Zookeeper3.4.11+Hadoop2.7.6+Hbase2.0.0搭建分布式集群
2019独角兽企业重金招聘Python工程师标准>>> 
有段时间没更新博客了,趁着最近有点时间,来完成之前关于集群部署方面的知识。今天主要讲一讲Zookeeper+Hadoop+Hbase分布式集群的搭建,在我前几篇的集群搭建的博客中已经分别讲过了Zookeeper和Hadoop的集群搭建:
集群四部曲(一):完美的Zookeeper集群搭建
集群四部曲(二):完美的Hadoop集群搭建
,剩下的就只有Hbase集群了,下面就来说一下基于Zookeeper和Hadoop的Hbase分布式集群的搭建。
一、环境:同样的启用三个节点,分别是虚拟机slave01,slave02,slave03,基于之前已经搭建好的环境,包括JDK、Zookeeper、Hadoop
二、Hbase配置(自己解压哈)
配置前,着重说一下:版本匹配问题,若出现不匹配的情况,后面启动会失败,关于版本匹配大家可以参考该链接内容:
https://blog.csdn.net/anningzhu/article/details/60468723
接下来了解一下HMaster、HRegionServer,这里准备将slave01作为HMaster,slave02、slave03作为HRegionServer,下面的操作都是以这个为前提展开的,请大家做好战前温习,以防不知下面的操作的意义,开始配置吧:
关闭防火墙,大家切记:
systemctl stop firewalld #只在本次运用时生效,下次开启机器时需重复此操作
或
systemctl disable firewalld #此命令在下次重启时生效,将永久关闭防火墙(1)将Hbase添加到环境变量中
vim /etc/profile添加HBASE_HOME,修改如下:
JAVA_HOME=/usr/java/jdk1.8.0_161
JRE_HOME=/usr/java/jdk1.8.0_161/jre
SCALA_HOME=/usr/local/scala
HADOOP_HOME=/usr/local/hadoop
SPARK_HOME=/usr/local/spark
ZOOKEEPER_HOME=/usr/local/zookeeper
HBASE_HOME=/usr/local/hbase
KAFKA_HOME=/usr/local/kafka
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin:$KAFKA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME SCALA_HOME HADOOP_HOME SPARK_HOME ZOOKEEPER_HOME HBASE_HOME KAFKA_HOME PATH CLASSPATH
使文件生效,运行命令:
source /etc/profile(2)修改HBase目录conf下配置文件hbase-env.sh:
export JAVA_HOME=/usr/java/jdk1.8.0_161/
export HBASE_PID_DIR=/usr/local/hbase/pid/
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop/
export HBASE_MANAGES_ZK=false其中,pid自己手动在HBase目录下新建,ZK=false表示不使用自身的Zookeeper。
(3)修改HBase目录conf下配置文件hbase-site.xml:
<configuration><property><name>hbase.root.dir</name><value>hdfs://slave01:9000/hbase</value><description>设置 hbase 数据库存放数据的目录</description></property><property><name>hbase.cluster.distributed</name><value>true</value><description>打开 hbase 分布模式</description></property><property><name>hbase.master</name><value>slave01</value><description>指定 hbase 集群主控节点</description></property><property><name>hbase.tmp.dir</name><value>/usr/tmp/hbase</value><description>hbase的一些临时文件存放目录。</description></property><property><name>hbase.zookeeper.quorum</name><value>slave01,slave02,slave03</value><description> 指定 zookeeper 集群节点名</description></property><property><name>zookeeper.session.timeout</name><value>60000000</value></property><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value><description> 连接到zookeeper的端口,默认是2181</description></property>
</configuration>
其中,hbase.root.dir注意和Hadoop保持一致。
(4)修改HBase目录conf下配置文件regionservers:
slave02
slave03添加的是作为datanode的节点。
(5)拷贝配置文件到其他服务器
若不想一个一个的进行文件配置,可以将已经配置好的文件拷贝到其他需要的服务器上,注意拷贝成功后执行命令:source /etc/profile使之生效:
//slave01上的/etc/profile文件拷贝到slave02
scp -r /etc/profile slave02:/etc/profile
//slave01上的/usr/local/hadoop文件夹整个目录拷贝到slave02
scp -r /usr/local/hbase slave02:/usr/local/节点slave03同上。以上配置即初步完成了HBase的配置,下面是启动验证的时候了,在这之前,最好重启虚拟机,保证所有的配置生效,切记,重启后先关闭防火墙,w(゚Д゚)w。
三、启动HBase集群并验证
因为我们使用的是Zookeeper+Hadoop+HBase,所以启动前,先要启动Zookeeper和Hadoop,分别依次启动Zookeeper和Hadoop,保证正常启动,请参考之前的博客。正常启动后如下:
[hadoop@slave01 sbin]$ jps
2880 QuorumPeerMain
3656 ResourceManager
3945 Jps
3449 SecondaryNameNode
3213 NameNode
[hadoop@slave02 bin]$ jps
3079 Jps
3018 NodeManager
2876 DataNode
2687 QuorumPeerMain
[hadoop@slave03 bin]$ jps
2644 QuorumPeerMain
3066 Jps
2938 NodeManager
2794 DataNode
接下来启动HBase,如下:
[hadoop@slave01 bin]$ ./start-hbase.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
running master, logging to /usr/local/hbase/logs/hbase-hadoop-master-slave01.out
slave02: running regionserver, logging to /usr/local/hbase/bin/../logs/hbase-hadoop-regionserver-slave02.out
slave03: running regionserver, logging to /usr/local/hbase/bin/../logs/hbase-hadoop-regionserver-slave03.out
显示多出的进程为HMaster:
[hadoop@slave01 sbin]$ jps
2880 QuorumPeerMain
4387 HMaster
4518 Jps
3656 ResourceManager
3449 SecondaryNameNode
3213 NameNode
节点slave02和slave03多出的进程为HRegionServer:
[hadoop@slave02 bin]$ jps
3424 HRegionServer
3018 NodeManager
2876 DataNode
3485 Jps
2687 QuorumPeerMain
好了,上面关于HBase集群已经成功启动了。
四、查看hbase管理界面
访问 slave01:16010,如下:
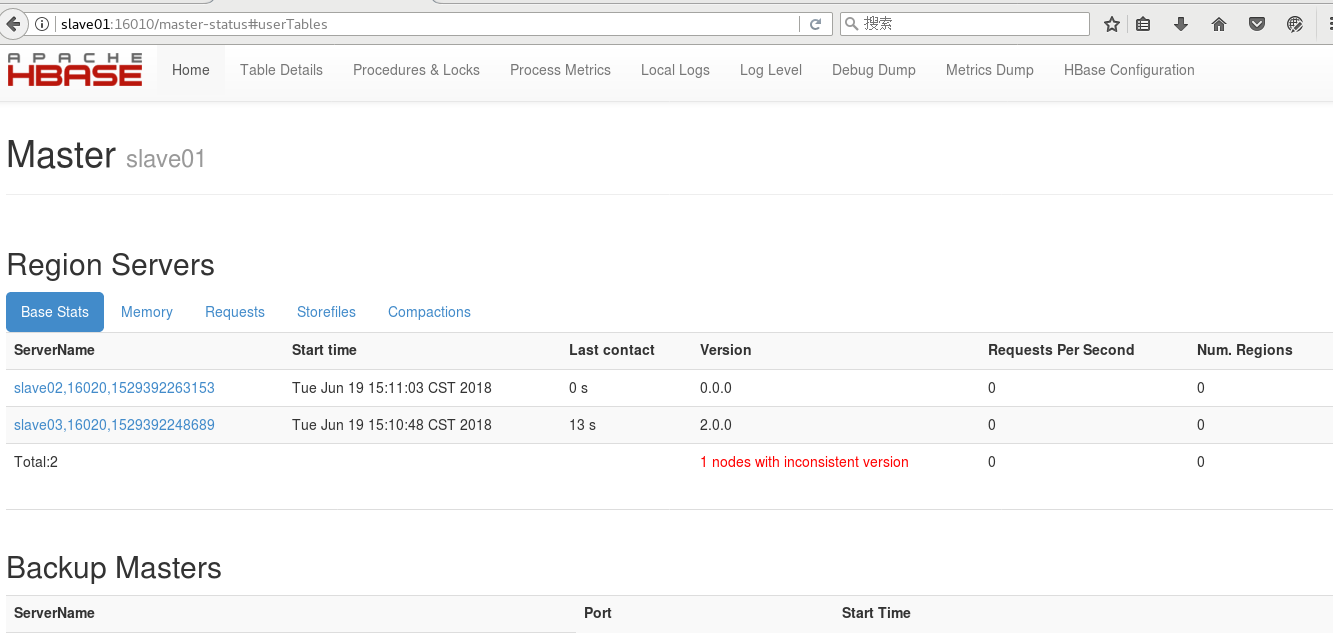
点击上图Region Servers中的节点slave02或者slave03即可查看其对应信息:
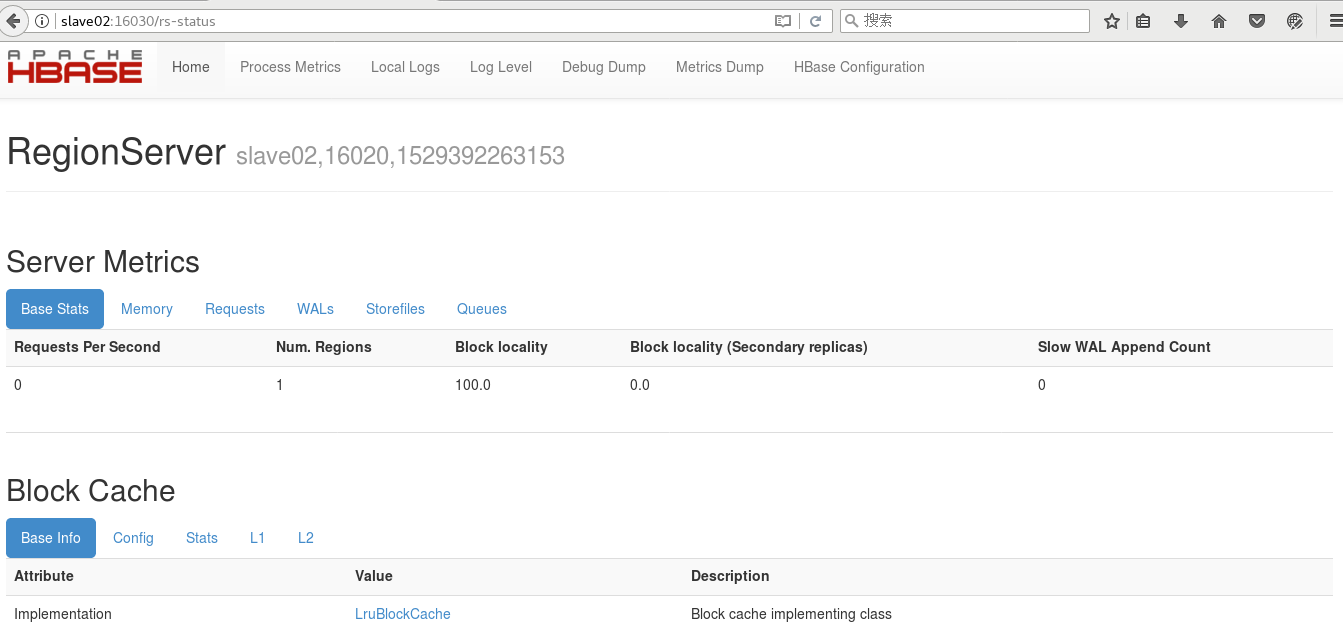
通过上面我们可以查看hbase相关信息,非常实用。
好了,关于这方面的配置已经结束了,下篇将说下HBase数据库的相关知识,敬请期待!
转载于:https://my.oschina.net/u/3747963/blog/1831923
Zookeeper3.4.11+Hadoop2.7.6+Hbase2.0.0搭建分布式集群相关推荐
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解: zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hado ...
- 【干货】Dask快速搭建分布式集群(大数据0基础可以理解,并使用!)
非常开心,解决了很久都没有解决的问题 使用的语言: Python3.5 分布式机器: windows7 注意到,其实,通过这工具搭建分布式不需要管使用的电脑是什么系统. 分布式使用流程 Created ...
- redis3.0搭建分布式集群
redis高版本使用ruby实现了集群,所以需要ruby环境,安装ruby环境和redis的gem接口后,就可以使用redis的redis-trib.rb脚本创建集群. 先列一下大的步骤. 1.修改配 ...
- spark1.1.0部署standalone分布式集群
配置三个节点的spark集群,集群模式为standalone模式,其中sp1节点作为主节点,sp2节点和sp3节点为从节点.***注意所有操作均为root用户. 创建3个CentOS虚拟机,如下: s ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- 【转】Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
https://www.cnblogs.com/caiyisen/p/7373512.html 前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- CentOS 7上搭建Spark3.0.1+ Hadoop3.2.1分布式集群
CentOS 7上搭建Spark3.0.1+ Hadoop3.2.1分布式集群 VMWare 安装CentOS 7 使用Xshell连接虚拟机 集群设置 安装JDK 1.8 SSH 免密登陆 安装ha ...
- CentOS 7上搭建Spark 3.0.1 + Hadoop 3.2.1分布式集群
CentOS 7上搭建Spark3.0.1+ Hadoop3.2.1分布式集群 VMWare 安装CentOS 7 使用Xshell连接虚拟机 集群设置 安装JDK 1.8 SSH 免密登陆 安装ha ...
最新文章
- AI帮你靠“想象”打字:手机电脑软键盘也能盲打了,准确率能达到95%
- python需要多久-在传智播客培训python需要多久?
- VS+VA 开发NDK
- 学习知识[置顶] C++学习方式方法
- java agent_GitHub - dingjs/javaagent: 基于javaagent开发的APM工具,收集方法的执行次数和执行时间,定时输出成json格式的日志。...
- 手机经常提示找不到服务器,为什么我的手机显示无法连接到服务器
- springboot使用jsp完成数据的页面展示
- python格式化输出类型_在python中自己写的数据类型使用print无法输出每个元素
- YOLO系列目标检测算法-YOLOv2
- You辉编程_用vue3.0开发移动app的流程
- 抢滩新零售混战 实力战将才不惧双十一 附:双十一红包雨时间表
- 图片怎么转文字?建议收藏这些方法
- UE4母材质之法线贴图
- 用Multisim13.0进行混频器的仿真
- python字符串转json(python字符串转浮点数)
- Postman使用xmysql连接数据库及Handshake inactivity timeout、PROTOCOL SEQUENCE TIMEOUT问题解决
- 深圳互联网科技公司|外企篇
- VS2017中配置QT5.12开发环境
- Redis用来干嘛的?
- OCR——视觉会议调研