【手把手教你】玩转Python金融量化利器之Pandas
前言
“手把手教你”系列将为Python初学者一一介绍Python在量化金融中运用最广泛的几个库(Library): NumPy(数组、线性代数)、SciPy(统计)、pandas(时间序列、数据分析)、matplotlib(可视化分析)。建议安装Anaconda软件(自带上述常见库),并使用Jupyter Notebook交互学习。
Pandas的数据结构类型:
Series (序列:一维列表)
DataFrame (数据框:二维表)
- Series
定义:数据表中的一列或一行,观测向量为一维数组,对于任意一组个体某一属性的观测可抽象为Series的概念。Series默认由index和values构成。
import pandas as pd
import numpy as np 1.1 Series的创建
创建Series 创建一个Series的基本格式是s = Series(data, index=index, name=name)
np.random.seed(1) #使用随机种子,这样每次运行random结果一致,
A=np.random.randn(5)
print("A is an array:\n",A)
S = pd.Series(A)
print("S is a Series:\n",S)
print("index: ", S.index) #默认创建索引,注意是从0开始
print("values: ", S.values)
A is an array:[ 1.62434536 -0.61175641 -0.52817175 -1.07296862 0.86540763]
S is a Series:0 1.624345
1 -0.611756
2 -0.528172
3 -1.072969
4 0.865408
dtype: float64
index: RangeIndex(start=0, stop=5, step=1)
values: [ 1.62434536 -0.61175641 -0.52817175 -1.07296862 0.86540763]可以在创建Series时添加index,并可使用Series.index查看具体的index。需要注意的一点是,
当从数组创建Series时,若指定index,那么index长度要和data的
长度一致
np.random.seed(2)
s=Series(np.random.randn(5),index=['a','b','c','d','e'])
print (s)
s.index
a -0.416758
b -0.056267
c -2.136196
d 1.640271
e -1.793436
dtype: float64Index(['a', 'b', 'c', 'd', 'e'], dtype='object')通过字典(dict)来创建Series。
stocks={'中国平安':'601318','格力电器':'000651','招商银行':'600036','中信证券':'600030','贵州茅台':'600519'}
Series_stocks = Series(stocks)
print (s)
中国平安 601318
格力电器 000651
招商银行 600036
中信证券 600030
贵州茅台 600519
dtype: object使用字典创建Series时指定index的情形(index长度不必和字典相同)。
Series(stocks, index=['中国平安', '格力电器', '招商银行', '中信证券','工业富联'])
#注意,在原来的stocks(dict)里没有‘工业富联’,因此值为‘NaN’
中国平安 601318
格力电器 000651
招商银行 600036
中信证券 600030
工业富联 NaN
dtype: object给数据序列和index命名:
Series_stocks.name='股票代码' #注意python是使用.号来连接和调用
Series_stocks.index.name='股票名称'
print(Series_stocks)
股票名称
中国平安 601318
格力电器 000651
招商银行 600036
中信证券 600030
贵州茅台 600519
Name: 股票代码, dtype: object1.2 Series数据的访问
Series对象的下标运算同时支持位置和标签两种方式
np.random.seed(3)
data=np.random.randn(5)
s = Series(data,index=['a', 'b', 'c', 'd', 'e'])
s
a 1.624345
b -0.611756
c -0.528172
d -1.072969
e 0.865408
dtype: float64
s[:2] #取出第0、1行数据
a -0.670228
b 0.488043
dtype: float64
s[[2,0,4]] #取出第2、0、4行数据
c -0.528172
a 1.624345
e 0.865408
dtype: float64
s[['e', 'a']] #取出‘e’、‘a’对应数据
e 0.865408
a 1.624345
dtype: float641.3 Series排序函数
np.random.seed(3)
data=np.random.randn(10)
s = Series(data,index=['j','a', 'c','b', 'd', 'e','h','f','g','i'])
s
j 1.788628
a 0.436510
c 0.096497
b -1.863493
d -0.277388
e -0.354759
h -0.082741
f -0.627001
g -0.043818
i -0.477218
dtype: float64
#排序
s.sort_index(ascending=True) #按index从小到大,False从大到小
a 0.436510
b -1.863493
c 0.096497
d -0.277388
e -0.354759
f -0.627001
g -0.043818
h -0.082741
i -0.477218
j 1.788628
dtype: float64
s.sort_values(ascending=True)
b -1.863493
f -0.627001
i -0.477218
e -0.354759
d -0.277388
h -0.082741
g -0.043818
c 0.096497
a 0.436510
j 1.788628
dtype: float64
s.rank(method='average',ascending=True,axis=0) #每个数的平均排名
j 10.0
a 9.0
c 8.0
b 1.0
d 5.0
e 4.0
h 6.0
f 2.0
g 7.0
i 3.0
dtype: float64
#返回含有最大值的索引位置:
print(s.idxmax())
#返回含有最小值的索引位置:
print(s.idxmin())
j
b根据索引返回已排序的新对象:
Series.sort_index(ascending=True)
根据值返回已排序的对象,NaN值在末尾:
Series.sort_values(ascending=True)
为各组分配一个平均排名:
Series.rank(method='average',ascending=True,axis=0)
rank的method选项:
'average':在相等分组中,为各个值分配平均排名
'max','min':使用整个分组中的最小排名
'first':按值在原始数据中出现的顺序排名
返回含有最大值的索引位置:
Series.idxmax()
返回含有最小值的索引位置:
Series.idxmin()
2 Pandas数据结构:DataFrame
DataFrame是一个二维的数据结构,通过数据组,index和columns构成
2.1 DataFrame数据表的创建
DataFrame是多个Series的集合体。
先创建一个值是Series的字典,并转换为DataFrame。
#通过字典创建DataFrame
d={'one':pd.Series([1.,2.,3.],index=['a','b','c']),'two':pd.Series([1.,2.,3.,4.,],index=['a','b','c','d']),'three':range(4),'four':1.,'five':'f'}
df=pd.DataFrame(d)
print (df)one two three four five
a 1.0 1.0 0 1.0 f
b 2.0 2.0 1 1.0 f
c 3.0 3.0 2 1.0 f
d NaN 4.0 3 1.0 f
#可以使用dataframe.index和dataframe.columns来查看DataFrame的行和列,
#dataframe.values则以数组的形式返回DataFrame的元素
print ("DataFrame index:\n",df.index)
print ("DataFrame columns:\n",df.columns)
print ("DataFrame values:\n",df.values)
DataFrame index:Index(['a', 'b', 'c', 'd'], dtype='object')
DataFrame columns:Index(['one', 'two', 'three', 'four', 'five'], dtype='object')
DataFrame values:[[1.0 1.0 0 1.0 'f'][2.0 2.0 1 1.0 'f'][3.0 3.0 2 1.0 'f'][nan 4.0 3 1.0 'f']]
#DataFrame也可以从值是数组的字典创建,但是各个数组的长度需要相同:
d = {'one': [1., 2., 3., 4.], 'two': [4., 3., 2., 1.]}
df = DataFrame(d, index=['a', 'b', 'c', 'd'])
print dfone two
a 1.0 4.0
b 2.0 3.0
c 3.0 2.0
d 4.0 1.0
#值非数组时,没有这一限制,并且缺失值补成NaN
d= [{'a': 1.6, 'b': 2}, {'a': 3, 'b': 6, 'c': 9}]
df = DataFrame(d)
print dfa b c
0 1.6 2 NaN
1 3.0 6 9.0
#在实际处理数据时,有时需要创建一个空的DataFrame,可以这么做
df = DataFrame()
print (df)
Empty DataFrame
Columns: []
Index: []
#另一种创建DataFrame的方法十分有用,那就是使用concat函数基于Series
#或者DataFrame创建一个DataFrame
a = Series(range(5)) #range(5)产生0到4
b = Series(np.linspace(4, 20, 5)) #linspace(a,b,c)
df = pd.concat([a, b], axis=1)
print (df)0 1
0 0 4.0
1 1 8.0
2 2 12.0
3 3 16.0
4 4 20.0其中的axis=1表示按列进行合并,axis=0表示按行合并,
并且,Series都处理成一列,所以这里如果选axis=0的话,
将得到一个10×1的DataFrame。下面这个例子展示了如何按行合并
DataFrame成一个大的DataFrame:
df = DataFrame()
index = ['alpha', 'beta', 'gamma', 'delta', 'eta']
for i in range(5):a = DataFrame([np.linspace(i, 5*i, 5)], index=[index[i]])df = pd.concat([df, a], axis=0)
print (df)0 1 2 3 4
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.02.2 DataFrame数据的访问
#DataFrame是以列作为操作的基础的,全部操作都想象成先从DataFrame里取一列,
#再从这个Series取元素即可。
#可以用datafrae.column_name选取列,也可以使用dataframe[]操作选取列
df = DataFrame()
index = ['alpha', 'beta', 'gamma', 'delta', 'eta']
for i in range(5):a = DataFrame([np.linspace(i, 5*i, 5)], index=[index[i]])df = pd.concat([df, a], axis=0)
print('df: \n',df)
print ("df[1]:\n",df[1])
df.columns = ['a', 'b', 'c', 'd', 'e']
print('df: \n',df)
print ("df[b]:\n",df['b'])
print ("df.b:\n",df.b)
print ("df[['a','b']]:\n",df[['a', 'd']])
df: 0 1 2 3 4
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.0
df[1]:alpha 0.0
beta 2.0
gamma 4.0
delta 6.0
eta 8.0
Name: 1, dtype: float64
df: a b c d e
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.0
df[b]:alpha 0.0
beta 2.0
gamma 4.0
delta 6.0
eta 8.0
Name: b, dtype: float64
df.b:alpha 0.0
beta 2.0
gamma 4.0
delta 6.0
eta 8.0
Name: b, dtype: float64
df[['a','b']]:a d
alpha 0.0 0.0
beta 1.0 4.0
gamma 2.0 8.0
delta 3.0 12.0
eta 4.0 16.0
#访问特定的元素可以如Series一样使用下标或者是索引:
print (df['b'][2]) #第b列,第3行(从0开始算)
print (df['b']['gamma']) #第b列,gamma对应行
4.0
4.0
##### df.loc['列或行名'],df.iloc[n]第n行,df.iloc[:,n]第n列
#若需要选取行,可以使用dataframe.iloc按下标选取,
#或者使用dataframe.loc按索引选取
print (df.iloc[1]) #选取第一行元素
print (df.loc['beta'])#选取beta对应行元素
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: beta, dtype: float64
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: beta, dtype: float64
#选取行还可以使用切片的方式或者是布尔类型的向量:
print ("切片取数:\n",df[1:3])
bool_vec = [True, False, True, True, False]
print ("根据布尔类型取值:\n",df[bool_vec]) #相当于选取第0、2、3行
切片取数:a b c d e
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
根据布尔类型取值:a b c d e
alpha 0.0 0.0 0.0 0.0 0.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
#行列组合起来选取数据:
print (df[['b', 'd']].iloc[[1, 3]])
print (df.iloc[[1, 3]][['b', 'd']])
print (df[['b', 'd']].loc[['beta', 'delta']])
print (df.loc[['beta', 'delta']][['b', 'd']])b d
beta 2.0 4.0
delta 6.0 12.0b d
beta 2.0 4.0
delta 6.0 12.0b d
beta 2.0 4.0
delta 6.0 12.0b d
beta 2.0 4.0
delta 6.0 12.0
#如果不是需要访问特定行列,而只是某个特殊位置的元素的话,
#dataframe.at和dataframe.iat
#是最快的方式,它们分别用于使用索引和下标进行访问
print(df)
print (df.iat[2, 3]) #相当于第3行第4列
print (df.at['gamma', 'd'])a b c d e
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.0
8.0
8.02.3创建时间序列
pandas.date_range(start=None, end=None, periods=None, freq='D',
tz=None, normalize=False, name=None, closed=None, **kwargs)
dates=pd.date_range('20180101',periods=12,freq='m')
print (dates)
DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30','2018-05-31', '2018-06-30', '2018-07-31', '2018-08-31', '2018-09-30','2018-10-31', '2018-11-30', '2018-12-31'], dtype='datetime64[ns]', freq='M')
np.random.seed(5)
df=pd.DataFrame(np.random.randn(12,4),index=dates,columns=list('ABCD'))
df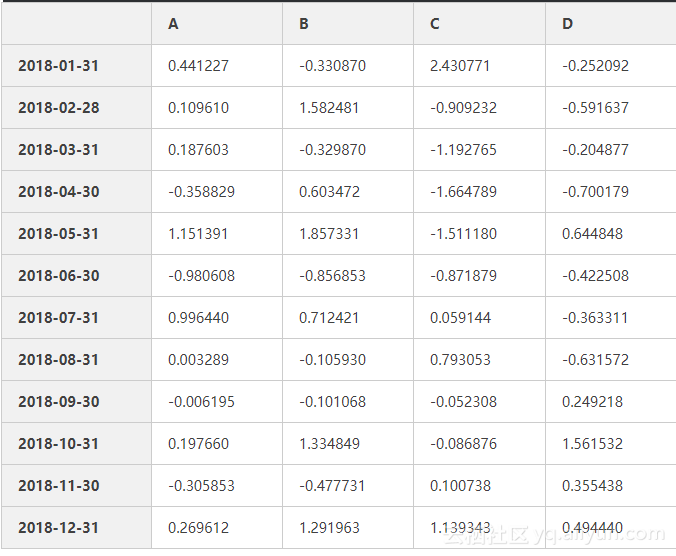
#查看数据头n行 ,默认n=5
df.head()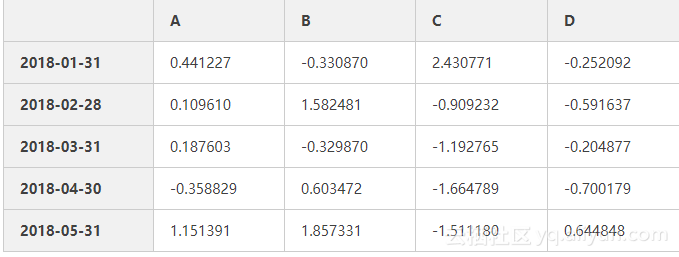
#查看数据最后3行
df.tail(3)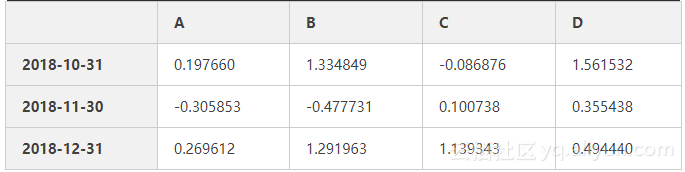
#查看数据的index(索引),columns (列名)和数据
print(df.index)
DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30','2018-05-31', '2018-06-30', '2018-07-31', '2018-08-31', '2018-09-30','2018-10-31', '2018-11-30', '2018-12-31'], dtype='datetime64[ns]', freq='M')
print(df.columns)
Index(['A', 'B', 'C', 'D'], dtype='object')
print(df.values)
[[ 0.44122749 -0.33087015 2.43077119 -0.25209213][ 0.10960984 1.58248112 -0.9092324 -0.59163666][ 0.18760323 -0.32986996 -1.19276461 -0.20487651][-0.35882895 0.6034716 -1.66478853 -0.70017904][ 1.15139101 1.85733101 -1.51117956 0.64484751][-0.98060789 -0.85685315 -0.87187918 -0.42250793][ 0.99643983 0.71242127 0.05914424 -0.36331088][ 0.00328884 -0.10593044 0.79305332 -0.63157163][-0.00619491 -0.10106761 -0.05230815 0.24921766][ 0.19766009 1.33484857 -0.08687561 1.56153229][-0.30585302 -0.47773142 0.10073819 0.35543847][ 0.26961241 1.29196338 1.13934298 0.4944404 ]]
#数据转置
# df.T根据索引排序数据排序:(按行axis=0或列axis=1)
df.sort_index(axis=1,ascending=False)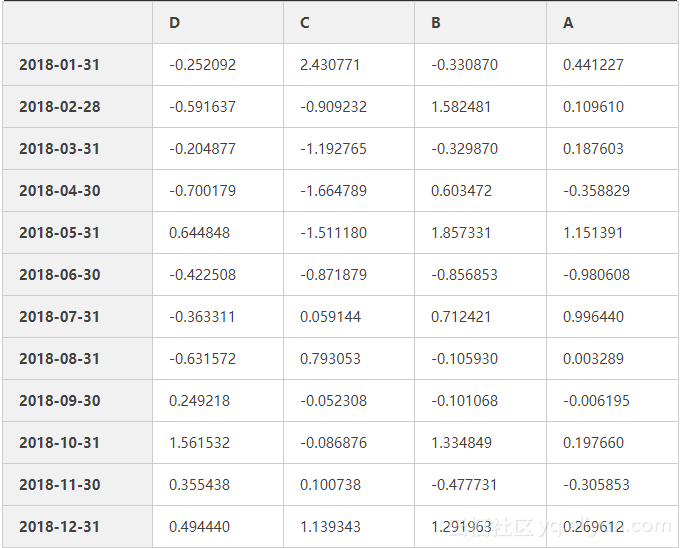
#按某列的值排序
df.sort_values('A') #按A列的值从小到大排序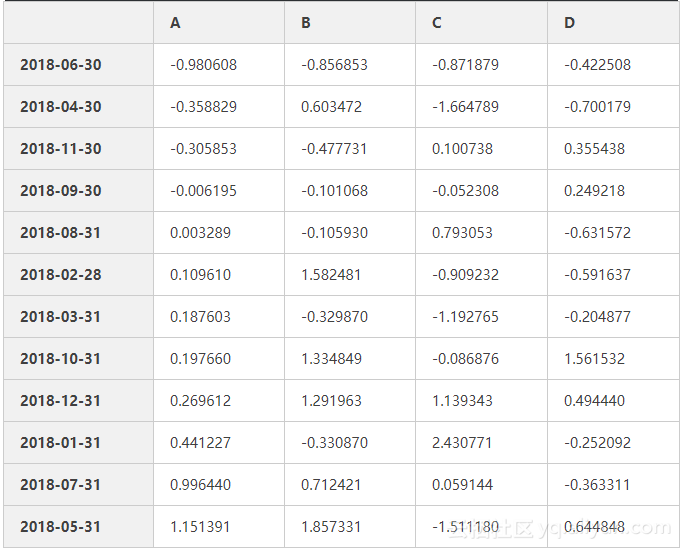
#数据选取loc和iloc
df.loc[dates[0]]
A 0.441227
B -0.330870
C 2.430771
D -0.252092
Name: 2018-01-31 00:00:00, dtype: float64
df.loc['20180131':'20180430',['A','C']] #根据标签取数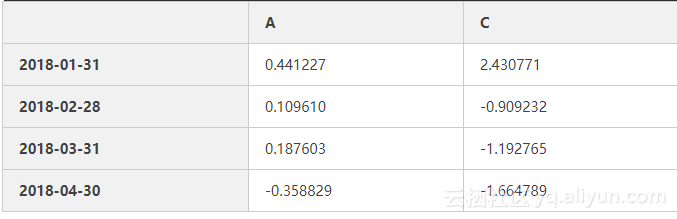
df.iloc[1:3,1:4] #根据所在位置取数,注意从0开始数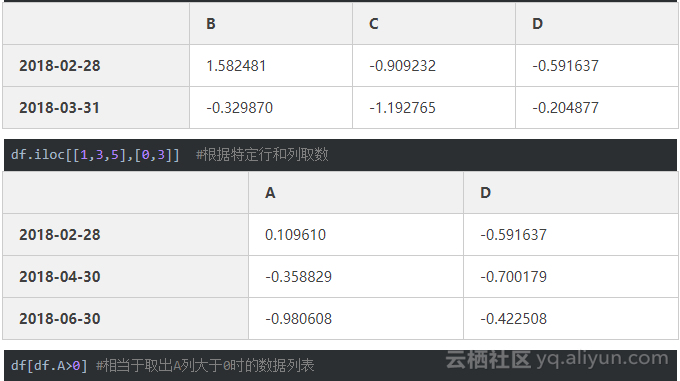
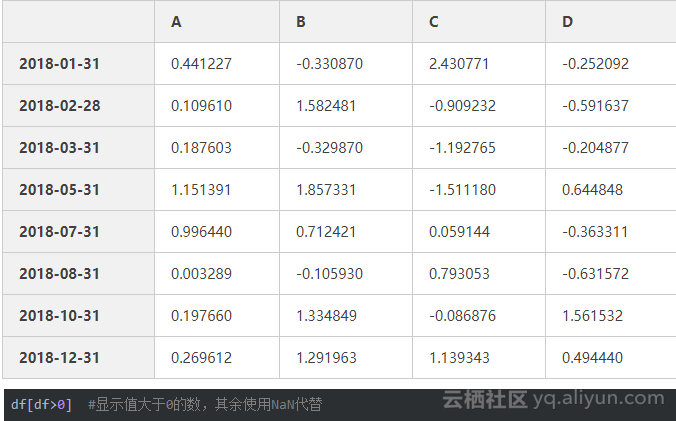
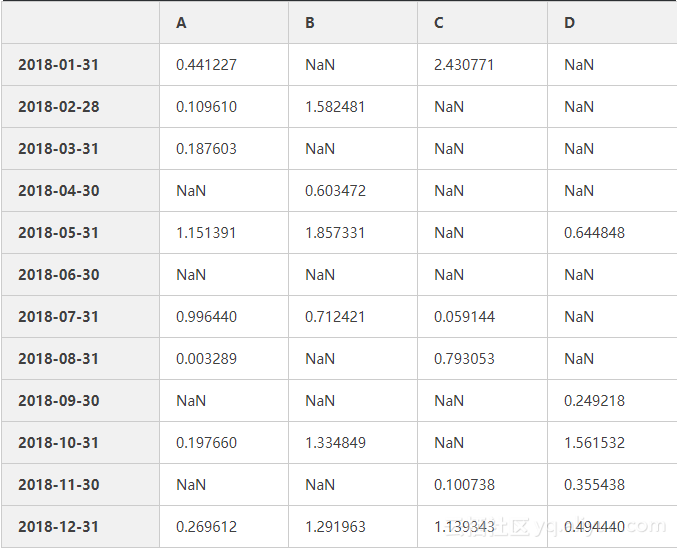
数据筛选isin()
df2=df.copy() #复制df数据
df2['E']=np.arange(12)
df2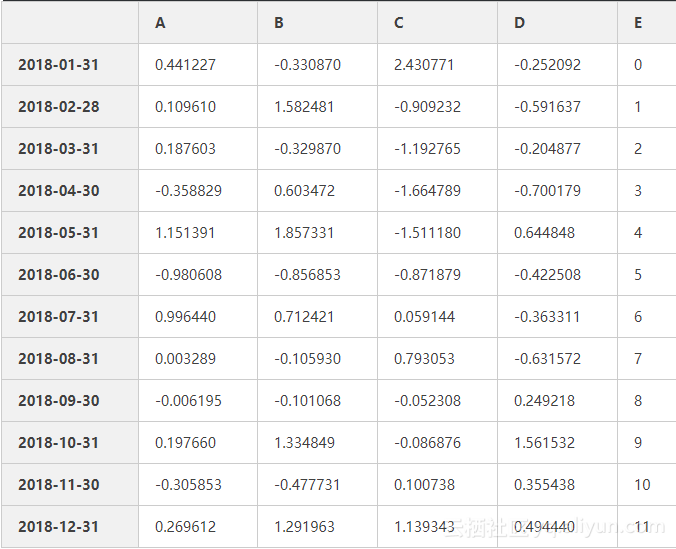
df2[df2['E'].isin([0,2,4])]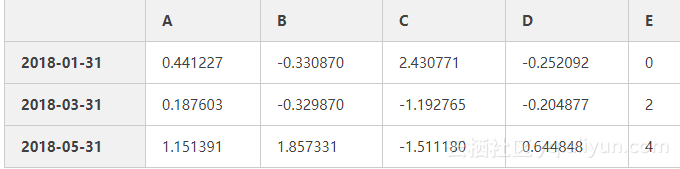
- 缺失值处理
缺失值用NaN显示
date3=pd.date_range('20181001',periods=5)
np.random.seed(6)
data=np.random.randn(5,4)
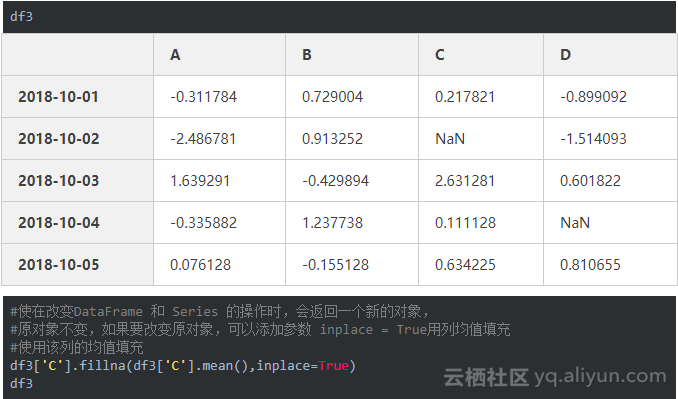
df3=pd.DataFrame(data,index=date3,columns=list('ABCD'))
df3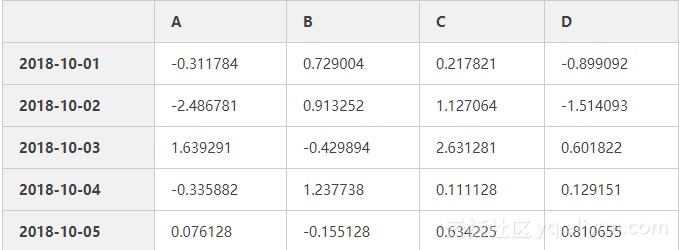
df3.iat[3,3]=np.NaN #令第3行第3列的数为缺失值(0.129151)
df3.iat[1,2]=np.NaN #令第1行第2列的数为缺失值(1.127064)
df3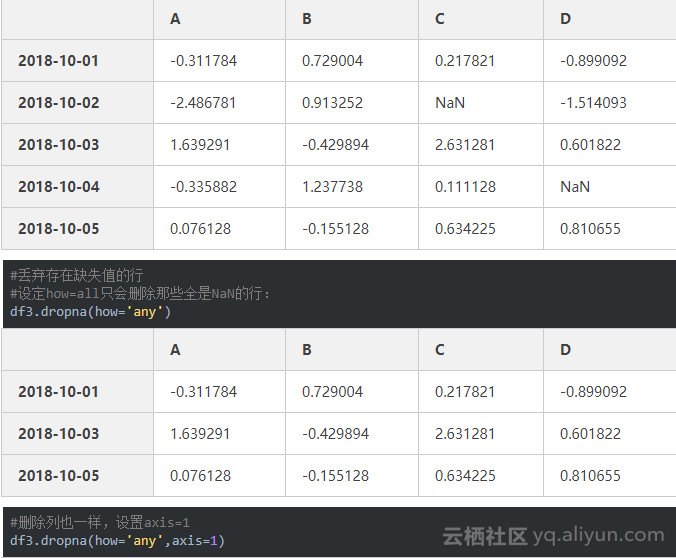
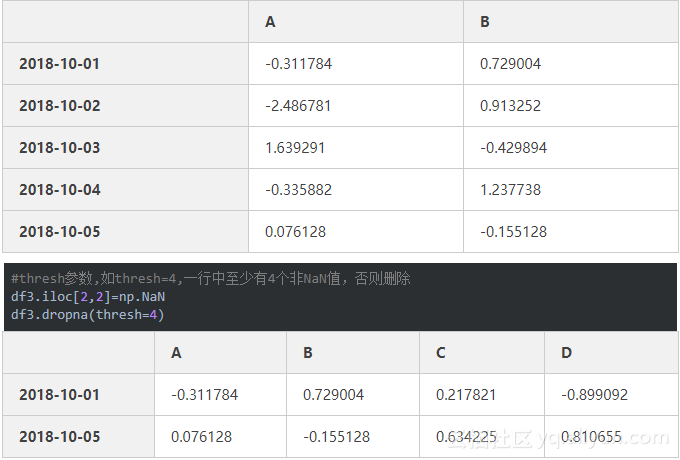
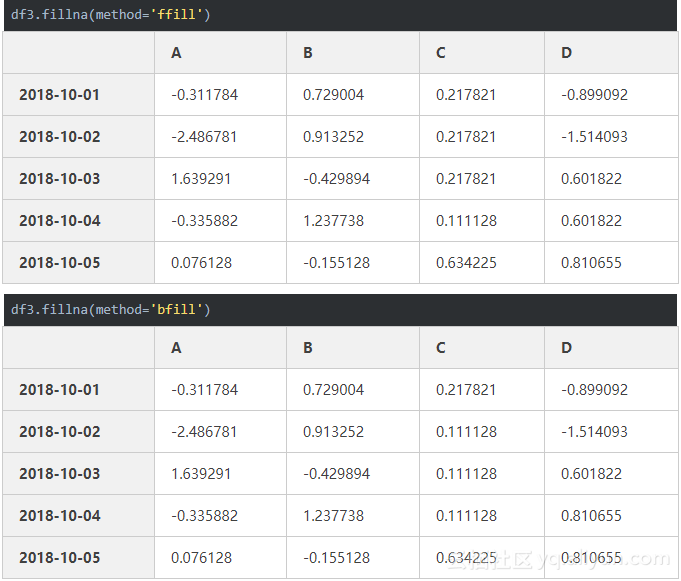
填充缺失值
fillna 还可以使用 method 参数
method 可以使用下面的方法
1 . pad/ffill:用前一个非缺失值去填充该缺失值
2 . backfill/bfill:用下一个非缺失值填充该缺失值
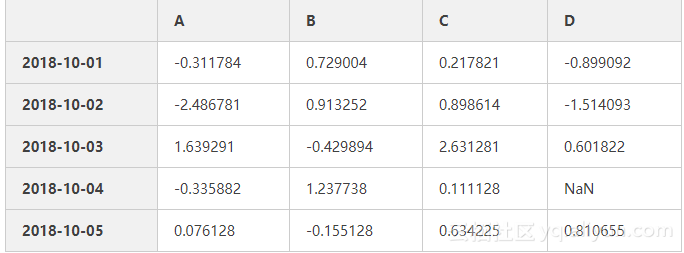
4、统计
date4=pd.date_range('20181001',periods=5)
np.random.seed(7)
data4=np.random.randn(5,4)
df4=pd.DataFrame(data4,index=date3,columns=list('ABCD'))
df4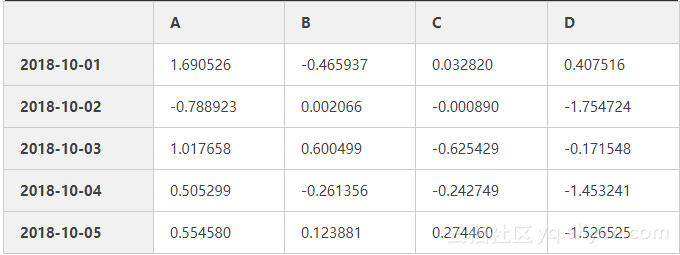
描述性统计 df.describe()
df4.describe()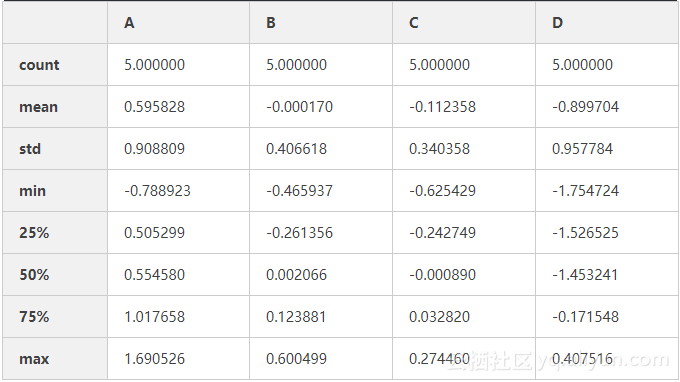
df4.mean() #均值,默认按列axis=0
A 0.595828
B -0.000170
C -0.112358
D -0.899704
dtype: float64
df4.mean(axis=1) #按行
2018-10-01 0.416231
2018-10-02 -0.635618
2018-10-03 0.205295
2018-10-04 -0.363012
2018-10-05 -0.143401
Freq: D, dtype: float64对数据使用函数df.apply()
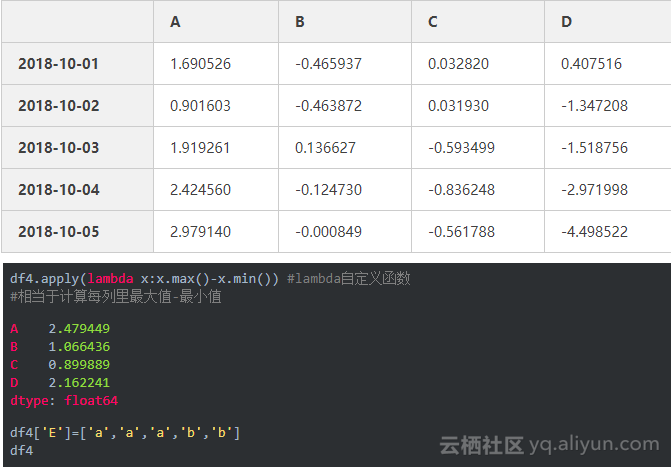
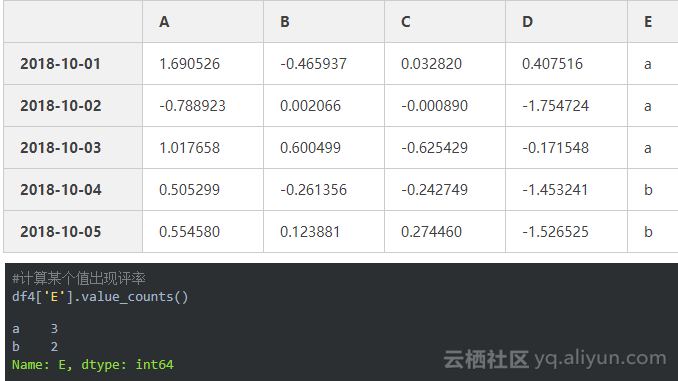
5、数据合并
#Concat()
d1=pd.Series(range(5))
print(d1)
d2=pd.Series(range(5,10))
print(d2)
0 0
1 1
2 2
3 3
4 4
dtype: int64
0 5
1 6
2 7
3 8
4 9
dtype: int64
pd.concat([d1,d2],axis=1) #默认是纵向合并即axis=0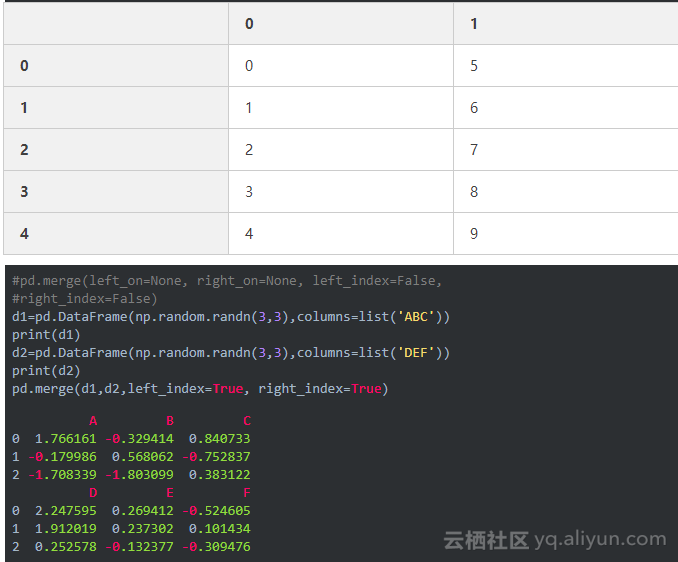
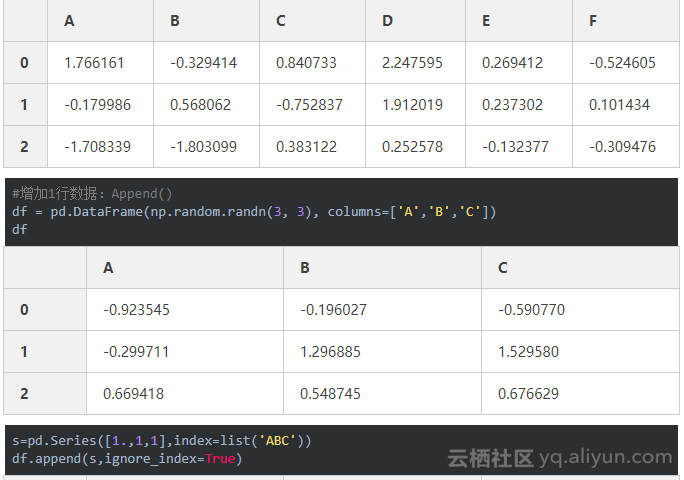
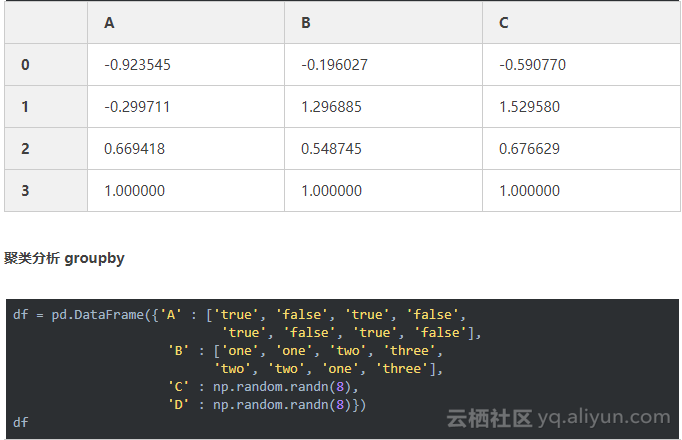
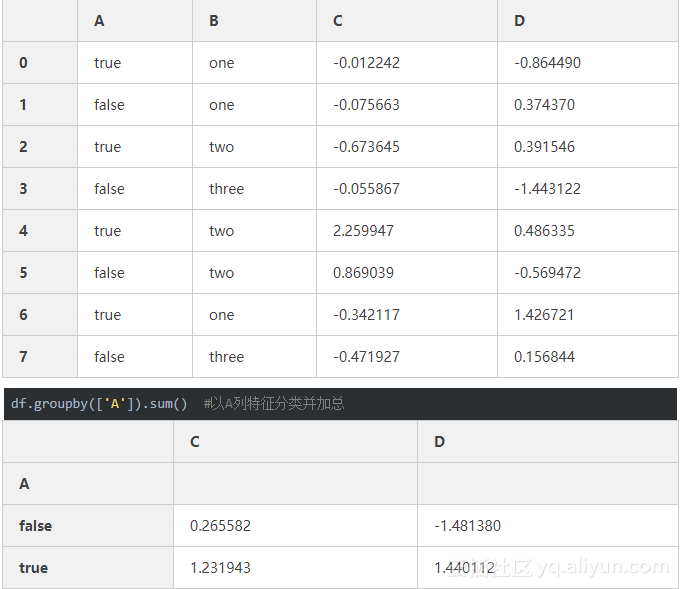
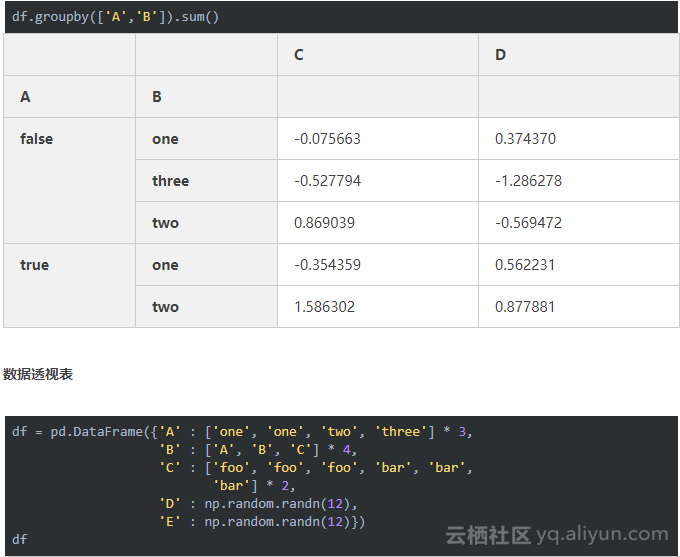
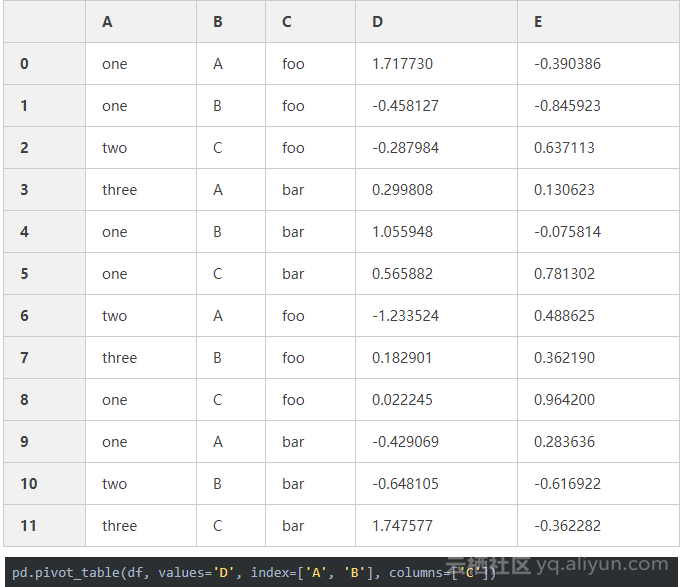
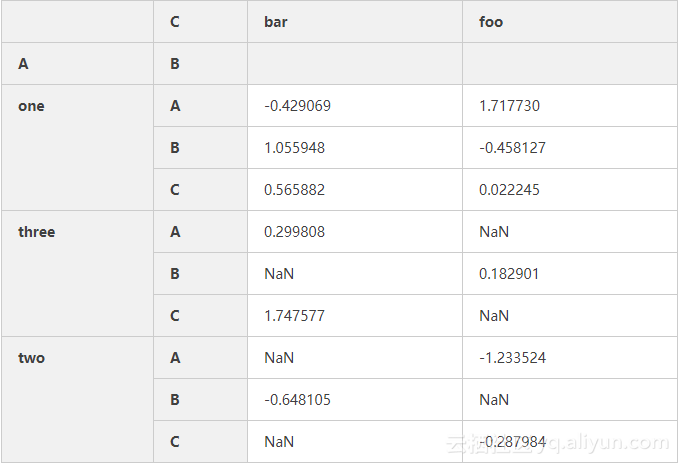
6、数据可视化(画图)
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
mpl.rcParams['axes.unicode_minus']=False # 用来正常显示负号
%matplotlib inline
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000',periods=1000))
ts = ts.cumsum()
ts.plot(figsize=(12,8))
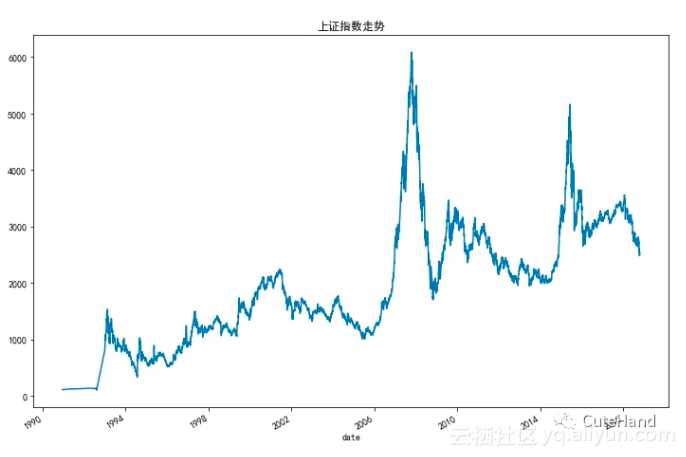
#利用tushare包抓取股票数据并画图
#得到的是DataFrame的数据结构
import tushare as ts
df=ts.get_k_data('sh',start='1990-01-01')
import pandas as pd
df.index=pd.to_datetime(df['date'])
df['close'].plot(figsize=(12,8))
plt.title("上证指数走势")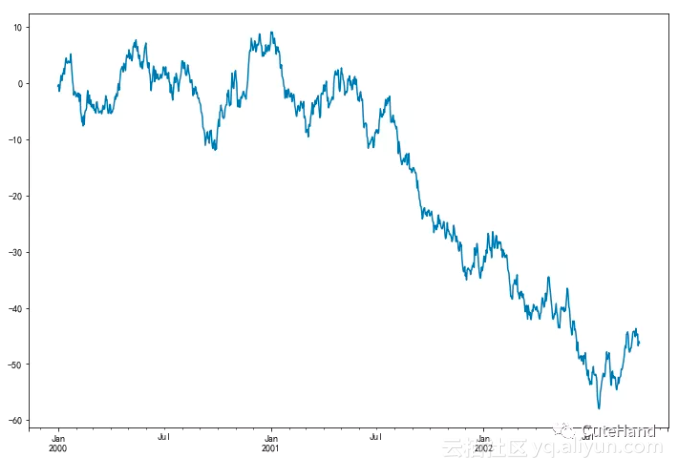
原文发布时间为:2019-1-3
本文作者:CuteHand
本文来自云栖社区合作伙伴“ Python爱好者社区”,了解相关信息可以关注“python_shequ”微信公众号
【手把手教你】玩转Python金融量化利器之Pandas相关推荐
- Python金融量化 | 从入门到高阶实战应用
引言 今天给大家分享一个微信公众号"Python金融量化",作者是金融学博士,堪萨斯大学访问学者,专注于分享Python在金融量化领域的实战应用,坚持走原创路线,持续输出技术干货, ...
- python 海龟交易法则_【手把手教你】用Python量化海龟交易法则
止损:什么时候放弃一个亏损的头寸? 离市:什么时候退出一个盈利的头寸? 策略:如何买卖? 趋势追踪--唐奇安通道 海龟交易法则利用唐奇安通道的突破点作为买卖信号指导交易,简单而言唐奇安通道是由一条上轨 ...
- python海龟交易策略_【手把手教你】用Python量化海龟交易法则 - 简书
下面使用简化版的海龟交易法则进行历史回测,即不考虑仓位管理和动态止损/止盈条件,以唐奇安通道突破作为买入卖出信号. 交易规则为: (1)当今天的收盘价,大于过去20个交易日中的最高价时,以收盘价买入: ...
- 「手把手教你」用Python量化海龟交易法则
1引言 对于纯多头或空头的方向性策略而言,只有当证券价格是均值回归或趋势的,交易策略才能盈利.否则,如果价格是随机游走的,交易将无利可图(法玛有效市场假说).换句话说,目前各种纷繁复杂的所谓量化策略大 ...
- 【手把手教你】用Python量化海龟交易法则
点击"简说Python",选择"置顶/星标公众号" 福利干货,第一时间送达! 本文授权转载自Python金融量化,禁二次转载 作者:CuteHand 阅读文本大 ...
- python金融实战 源代码_穆棱市seo总代直销python金融量化营业实战课程 python量化项目实战源码+课件+视频...
python金融量化生意实战课程 python量化项目实战源码+课件+视频 1. 自愿化生意综述 重要实质: 课程实质综述,自愿化/算法生意先容,python正在自愿生意中的使用简介 2. 量化生意体 ...
- android 自动化 微信,C#手把手教你玩微信自动化
原标题:C#手把手教你玩微信自动化 转自:初久的私房菜 cnblogs.com/MrChuJiu/p/13959383.html 介绍 本文主要讲的内容是 C# + Appium 自动化玩微信. Ap ...
- echarts formatter_手把手教你玩转echarts(二)折线图
茫茫人海中与你相遇 相信未来的你不会很差 作者:婷酱Yaaa 来源:https://juejin.im/post/5f0292d35188252e5a5dbed0 前言 哈喽,everybody,我又 ...
- 手把手教你玩转SOCKET模型之重叠I/O篇(下)
http://blog.csdn.net/PiggyXP/archive/2004/09/23/114908.aspx 四. 实现重叠模型的步骤 作了这么多的准备工作,费了这么多的笔墨,我们终 ...
最新文章
- Codeforces Round #272 (Div. 2)
- 【FPGA】Buffer专题介绍(三)
- Nature撤稿!为销毁造假证据丢弃电脑,“划时代”成果翻车了,副校长鞠躬道歉...
- LPC43xx SGPIO Pattern Match Mode
- Linux下VMware虚拟机报Could not open /dev/vmmon: No such file or directory. Please make sure that the kern
- 算法数据结构(一)-B树
- 基金小窍门:如何判断基金的赚与赔
- Spring的@Scheduled注解实现定时任务
- 日记背景 android,只是意外 - 用这些 APP 来记录生活,再也不用担心无法坚持写日记 - Android 应用 - 【最美应用】...
- scrapy 伪装代理和fake_userAgent的使用
- [Coci2015]Divljak
- php 呼叫中心 源码,FreeSWITCH+Workerman+PHP 搭建呼叫中心
- C语言学习笔记--数组指针和指针数组
- 怎么查询sybase money列数据长度_用PBI分析上市公司财务数据(一)
- Java 字符串替换String.replaceAll需注意
- 什么是归纳法、数学归纳法
- Google Play支付:测试报错“无法购买您要的商品”问题
- js vue+elementui 全屏跟退出全屏功能搬砖
- 携程商旅酒店直连平台的实践(一)
- python中文字符截取乱码