(翻译)Pachyderm介绍-建造一个现代的Hadoop
背景
最近在调研时发现了Pachyderm这个项目,感觉他们做的工作挺有意思的。Pachyderm将Docker和Hadoop联合起来,旨在使得大数据分析的过程更加便捷,众多非Java语言的工具也可以方便的使用到大数据的分析中来,并在HDFS的基础上增加了版本控制,使得数据可以进行增量分析。我在Medium上看到一篇相关介绍,讲的比较详细,原文是英文的,因此翻译下来分享一下,也方便自己之后的查阅。 原文链接 Let’s Build a modern Hadoop
我的个人博客 http://www.wangjialong.cc
翻译正文
让我们建造一个现代的Hadoop
我承诺,这不仅仅是另一个Hadoop的激情演说
如果你做过大数据的相关工作,那么你很可能已经感受到Hadoop带来的烦恼。但我们仍然坚持使用它,因为我们告诉自己:“这就是Hadoop作为基础设施软件必须工作的方式”。然而,在过去的十年内,像NoSQL数据库,分布式部署工具,云计算等工具,都随着量级的由小到大产生了很大的改进。为什么大数据分析软件就要被远远甩在身后?是什么让Redis,Docker和CoreOS看起来那么年轻和酷炫而Hadoop却如此老迈?
Hadoop是一个不可挽回的分裂的生态
现代开源项目信奉Unix的哲理——“做一件事,把它做到极致,并能和其他相关的工具结合使用”。上面提到的每一个项目,从创建伊始,就有一个清晰的创建者,培养着一个健康的生态并给予项目正确的方向和目标。在一个蓬勃的生态中,每个部分都流畅的集成在一起以给开发者提供弹性的可结合的技术栈。
Hadoop从来没有考虑过这些。它像是一匹野马,被释放在一片旷野之上,没有缰绳也没有方向。每一个主要的Hadoop用户都必须自己增加丢失的功能。有一些被回馈给了社区,但很多并没有。Facebook大概是Hadoop世界中最大的使用者。他们六年前(根据文章的时间,推算为2009年)fork出Hadoop并将他们的改进版本闭源。
这不是一个现代开源项目应当工作的方式。我认为是时候创造一个现代的Hadoop了,那也是我们对于Pachyderm的期许。Pachyderm是一个架构在现代工具上的全新的存储和计算引擎。最大的好处就是我们得以使用开源基础设施中令人惊叹的功能,比如Docker和Kubernetes。
这也是为什么我们在数量级上比Hadoop好的原因。Pachyderm只关注数据分析平台而对于其他部分,我们使用强大的成品工具。当Hadoop出来的时候,他们需要自己建造每一个轮子,但我们不需要。文章接下来我们对于现在数据分析技术栈的设计蓝图。Pachyderm现在还很年轻,开源项目需要健康的讨论以不断的提高。请分享你的观点并帮助我们建造Pachyderm
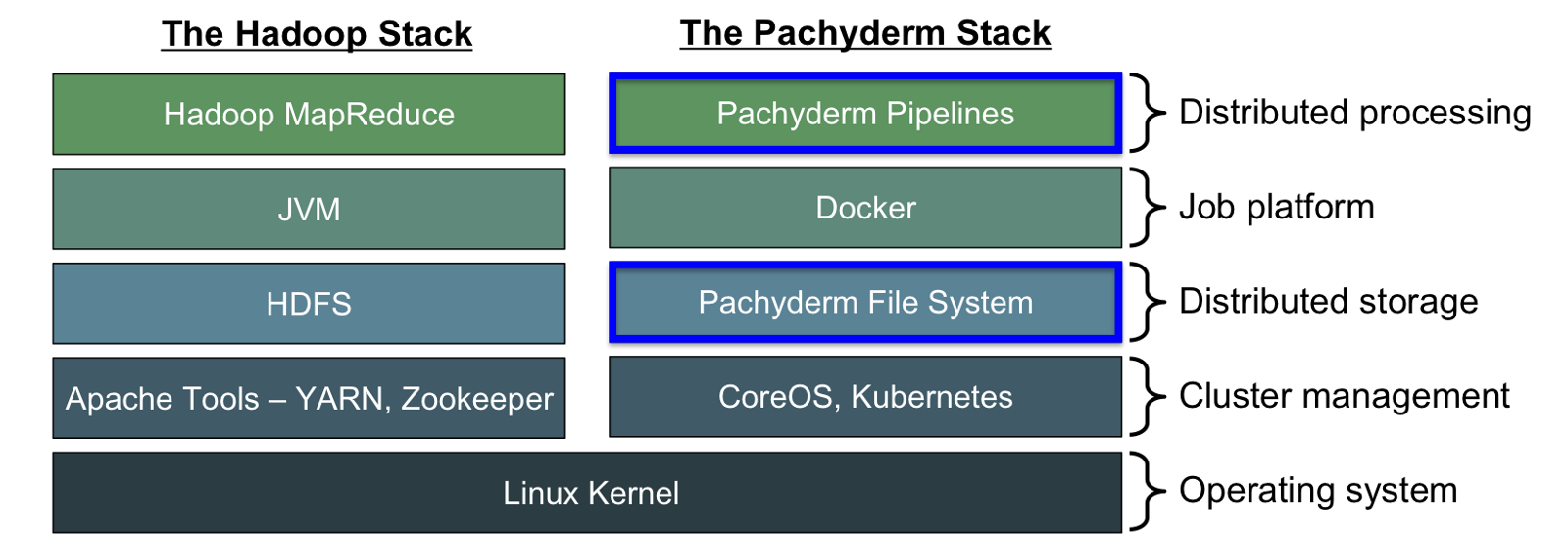
注意: Hadoop生态已经形成十多年了,因此是很成熟的。Pachyderm要拥有每一个相应的替代品(如Hive,Pig)之后,才能完美使用。上图仅仅比较两者都有的功能,像分布式文件系统,计算框架等。
分布式计算
在Hadoop中,MapReduce的任务只能是Java的。这对于Java专家来说OK,但不适用与任何人。现在有很多解决方法使用的不是Java,比如Hadoop Streaming。但是通常来说,如果你要广泛的使用Hadoop,那么你最好使用Java或者Scala。
任务管道在分布式计算中经常是一个挑战。当Hadoop MapReduce显示正在运行的Jobs时,它原生不支持任何Job pipeline的标识(DAG).有很多的任务调度工具在解决这个问题上获得了不同程度的成功(比如 Chronos, Oozie, Luigi, Airflow),但最终,公司选择整合第三方工具并自己添加功能。整合自己的代码和外部工具的任务成为一件让人头疼的事情。
Pachyderm Pipelines与此正好相反。在Pachyderm中为了处理数据,你只需要简单的创建一个容器化的应用将其读写到本地文件系统上即可。你可以使用任何你想要的工具因为它是跑在一个容器中的。Pachyderm将会使用一个FUSE存储卷把数据注入到你的容器中,之后自动的复制这个容器,并展示给每个容器不同的数据块。通过这项技术,Pachyderm可以并行的扩展任何你写的代码来处理大量的数据集。再也没有Java和JVM的什么事了,只要使用你最爱的编程语言写数据处理逻辑就可以了。如果你的代码可以跑在Docker上,你就可以使用它来做数据分析。
Pachyderm也会为所有的任务和他们的依赖创建一个DAG。DAG自动的调度pipeline使得每个任务等待他们的依赖完成之后运行。Pachyderm中的每个部分互相通知不同之处,因此它们准确的知道哪些数据改变了以及pipeline中的哪个子集需要重启。
Job执行平台
将Docker和JVM进行比较是有一点难度的,我们将它们分类为“job platform”,因为他们定义了job的输入格式。
JVM是Hadoop生态的骨干,如果你想要在Hadoop之上建造点什么,你要么需要用Java写要么需要一个特定的工具来将你原来的代码转换过去。Hive是一个HDFS的SQL_like接口,是目前为止最受欢迎且支持度最高的。也有常用的第三方库,比如图像处理,但是他们通常很不标准且不经常维护。如果你尝试做一些复杂的事情,比如说分析象棋比赛,通常你需要结合很多第三方工具,统一使用。
Docker则大不一样,它完全不依赖任何的语言和库。你不用局限于JVM指定的工具,只需要使用那些库并把他们打包进Docker即可。比如,你可以使用npm install opencv来做PB级的计算机视觉任务!工具可以使用任何语言来编写,它非常容易被整合进Pachyderm的技术栈里。
最后,Pachyderm数据分析管道是可插拔和共享的。因为每个部分都是在容器里,它可以保证在不同的集群和数据集上运行一个可预测的环境。就像某人可以从Docker Hub上pull下来镜像,并立即使用在生产环境中,也可以通过镜像创建一个自然语言处理的容器。它的工作不依赖任何基础设施。那就是我们通过Pachyderm pipeline想要做的事。
分布式存储
HDFS是Hadoop生态中最稳定和鲁棒的一个了。它非常适用于分布式的存储大量的数据集,但是缺乏协作。大规模的数据分析和流水线是一个天然的合作结果,但是HDFS从来不是被设计成用于并发的。相反,它防止用户之间产生任何影响。如果有人改变了管道的输入流,很容易导致一个任务失败或者改变。每个公司使用不同的方式解决这个问题。有时候的方法是单纯的使得每个用户得到数据的一份拷贝,而这需要大量的额外存储空间。
Pachyderm File System(PFS)是一个分布式文件系统,它受git的启发。在一个空间中,Pfs给予你数据的完全版本控制。整个文件系统是基于commit的,这意味着你拥有数据的每一个版本。就像git那样,Pachyderm提供了分支功能,允许每个用户有他自己的完全独立的数据分支。用户可以无所顾忌的使用自己的文件,而不需考虑会影响到其他的用户。
Pfs使用对象存储你的数据(S3, GCS, Ceph)。你不需要担心把数据交给全新的技术是否安全。相反,你得到所有你之前习惯的冗余和一致性保证,但使用的是Pachyderm的数据管理特性。
数据的版本控制也是和管道系统高度协作的。Pachyderm了解你的数据怎样变化,因此,当新的数据进来时,你可以仅仅在变化的那部分数据上运行你的任务,而不需要读取整个文件。这不仅使得集群性能大幅提高,而且使得Pachyderm的批处理和流处理没有任何区别,相同的代码可以支持两种操作。
集群管理
集群管理层帮助你管理存储数据和执行任务的机器。
在Hadoop中,两个主要的工具是YARN和Zookeeper。YARN用于任务调度和资源管理,Zookeeper则提供了配置信息的强一致性。在Hadoop概念中,没有太好的其他工具解决这些问题,所以Hadoop是强烈依赖YARN和Zookeeper的。这两个工具早期促成了Hadoop的成功,但现在却成为了新特性的重要障碍。模块化的缺失,毫无疑问是Hadoop最大的缺点。
Pachyderm遵循了Docker的哲学——“包含电池,但可以移除”。我们聚焦于把大数据分析做到最好,其他的部分全部使用现成的组件。我们选择Kubernetes用于集群管理,选择Docker用于容器化,但他们都可以使用其他的组件替换。
在Pachyderm技术栈中,集群管理使用Kubernetes和CoreOS的工具etcd。他们的功能是类似于YARN和Zookeeper的。Kubernetes是一个调度者,根据资源的可用性来调度服务。Etcd是一个容错的分布式数据库用于存放配置信息并在网络分裂后进行节点的管理。如果一个节点挂掉了,Etcd注册这个信息并使得Kubernetes重新手机节点的进程。其他的集群管理工具如Mesos,可以用于替代CoreOS和Kubernetes,但没有被正式的支持。
使用现成的工具有两大好处。第一,它节省了我们“重复造轮子”的时间并且给了我们很好的抽象和剥离。第二,Etcd和Kubernetes本身就是模块化的,因此它们也支持其他的部署方案。
操作系统
两个技术栈都是运行在Linux之上的。
结束语
可扩展,分布式是数据分析软件的重要基本特性。现代的Web公司收集持续不断的数据用于制定面向数据的决策。世界需要一个现代的开源软件,Hadoop的过时已经成为数据驱动时代的负担,是时候让我们的数据分析工具来拥抱未来了。
我的感想
通读下来后,原作者对于Hadoop的一些弊端的论述我是很难理解的(我就觉得Zookeeper挺优秀的啊,为什么要换~~~),毕竟我的水平太低o(╥﹏╥)o,但作者的一些观点还是很新颖的,比如借鉴Git来改进文件系统,使用数据的增量进行数据分析等。Docker和Hadoop都是很牛的项目,期待他们的碰撞会迸发怎样的火花 ^_^
翻译不易,转载请注明出处 Thanks♪(・ω・)ノ
(翻译)Pachyderm介绍-建造一个现代的Hadoop相关推荐
- css游戏代码_介绍CSSBattle-第一个CSS代码搜寻游戏
css游戏代码 by kushagra gour 由kushagra gour 介绍CSSBattle-第一个CSS代码搜寻游戏 (Introducing CSSBattle - the first ...
- Hadoop介绍及最新稳定版Hadoop 2.4.1下载地址及单节点安装
Hadoop介绍 Hadoop是一个能对大量数据进行分布式处理的软件框架.其基本的组成包括hdfs分布式文件系统和可以运行在hdfs文件系统上的MapReduce编程模型,以及基于hdfs和MapR ...
- 建造一个自平衡机器人
index 第1部分:简介 1.1 简要概述 1.2 所需组件 必要: 可选的: 第2部分:加速度计和陀螺仪传感器 2.1 确定要使用的陀螺仪模块 2.2 Accel-Gyro模块入门 2.3 标记 ...
- 介绍计算机硬件的英语作文带翻译,自我介绍作文之英语作文自我介绍带翻译(35页)-原创力文档...
英语作文自我介绍带翻译 [篇一:英文版自我介绍翻译(共4篇)] 篇一:面试用英语自我介绍怎么说 面试用英语自我介绍怎么说? 面试过程中自我介绍是在所难免的,中文自我介绍尚且难倒了很多人,更 何况是英文 ...
- 如何建造一个高效的求职攻略
如何建造一个高效的求职攻略 这篇文章将分享我的求职经验.如果你对自己不够自信,或者不知道如何在求职道路中前进,那么以下内容或许会对你有帮助.本文将聚焦在软件研发领域来展开,然而其中的方法也适用于其它行 ...
- 《MINECRAFT我的世界 新手完全攻略(第3版)》一2.4 建造一个工作台
本节书摘来异步社区<MINECRAFT我的世界 新手完全攻略(第3版)>一书中的第2章,第2.4节,作者: [澳]Stephen O'Brien 译者: 相世杰 责编: 赵轩,更多章节内容 ...
- 介绍微软一个罕为人知的无敌命令
介绍微软一个罕为人知的无敌命令问:怎么才能关掉一个用任务管理器关不了的进程?我前段时间发现我的机子里多了一个进程,只要开机就在,我用任务管理器却怎么关也关不了 答1:杀进程很容易,随便找个工具都行.比 ...
- 介绍大家一个很好玩的网站。多人在线flash联机游戏。
介绍大家一个很好玩的网站.多人在线flash联机游戏. http://www.iminlikewithyou.com/ 在首页的左下角可以选择游戏.有炸弹超人(Balloono).putt putt ...
- 【转】游戏设计的秘密——翻译GDC2010 blizzard的一个演讲
游戏设计的秘密--翻译GDC2010 blizzard的一个演讲 转自:http://blog.sina.com.cn/s/blog_62c6329f0100hmia.html 翻译了一篇blizza ...
最新文章
- 8.5-7 mkfs、dumpe2fs、resize2fs
- SAP Commerce Cloud 的本地开发
- Hadoop:pig 安装及入门示例
- 计算机进去pe怎么设置用户,电脑密码怎么设置,教您设置电脑开机密码
- 标准时间校对_光源色灯箱标准原理
- Apache ab并发负载压力测试
- jdbc连接oracle_Oracle数据库性能监控|使用SiteScope 监控Oracle
- 用SAX2方式解析XML
- 【BZOJ 1095】 [ZJOI2007]Hide 捉迷藏 括号序列
- node 请求内网_Nodejs轻松搭建局域网服务器
- 2017会考计算机知识点,高中物理会考知识点考点归纳2017
- 小米手机的专用计算机连接软件,小米手机怎么连接电脑?这些方法值得收藏!...
- 微信自动跳转默认浏览器 微信扫一扫直接打开外部浏览器
- 怎么用计算机弹奏忘羡,《忘羡,钢琴谱》魔道祖师 岚之调(五线谱 钢琴曲 指法)-弹吧|蛐蛐钢琴网...
- office 安装出现安装30088-4(5)错误解决方案
- 概率论得学习整理--番外3:二项式定理和 二项式系数
- Android远程登录Telnet配置
- 树莓派Pico开发板与大功率MOSFET/IGBT器件驱动控制24V直流电机技术实践
- Hadoop 3.X 和 2.X 的常用端口号和配置文件
- choose ,when ,otherwise