Python 爬虫基础 - Urllib 模块(1)
Python的一个很广泛的功能就是爬虫。爬虫可以获取我们需要的资料,甚至进行DDos的工具。爬虫现在比较流行的是Scrapy之类的模块,但是在学习这些工具之前,先了解一下Urllib模块,知道他的基本工作原理。
爬虫的基本思路:
扫描获取对应的Url,扫描Url网页的内容,通过正则匹配获取需要的内容进行下载。
Urllib的官方帮助文档
https://docs.python.org/3/library/urllib.request.html
关于Python的基本语法和正则的使用这里就不赘述了。下面直接看实例:
例1 获取取豆瓣的出版社信息,然后把结果写入文本文件和Excel文件
关键其实在于分析HTML页面的标签,这样才能通过正则匹配出来需要的字符串

#!/usr/bin/env python
#! -*- coding:utf-8 -*-
# Author: Yuan Li
import re,urllib.request
print("读取网页中...")#
data=urllib.request.urlopen('https://read.douban.com/provider/all').read().decode('utf8')
pat='<div class=\"name\">(.+?)<\/div>'
result=re.compile(pat).findall(data)
print(result)print("写入文档...")
fp=open('c:\\temp\\publisher.txt','a',encoding='utf8')
for item in result:fp.write(item+"\n")
fp.close()print("写入Excel...")
import xlsxwriter
workbook=xlsxwriter.Workbook('publisher.xlsx')
worksheet=workbook.add_worksheet('出版社')
row=0
col=0
worksheet.write(row,col,'出版社名称')
for item in range(len(result)):row+=1worksheet.write(row,col,result[item])
workbook.close()读取网页中...
['博集天卷', '北京邮电大学出版社', '北京师范大学出版社', '百花洲文艺出版社', '百花文艺出版社', '长江数字', '重庆大学出版社', '东方文萃', '读客图书', '电子工业出版社', '当代中国出版社', '第一财经周刊', '豆瓣阅读同文馆', '豆瓣', '豆瓣阅读', '豆瓣阅读出版计划', '东方巴别塔文化', '凤凰壹力', '凤凰悦世泓文', '凤凰联动', 'Fiberead', '复旦大学出版社', '凤凰雪漫', '果壳阅读', '果麦文化', '广西师范大学出版社', '杭州蓝狮子文化创意股份有限公司', '后浪出版公司', '华东师范大学出版社', '华章数媒', '汉唐阳光', '华文时代', '湖北人民出版社', '华章同人', '华夏盛轩', '海豚出版社', '虹膜出版', '化学工业出版社', '华中科技大学出版社', '湖北科学技术出版社', '黑龙江北方文艺出版社', '华文经典', 'HarperCollins', '聚石文华', '金城出版社', '简书', '今古传奇', '江苏人民出版社', '九州幻想', '科幻世界', '酷威文化', '理想国', '漓江出版社', '磨铁数盟', '宁波出版社', '南方人物周刊', 'ONE·一个', '浦睿文化', '清华大学出版社', '青岛出版社', '《人物》杂志', '人民文学出版社', '人民邮电出版社', '儒意欣欣', '人民东方出版传媒', '人民文学杂志社', '上海九久读书人', '世纪文景', '四川数字出版传媒有限公司', '上海译文出版社', '时代华文', '上海雅众文化', '世纪文睿', '时代华语', '商务印书馆', '生活·读书·新知三联书店', '上海社会科学院出版社', '社会科学文献出版社', '山西春秋电子音像出版社', '时代数联', '陕西人民出版北京分公司', '《书城》杂志', '世图北京', '四川文艺出版社', '上海文艺出版社', '上海人民出版社', '上海交通大学出版社', '斯坦威图书', '上海人民美术出版社', '图灵社区', 'Trajectory', '武汉大学出版社北京分社', '万有图书', '我和豆瓣', '新经典文化电子书', '新星出版社', '新华先锋文化传媒', '雪球', '悬疑世界', '现代出版社', '西南财经大学出版社', '新华出版社', '新华先锋出版科技', '译林出版社', '译言·东西文库', '译言·古登堡计划', '悦读纪', '阳光博客', '悦读名品', '燕山出版社', '阅文集团华文天下', '中信出版社', '中国人民大学出版社', '中作华文', '中国轻工业出版社', '紫图图书', '浙版数媒', '中央编译出版社', '知乎', '中国国家地理图书部', '浙江摄影出版社', '中国经济出版社', '中国青年出版社', '中国民主法制出版社', '中国传媒大学出版社', '中国言实出版社', '浙江大学出版社', '湛庐文化', '浙江文艺出版社', '中华书局']
写入文档...
写入Excel...我们知道在HTTP协议里面,最常用的两个方法就是Get和Post。Get一般通过URl传递参数,一般是刷新页面的时候来获取信息;POST一般是通过form或者Ajax来提交数据。 下面看看两个简单的实例
例2. GET请求,通过百度搜索并返回前5页结果的标题
关键点:分析百度的URL,wd表示是关键字, pn表示是(页码数-1)*10的结果

import urllib.request,re
word= input('请输入关键字:')
#quote的目的是把中文转码成URL能够识别的格式
word=urllib.request.quote(word)
for i in range(1,5):print("page%d"%i)page=(i-1)*10url="https://www.baidu.com/s?wd=%s&pn=%s"%(word,str(page))pat='"title":"(.*)",'data=urllib.request.urlopen(url).read().decode("utf-8")print(len(data))result=re.compile(pat).findall(data)for item in result:print(item)请输入关键字:beanxyz
page1
172165
麻婆豆腐 - 51CTO技术博客 - 领先的IT技术博客
【挨踢人物传】beanxyz:海外8年经历 不为当初的选择后悔 - 51CTO...
beanxyz的微博_微博
PowerShell 抓取网页表格 - 麻婆豆腐 - 51CTO技术博客
PowerShell 多线程的使用 - 麻婆豆腐 - 51CTO技术博客
XenApp / XenDesktop 7.6 初体验一 安装, 配置站点和序列号服务器...例3 POST请求,输出结果
基本思路:通过urllib.parse.urlencode把字典格式的内容转码,通过urllib.request.Request生成一个提交post请求的对象,然后再通过urlopen来进行发送
下面这个例子一般实战里面好像能成功的不多,毕竟太low了,所以为了理解流程,有个非常简单的测试form页面可以试试
import urllib.request,re
url='http://www.iqianyue.com/mypost'
dic={'name':'aaa','pass':'kkk'}
postdata=urllib.parse.urlencode(dic).encode('utf-8')
r=urllib.request.Request(url,postdata)
data=urllib.request.urlopen(r).read().decode('utf-8')
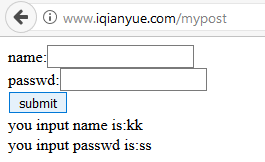
print(data)<html>
<head>
<title>Post Test Page</title>
</head>
<body>
<form action="" method="post">
name:<input name="name" type="text" /><br>
passwd:<input name="pass" type="text" /><br>
<input name="" type="submit" value="submit" />
<br />
you input name is:aaa<br>you input passwd is:kkk</body>
</html>例4 爬虫的异常处理,爬虫的异常主要是URLError或者HTTPError, 后者是前者的继承类,多了一个code的属性
小技巧:PyCharm里面Ctrl+点击对应的类可以查看源码
class HTTPError(URLError, urllib.response.addinfourl):"""Raised when HTTP error occurs, but also acts like non-error return"""__super_init = urllib.response.addinfourl.__init__def __init__(self, url, code, msg, hdrs, fp):self.code = codeself.msg = msgself.hdrs = hdrsself.fp = fpself.filename = url我们可以直接使用URLError 然后根据结果判定是否是HTTPError或者是其他的Error
比如我直接去打开Nagios的页面,因为没有提供用户名和密码,所以直接拒绝访问
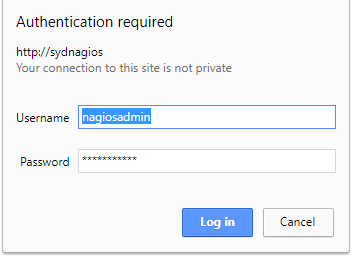
import urllib.request,urllib.error
try:urllib.request.urlopen('http://sydnagios/nagios')
except urllib.error.URLError as e:if hasattr(e,'code'):print(e.code)if hasattr(e,'reason'):print(e.reason)401
UnauthorizedPython 爬虫基础 - Urllib 模块(1)相关推荐
- Python爬虫进阶——urllib模块使用案例【淘宝】
Python爬虫基础--HTML.CSS.JavaScript.JQuery网页前端技术 Python爬虫基础--正则表达式 Python爬虫基础--re模块的提取.匹配和替换 Python爬虫基础- ...
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- Python爬虫【urllib模块】
通用爬虫 爬虫的一般流程 1 初始化一批URL,将这些URL放入队列 2 从队列中取出这些URL,通过DNS解析IP,对IP对应的网站下载HTML页面,保存到本地服务器中,爬取完的URL放到已爬取队列 ...
- pythonurllib模块-python爬虫之urllib模块和requests模块学习
今天学习了request模块和urllib模块,了解到这两个模块最大的区别就是在爬取数据的时候连接方式的不同.urllb爬取完数据是直接断开连接的,而requests爬取数据之后可以继续复用socke ...
- python爬虫基础(一)~爬虫概念和架构
目录 1. 爬虫 1.1 概念 1.2 分类 2. 爬虫架构 2.1 url管理器 2.2 网页(html)下载(download)器 2.2.1 urllib下载html源码 2.2.2 reque ...
- python爬虫基础-requests库
python爬虫基础-requests库 python爬虫 1.什么是爬虫? 通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程. 注意:浏览器抓取的数据对应的页面是一个完整的页面. 为什 ...
- Urllib2库丨Python爬虫基础入门系列(12)
提示:文末有福利!最新Python爬虫资料/学习指南>>戳我直达 文章目录 前言 Urllib2库 学习目的 urlopen GET请求方式 利用urllib2.Request类,添加He ...
- python爬虫用urllib还是reques,python爬虫中urllib.request和requests有什么区别?
在学习python爬虫,想要检索request相关内容时,往往会出现urllib.request和requests这两个词,urllib.request和requests都是python爬虫的模块,其 ...
- python基础知识整理-python爬虫基础知识点整理
首先爬虫是什么? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 根据我的经验,要学习Python爬虫 ...
最新文章
- 编程软件python下载-python 2.7官方版
- windows server2008R2 64位 配置 mysql-8.0.15-winx64
- Icarus Verilog与GTKWave简介及其下载安装
- php composer 安装,composer安装的方法步骤(图文)
- mysql --explicit_【MySQL】 explicit_defaults_for_timestamp 参数解析
- 微软文本检索_如何在Microsoft Word中引用其他文档中的文本
- 使用datepickerdialog提示is undefined错误_23.5 使用视图
- Membership三步曲之入门篇 - Membership基础示例
- Android数字签名机制和应用场景
- vue 圆形百分比进度条_vue圆形进度条
- ModifyStyle()调用不起作用
- 2022全年PMP考证时间表(预估)收藏版
- java 裁剪 pdf_java拆分pdf文档
- 半波耦合器的设计——RSOFT
- whois域名查询工具在线使用
- Salesforce Sales Cloud 零基础学习(四) Chatter
- Shell 循环检查的格式
- 【Javascript的基本知识——数据的流程和流程的切割】
- 无源领域自适应:Source Hypothesis Transfer for Unsupervised Domain Adaptation
- Java 中的三目运算符