knn 机器学习_机器学习:通过预测意大利葡萄酒的品种来观察KNN的工作方式
knn 机器学习
Introduction
介绍
For this article, I’d like to introduce you to KNN with a practical example.
对于本文,我想通过一个实际的例子向您介绍KNN。
I will consider one of my project that you can find in my GitHub profile. For this project, I used a dataset from Kaggle.
我将考虑可以在我的GitHub个人资料中找到的我的项目之一。 对于这个项目,我使用了Kaggle的数据集。
The dataset is the result of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars organized in three classes. The analysis was done by considering the quantities of 13 constituents found in each of the three types of wines.
该数据集是对意大利同一地区种植的葡萄酒进行化学分析的结果,这些葡萄酒来自三个不同类别的三个品种。 通过考虑三种葡萄酒中每种葡萄酒中13种成分的数量来进行分析。
This article will be structured in three-part. In the first part, I will make a theoretical description of KNN, then I will focus on the part about exploratory data analysis in order to show you the insights that I found and at the end, I will show you the code that I used to prepare and evaluate the machine learning model.
本文将分为三部分。 在第一部分中,我将对KNN进行理论上的描述,然后,我将重点介绍探索性数据分析这一部分,以便向您展示我发现的见解,最后,我将向您展示我曾经使用过的代码准备和评估机器学习模型。
Part I: What is KNN and how it works mathematically?
第一部分:什么是KNN及其在数学上的作用?
The k-nearest neighbour algorithm is not a complex algorithm. The approach of KNN to predict and classify data consists of looking through the training data and finds the k training points that are closest to the new point. Then it assigns to the new data the class label of the nearest training data.
k最近邻居算法不是复杂的算法。 KNN预测和分类数据的方法包括浏览训练数据并找到最接近新点的k个训练点。 然后,它将新的训练数据的类别标签分配给新数据。
But how KNN works? To answer this question we have to refer to the formula of the euclidian distance between two points. Suppose you have to compute the distance between two points A(5,7) and B(1,4) in a Cartesian plane. The formula that you will apply is very simple:
但是KNN是如何工作的? 要回答这个问题,我们必须参考两点之间的欧几里得距离的公式。 假设您必须计算笛卡尔平面中两个点A(5,7)和B(1,4)之间的距离。 您将应用的公式非常简单:
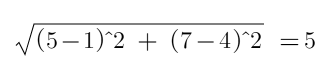
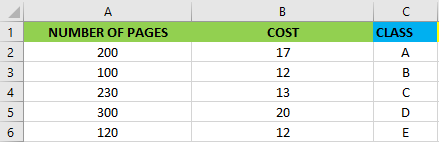
Okay, but how can we apply that in machine learning? Imagine to be a bookseller and you want to classify a new book called Ubick of Philip K. Dick with 240 pages which cost 14 euro. As you can see below there are 5 possible classes where to put our new book.
好的,但是我们如何将其应用到机器学习中呢? 想象成为一个书商,您想对一本名为Philip K. Dick的Ubick的新书进行分类,共有240页,售价14欧元。 如您在下面看到的,有5种可能的类别可用于放置我们的新书。
To know which is the best class for Ubick we can use the euclidian formula in order to compute the distance with each observation in the dataset.
要知道哪个是Ubick的最佳分类,我们可以使用欧几里得公式来计算数据集中每个观测值的距离。
Formula:
式:

output:
输出:
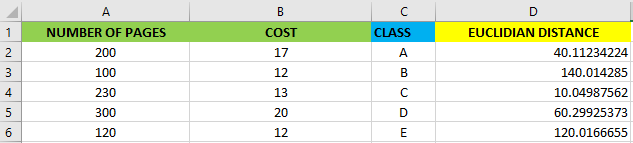
As you can see above the nearest class for Ubick is class C.
如您所见,Ubick最近的课程是C类 。
Part II: insights that I found to create the model
第二部分:我发现的创建模型的见解
Before to start to speak about the algorithm, that I used to create my model and predict the varieties of wine, let me show you briefly the main insights that I found.
在开始谈论算法之前,我曾用它来创建模型并预测葡萄酒的种类,然后让我简要地向您展示我发现的主要见解。
In the following heatmap, there are correlations between the different features. This is very useful to have a first look at the situation of our dataset and knowing if it is possible to apply a classification algorithm.
在下面的热图中,不同功能之间存在关联。 首先了解一下数据集的情况,并了解是否有可能应用分类算法,这非常有用。
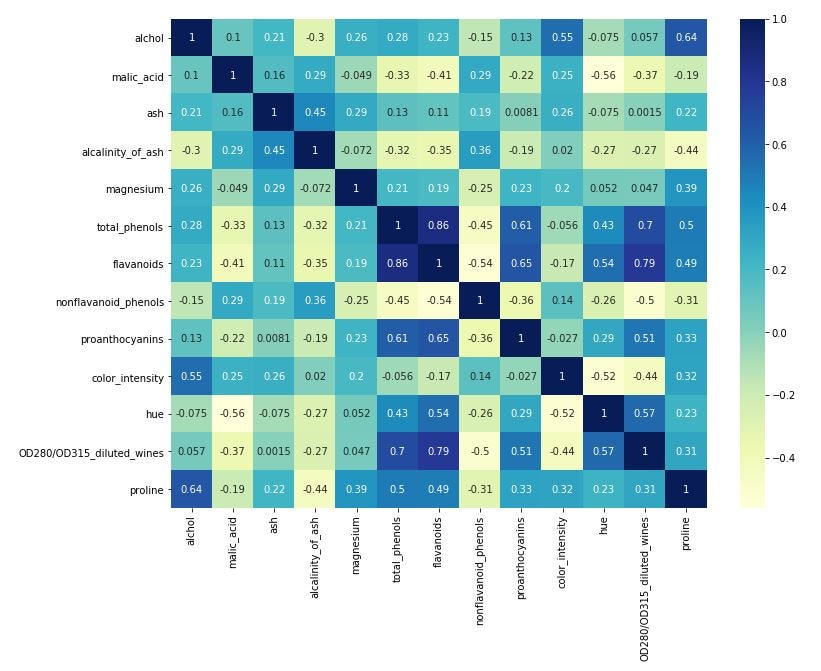
The heatmap is great for a first look but that is not enough. I’d like also to know if there are some elements whose absolute sum of correlations is low in order to delete them before to train the machine learning model. So, I construct a histogram as you can see below.
该热图乍一看很棒,但这还不够。 我还想知道是否存在某些元素的相关绝对和很低,以便在训练机器学习模型之前将其删除。 因此,如下图所示,我构建了一个直方图。
You can see that there are three elements with low total absolute correlation. The elements are ash, magnesium and the color_intensity.
您会看到三个绝对绝对相关性较低的元素。 元素是灰,镁和color_intensity。
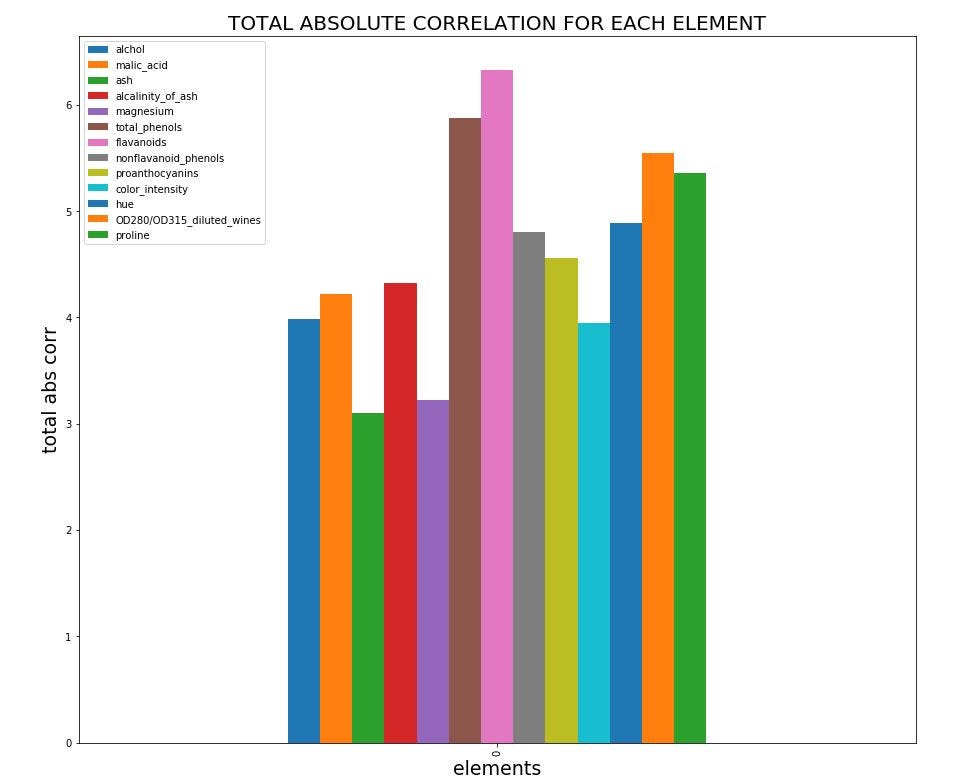
Thanks to these observations now we are sure that there is the possibility to apply a KNN algorithm to create a predictive model.
现在,由于这些观察,我们确信可以应用KNN算法创建预测模型。
Part III: use scikit-learn to make predictions
第三部分:使用scikit-learn进行预测
In this part, we will see how to prepare the model and evaluate it thanks to scikit-learn.
在这一部分中,我们将借助scikit-learn了解如何准备模型并进行评估。
Below you can observe that I split the model into two parts: 80% for training and 20% for testing. I chose this proportion because the data set is not big.
在下面,您可以看到我将模型分为两个部分:80%用于训练,20%用于测试。 我选择此比例是因为数据集不大。
# split data to train and test
y = df['class']
X = input_data.drop(columns=['ash','magnesium', 'color_intensity'])X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state=0)# to be sure that the data was split rightly (80% for train data and 20% for test data)print("X_train shape: {}".format(X_train.shape))
print("y_train shape: {}".format(y_train.shape))print("X_test shape: {}".format(X_test.shape))
print("y_test shape: {}".format(y_test.shape))out:
出:
X_train shape: (141, 10)y_train shape: (141,)X_test shape: (36, 10)y_test shape: (36,)You have to know that all machine learning models in scikit-learn are implemented in their own classes. For example, the k-nearest neighbors classification algorithm is implemented in the KNeighborsClassifier class.
您必须知道scikit-learn中的所有机器学习模型都是在各自的类中实现的。 例如,在KNeighborsClassifier类中实现了k最近邻居分类算法。
The first step is to instantiate the class into an object that I called cli as you can see below. The object contains the algorithm that I will use to build the model from the training data and make predictions on new data points. It contains also the information that the algorithm has extracted from the training data.
第一步是将类实例化为一个我称为cli的对象,如下所示。 该对象包含用于从训练数据构建模型并对新数据点进行预测的算法。 它还包含算法已从训练数据中提取的信息。
Finally, to build the model on the training set, we call the fit method of the cli object.
最后,要在训练集上构建模型,我们调用cli对象的fit方法 。
from sklearn.neighbors import KNeighborsClassifiercli = KNeighborsClassifier(n_neighbors=1)
cli.fit(X_train, y_train)out:
出:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=None, n_neighbors=1, p=2,weights='uniform')In the output of the fit method, you can see the parameters used in creating the model.
在fit方法的输出中,您可以看到用于创建模型的参数。
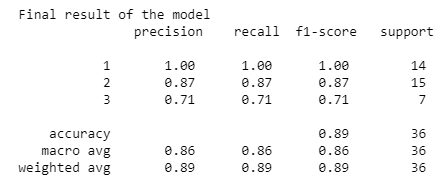
Now, it is time to evaluate the model. Below, the first output shows us that the model predict the 89% of the test data. Instead the second output give us a complete overview of the accuracy for each class.
现在,该评估模型了。 下面的第一个输出向我们展示了该模型预测了89%的测试数据。 相反,第二个输出为我们提供了每个类别的准确性的完整概述。
y_pred = cli.predict(X_test)
print("Test set score: {:.2f}".format(cli.score(X_test, y_test))) # below the values of the model
from sklearn.metrics import classification_report
print("Final result of the model \n {}".format(classification_report(y_test, y_pred)))out:
出:
Test set score: 0.89out:
出:
Conclusion
结论
I think that the best way to learn something is by practising. So in my case, I download the dataset from Kaggle which is one of the best places where to find a good dataset on which you can apply your machine learning algorithms and learn how they work.
我认为最好的学习方法是练习。 因此,就我而言,我是从Kaggle下载数据集的,这是找到良好数据集的最佳位置之一,您可以在该数据集上应用机器学习算法并了解它们的工作方式。
Thanks for reading this. There are some other ways you can keep in touch with me and follow my work:
感谢您阅读本文。 您可以通过其他方法与我保持联系并关注我的工作:
Subscribe to my newsletter.
订阅我的时事通讯。
You can also get in touch via my Telegram group, Data Science for Beginners.
您也可以通过我的电报小组“ 面向初学者的数据科学”来联系 。
翻译自: https://towardsdatascience.com/machine-learning-observe-how-knn-works-by-predicting-the-varieties-of-italian-wines-a64960bb2dae
knn 机器学习
http://www.taodudu.cc/news/show-997420.html
相关文章:
- python 实现分步累加_Python网页爬取分步指南
- 用于MLOps的MLflow简介第1部分:Anaconda环境
- pymc3 贝叶斯线性回归_使用PyMC3估计的贝叶斯推理能力
- 朴素贝叶斯实现分类_关于朴素贝叶斯分类及其实现的简短教程
- vray阴天室内_阴天有话:第1部分
- 机器人的动力学和动力学联系_通过机器学习了解幸福动力学(第2部分)
- 大样品随机双盲测试_训练和测试样品生成
- 从数据角度探索在新加坡的非法毒品
- python 重启内核_Python从零开始的内核回归
- 回归分析中自变量共线性_具有大特征空间的回归分析中的变量选择
- python 面试问题_值得阅读的30个Python面试问题
- 机器学习模型 非线性模型_机器学习:通过预测菲亚特500的价格来观察线性模型的工作原理...
- pytorch深度学习_深度学习和PyTorch的推荐系统实施
- 数据库课程设计结论_结论:
- 网页缩放与窗口缩放_功能缩放—不同的Scikit-Learn缩放器的效果:深入研究
- 未越狱设备提取数据_从三星设备中提取健康数据
- 分词消除歧义_角色标题消除歧义
- 在加利福尼亚州投资于新餐馆:一种数据驱动的方法
- 近似算法的近似率_选择最佳近似最近算法的数据科学家指南
- 在Python中使用Seaborn和WordCloud可视化YouTube视频
- 数据结构入门最佳书籍_最佳数据科学书籍
- 多重插补 均值插补_Feature Engineering Part-1均值/中位数插补。
- 客户行为模型 r语言建模_客户行为建模:汇总统计的问题
- 多维空间可视化_使用GeoPandas进行空间可视化
- 机器学习 来源框架_机器学习的秘密来源:策展
- 呼吁开放外网_服装数据集:呼吁采取行动
- 数据可视化分析票房数据报告_票房收入分析和可视化
- 先知模型 facebook_Facebook先知
- 项目案例:qq数据库管理_2小时元项目:项目管理您的数据科学学习
- 查询数据库中有多少个数据表_您的数据中有多少汁?
knn 机器学习_机器学习:通过预测意大利葡萄酒的品种来观察KNN的工作方式相关推荐
- pytorch机器学习_机器学习— PyTorch
pytorch机器学习 PyTorch : It is an open source machine learning library based on the Torch library (whic ...
- 机器学习模型 非线性模型_机器学习:通过预测菲亚特500的价格来观察线性模型的工作原理...
机器学习模型 非线性模型 Introduction 介绍 In this article, I'd like to speak about linear models by introducing y ...
- 信号处理深度学习机器学习_机器学习和信号处理如何融合?
信号处理深度学习机器学习 As a design engineer, I am increasingly exposed to more complex engineering challenges ...
- 机器学习与分布式机器学习_机器学习的歧义
机器学习与分布式机器学习 超越最高精度 (Beyond Achieving Top Accuracy) We are familiar with the idea of using machine l ...
- 泰坦尼克号 机器学习_机器学习项目泰坦尼克号问题陈述
泰坦尼克号 机器学习 介绍(Introduction) Everyone knows about the Titanic ship as many of the people have seen th ...
- 完整的机器学习_加州房价预测
机器学习的主要步骤 将问题框架化并且关注重点. 获取并探索数据以洞悉数据. 准备数据以更好地将基础数据模式暴露给机器学习算法. 探索多种不同的模型并列出最好的那些. 微调模型并将它们组合成一个很好的解 ...
- 信号处理深度学习机器学习_机器学习与信号处理
信号处理深度学习机器学习 机器学习性能与两种关键信号处理算法(快速傅里叶变换和最小均方预测)的有趣对比. (A fun comparison of machine learning performan ...
- 感知器 机器学习_机器学习感知器实现
感知器 机器学习 In this post, we are going to have a look at a program written in Python3 using numpy. We w ...
- 机器学习与分布式机器学习_机器学习治疗抑郁症
机器学习与分布式机器学习 重点 (Top highlight) Machine learning is a hot topic that has permeated numerous public a ...
最新文章
- abstract类中不可以有private的成员_我要告诉你:java接口中可以定义private私有方法...
- 【待填坑】LG_4996_咕咕咕
- C#调用C++(opencv)中图片数据传递的问题
- 获取客户端浏览器信息
- cf570 D. Tree Requests
- php点链接直接现在文件吗,PHP实现点击a标签的href做链接时,直接保存文件(任何类型),而...
- java类初始化顺序_《To Be a Better Javaer》-- Java 基础篇 vol.2:面向对象
- Metal Framework基础使用教程
- JS中同名函数有效执行顺序
- 深度学习2.0-30.卷积神经网络之池化与采样
- Mybatis--关于插入数据后返回id的操作
- 【优化分类】基于matlab粒子群算法优化支持向量机分类(多输入多分类)【含Matlab源码 1559期】
- 独热向量编码(one-hot encoding)原理详解与实现
- v9更新系统后为何显示服务器连接,红伞V9升级不能……报告里说好多文件无法与服务器建立连接……...
- 身神话继续遭受DDOS进攻,也遭受了雷同的陵犯
- Cadence画PCB的傻瓜式教程
- 分布式系统的完整介绍
- 《 阿房宫赋》古文鉴赏
- Cocos Creator plist图集使用方法
- D语言/DLang 2.085.1 发布,修复性迭代