循环神经网络 递归神经网络_递归神经网络-第2部分
循环神经网络 递归神经网络
有关深层学习的FAU讲义 (FAU LECTURE NOTES ON DEEP LEARNING)
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
这些是FAU YouTube讲座“ 深度学习 ”的 讲义 。 这是演讲视频和匹配幻灯片的完整记录。 我们希望您喜欢这些视频。 当然,此成绩单是使用深度学习技术自动创建的,并且仅进行了较小的手动修改。 如果发现错误,请告诉我们!
导航 (Navigation)
Previous Lecture / Watch this Video / Top Level / Next Lecture
上一个讲座 / 观看此视频 / 顶级 / 下一个讲座

Welcome back to deep learning! Today we want to talk a little bit more about recurrent neural networks and in particular look into the training procedure. So how does our RNN training work? Let’s look at a simple example and we start with a character level language model. So, we want to learn a character probability distribution from an input text and our vocabulary is going to be very easy. It’s gonna be the letters h, e, l, and o. We’ll encode them as one-hot vectors which then gives us for example for h the vector (1 0 0 0)ᵀ. Now, we can go ahead and train our RNN on the sequence “hello” and we should learn that given “h” as the first input, the network should generate the sequence “hello”. Now, the network needs to know previous inputs when presented with an l because it needs to know whether it needs to generate an l or an o. It’s the same input but two different outputs. So, you have to know the context.
欢迎回到深度学习! 今天,我们想谈论更多有关递归神经网络的知识,尤其是研究训练过程。 那么我们的RNN培训如何工作? 让我们看一个简单的例子,我们从字符级语言模型开始。 因此,我们想从输入文本中学习字符概率分布,并且我们的词汇将非常简单。 它是字母h,e,l和o。 我们将它们编码为一热向量,然后为我们提供例如向量(1 0 0 0)ᵀ。 现在,我们可以继续在序列“ hello”上训练我们的RNN,我们应该学习到给定“ h”作为第一个输入,网络应该生成序列“ hello”。 现在,网络需要在显示l时知道以前的输入,因为它需要知道是否需要生成l或o。 它是相同的输入,但有两个不同的输出。 因此,您必须了解上下文。

Let’s look at this example and here you can already see how the decoding takes place. So, we put in essentially on the input layer again as one-hot encoded vectors the inputs. Then, we produce the hidden state h subscript t with the matrices that we’ve seen previously and produce outputs and you can see. Now, we feed in the different letters and this then produces some outputs that can then be mapped via one-hot encoding back to letters. So, this gives us essentially the possibility to run over the entire sequence and produce the desired outputs. Now, for the training, the problem is how can we determine all of these weights? Of course, we want to maximize these weights with respect to predicting the correct component.
让我们看一下这个例子,在这里您已经可以看到解码是如何进行的。 因此,我们实际上再次将输入作为一热编码矢量输入到输入层。 然后,我们用前面已经看到的矩阵生成隐藏状态h下标t并生成输出,您可以看到。 现在,我们输入不同的字母,然后产生一些输出,然后可以通过一键编码将其映射回字母。 因此,这实际上使我们有可能在整个序列上运行并产生所需的输出。 现在,对于培训而言,问题在于我们如何确定所有这些权重? 当然,我们要在预测正确分量方面最大化这些权重。

This all can be achieved with the backpropagation through time algorithm. The idea is we train on the unfolded network. So here’s a short sketch on how to do this. The idea is that we unfold the network. So, we compute the forward path for the full sequence and then we can apply the loss. So, we essentially then backpropagate over the entire sequence such that even things that happen in the very last state can have an influence on the very beginning. So, we compute the backward pass through the full sequence to get the gradients and the weight update. So, for one update with backpropagation through time, I have to unroll this complete network that then is generated by the input sequence. Then, I can compare the output that was created with the desired output and compute the update.
所有这些都可以通过时间反向传播算法来实现。 我们的想法是在不断扩展的网络上进行训练。 因此,这是一个简短的草图。 这个想法是我们展开网络。 因此,我们计算整个序列的前向路径,然后可以应用损耗。 因此,我们实质上是在整个序列上反向传播,这样,即使是在最后状态下发生的事情也可能对一开始产生影响。 因此,我们计算整个序列的反向传递,以获得梯度和权重更新。 因此,对于一次使用反向传播的更新,我必须展开由输入序列生成的完整网络。 然后,我可以将创建的输出与所需的输出进行比较,并计算更新。

So, let’s look at this in a little bit more detail. The forward pass is, of course, just the computation of the hidden states and the output. So, we know that we have some input sequence that is x subscript 1 to x subscript T, where T is the sequence length. Now, I just repeat update our u subscript t which is the linear part before the respective activation function. Then, we compute the activation function to get our new hidden state then we compute the o subscript t which is essentially the linear part before the sigmoid function. Then, we apply the sigmoid to produce the y hat that is essentially the output of our network.
因此,让我们更详细地看一下。 当然,前向通过只是隐藏状态的计算和输出。 因此,我们知道我们有一些输入序列,即x下标1到x下标T,其中T是序列长度。 现在,我只是重复更新我们的u下标t,它是相应激活函数之前的线性部分。 然后,我们计算激活函数以获得新的隐藏状态,然后计算o下标t,它实际上是S型函数之前的线性部分。 然后,我们应用S形来产生y hat,这实际上是网络的输出。

If we do so, then we can unroll the entire network and produce all of the respective information that we need to then actually compute the update for the weights.
如果这样做,那么我们可以展开整个网络并生成我们需要的所有相应信息,然后实际计算权重的更新。

Now the backpropagation through time then essentially produces a loss function. Now, the loss function is summing up essentially the losses that we already know from our previous lectures, but we sum it up over the actual observations at every time t. So, we can, for example, take cross-entropy, then we compare the predicted output with the ground truth and compute the gradient of the loss function in a similar way as we already know it. We want to get the parameter update for our parameter vector θ that is composed of those three matrices, the two bias vectors, and the vector h. So, the update of the parameters can then also be done using a learning rate in a very similar way as we have been doing this throughout the entire class. Now, the question is, of course, how do we get those derivatives and the idea is now to go back in time through the entire network.
现在,随时间的反向传播基本上会产生损失函数。 现在,损失函数实质上是对我们先前的讲课中已经知道的损失进行总结,但是我们将其在每个时间t的实际观察值上进行总结。 因此,例如,我们可以采用交叉熵,然后将预测的输出与基本事实进行比较,并以类似于我们已经知道的方式计算损失函数的梯度。 我们想要获取由这三个矩阵,两个偏置向量和向量h组成的参数向量θ的参数更新。 因此,还可以使用学习率来完成参数的更新,这与我们在整个课堂上所做的非常相似。 现在,问题是,当然,我们如何获得这些衍生产品,现在的想法是追溯整个网络。

So what do we do? Well, we start at time t equals T and then iteratively compute the gradients for T up to 1. So just keep in mind that our y hat was produced by the sigma of o subscript t which is composed of those two matrices. So, if we want to compute the partial derivative with respect to o subscript t, then we need the derivative of the sigmoid functions of o subscript t times the partial derivative of the loss function with respect to y hat subscript t. Now, you can see that the gradient with respect to W subscript hy is going to be given as the gradient of o subscript t times h subscript t transpose. The gradient with respect to the bias is going to be given simply as the gradient of o subscript t. So, the gradient hsubscript t now depends on two elements: the hidden state that is influenced by o subscript t and the next hidden state hsubscript t+1. So, we can get the gradient of h subscript t as the partial derivative of h subscript t+1 with respect to hsubscript t transpose times the gradient of h subscript t+1. Then, we still have to add the partial derivative of o subscript t with respect to h subscript t transposed times the gradient of o subscript t. This can then be expressed as the weight matrix W subscript hh transpose times the tangens hyperbolicus derivative of W subscript hh times h subscript t plus Wsubscript xh times x subscript t+1 plus the bias h multiplied with the gradient of h subscript t+1 plus W subscript hy transposed times the gradient of o subscript t. So, you can see that we can also implement this gradient with respect to matrices. Now, you already have all the updates for the hidden state.
那么我们该怎么办? 好吧,我们从时间t等于T开始,然后迭代地计算T的梯度直到1。因此,请记住,我们的y是由o下标t的总和构成的,而o下标t由这两个矩阵组成。 因此,如果要计算关于o下标t的偏导数,则需要o下标t的S形函数的导数乘以关于y hat下标t的损失函数的偏导数。 现在,您将看到相对于W下标hy的梯度将作为o下标t乘以h下标t转置的梯度给出。 相对于偏差的梯度将简单地以o下标t的梯度给出。 因此,梯度h下标t现在取决于两个元素:受o下标t影响的隐藏状态和下一个隐藏状态h下标t + 1。 因此,我们可以得到h下标t的梯度作为h下标t + 1的偏导数相对于h下标t转置乘以h下标t + 1的梯度的偏导数。 然后,我们仍然必须将o下标t的偏导数相对于h下标t的转置乘以o下标t的梯度。 这可以被表示为权重矩阵W标HH转置倍tangens hyperbolicus衍生物W¯¯标HH的倍ħ下标t加W¯¯标XH乘以x下标t + 1加上偏压ħ乘以h的下标t + 1中的梯度加W下标hy转置乘以o下标t的梯度。 因此,您可以看到我们也可以针对矩阵实现此梯度。 现在,您已经具有隐藏状态的所有更新。

Now, we also want to compute the updates for the other weight matrices. So, let’s see how this is possible. We now have established essentially the way of computing the derivative with respect to our h subscript t. So, now we can already propagate through time. So for each t, we essentially get one element in the sum and because we can compute the gradient h subscript t, we can now get the remaining gradients. In order to compute h subscript t, you see that we need the tanh of u subscript t which then contains the remaining weight matrices. So we essentially get the derivative respect to the two missing matrices and the bias. By using the gradient h subscript t times the tangens hyperbolicus derivative of u subscript t. Then, depending on which matrix you want to update, it’s gonna be h subscript t-1 transpose, or x subscript t transpose. For the bias, you don’t need to multiply with anything extra. So, these are essentially the ingredients that you need in order to compute the remaining updates. What we see now is that we can compute the gradients, but they are dependent on t. Now, the question is how do we get the gradient for the sequence. What we see is that the network that emerges in the unrolled state is essentially a network of shared weights. This means that we can update simply by the sum over all time steps. So this then allows us to compute essentially all the updates for the weights and every time t. Then, the final gradient update is gonna be the sum of all those gradient steps. Ok, so we’ve seen how to compute all these steps and yes: It’s maybe five lines of pseudocode, right?
现在,我们还想计算其他权重矩阵的更新。 那么,让我们看看这是怎么可能的。 现在,我们基本上建立了关于我们的h下标t的导数计算方法。 因此,现在我们已经可以随着时间传播。 因此,对于每个t,我们基本上得到一个和,并且因为我们可以计算梯度h下标t,所以现在可以得到其余的梯度。 为了计算h下标t,您看到我们需要u下标t的tanh,然后包含剩余的权重矩阵。 因此,我们从本质上得到了两个缺失矩阵和偏差的导数方面。 通过使用梯度h下标t乘以u下标t的tangens双曲导数。 然后,根据要更新的矩阵,将是h下标t-1转置或x下标t转置。 对于偏见,您不需要乘以其他任何东西。 因此,这些实质上是您计算剩余更新所需的要素。 现在看到的是,我们可以计算梯度,但是它们取决于t。 现在,问题是如何获得序列的梯度。 我们看到的是,处于展开状态的网络实质上是共享权重的网络。 这意味着我们可以简单地按所有时间步长的总和进行更新。 因此,这使我们能够计算出权重和每次t的所有更新。 然后,最终的梯度更新将是所有这些梯度步长的总和。 好的,我们已经了解了如何计算所有这些步骤,是的:可能是五行伪代码,对吗?

Well, there are some problems with normal backpropagation through time. You need to unroll the entire sequence and for long sequences and complex networks, this can mean a lot of memory consumption. A single parameter update is very expensive. So, you could do a splitting approach like the naive approach that we’re suggesting here, but if you would just split the sequence into batches and then start again initializing the hidden state, then you can probably train but you lose dependencies over long periods of time. In this example, the first input can never be connected to the last output here. So, we need a better idea of how to proceed and save memory and, of course, there’s an approach to do so. This is called the truncated backpropagation through time algorithm.
好吧,正常的反向传播会存在一些问题。 您需要展开整个序列,对于较长的序列和复杂的网络,这可能意味着大量的内存消耗。 单个参数更新非常昂贵。 因此,您可以像我们在此建议的天真的方法那样进行拆分,但是如果您只是将序列拆分为批次,然后再次开始初始化隐藏状态,那么您可能可以进行训练,但是长期失去依赖时间。 在此示例中,第一个输入永远无法连接到此处的最后一个输出。 因此,我们需要更好地了解如何继续进行并节省内存,当然,有一种方法可以做到这一点。 这称为通过时间的截短反向传播算法。

Now, the truncated backpropagation through time algorithm keeps the processing of the sequence as a whole, but it adapts the frequency and depth of the updates. So every k₁ time steps, you run a backpropagation through time for k₂ time steps and the parameter update is gonna be cheap if k₂ is small. The hidden states are still exposed to many time steps as you will see in the following. So, the idea is for time t from 1 to T to run our RNN for one step computing h subscript t and ysubscript t and then if we are at the k₁ step, then we run backpropagation through time from T down to t minus k₂.
现在,通过时间截断的反向传播算法可以保持序列的整体处理,但可以适应更新的频率和深度。 因此,每k₁个时间步长,您将对k2个时间步长进行时间反向传播,如果k2很小,参数更新将很便宜。 您将在下面看到,隐藏状态仍然面临许多时间步长。 因此,想法是让时间t从1到T运行我们的RNN,一步计算h下标t和y下标t,然后如果我们处于k₁步骤,那么我们将进行从T到t减去k 2的时间反向传播。 。
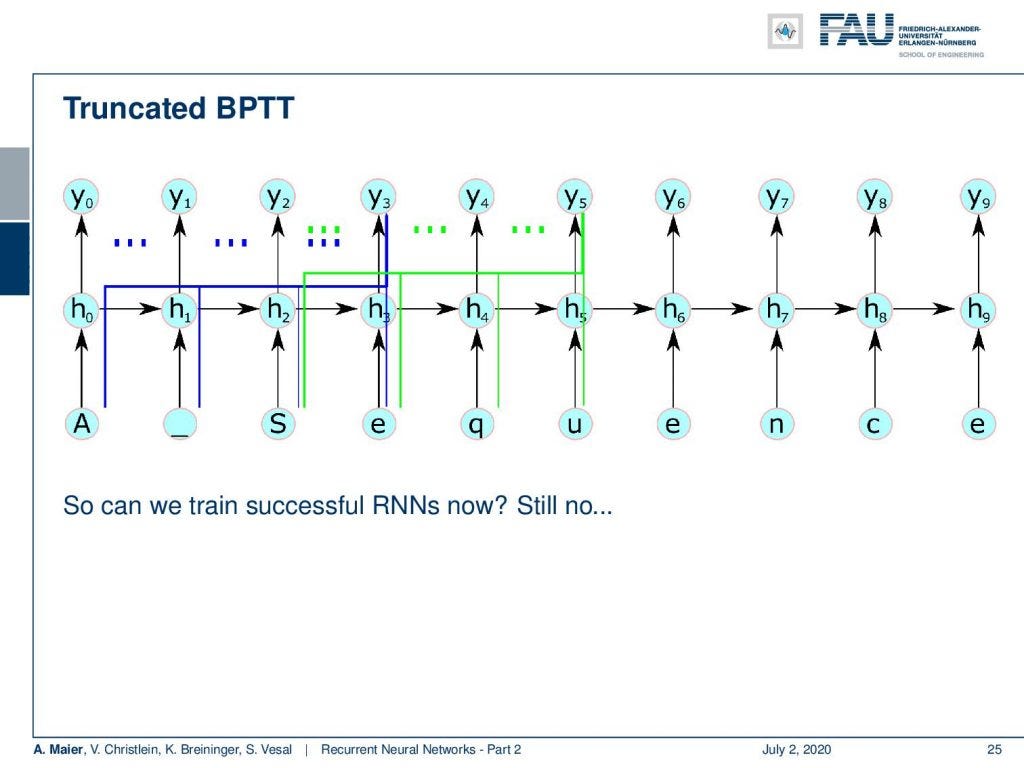
This then emerges in the following setup: What you can see here is that we essentially step over 4 time steps. If we are in the fourth time step, then we can backpropagate through time until the beginning of the sequence. Once we did that, we process ahead and we always keep the hidden state. We don’t discard it. So, we can model this interaction. So, does this solve all of our problems? Well, no because if we have a very long temporal context, it will not be able to update. So let’s say, the first element is responsible for changing something in the last element of your sequence, then you see they will never be connected. So, we are not able to learn this long temporal context anymore. This is a huge problem with long term dependency and basic RNNs.
然后在以下设置中出现:您可以在这里看到的是,我们基本上分了4个时间步长。 如果我们处于第四时间步长,那么我们可以反向传播时间直到序列开始。 一旦做到这一点,我们将继续前进,并始终保持隐藏状态。 我们不会丢弃它。 因此,我们可以对此交互进行建模。 那么,这是否解决了我们所有的问题? 好吧,不是,因为如果我们的时间上下文很长,它将无法更新。 这么说吧,第一个元素负责更改序列的最后一个元素,然后您将看到它们永远不会被连接。 因此,我们不再能够学习这种长时态上下文。 对于长期依赖和基本RNN,这是一个巨大的问题。

So, let’s say you have this long term dependency. You want to predict the next word in “the clouds are in the sky”. You can see that the clouds are probably a relevant context for this. Here, the context information is rather nearby. So, we can encode it in the hidden state rather easily. Now, if we have very long sequences, then it will be much harder because we have to backpropagate over so many steps. You have seen also that we had these problems in deep networks where we had the vanishing gradient problem. We were not able to find updates that connect parts of networks that are very far apart from each other.
因此,假设您具有这种长期依赖性。 您想预测“云在天空”中的下一个单词。 您可以看到云可能与此相关。 在这里,上下文信息就在附近。 因此,我们可以很容易地将其编码为隐藏状态。 现在,如果我们有很长的序列,那么将变得更加困难,因为我们必须在许多步骤中反向传播。 您还已经看到,我们在深度网络中遇到了这些问题,在这些网络中,梯度问题逐渐消失了。 我们找不到连接彼此相距很远的网络部分的更新。

You can see here that if we have this example: a sentence like “I grew up in Germany” and then say something else and “I speak fluent”, it’s probably German. I have to be able to remember that “I grew up in Germany”. So, the contextual information is far away and this makes a difference because we have to propagate through many layers.
您可以在这里看到,如果有这样的例子:诸如“我在德国长大”然后再说其他话和“我说流利”的句子,可能是德语。 我必须记得“我在德国长大”。 因此,上下文信息距离很远,这有所作为,因为我们必须传播许多层。

This means that we have to multiply with each other. You can see that those gradients are prone to vanishing and exploding as by the way identified by Hochreiter and Schmidhuber in [12]. Now, you still have this problem that you could have an exploding gradient. Well, you can truncate the gradient but the vanishing gradient is much harder to solve. There’s another problem the memory overwriting because the hidden state is overwritten in each time step. So detecting long-term dependencies will be even more difficult if you don’t have enough space in your hidden state vector. This is also a problem that may occur in your recurrent neural network. So, can we do better than this? The answer is again: yes.
这意味着我们必须彼此相乘。 您可以看到,按照Hochreiter和Schmidhuber在[12]中指出的方式,这些梯度很容易消失和爆炸。 现在,您仍然有可能会出现爆炸梯度的问题。 好了,您可以截断渐变,但是逐渐消失的渐变很难解决。 内存覆盖还有另一个问题,因为隐藏状态在每个时间步都被覆盖。 因此,如果隐藏状态向量中没有足够的空间,则检测长期依赖项将变得更加困难。 这也是您的循环神经网络中可能发生的问题。 那么,我们能做得更好吗? 答案是:是的。

This is something we will discuss in the next video, where we then talk about long short-term memory units and the contributions that were done by Hochreiter and Schmidhuber.
这是我们将在下一个视频中讨论的内容,然后在其中讨论长短期存储单元以及Hochreiter和Schmidhuber所做的贡献。

So thank you very much for listening to this video and hope to see you in the next one. Thank you and goodbye!
因此,非常感谢您收听此视频,并希望在下一个视频中见到您。 谢谢,拜拜!
If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep LearningLecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced.
如果你喜欢这篇文章,你可以找到这里更多的文章 ,更多的教育材料,机器学习在这里 ,或看看我们的深入 学习 讲座 。 如果您希望将来了解更多文章,视频和研究信息,也欢迎关注YouTube , Twitter , Facebook或LinkedIn 。 本文是根据知识共享4.0署名许可发布的 ,如果引用,可以重新打印和修改。
RNN民间音乐 (RNN Folk Music)
FolkRNN.orgMachineFolkSession.comThe Glass Herry Comment 14128
FolkRNN.org MachineFolkSession.com 玻璃哈里评论14128
链接 (Links)
Character RNNsCNNs for Machine TranslationComposing Music with RNNs
字符RNN CNN用于机器翻译 和RNN组合音乐
翻译自: https://towardsdatascience.com/recurrent-neural-networks-part-2-5f45c1c612c4
循环神经网络 递归神经网络
http://www.taodudu.cc/news/show-1874183.html
相关文章:
- 自动化生产线认知_什么是认知自动化?
- 边缘计算中高效ML的EEoI
- ai/ml_十大ML / AI现实世界项目,以增强您的产品组合
- 循环神经网络 递归神经网络_递归神经网络-第3部分
- 人工智能和金融是天作之合的5个理由
- 好莱坞法则_人工智能去好莱坞
- 什么时候需要档案_需要什么
- 逻辑回归分析与回归分析_逻辑回归从零开始的情感分析
- 构建ai数据库_为使用AI的所有人构建更安全的互联网
- 社会达尔文主义 盛行时间_新达尔文主义的心理理论
- 两种思想
- 强化学习推荐系统_推荐人系统:价值调整,强化学习和道德规范
- ai带来的革命_AI革命就在这里。 这与我们预期的不同。
- 卷积神经网络解决拼图_使用神经网络解决拼图难题
- 通用逼近定理证明_通用逼近定理:代码证明
- ai人工智能的本质和未来_人工智能如何塑造音乐产业的未来
- 机器学习指南_管理机器学习实验的快速指南
- 强化学习与环境不确定_不确定性意识强化学习
- 部署容器jenkins_使用Jenkins部署用于进行头盔检测的烧瓶容器
- 贝叶斯网络 神经网络_随机贝叶斯神经网络
- 智能机器人机器人心得_如果机器人说到上帝
- 深度前馈神经网络_深度前馈神经网络简介
- 女人在聊天中说给你一个拥抱_不要提高技能; 拥抱一个机器人
- 机器学习中特征选择_机器学习中的特征选择
- 学术会议查询 边缘计算_我设计了可以预测边缘性的“学术不诚实”的AI系统(SMART课堂)...
- 机器学习 深度学习 ai_用AI玩世界末日:深度Q学习的多目标优化
- 学习自动驾驶技术 学习之路_一天学习驾驶
- python 姿势估计_Python中的实时头姿势估计
- node-red 可视化_可视化和注意-第4部分
- 人工智能ai算法_AI算法比您想象的要脆弱得多
循环神经网络 递归神经网络_递归神经网络-第2部分相关推荐
- 人工神经网络心得体会_人工神经网络
内容介绍 原文档由会员 天缘 发布 人工神经网络 页数 44 字数 22434 摘要 人工神经网络是由一些类似人脑神经元的简单处理单元相互连接而成的复杂网络.已涌现出许多不同类型的ANN及相应的学习算 ...
- 递归函数非递归化_递归神秘化
递归函数非递归化 by Sachin Malhotra 由Sachin Malhotra 递归神秘化 (Recursion Demystified) In order to understand re ...
- 递归 尾递归_递归,递归,递归
递归 尾递归 by Michael Olorunnisola 通过Michael Olorunnisola 递归,递归,递归 (Recursion, Recursion, Recursion) Bef ...
- java 递归 尾递归_递归和尾递归
C允许一个函数调用其本身,这种调用过程被称作递归(recursion). 最简单的递归形式是把递归调用语句放在函数结尾即恰在return语句之前.这种形式被称作尾递归或者结尾递归,因为递归调用出现在函 ...
- 易语言神经网络验证码识别_递归神经网络 GRU+CTC+CNN 教会验证码识别
利用 NLP 技术做简单数据可视化分析 Chat 简介: 用递归神经网络采用端到端识别图片文字,递归神经网络大家最早用 RNN ,缺陷造成梯度消失问题:然后采用了 LSTM,解决 RNN 问题,并且大 ...
- 利用循环神经网络生成唐诗_进化神经网络基本概念入门
深入介绍了神经进化,其理论基础和该领域的标志性研究. 这篇博客文章是我关于该主题的系列文章中的第一篇文章. 神经进化是一种机器学习技术,可通过进化算法生成越来越好的拓扑,权重和超参数,从而改善作为人工 ...
- python神经网络预测股票_用神经网络预测股票市场
作者:Vivek Palaniappan 编译:NumberOne 机器学习和深度学习已经成为定量对冲基金常用的新的有效策略,以最大化其利润.作为一名人工智能和金融爱好者,这是令人激动的消息,因为它结 ...
- 神经网络 目标跟踪_图神经网络的多目标跟踪
神经网络 目标跟踪 Multiple object tracking(MOT) is the task of studying object appearance and movements to a ...
- python bp神经网络 异或_【神经网络】BP算法解决XOR异或问题MATLAB版
第一种 %% %用神经网络解决异或问题 clear clc close ms=4;%设置4个样本 a=[0 0;0 1;1 0;1 1];%设置输入向量 y=[0,1,1,0];%设置输出向量 n=2 ...
- 人工神经网络心得体会_卷积神经网络学习心得
萌新小白一只,刚刚接触AI,在遍历人工智能发展时就看到了"卷积神经网络",顿时想到了去年被概率论支配的恐惧,因此想在这里分享一点经验来帮助大家更好理解. 所谓"卷积神经网 ...
最新文章
- 只因接了一个电话,程序员被骗 30 万!
- 远程扫描iPhone相册?苹果的好心网友不领情
- python subprocess.Popen 使用简介
- hdu5491(2015合肥网络赛H题)
- php读取mysql数据无法修改时间_php设置mysql查询读取数据的超时时间
- B2C全开源无加密单商户商城源码可二开双端自适应
- Python项目:用微信自动给女朋友每天一句英语问候
- bat命令运行java程序
- 正则表达式基础知识(转)
- SQLServer数据库写入操作时报错:not all arguments converted during string formatting 问题解决
- java烟花代码详细步骤,一文说清!
- 开源人物之九:赖霖枫
- MindSpore布道师招募计划,开启AI的信仰之跃
- Java实现Socket网络聊天室
- 360卫士锁定IE主页之更换主页
- 【coolshell酷壳】你可能不知道的Shell
- 《金融学从入门到精通》读书摘记
- 分享机器学习入门课件
- Java小游戏——五子棋
- 将AS中Module编译成JRA包引用