ignite支持通过Java Bean以及原生的Spring XML集成对系统进行配置,同时也支持通过代码对系统进行方便配置的能力。 | Gemfire通过专有的XML格式文件进行配置,不支持通过代码进行配置。 |
| 10 | 部署 | Ignite节点是对等的,并且在启动时自动加入集群(不需要任何locator服务器)。 | Gemfire需要启动和维护一个locator服务器,以便控制节点的加入和退出。 |
4.Ignite和Redis
Apache Ignite和Redis都提供了分布式缓存的功能,但是每个产品提供的功能特性是非常不同的。Redis主要是一个数据结构存储,但是Ignite提供了很多内存内的分布式组件,包括数据网格、计算网格、流,当然也包括数据结构。
Ignite是一个内存数据组织,并且提供了更多的功能,无法进行一个一个对应功能特性的比较,但是我们仍然能对一些数据网格功能进行比较。
|
序号 |
对比项目 |
Apache Ignite |
Redis |
| 1 | JCache (JSR 107) | Ignite完全兼容JCache(JSR107)缓存规范 | 不支持 |
| 2 | ACID事务 | Ignite完全支持ACID事务,包括乐观和悲观并发模型以及READ_COMMITTED, REPEATABLE_READ和SERIALIZABLE隔离级别。 | Redis提供了客户端乐观事务的有限支持,在并发更新情况下,客户端需要手工重试事务。 |
| 3 | 数据分区 | Ignite支持分区缓存,类似于一个分布式哈希,集群中的每个节点都存储数据的一部分,在拓扑发生变化的情况下,Ignite会自动进行数据的平衡。 | Redis不支持分区,但是他提供了副本的分片, |
| 4 | 全复制 | Ignite支持缓存的复制,集群中的每个节点的每个键值对都支持。 | Redis不提供对全复制的直接支持。 |
| 5 | 原生对象 | Ignite允许用户使用自己的领域对象模型并且提供对任何Java/Scala, C++和.NET/C#数据类型(对象)的原生支持,用户可以在Ignite缓存中轻易的存储任何程序和领域对象。 | Redis不允许用户使用自定义数据类型,仅支持预定义的基本数据结构集合,比如Set、List、Array以及一些其他的。 |
| 6 | (近)客户端缓存 | Ignite提供客户端缓存最近访问数据的直接支持。 | Redis不支持客户端缓存。 |
| 7 | 服务器端并行处理 | Ignite支持在服务器端,靠近数据并行地直接执行任何Java, C++和.NET/C#代码。 | Redis通常没有任何并行数据处理的能力,服务器端基本只支持LUA脚本语言,服务器端不直接支持Java, .NET,或者C++代码执行。 |
| 8 | SQL查询 | Ignite支持完整SQL(ANSI-99)语法以查询内存中的数据。 | Redis不支持任何查询语言,只支持客户端缓存API。 |
| 9 | 持续查询 | Ignite提供对客户端和服务器端持续查询的支持,用户可以设置服务器端的过滤器来减少和降低传输到客户端的数据量。 | Redis提供客户端基于键值的事件通知的支持,然而,他不提供服务器端的过滤器,因此造成了在客户端和服务器端中更新通知网络流量的显著增加。 |
| 10 | 数据库集成 | Ignite可以自动集成外部的数据库-RDBMS, NoSQL,和HDFS | 不支持 |
按照官方的说法,Ignite是很强大的整体解决方案和开发平台,功能很多而且复杂,没有提到缺点或者说坑,这个只能使用过程中逐步发现和解决,虽然Ignite本身历史尚短,但是既然来源于历史不算短的商业软件,还是经过实际生产环境验证的,基本功能的可用性肯定是有的。
来源:http://my.oschina.net/liyuj/blog/516836
Apache Ignite vs Apache Spark
|
出于我前面的贴子大赞了 Apache Ignite 的基于内存的文件系统和缓存功能,我将总结一下我将总结一下 Ignite 和 Spark 的主要区别。我发现这样的问题被重复提出。这很容易回答,因此不必在网上“挖坟”。 显而易见的一个不同就是 Ignite 是一个存于内存的计算系统,也就是把内存做为主要的存储设备。Spark 则是在处理时使用内存。系统的索引更快,提取时间减少,避免了序列/反序列等优点,使前者这种内存优先的方法更快。 |

思维特无敌
|
|
Ignite 的mapreduce 完全兼容 Hadoop MR API,因此大家可以简单的复用现有的MR代码,并让其以30倍的速度运行。 我准备发布的 Apache Bigtop in-memory stack的例子,将展示出这感人的加速。 另外,不同于Spark的 streaming,Ignite 并不受RDD 大小的限制。换句话说,你不需要在处理RDD前指定他的长度,你可以确实做到真正的流式处理。就是说,Ignite处理一个流式内容的时候是没有延迟的。 溢出是内存计算的通病:毕竟内存是有限的。在Spark中RDD是不可变长的,如果一个RDD创建的时候内存占用大于节点内存的1/2,那随后transformation跟generation的RDD很有可能占满整个节点内存,然后导致溢出。除非新的RDD是在另一个节点产生的。Tachyon 也在努力试图解决这个问题。 |

Frank_mc
|
|
Ignite 没有这种数据内存溢出的问题,因为他的缓存可以按照原子或事务的方式更新。无论如何,还是有可能溢出的:处理策略在这里有详细解释 -作为一个组件,Ignite也提供了first-class citizen的文件系统缓存层。注意,我已经定位过这个跟Ignite的不同,但是由于一些原因,我发的东西被他们删除了。我想知道为什么?;) -Ignite 使用 off-heap 内存,来避免 GC 中断,灰常有效。 -Ignite 保证强一致性。 -Ignite 完全支持 SQL99 作为一个支持 ACID 事务的方式。 |
Frank_mc
|
|
-Ignite 提供了内存SQL索引功能,可以避免全部数据扫描,直接导致非常显著的性能改进(参见第一段) -用Ignite的Java开发者不需要学习Scala Ropes这些,而且还鼓励使用Groovy。为了文章的简洁与凝练,对于后者我保留我的专业意见。 我会在闲散很长一段时间,但你可以考虑阅读一下 http://www.infoq.com/articles/gridgain-apache-ignite , http://www.odbms.org/blog/2015/02/interview-nikita-ivanov/, 这个项目的作者之一Nikita Ivanov 对其它关键的区别有很好的反馈。另外, 另外如果你对这些内容感兴趣 - 考虑加入 Apache Ignite (孵化中) 开发组 然后开始贡献代码吧! |
来源:http://www.oschina.net/translate/apache-ignite-vs-apache-spark
敢说 Apache Ignite 比 Tachyon 好?删帖!
编者说:本文的原作者在网上发表了 Apache Ignite 与 Tachyon 优劣的言论后,竟然发现帖子被无情的删除了,于是他贴出了与 Google 团队成员交流的邮件,顺便写下了下面的文章以表达愤懑之情。关于被删帖一事可点击此处查看。
在我发布 Apache Ignite (孵化中) 和 Tachyon 缓存项目之间差异说明之后,竟然发现文章被删除了。同时,我收到一份来自 Google 团队一名叫 tachyon-user 的私人邮件,上面解释了为什么文章“会被当做营销信息”而删除。
看来所有带有轻微批评 Tachyon 项目的信息都会被当做“营销信息”并且以真正“自由和开放“的名义删除掉!这个社区好像哪里搞错了。所以,我决定贴上曾经被他们退回的原始邮件。
你们自己判断:
From:<kboudnik@gmail.com>
Date:Fri,Apr 10,2015 at 11 : 46 PM
Subject:RE:Apache Ignite vs Tachyon
To:tachyon-user@googlegroups.com
实际上,你只是部分正确。
Apache Ignite 是一个发展成熟的内存计算(IMC)平台(又名数据结构)。 “支持 Hadoop 生态系统”只是结构的一个组成部分。它包括两个部分:-文件系统缓存:让 HDFS IO 性能显著提升的完全透明的缓存。从某种程度上说,这个和Tachyon 所要实现的功能相似。不像 Tacyon,Apache Ignite 缓存数据是更大的数据结构的一个组成部分,可以被任何 Ignite 服务使用。
- MR 加速器可以在 Ignite 内存引擎上运行“经典”的 MR 任务。基本上,Ignite MR (大量 SQL 列表和其他计算组件)是一个将数据储存在集群内存的方式。我会说 Ignite MT 比 Hadoop MR 快30倍(也就是 3000%)吗?顺便说下,它还不需要改变代码。
当你说“Tachyon...支持本地大数据堆栈”的时候,你应该要明白,Ignite Hadoop 加速也是支持本地化的:你可以在 IgniteFS 顶层运行 MR,Hive,HBase,Spark 等等,而且不需要改变任何事情。
顺 便截取一段给你看看:在 Ignite 系统文件缓存是“数据结构”范例的一部分,就像服务、高级集群、分布式消息、ACID 实时交易一样。加 HDFS 和 MR 加速层是很直接的,因为它们建立于高级的 Ignite 核心,而此核心已经实际运行了5年以上。不过,当你开始使用如 Tachyon 这样的内存文件系统,你会发现他很难实现相同企业级的计算。 没有任何抨击,就像刚才说的。
我建议你去看看 ignite.incubator.apache.org:读下文档,试着使用1.0版本的 Ignite ,下载:https://dist.apache.org/repos/dist/release/incubator/ignite/1.0.0/(安装很容易),然后加入我们的 Apache 社区。如果你有兴趣通过 Ignite 使用 Hadoop, Apache Bigtop 会给你一整套软件,包括无缝的集群部署,它能让你在几分钟之内开启全功能集群。
再透露下:我是 Apache 孵化器 Ignite 项目的导师。
Best regards,
Konstantin Boudnik
On Thursday, April 9, 2015 at 7:39:00 PM UTC-7, Pengfei Xuan wrote:
>
> 我所理解的, Apache Ignite (GridGain) 从传统的成长
Posted by Cos at 18:51
Source:drcos.boudnik.org
来源:http://www.oschina.net/news/62024/apache-ignite-incubating-vs-tachyon
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow
转 Apache Ignite——新一代数据库缓存系统相关推荐
- Apache Ignite——集合分布式缓存、计算、存储的分布式框架
Apache Ignite内存数据组织平台是一个高性能.集成化.混合式的企业级分布式架构解决方案,核心价值在于可以帮助我们实现分布式架构透明化,开发人员根本不知道分布式技术的存在,可以使分布式缓存.计 ...
- java模拟数据库压测_java模拟数据库缓存
实现缓存一些数据到本地,避免重复查询数据库,对数据库造成压力,代码如下: package threadLock; import java.util.HashMap; import java.util. ...
- mybatis缓存二级缓存_MyBatis缓存与Apache Ignite的陷阱
mybatis缓存二级缓存 一周前,MyBatis和Apache ignite 宣布支持apache ignite作为MyBatis缓存(L2缓存). 从技术上讲,MyBatis支持两个级别的缓存: ...
- MyBatis缓存与Apache Ignite的陷阱
一周前,MyBatis和Apache ignite 宣布支持apache ignite作为MyBatis缓存(L2缓存). 从技术上讲,MyBatis支持两个级别的缓存: 本地缓存,默认情况下始终启用 ...
- Apache Ignite,Hazelcast,Cassandra和Tarantool之间的主要区别
Apache Ignite在世界范围内得到广泛使用,并且一直在增长. 诸如Barclays,Misys,Sberbank(欧洲第三大银行),ING,JacTravel之类的公司都使用Ignite来增强 ...
- 分布式数据库缓存的基本概念?MemCache和redis的详细比较?
分布式数据库缓存指的是在高并发环境下,为了减轻数据库压力和提高系统响应时间,在数据库系统和应用系统之间增加的独立缓存系统. 目前市场上常见的数据库缓存系统是MemChace和Redis,他们的主要区别 ...
- Apache Cassandra和Apache Ignite:分布式数据库的明智之选
为什么80%的码农都做不了架构师?>>> Apache Cassandra应用广泛,是一个开源的.分布式的.键值存储列模式NoSQL数据库,支撑了很多大公司的关键业务,比如Ne ...
- 订单失效怎么做的_此招一出,数据库压力降低90%,携程机票订单缓存系统实践...
本文转自 | 携程技术 作者简介 Chaplin,携程资深PMO,平时喜欢解决系统相关的问题,包括但不限于分布式/大数据量/性能/体验等,不畏复杂但更喜欢简单.本文旨在分享携程机票后服务订单处理团队, ...
- 订单失效怎么做的_数据库压力降低90%,携程机票订单缓存系统实践
本文旨在分享携程机票后服务订单处理团队,在构建机票订单缓存系统过程中的一些思考总结,希望能给大家一些启发或帮助.通篇分为以下七大部分:背景,瓶颈,选型,架构,方案,优化,总结,文章概要如下图: 一.背 ...
- 订单失效怎么做的_携程技术专家:数据库压力降低90%,订单缓存系统架构实践...
来源:携程技术(ID:ctriptech) 本文旨在分享携程机票后服务订单处理团队,在构建机票订单缓存系统过程中的一些思考总结,希望能给大家一些启发或帮助.通篇分为以下七大部分:背景,瓶颈,选型,架构 ...
最新文章
- SQL Server2008附加数据库之后显示为只读
- linux下安装python3
- 判断点是否在多边形内——射线法
- 微型计算机原理risc,微型计算机原理习题及解答-20210409003329.docx-原创力文档
- 有向图的邻接表描述 c++
- 以links方式安装eclipse插件
- java命令生成jdk文档(jdk文档)-jdk文档是通过命令生成
- MATLAB2016b 下载和安装(亲测)
- 使用命令查看linux编码,如何利用命令查看linux 系统汉字编码
- R语言安装ccgarch_R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
- 秋冬季健康生活小常识
- 断食有什么好处?如何轻松断食?
- Win10开始菜单打不开
- Numpy IO:npy、npz
- java中获取当前时间的代码
- matlab多元方程整数解,matlab多元非线性方程组解法
- 「硬见小百科」 常见电子元器件等效电路汇总
- 郭卓惺:互动课堂的搭建实例及相关领域应用 1
- SpeeDx与罗氏合作推广抗生素耐药检测
- 上传文件 力软_力软敏捷开发框架权限系统,MVC,CRM,OA,APP工作流源码 说明文档齐全【更新至6.1.6.2】...